






前言
回忆一下DDPM,实质上它的推导过程应是如下的:
其中, 是单纯的高斯分布的推导,相当于一个序列过程的归纳法推导。 在DDPM中采用的是[贝叶斯公式]。

而过程则是用对进行一个估测,也就是用前向过程反过来对进行一个估测。
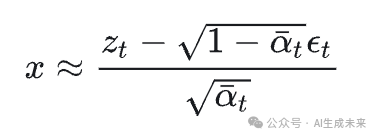
最后的训练和推理过程如下

这是根据生成模型的变分下限推导出来的,变分下限的第一项是diffusion正向过程自带完成的,第二项和第三项都可以用训练中对噪声的MSE来最小化从而实现生成模型对原真实数据分布的逼近。
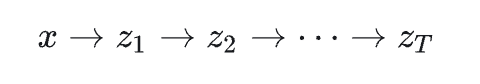
的马尔可夫性这一强假设。只是中间推导的时候用到了这个东西,也就是在 和的过程中用到了和马尔可夫性。那么我们想,是不是可以跳过这个模型和马尔可夫性的假设,也推导出。答案是可以。
只要
-
跳过 p(z_t|x)的推导,直接假设出p(z_t|x)$。
-
,不采用贝叶斯估计,也就没有的使用,而是用另一种方法去得到的描述即可。
那么为什么我们要这样做呢?这不是吃饱了撑着吗?原本的DDPM有什么问题呢?事实上就是,训练过程从0到T(一般T=1000),再从T去噪到0,其实我们可以忍受这么长的时间,毕竟是训练。但是对于推理,要从T 到0,如果采样数据(比如图片如果是高分辨率的)大一点,那么时间就会很长,在一些任务中,我们没有这么长的时间给模型去推理。所以如果能把马尔可夫性这个假设去掉,我们就可以在采样的时候进行跳步,比如T→T−20→T−40→⋯→20→0。这样相当于把时间缩短了20倍。因此,是十分有意义的工作。
回到前面,对于第一点,跳过 的推导,直接假设出 这个很简单,我们直接假设是一个高斯分布,即

好的,以下是您提供的内容,使用带有美元符号的 Markdown 格式表示其中的公式:
注意,这里的 和 DDPM 里面的没有任何关系,是一个新的独立符号,只是便于对照,写成一样的。它也不是 的累乘,而只是一个单纯的符号,因为这里我们没有对 进行任何的假设,也没有建模。
这个第一点是解决了,但是第二点就有点头疼了,一般看到这样的东西就是想用贝叶斯,把它从后验估计转化为先验估计来算。但是现在不行了,因为没有了 ,相当于假设给的更少了,约束少了,很自然我们知道,后续得到的这个结论“自由度”也会更高,更不确定(因为没有了马尔可夫性的约束)。
那么对于第二点,我们看看我们手上的工具,我们有了 , ,要得到 转化为 和 的形式,从而求出来。
结论是当然可以,可以写成联合分布积分求边际分布的形式
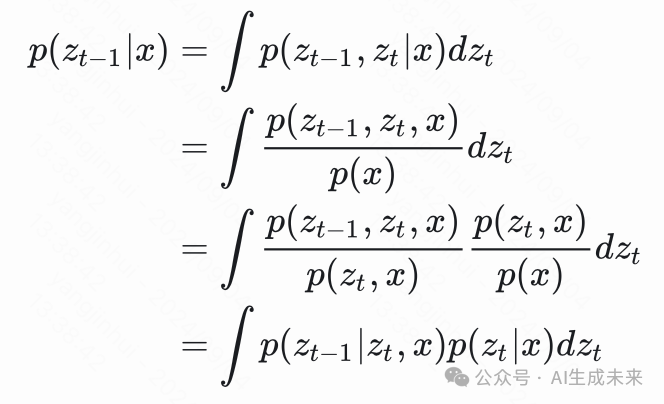
现在这个式子就写出来了,可以我们知道 和 ,又有一个这样的等式(虽然是个积分),可以把 给“逼”出来,约束出来,好像都不是很严谨的说法,就是算出来。
但是,如果单纯的这样算,这个 的形式可以是千奇百怪,我们必须给它一点约束假设,那就与 DDPM 一样,我们认为 也是一个高斯分布,即
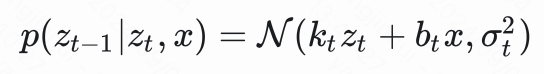
其中 是系数,为什么要这样假设,因为根据 DDPM, 也只有期望是与 有关的,这样才能用神经网络去拟合逼近,这是生成模型的一个特性。我们希望去学的也就是这个“重构”或者说生成的分布的期望。
对于 ,用高斯重采样可以看成
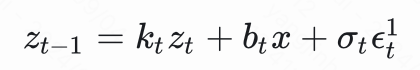
对于 和 可以看成

则 的重采样可以看成
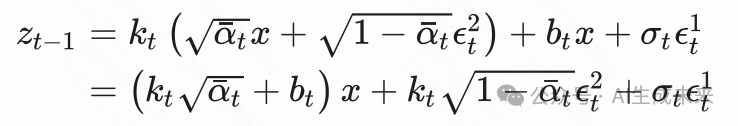 我们知道 ,,且两者独立,所以它们是独立同分布的,因此有
我们知道 ,,且两者独立,所以它们是独立同分布的,因此有
 所以有,
所以有, 对比上式与 的重采样,,因为有
对比上式与 的重采样,,因为有
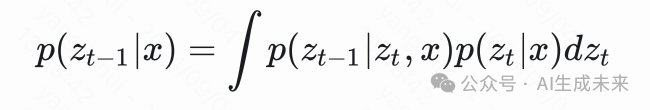 所以我们可以得到
所以我们可以得到

我们发现系数变量有三个 ,而约束等式只有两个,因此一定有一个自由变量。这也说明了,我们去掉了马尔可夫性这个约束后,得到的 一定有一个自由变量,即这个模型中的参数并不都是确定的。
我们将 作为那个自由变量,可以解得: 因此我们就得到了我们想要的
因此我们就得到了我们想要的
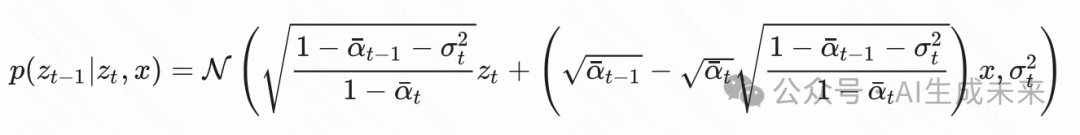 对比一下DDPM的
对比一下DDPM的
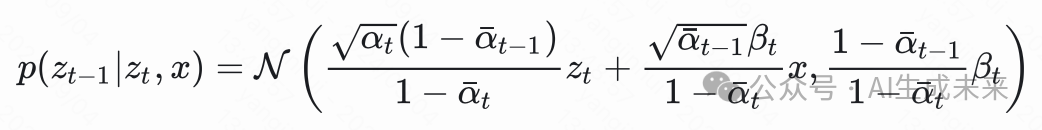
当我们把 带入 DDIM 得到的式子中,我们会发现 DDIM 的 和 DDPM 的 是一样的。
补充:这里我们可以定义一下, 。
这里说明了 DDPM 中的 和马尔可夫性给 带来的约束条件就是但是反过来,我们令 DDIM 中的 并不能得到
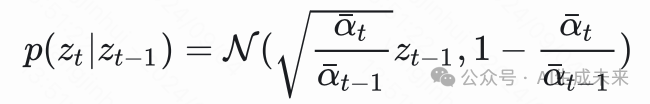 这样的结论。因为我们前面的推导中根本没有定义 这样的东西,而且这个 和 DDPM 里面的根本不是同一个东西。
这样的结论。因为我们前面的推导中根本没有定义 这样的东西,而且这个 和 DDPM 里面的根本不是同一个东西。
我们现在有了 ,那么还是和 DDPM 一样,我们希望的是 ,我们用 的反向来估计一下 x,从而得到 。
 则有
则有
 代入
代入
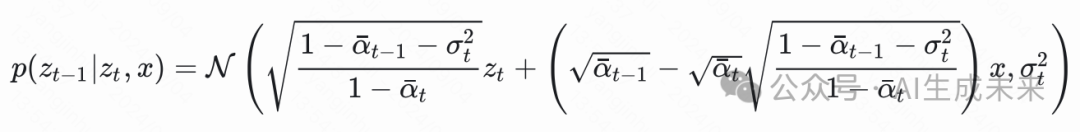 中,则得到
中,则得到
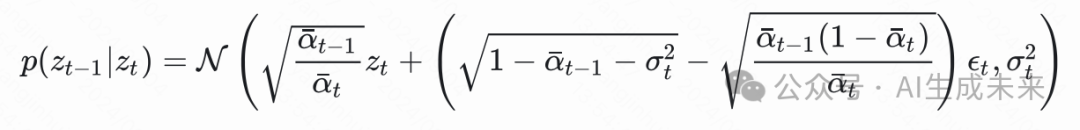 那么我们希望优化的目标是
那么我们希望优化的目标是

其中我们定义神经网络拟合的 为
 根据公式:
根据公式:
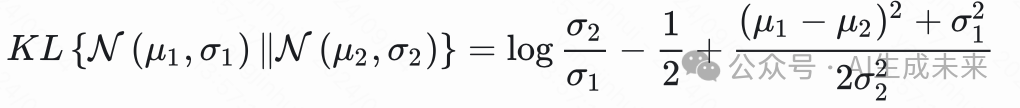 则有
则有 这就是DDIM训练的时候用的损失函数。
这就是DDIM训练的时候用的损失函数。
讨论一下 的选取。
前面讨论过,如果 则就与 DDPM 的损失函数和形式一样了。而如果我们令 这就有意思了,此时 就是一个确定性的过程,这时候这个模型就称为 DDIM(前面说的这些都是一个一般形式的模型,当 时,模型就是 DDIM;当 时,模型就是 DDPM)。
讨论一下加速采样过程
此时得到的
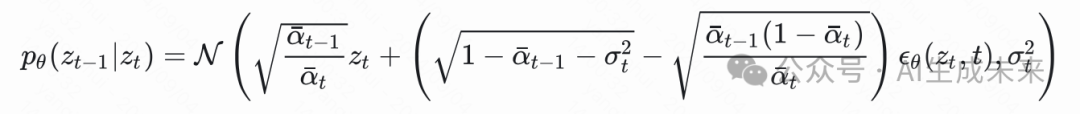
不是依赖马尔可夫性,所以可以跳步向前采样,
则此时采样变成了
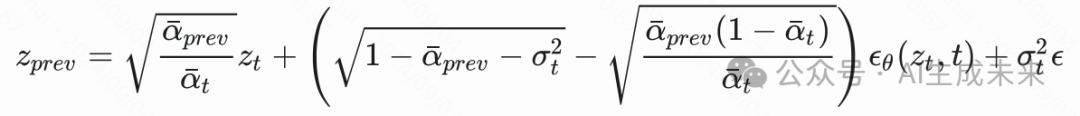
这里的 和 之间可以间隔很多步,比如 20、50 等。
最后作者经过实验发现,减小采样步数可以加速生成,使图片更加平滑,但会损失多样性;而减小 能增加多样性。因此,在减少采样步数的同时,应适当减小 的值,以保证图片生成质量。反过来想,如果在采样步数少的情况下还增大 ,增加了噪声的影响,那么生成的质量可能也会不尽人意。
这一点有些反直觉,减小 反而能增加多样性,但确实如此。采样步数的设计和 的选取是 DDIM 设计中非常重要的超参数,需要仔细设计。
这个DDIM的推导主要是建立一种更一般的框架,通过选择合适的,得到了DDPM和DDIM模型,同时还把推理采样的速度提升了,是diffusion model中非常重要的一步。
这里分享给大家一份Adobe大神整理的《AIGC全家桶学习笔记》,相信大家会对AIGC有着更深入、更系统的理解。
有需要的朋友,可以点击下方免费领取!

AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC

有需要的朋友,可以点击下方卡片免费领取!

精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。
AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









