






前言
稳定扩散基础
学习ComfyUI应该先从理论入手。
AI绘画工具与传统绘画工具(如Photoshop或Figma)最大的区别在于,它的许多配置或操作不是可视化的,且结果具有随机性。前者意味着当你修改某个配置时,界面不一定会有反应,这使得自学变得困难;不像Figma能自主探索。后者会让你产生挫败感,即使完全按照教程操作也可能得不到相同结果。
所有的AI设计工具,安装包、模型和插件,都已经整理好了,👇获取~
如何解决这些问题?
我认为学习这类工具的第一步不是学习如何使用,而是从AI相关理论开始。理解理论后,你就能明白绘图工具中的配置选项用途,甚至举一反三。
因此,本系列教程将从稳定扩散的基础知识开始。掌握基本概念后,再介绍如何使用ComfyUI,这样你就能理解其表象与本质。
什么是稳定扩散? 教程中会看到高亮内容(如潜在空间),这些可能在后续教程或ComfyUI中出现,需特别注意。
为降低理解成本,我将尽量减少数学内容,多用类比帮助理解概念。部分描述可能不够严谨,欢迎留言指正或加入社区讨论。
严格来说,稳定扩散是由多个组件(模型)构成的系统,而非单一模型。我将以最常见的文生图工作流为例,解析其整体架构和工作原理。
当输入提示词"猫站在城堡上"时,稳定扩散会生成对应图片。看似一步完成:
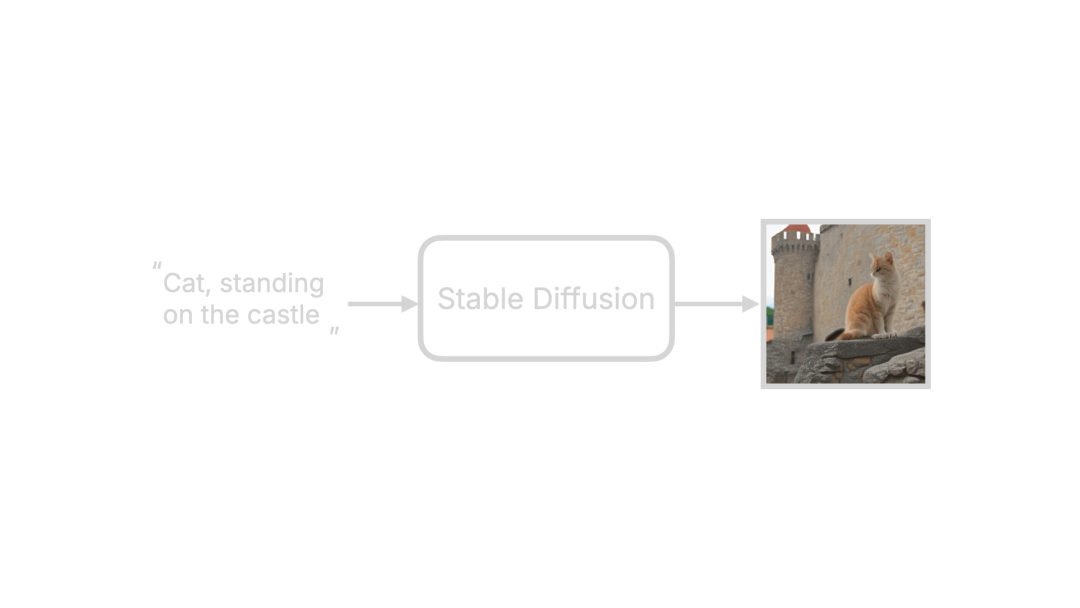
实际上生成过程分为三大步骤。先概述这三个步骤,建立整体认知,再深入细节:
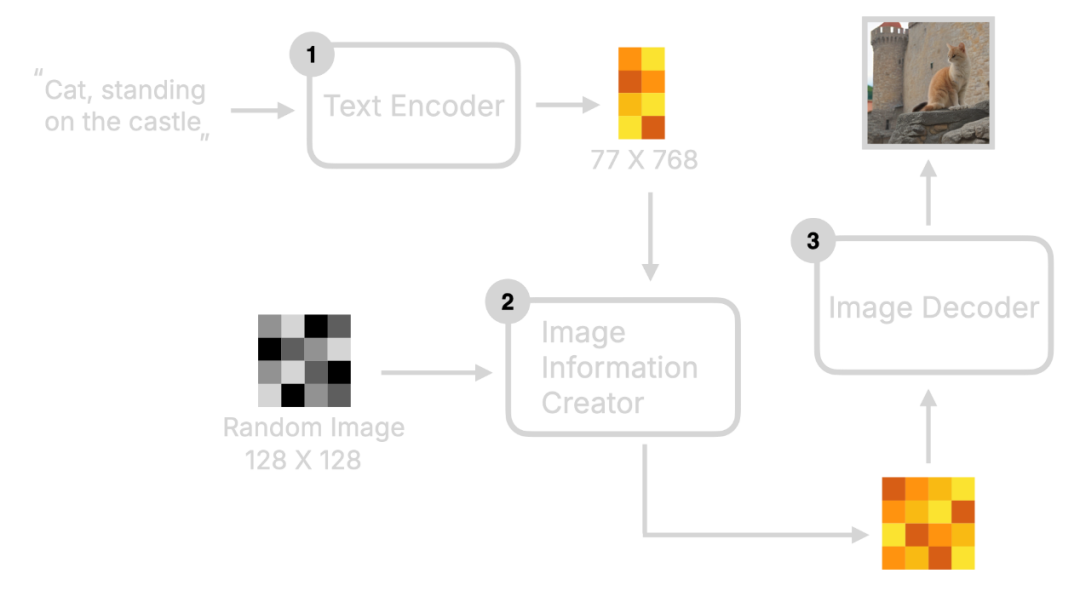
1.用户输入的提示词通过文本编码器编译为单词特征向量,输出77个等长向量(每个768维)。可暂时理解为"将文本转换为机器可识别的数字组合"。
2.这些特征向量与随机图像(类似布满噪点的图片)进入图像信息生成器。机器先将它们转换为潜在空间,再根据特征向量对随机图像"去噪"生成"中间产物"。此时中间产物是人类无法理解的数字集合,但已包含猫站城堡的信息。
3.图像解码器将中间产物解码为真实图片。
整个过程可视化如下:
简言之,用户输入指令后,机器会在潜在空间中将随机图像去噪为符合指令的图片。AI更像在"雕刻"而非生成图像,正如米开朗基罗完成大卫雕像时的感悟:雕像本就在石头中,我只是去除多余部分。
所有图像都存在于充满噪声的图片里,AI只是去除冗余。使用基于扩散模型的Midjourney时,你会看到图像从模糊逐步变清晰的过程,这正是"去噪雕刻"的体现:
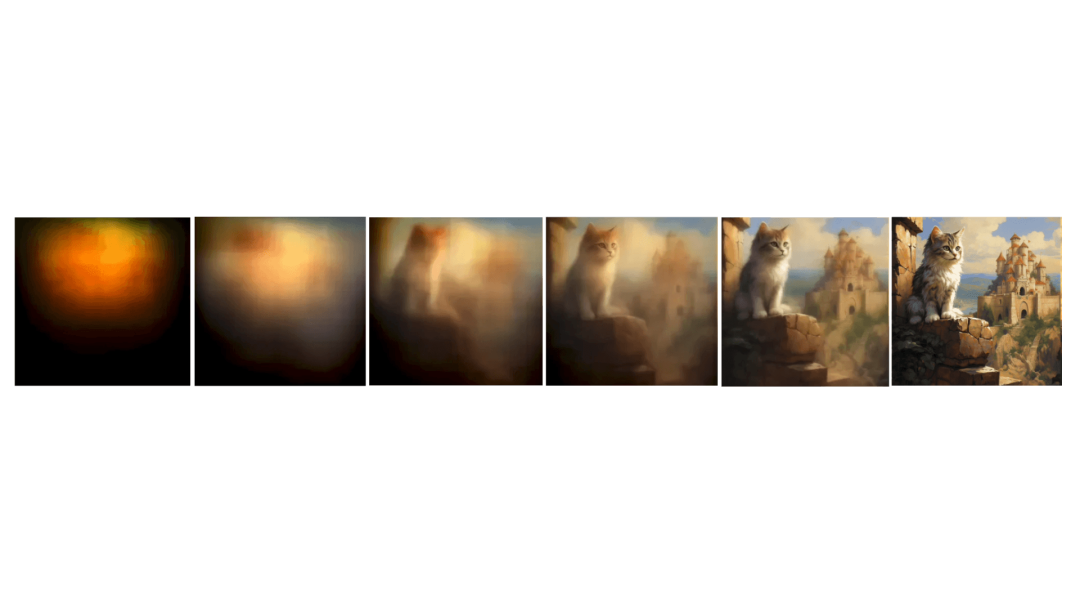
稳定扩散之所以直接输出结果,是因为其仅在第二步多次去噪,最终才解码成图,故不显示中间过程。
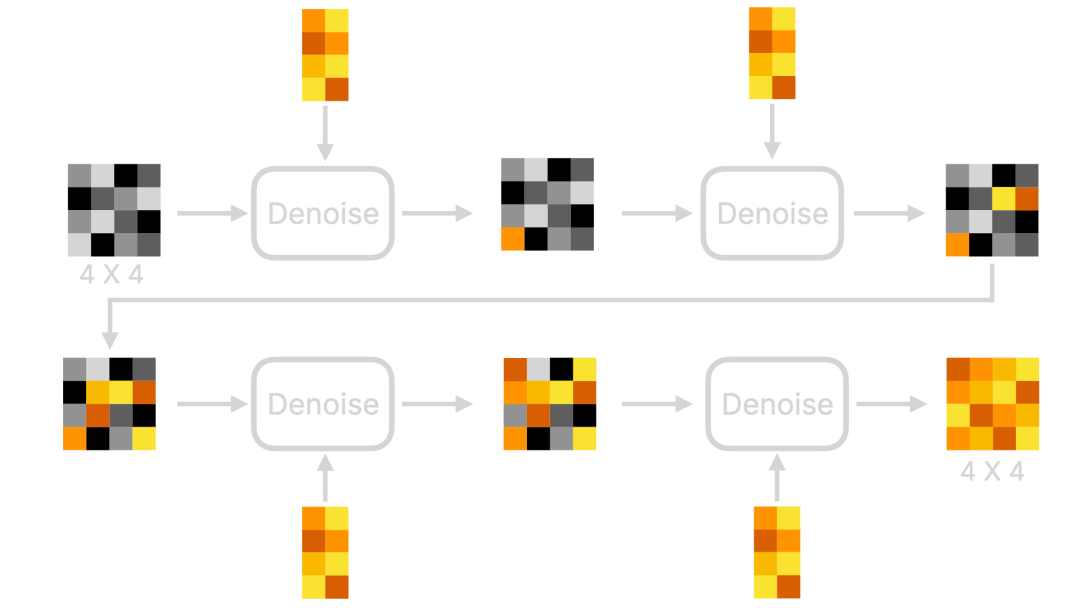
图像信息生成器 既然我们在谈论去噪,让我们扩展一下整个“去噪”过程。
首先,整个去噪过程将在潜在空间(Latent Space)中进行,并且会有多个去噪步骤(Steps)。你可以调整这些步骤的数量;通常,步骤越多,图像质量越好,但所需时间也会越长。当然,这也取决于模型。比如,Stable Diffusion XL Turbo可以在一步内生成图像,用时不到一秒钟,且图像质量相当不错。如果我们将这个步骤可视化,它看起来是这样的(为更好地解释,我将下面的黑色块描述为图像,但它们本质上不是图像,只是一堆与图像相关的数据):
所以在去噪过程中会发生什么?下面的图像是第一次去噪过程的可视化:
前面的图像可能看起来很复杂,但没必要害怕。只要我们理解加减乘除等基本操作,就能理解去噪的每一步。
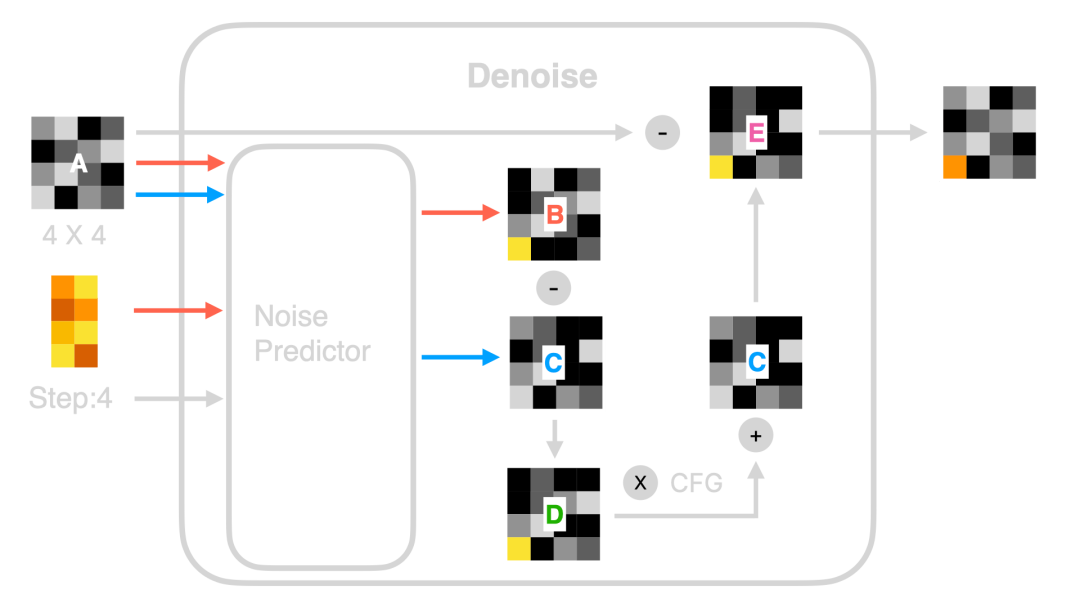
- 首先,去噪过程中有一个噪声预测器(Noise Predictor)。顾名思义,它是一个预测随机图像中噪声的模型。除了输入随机图像和提示(Prompt)的词特征向量,还需要当前的步骤(Step)编号。尽管在上述可视化过程中你会看到很多去噪步骤,但实际程序运行的是相同的去噪步骤,因此有必要通知噪声预测器当前的步骤以进行计算。 - 接下来,我们看一下橙色线条。噪声预测器使用随机图像(例如一个4x4的图像)和提示的词特征向量来预测噪声图像B。请注意,它并不是预测和输出实际图像,而是一个噪声图像。换句话说,噪声预测器基于词向量预测这个随机图像中有哪些不必要的噪声。如果用之前雕刻的例子类比,它输出的是雕像雕刻不需要的废料。同时,噪声预测器在不使用提示的词特征向量的情况下也预测一个噪声图像C(图中的蓝色线条)。
💡你可能会好奇为什么我强调4x4。回顾整个去噪过程,你会发现最初的随机图像是4x4,结果也是4x4。这意味着,如果你想改变最终图像的比例或大小,需要调整随机图像的比例或大小,而不是通过提示命令。用雕刻作比,无论雕刻家多么巧妙,他无法用一立方米的石头雕刻出十米高的雕像。雕刻出的最高雕像是一米高。
- 然后,去噪将噪声图C从噪声图B中减去,得到图D。我们可以用数学来简化这个过程。图B是基于提示和随机图像预测的噪声,包含了“基于提示预测的噪声”和“基于随机图像预测的噪声”。C代表“基于随机图像预测的噪声”。因此,B减C等于“基于提示预测的噪声”。
- 接下来,去噪放大噪声图C,通常是通过乘以一个系数来实现的。这个系数常常在一些Stable Diffusion实现中表示为CFG, CFG Scale或Guidance Scale。然后,将这个放大的图像加到噪声图C中,形成图E。这样做的原因是提高图像生成的准确性。这样,基于提示预测的噪声被通过乘以一个因子刻意强调了。如果没有这一步,生成的图像与提示的关联度就不会那么高。这种方法也被称为无分类器引导(Classifier Free Guidance)。
- 最后,去噪将图E从图A中减去,以得到一个新图像。这是前面提到的“雕刻”过程,其中不必要的噪声被消除了。
图像解码器
现在让我们来谈谈潜在空间(Latent Space)。当我在研究这个概念时,我最大的疑问是,为什么要在潜在空间中操作,而不是直接对图像进行去噪处理? 要回答这个问题,我们首先必须了解什么是潜在空间。 在机器学习和深度学习领域,潜在空间是用于表示数据的低维空间。潜在空间通过对原始数据的编码(Encoding)和降维处理(Dimension Reduction)创建,结果是一组潜在变量。潜在空间的维度通常低于原始数据的维度,使我们能够从数据中提取最关键的特征和结构。 听起来很复杂,但简单来说,潜在空间就是将图像编码为一组数字并压缩这些数字。
让我们来可视化这个过程:
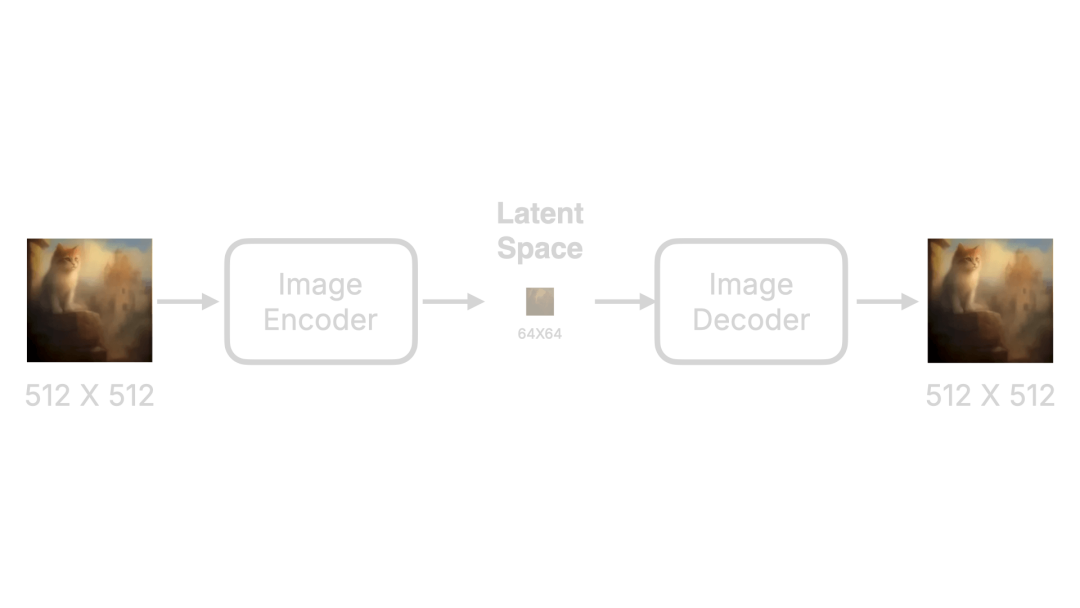
图像首先由图像编码器(Image Encoder)编码为一组数据,然后进行压缩。如果我们从像素的角度衡量这种数据压缩的效果,原始的512x512图像可能会被压缩到64x64,从而极大地减少数据量。最后,图像解码器(Image Decoder)会将其还原。这种编码器和解码器组件也称为变分自编码器(Variational Auto Encoder,VAE)。因此,在某些产品中,图像解码器也被称为VAE解码器(VAE Decoder)。 那么,使用这种技术的优点和缺点是什么呢?
**优点**:
- 首先,效率显著提高。使用VAE,即使是消费级GPU也可以以相对较高的速度执行去噪计算,同时训练模型的时间也会缩短。
- 此外,潜在空间的维度通常比原始图像的维度低得多,这意味着它可以更有效地表示图像的特征。通过在潜在空间中操作和插值,可以更精细地控制和编辑图像。这使得在生成过程中对图像的细节和风格有更好的掌控,从而提高生成图像的质量和现实感。
**缺点**:
- 编码然后还原数据会导致一些数据丢失。而且,由于潜在空间的维度较低,可能无法完全捕捉到原始数据的所有细节和特征。这最终可能导致还原的图像看起来有些奇怪。
💡 为什么Stable Diffusion生成的图像中的文字经常看起来很奇怪?一个原因是,部分文字的细节特征在这个过程中丢失了。另外,预测噪声时,文本预测不像图像预测那样连贯。例如,预测猫的特征相对简单,因为猫可能有两只眼睛,眼睛下方是鼻子,这是连贯的。但英语单词"Cat"和汉字"猫"则差别很大,难以预测。比如,汉字可能由横、竖、钩、撇、捺组成,但撇后面是什么呢?
文本编码器
在初始过程中,我提到过文本编码器会将你的输入提示(Prompt)翻译成单个词的特征向量。这个步骤输出77个等长的向量,每个向量包含768个维度。这些向量的作用是什么呢? 接下来,有一个更有趣的问题。当我们在提示中仅输入"Cat",而没有添加"orange"时,为什么最终生成的猫会是橙色的?要回答这些问题,我们需要首先了解文本编码器的实现。 目前在Stable Diffusion中流行的文本编码器是CLIP模型,它代表对比语言图像预训练(Contrastive Language Image Pre-training)。让我们绘制一张图:
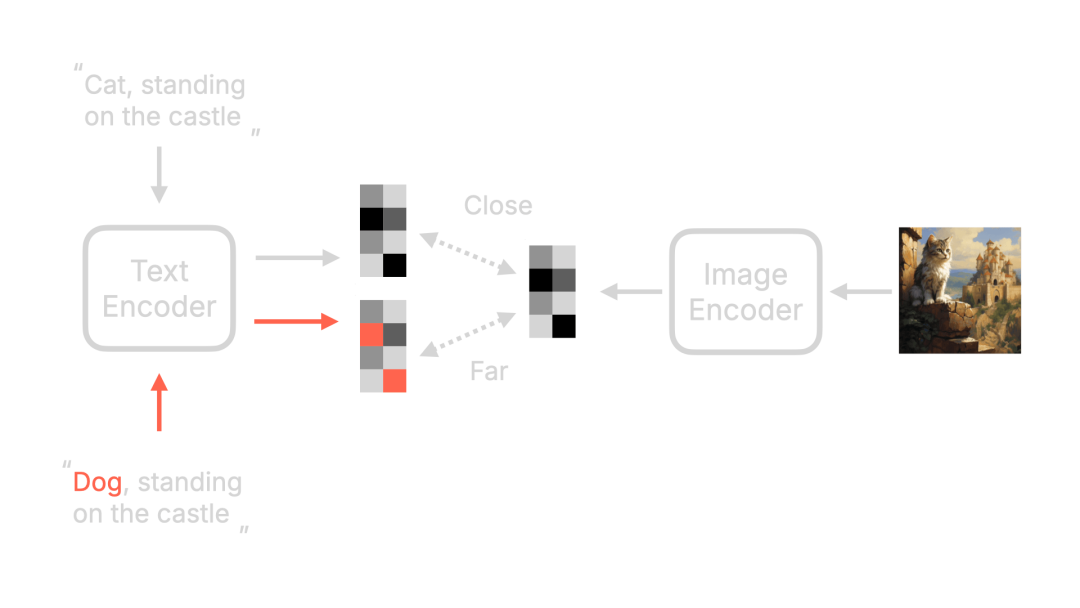
首先,这个CLIP也有一个文本编码器,可以将文本转换成特征向量。然后,它还有一个图像编码器,可以将图像转化为各种特征向量。这两个向量越接近,这个描述与图像内容就越接近。距离越远,相关性就越小。 OpenAI使用了4亿组图文对来训练这个模型。最终训练完成的CLIP模型效果如下图所示。当我们输入一个图像的描述时,CLIP可以确定哪个图片与这个描述最相符。例如,在下图的第四行,描述是“一张虎斑猫的面部照片”,它与纵向第四张图像的相关性最高,为0.31,而与第一张书封面的截图相关性仅为0.12。
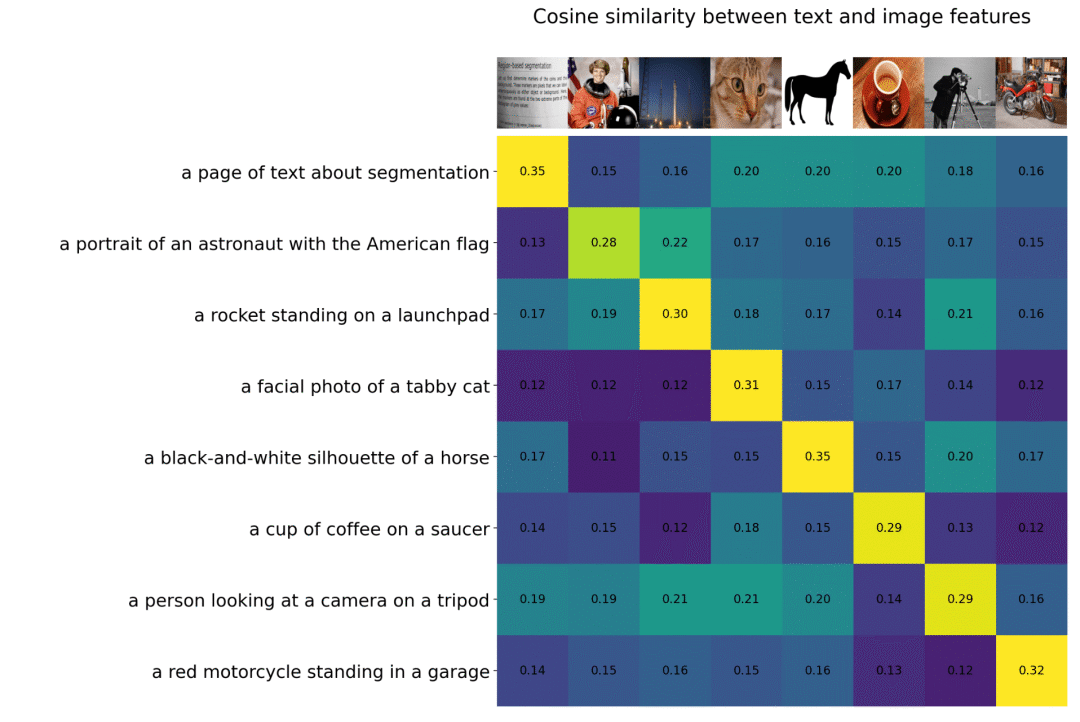
回到Stable Diffusion,在Stable Diffusion中,我们只使用了CLIP的部分文本编码器,因为它可以将文本转换成相应的文本特征向量,这些向量将与现实中的图像存在相关性。 再回到前面提到的两个问题,事实上,它们互相回答了
😁 为什么当我们输入“Cat”时,生成的图像很可能是橙色猫或猎豹?这是因为文本编码器将“Cat”转化为77个等长的向量,这些向量中的“Embedding”将包含一些与“Cat”相关的特征和意义:
- 形态特征:向量表示可能捕捉到猫的形态特征,如身体形状、头部形状、四肢位置等。这些特征有助于将猫与其他动物或物体区分开来。 - 视觉特征:向量表示可能包含猫的视觉特征,如颜色、图案、眼睛的形状等。这些特征有助于识别猫的外观特征。 - 语义意义:向量表示可能包含与“Cat”相关的语义意义,比如它是一种宠物,是一种独立的动物,与人类有亲密关系等。这些意义有助于理解猫在文化和社会中的角色和重要性。
⚠️注意:由于模型在某些领域的不解释性,这些向量不一定包含这些特征。具体示例主要用于更好的解释。 总之,由于在Stable Diffusion中只使用了CLIP文本编码器的部分,它被称为“CLIP文本编码器”,在某些产品中也称为“CLIP文本编码”。 💡为什么在使用Stable Diffusion或Midjourney时,我们不需要担心提示语中的语法和大小写?这是因为这些提示语由文本编码器转换成特征向量。转换成特征向量后,语法和大小写被简化为一系列数字,在没有任何模型调整的情况下,这些数字是没有敏感性的。
为了帮助大家更好地掌握 ComfyUI,我在去年花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …

二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …

三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …

四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …

五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









