






前言
时隔4个月,开源文生图模型霸主Stable Diffusion原班人马再创业!2024年8月1日官宣:Black Forest Labs成立,公司的第一个产品FLUX.1系列模型包含专业版、开发者版、快速版三种模型,效果直接秒杀Midjourney、DALL-E和Stable Diffusion!目前已获3200万美元融资。

据官方消息,文生图只是一个开始,后续还将发布视频生成模型,准备和Sora和Gen-3等产品过招。
相关链接
效果
FLUX.1在文字生成、复杂指令遵循和人手生成上具备优势。以下是其最强的专业版模型FLUX.1[pro]生成图像示例,可以看到即使是生成大段的文字、多个人物,也没有出现字符、人手等细节上的错误。





官方新闻


今天,我们很高兴地宣布成立Black Forest Labs。我们的使命深深扎根于生成式人工智能研究社区,旨在为图像和视频等媒体开发和推进最先进的生成式深度学习模型,并突破创造力、效率和多样性的界限。我们相信,生成式人工智能将成为所有未来技术的基本组成部分。通过向广大受众提供我们的模型,我们希望将其好处带给每个人,教育公众并增强对这些模型安全性的信任。我们决心为生成式媒体打造行业标准。今天,作为实现这一目标的第一步,我们发布了 FLUX.1 模型套件,推动了文本到图像合成的前沿发展。


The Black Forest Team
我们是一支由杰出的 AI 研究人员和工程师组成的团队,在学术、工业和开源环境中开发基础生成式 AI 模型方面拥有出色的业绩。我们的创新包括创建VQGAN和潜在扩散、用于图像和视频生成的稳定扩散模型(Stable Diffusion XL, Stable Video Diffusion, Rectified Flow Transformers)以及用于超快速实时图像合成的对抗扩散蒸馏Adversarial Diffusion Distillation-ADD。
我们的核心信念是,广泛使用的模型不仅能促进研究界和学术界的创新和合作,还能提高透明度,这对于信任和广泛采用至关重要。我们的团队致力于开发最高质量的技术,并让尽可能广泛的受众能够使用它。
资金来源
我们很高兴地宣布,我们成功完成了 3100 万美元的种子轮融资。本轮融资由我们的主要投资者Andreessen Horowitz领投,天使投资者Brendan Iribe、Michael Ovitz、Garry Tan、Timo Aila和Vladlen Koltun以及其他知名的人工智能研究和公司建设专家也参与其中。我们已收到来自General Catalyst和MätchVC的后续投资,以支持我们将欧洲最先进的人工智能带给全世界每个人的使命。
此外,我们很高兴地宣布我们的顾问委员会,包括在内容创作行业拥有丰富经验的Michael Ovitz ,以及神经风格转换的先驱和欧洲开放人工智能研究的领先专家Matthias Bethge 教授。
Flux.1 模型系列
 我们发布了 FLUX.1 文本到图像模型套件,为文本到图像合成定义了图像细节、及时遵守、风格多样性和场景复杂性的全新最先进水平。
我们发布了 FLUX.1 文本到图像模型套件,为文本到图像合成定义了图像细节、及时遵守、风格多样性和场景复杂性的全新最先进水平。
为了在可访问性和模型功能之间取得平衡,FLUX.1 有三种版本:FLUX.1 [pro]、FLUX.1 [dev] 和 FLUX.1 [schnell]:
-
FLUX.1 [pro]:FLUX.1 的最佳功能,提供最先进的性能图像生成,具有顶级的即时跟踪、视觉质量、图像细节和输出多样性。在此处通过我们的API注册以访问 FLUX.1 [pro] 。FLUX.1 [pro] 也可通过Replicate和fal.ai获得。
-
FLUX.1 [dev]:FLUX.1 [dev] 是一种开放权重、指导提炼的模型,适用于非商业应用。FLUX.1 [dev] 直接从 FLUX.1 [pro] 提炼而来,具有相似的质量和及时遵守能力,同时比同等大小的标准模型更高效。FLUX.1 [dev] 权重可在HuggingFace上使用,并可直接在Replicate或Fal.ai上试用。
-
FLUX.1 [schnell]:我们最快的模型是为本地开发和个人使用量身定制的。FLUX.1 [schnell] 在 Apache2.0 许可下公开可用。类似地,FLUX.1 [dev],权重可在 Hugging Face 上使用,推理代码可在GitHub和HuggingFace 的 Diffusers中找到。此外,我们很高兴在第一天就与ComfyUI集成。
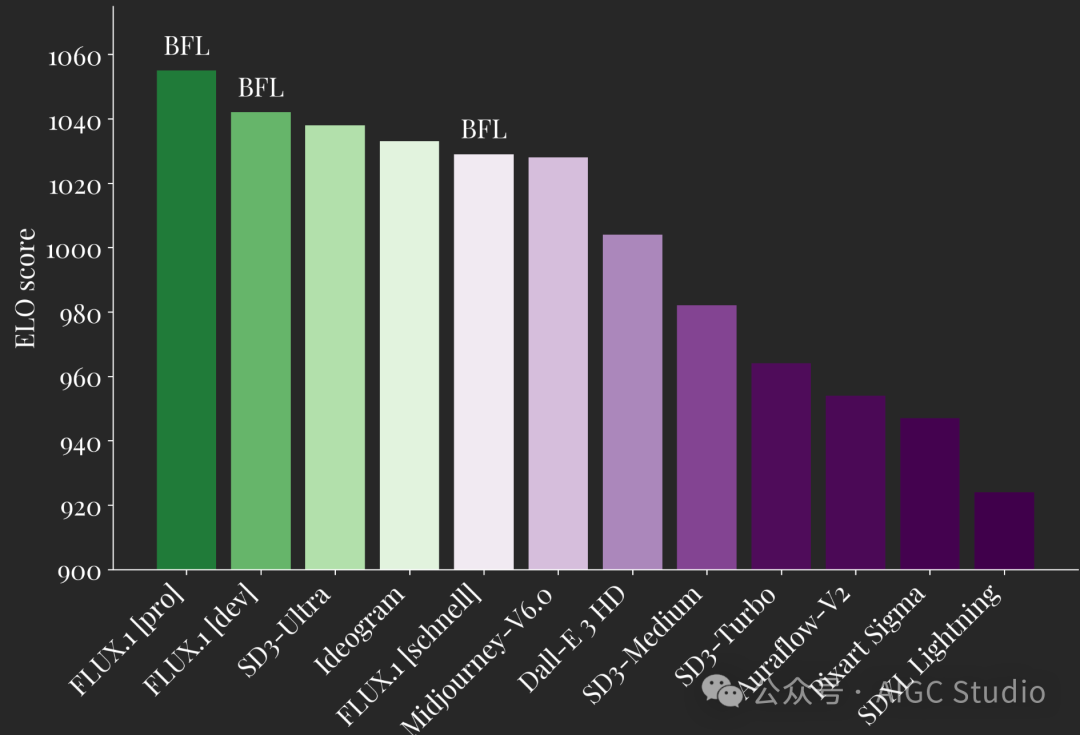
图像合成的新基准
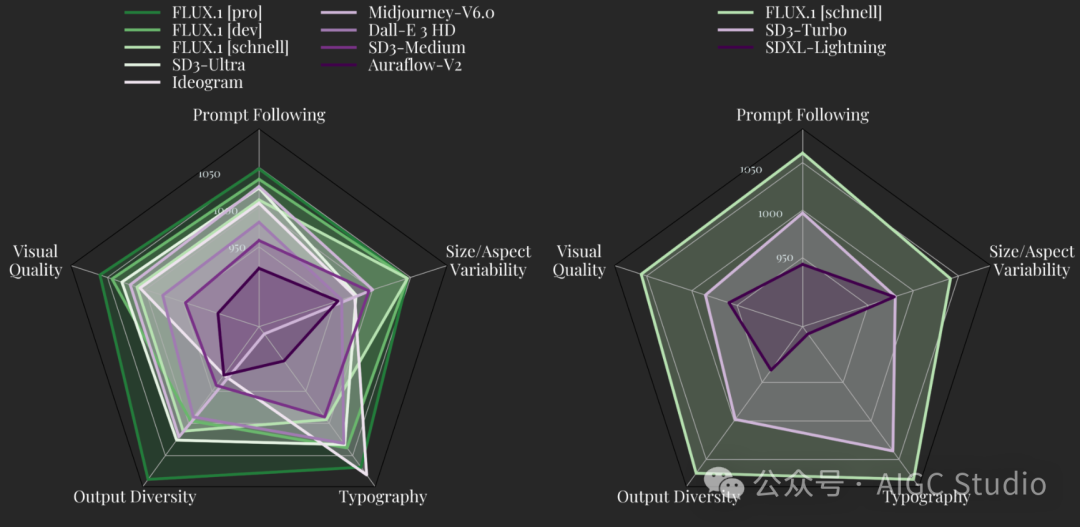
FLUX.1 定义了图像合成领域的最新技术。我们的模型在各自的模型类别中树立了新标准。FLUX.1 [pro] 和 [dev] 在以下每个方面都超越了 Midjourney v6.0、DALL·E 3 (HD) 和 SD3-Ultra 等热门模型:视觉质量、快速跟进、尺寸/长宽变化、排版和输出多样性。
FLUX.1 [schnell] 是迄今为止最先进的几步模型,其表现不仅优于同类竞争对手,还优于 Midjourney v6.0 和 DALL·E 3 (HD) 等强大的非蒸馏模型。我们的模型经过专门微调,以保留预训练的整个输出多样性。与目前最先进的技术相比,它们提供了显着改进的可能性,如下所示:
 所有 FLUX.1 型号变体均支持 0.1 和 2.0 mp像素的多种宽高比和分辨率,如下例所示。
所有 FLUX.1 型号变体均支持 0.1 和 2.0 mp像素的多种宽高比和分辨率,如下例所示。



这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









