






前言
大家好,我是每天分享AI应用的萤火君!
在AI绘画领域,Stable Diffusion 因其开源特性而受到广泛的关注和支持,背后聚拢了一大批的应用开发者和艺术创作者,是AI绘画领域当之无愧的王者。
目前使用 Stable Diffusion 进行创作的工具主要有两个:Stable Diffusion WebUI 和 ComfyUI。
Stable Diffusion WebUI 我之前介绍过很多,这里就不赘述了,用兴趣的同学可以去这里看看:[Stable Diffusion WebUI 教程合集]
ComfyUI 虽然出来的晚一点,但是它的可定制性很强,可以让创作者搞出各种新奇的玩意,通过工作流的方式,也可以实现更高的自动化水平,发展势头特别迅猛,但是 ComyUI 的上手门槛有点高,对 Stable Diffusion 以及各种扩展能力的原理需要有一定的理解,动手能力要求也比较高。
但是但是从解放生产力以及工业化批量生产的角度看,ComfyUI 具备更广阔的应用前景,因此从这篇文章开始,我将开始介绍一些 ComfyUI 的概念和使用方法,让大家更快的掌握 ComfyUI 的使用技巧,创作出自己独特的艺术作品。
所有的AI设计工具,安装包、模型和插件,都已经整理好了,👇获取~
安装部署
安装部署已经在之前的文章介绍过,点击进入:[ComfyUI 完全入门:安装部署]
使用ComfyUI
ComfyUI 的使用界面就是一个工作流配置面板,ComfyUI 将图片生成任务分成了多个步骤,这些步骤串起来就是一个工作流。在 ComfyUI 的侧边有一个浮动的管理菜单,可以做一些基础的管理操作。
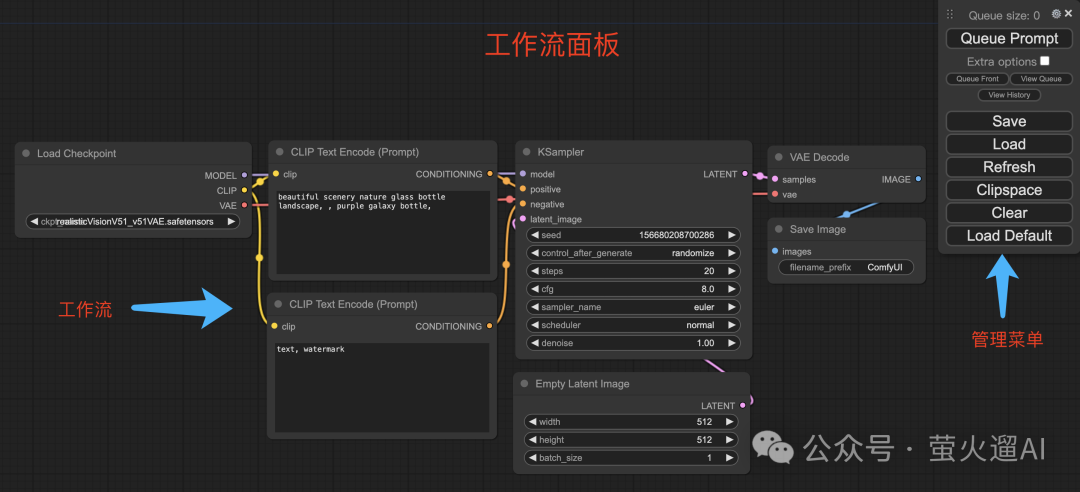
管理菜单
我们先看一下侧边栏的管理菜单,这里我对相关操作都做了一个标注,再重点说下常用的几个:
Queue Prompt:将当前工作流加入队列,也就是执行当前工作流,开始生成图片、视频等。
Save:保存工作流,可以将当前工作流以Json格式保存到本地电脑,方便以后使用或者分享给别的用户。
Load:从本地电脑选择带有工作流的图片或者Json格式的工作流文件,加载工作流信息,并作为当前工作流进行展示。
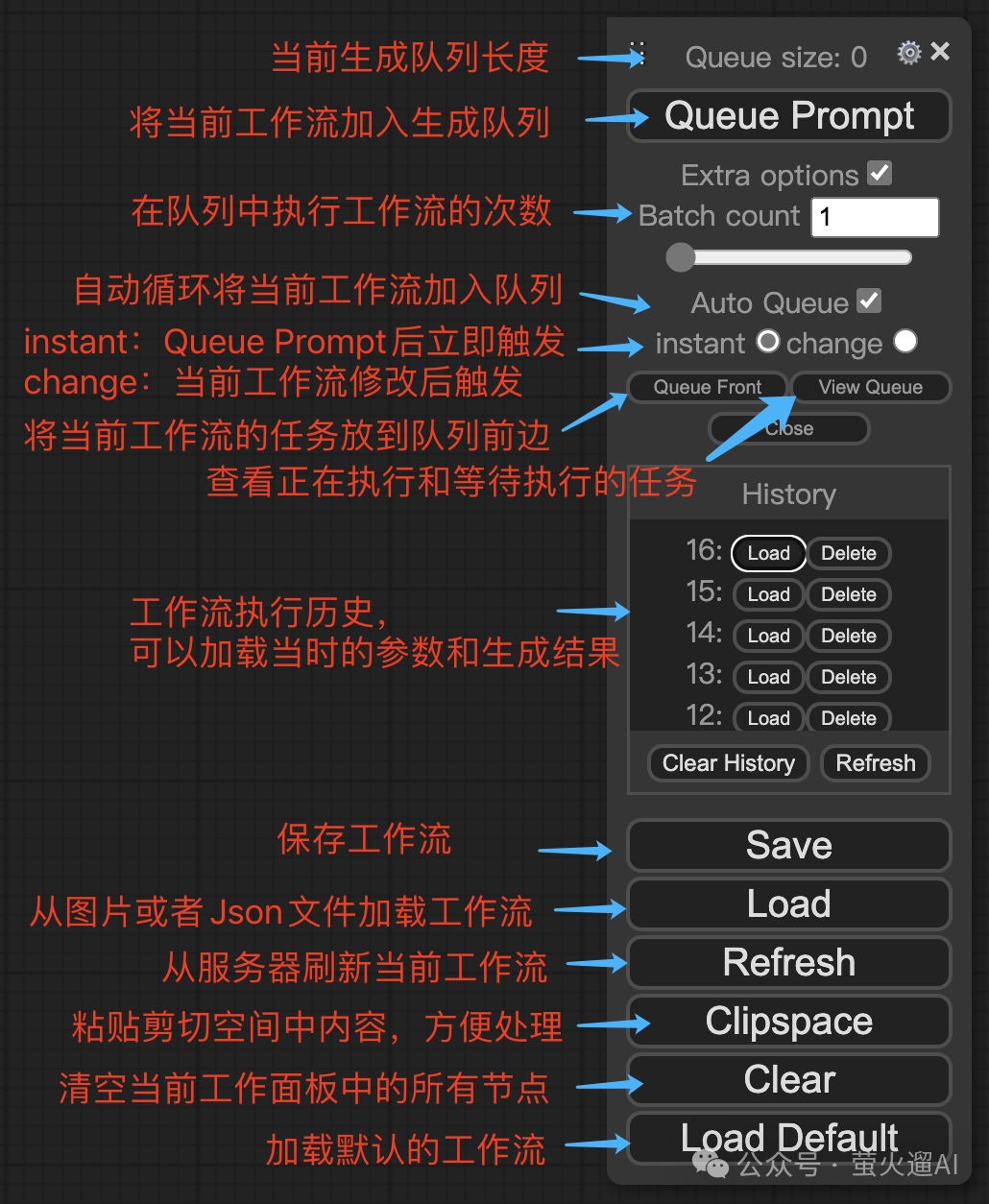
工作流
工作流是由一个个操作节点连接起来的,每个节点会完成一个独立的操作,比如加载模型、编码提示词等,上游节点的输出会作为下游节点的输入,直到最后一个节点输出最终的内容。节点的输入除了来自上游节点的输出,还有一些来自用户的输入,节点可能会包含一些输入框或者选择框,比如SD基础模型选择框、提示词输入框等等。
ComfyUI 默认会加载一个简单的工作流,这是一个最基础的工作流,可以让我们清晰的了解工作流的组织方式和图片的生成过程。我将按照从左到右的顺序进行介绍:
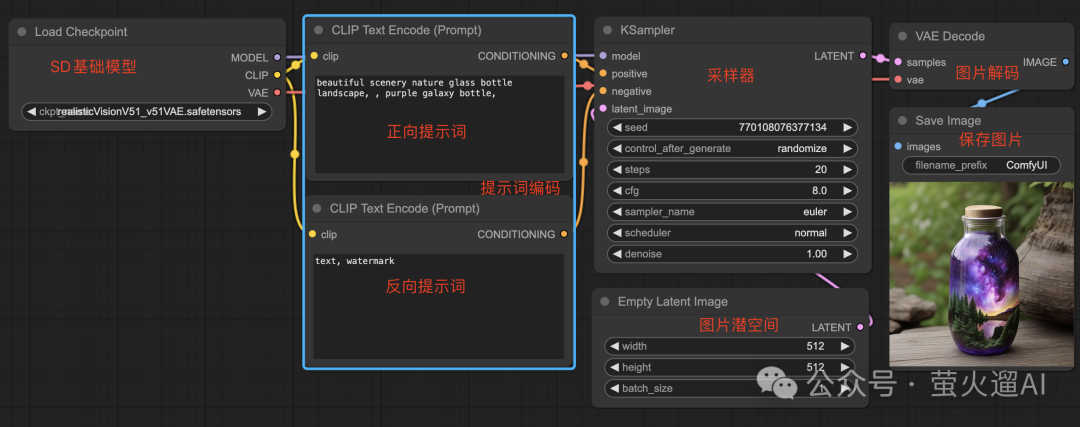
Load Checkpoint:这个节点用来加载 Stable Diffusion 基础模型,基础模型是生成图片必需的,不同的基础模型可能擅长生成不同事物或者风格的图片,比如这里的 realisticVisionV51_v51VAE 擅长生成真实视觉图像。国内用户可以在 https://liblib.art 下载自己喜欢或者需要的基础模型。
这个节点有三个输出:MODEL、CLIP和VAE,MODEL就是从硬盘加载到的SD基础模型,用于后续采样处理,CLIP是文本到图像的映射模型,用来编码文本提示词,VAE是图像数据解码器,用于最终生成可见的图像。
CLIP Text Encode(Prompt):文本编码器。目前人工智能的背后就是大量的向量计算,文本编码器就是把文字转换成向量,然后再进行各种复杂的运算。这里有两个文本编码器,分别对应正向提示词和反向提示词,它们都有一个clip输入,接收 Load Checkpoint 节点从SD基础模型中提取出的CLIP模型,用于编码提示词。编码后的内容会作为采样器的采样条件。同一个词语在不同的SD基础模型中可能对应到不同的向量数据,因此CLIP模型是从SD基础模型中提取出来的。
KSampler:K采样器。这是生成图片的核心组件,主要用来实现SD模型的反向扩散过程,反向扩散是从一张完全噪音图(电视没有信号的画面)开始,通过采样逐步去除噪音,最终生成图片的过程。这个节点有很多参数,也就是有很多输入,其中:
-
model 来自Load Checkpoint节点输出的MODEL,也就是SD基础模型,采样将在这个模型上进行;
-
positive 来自正向提示词编码器,向量数据格式,采样时将以此为条件,尽量保留和此向量接近的噪音数据;
-
negative 来自反向提示词编码器,向量数据格式,采样时将以此为条件,尽量去除和此向量接近的噪音数据;
-
latent_image 是一个空的图像空间,用于在其中存储生成的图片数据,它来自于 Empty Latent Image 节点,这个节点提供指定宽高和数量的空图像空间。之所以用Latent这个词,是因为采样产生的图像数据还不是真正的图像格式,是一种图片数据的压缩格式,称为潜空间图像。
-
seed 是生成图片的种子,每次使用不同的种子就会引入不同的随机特征,同样的参数就可以生成主题相同但变化无穷的图像。使用完全相同的参数和种子将生成完全相同的图像。
-
steps 采样步数,根据使用的SD基础模型和采样方法,这个数值可能需要进行调整,一般是20-30步。一些快速出图模型,可能只需要1-8步,比如LCM、Turbo、Lightning等模型。
-
cfg 无分类器指导尺度,无分类器就是仅依靠文本提示词,指导尺度就是控制文本提示对图像生成的影响力。值越大,生成的图像越贴合提示词,值越小自由发挥的越多。一般使用6-8,具体最优值取决于使用的SD模型和个人偏好。
-
sampler_name 采样器,反向扩散时去除噪音的方法,不同的方法对速度和质量会有不同的影响。默认选择的是 euler,兼顾了生成图片的质量和速度,质量要求高时建议选择 dpmpp 类的采样器。关于采样器,我这里有一篇详细介绍,感兴趣的同学可以去看看:https://xiaobot.net/post/055d0d28-51f4-462b-9224-a0faf139ff46
-
scheduler 采样调度器。控制在整个采样过程的时间线上每一步降噪的幅度。如果对默认的调度器不满意,可以试试 karras,它可以让生成获得更高的采样效率和图片质量。
-
denoise 去噪幅度,最大1.0。越高的值代表初始噪音保留的越少,图像特征越清晰;越低的值代表初始噪音保留的较多,图像更抽象或者有某种艺术效果。生成图片时要一起考虑提示词、图像尺寸、采样策略等因素的影响。
VAE Decode:采样器生成的图片数据是一种特殊的压缩格式,和真正的图片数据格式不同,要获取真正的图片数据,我们还需要VAE解码。
-
VAE解码需要使用一个VAE模型,VAE模型一般包含在SD基础模型中(这里的例子中就是如此),也可以使用单独的VAE模型。这个节点的vae输入需要的就是VAE模型。
-
另外这个节点还需要输入待解码的数据,也就是采样器的输出 LATENT 连接到本节点的 samples 输入上。
Save Image:保存图片并展示。这个节点会将图片保存到硬盘中,默认是:ComfyUi/output。节点有一个filename_prefix的参数,代表保存图片路径的前缀,可以在其中包含目录,比如 simple/test,就会保存到 simple 目录中,以 test 为图片文件名的前缀。
添加节点
默认的工作流是一个最简单的文生图工作流,如果你要使用图生图、或者ControlNet,还需要引入更多个节点。
添加节点有两种方式:
在 ComfyUI 操作界面的空白处,点击鼠标右键,在弹出的菜单中点击 Add Node,这里有一些内置的节点分类,比如采样、加载器、潜空间、图片等等,可以根据需要一层层查找。
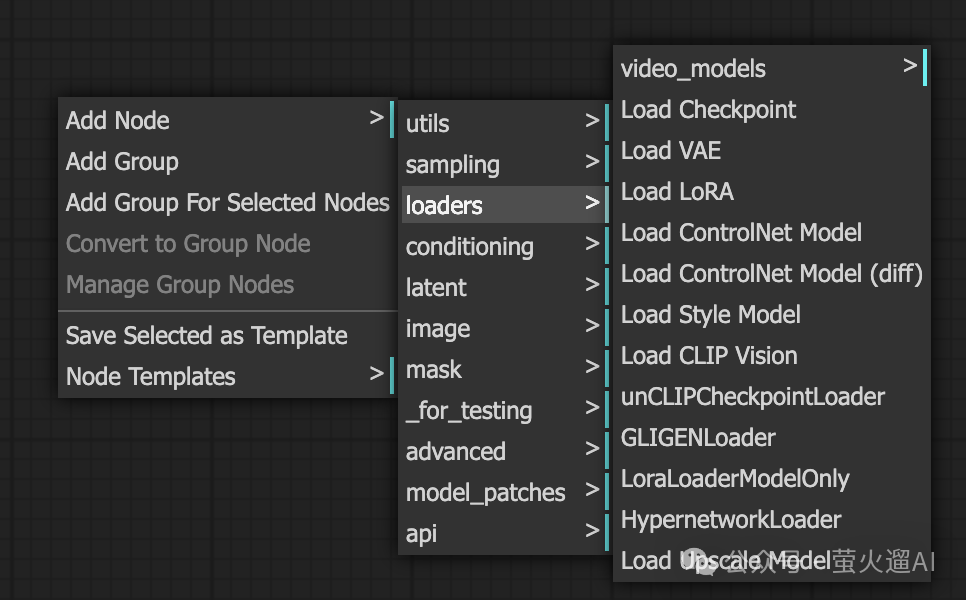
如果你对节点比较熟悉,可以在 ComfyUI 操作界面的空白处双击左键,在弹出的搜索框中,填入关键词进行搜索,点击对应的结果即可添加节点到工作流面板。
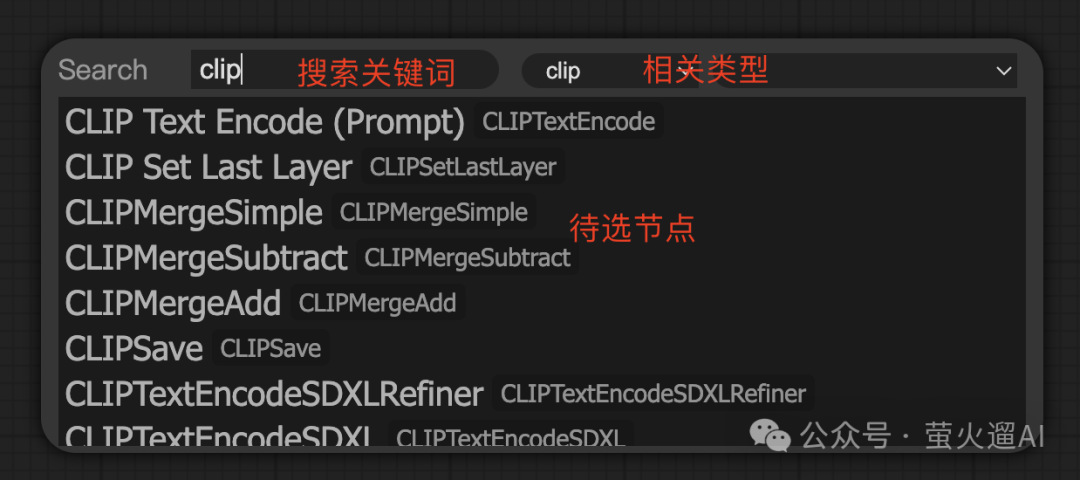
怎么将新加入的节点添加到工作流?
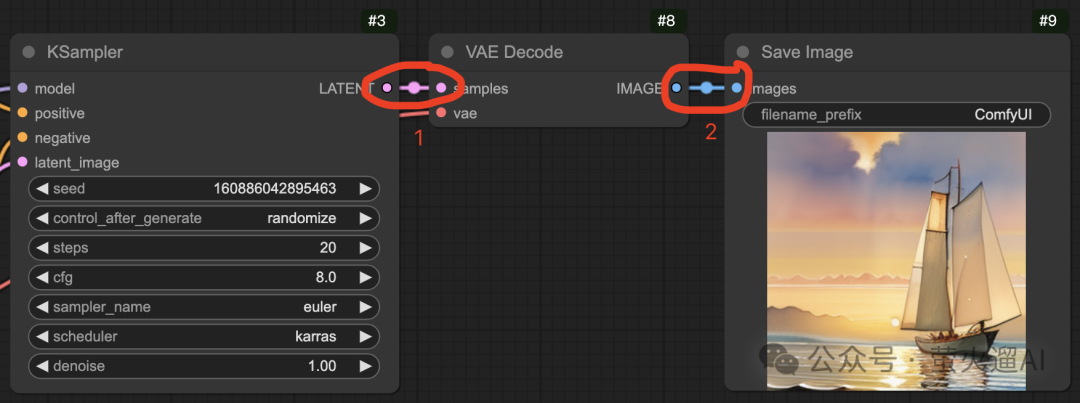
你需要根据需求,将新节点的输出连接到其它节点的输入,或者将其它节点的输出连接到新节点的输入。连接方法就是在一个节点的输出项上点击鼠标左键,然后拖动到另一个节点的输入项上。针对某个节点,其输入项一般在节点的左侧,输出项一般在节点的右侧。
比如下图中的 VAE Decode 节点,其输入项 samples 连接到 KSampler 节点的输出项 LATENT,输出项 IMAGE 连接到 Save Image 节点的输入项 Images。
怎么将手动输入转换成其它节点输入?
有些节点的参数默认是手动输入的,你可能想从其它的节点自动填入这个参数,或者想和其它的节点共享一个参数值,这时候我们就可以把这个输入框转换为外部输入。比如这个提示词的节点,在节点上点击右键,在弹出的菜单中点击“Convert input to …”,即可选择把某些参数转换为外部输入项,能够将其它节点的输出项连接到这个输入项。注意输入和输出的数据格式必须匹配才能连接。

用好ComfyUI
用好 ComfyUI:
-
首先需要对 Stable Diffusion 的基本概念有清晰的理解,熟悉 ComfyUI 的基本使用方式;
-
然后需要在实践过程中不断尝试、不断加深理解,逐步掌握各类节点的能力和使用方法,提升综合运用各类节点进行创作的能力。
我将在后续文章中持续输出 ComfyUI 的相关知识和热门作品的工作流,帮助大家更快的掌握 ComfyUI,创作出满足自己需求的高质量作品。
考虑到多平台发布存在延迟,文章将首先发布在我的公众号“萤火遛AI”,欢迎关注,以免错过重要信息。
另外我在AutoDL云平台上也发布了一个 ComfyUI 的镜像,你可以跳过繁琐的安装过程,还可以直接使用 AutoDL 提供的各种显卡设备,镜像已经内置了常用的工作流和基础模型,助你快速开启自己的 ComfyUI 之旅。镜像地址:https://www.codewithgpu.com/i/comfyanonymous/ComfyUI/yinghuoai-ComfyUI,进入后点击页面右下角的“AutoDL创建实例”即可使用镜像。
这里分享给大家一份Adobe大神整理的《AIGC全家桶学习笔记》,相信大家会对AIGC有着更深入、更系统的理解。
有需要的朋友,可以点击下方免费领取!

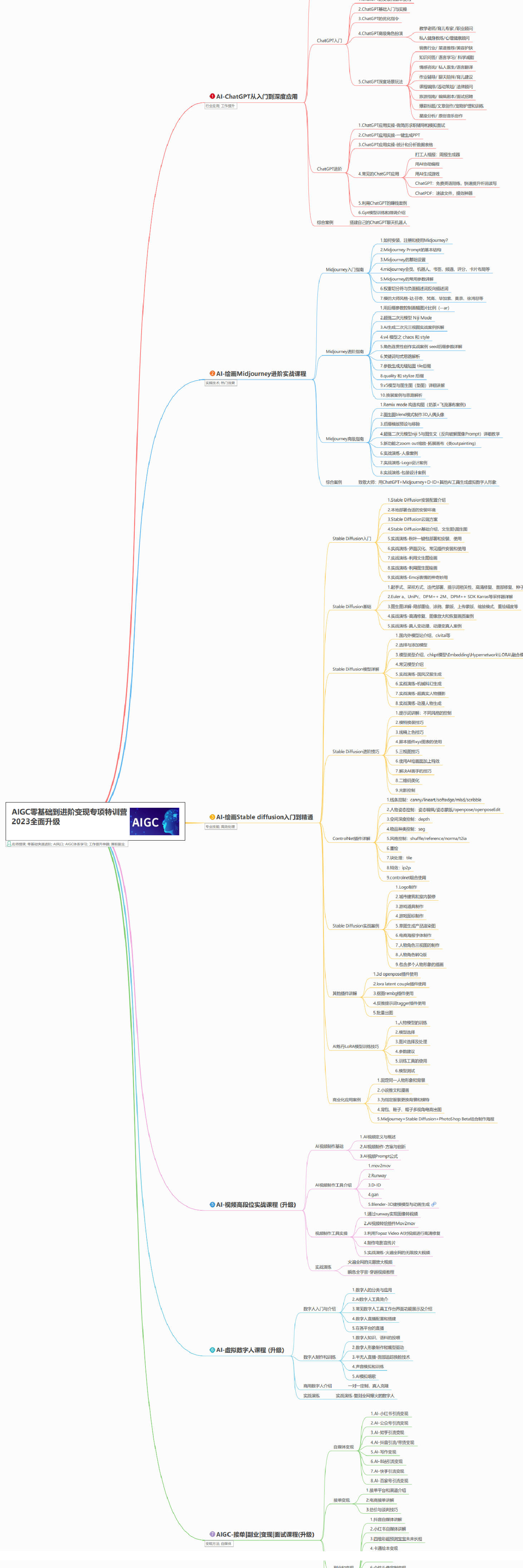
AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC

有需要的朋友,可以点击下方卡片免费领取!

精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。
AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。
















 4413
4413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









