






前言
前一篇的文章中讲了右值引用以及移动语义,本篇文章就继续来讲解 C++11 的其他新特性,至于发展历史这些在上一篇已经提过了,本篇就不再做详细说明。
一、列表初始化
1.1 C++98的{}
struct A
{
int _x;
int _y;
};
int main()
{
int arr1[] = { 1, 2, 3, 4, 5 };
int arr2[5] = { 0 };
A p = { 1, 2 };
return 0;
}1.2 C++11的{}
struct A
{
int _x;
int _y;
};
class Date
{
public:
Date(int year = 1, int month = 1, int day = 1)
:_year(year)
, _month(month)
, _day(day)
{
cout << "Date(int year, int month, int day)" << endl;
}
Date(const Date& d)
:_year(d._year)
, _month(d._month)
, _day(d._day)
{
cout << "Date(const Date& d)" << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
// 内置类型支持
int x1 = { 2 };
// ⾃定义类型支持
// 这⾥本质是用{2025, 1, 1}构造⼀个Date临时对象
// 临时对象再去拷⻉构造d1,编译器优化后合⼆为⼀变成{2025, 1, 1}直接构造初始化d1
// 运⾏⼀下,我们可以验证上面的理论,发现是没调⽤拷贝构造的
Date d1 = { 2025, 1, 1 };
// 这⾥d2引⽤的是{2025, 1, 1}构造的临时对象
const Date& d2 = { 2025, 1, 1 };
// C++98⽀持单参数时类型转换,也可以不⽤{}
Date d3 = { 2025 };
Date d4 = 2025;
// 可以省略掉=
A p1{ 1, 2 };
int x2{ 2 };
Date d6{ 2024, 7, 25 };
const Date& d7{ 2024, 7, 25 };
vector<Date> v;
v.push_back(d1);
v.push_back(Date(2025, 1, 1));
// ⽐起有名对象和匿名对象传参,这⾥{}更有性价⽐
v.push_back({ 2025, 1, 1 });
return 0;
}一般是用在传参中比较多,非常方便,直接走类型转换,不需要定义有名对象或者匿名对象。
1.3 C++11的initializer_list
比如说我们在使用vector/list的时候,它们的构造函数都有一个用n个val去构造,但是这个构造出来的容器内所有的值都是一样的,没法做到我想用1,2,3,4,5来初始化,就只能先定义出来对象再一个一个的插入,那 C++11库中提出了一个 initializer_list 的类
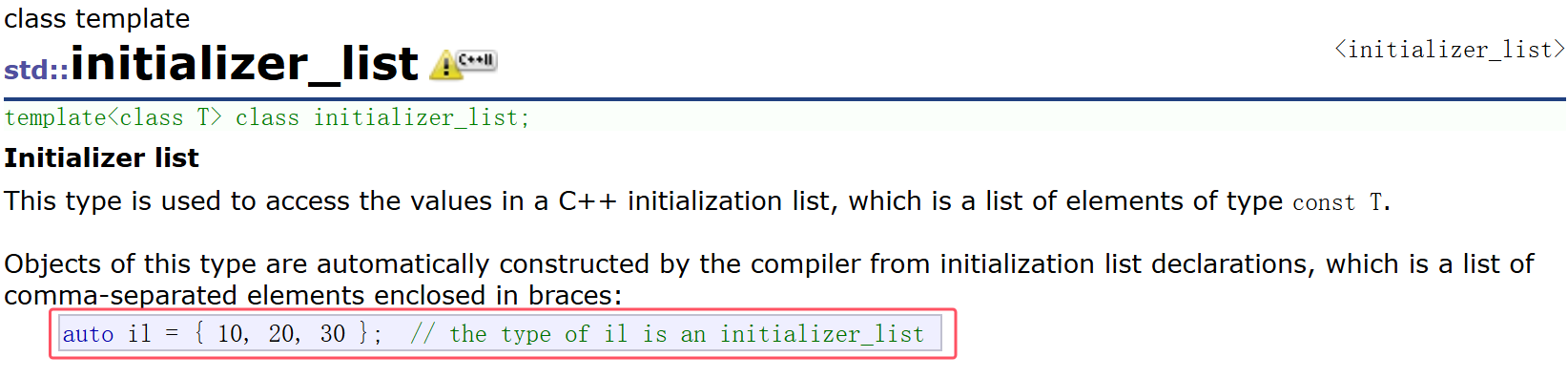
这个类的本质是底层开一个数组,将数据拷贝过来,initializer_list内部有两个指针分别指向数组的开始和结束。initializer_list支持迭代器遍历。
int main()
{
auto ili = { 1, 2, 3, 4, 5 };
//initializer_list<int> ili = { 10, 20, 30 };
//成员变量有2个指针,32位下大小是8
cout << sizeof(ili) << endl;
//打印得到的类型是class std::initializer_list<int>
cout << typeid(ili).name() << endl;
//地址非常接近,验证了我们说的是在栈上开一块数据,把数据拷贝过来
int x = 0;
cout << &x << endl;
cout << ili.begin() << endl;
cout << ili.end() << endl;
//下面两种写法看似一样,其实并不一样,一个是调构造,参数的个数有要求,
// 另一个是initializer_list,传多少个都可以
Date d1 = { 2025,1,1 };
vector<int> v = { 1,2,3 };
//initializer_list也支持赋值版本
v = { 10,20,30 };
return 0;
}二、可变模版参数
2.1 基本语法及原理
// 普通模版
template <class ...Args>
void Func(Args... args)
{}
// 左值引用模版
template <class ...Args>
void Func(Args&... args)
{}
// 万能引用模版
template <class ...Args>
void Func(Args&&... args)
{}template <class ...Args>
void Print(Args&&... args)
{}
int main()
{
double d = 2.2;
Print(); // 包里有0个参数
Print(0); // 包里有1个参数
Print(0, string("111")); // 包里有2个参数
Print(0, string("111"), d); // 包里有3个参数
return 0;
}void Print();
template <class T1>
void Print(T1&& arg1);
template <class T1, class T2>
void Print(T1&& arg1, T2&& arg2);
template <class T1, class T2, class T3>
void Print(T1&& arg1, T2&& arg2, T3&& arg3);void Print();
void Print(int&& arg1);
void Print(int&& arg1, string&& arg2);
void Print(double&& arg1, string&& arg2, double& arg3);大家都知道sizeof操作符是干嘛的,就是计算所占内存空间的大小,在这里要引入一个sizeof...操作符,它的功能是去计算参数包中的个数。
template <class ...Args>
void Print(Args&&... args)
{
cout << sizeof...(args) << endl;
}那既然我们可以通过这个运算符求出参数包中的个数,那可不可以遍历参数包中的个数次,来依次拿到里面的内容,解析出来呢?
template <class ...Args>
void Print(Args&&... args)
{
cout << sizeof...(args) << endl;
for (int i = 0; i < sizeof...(args); i++)
{
cout << args[i] << " ";
}
cout << endl;
}一定要注意是没有这种语法的,解析参数包有其他的方法但是这种方法不可以,不可以用[]访问。下面就来介绍解析参数包的方法。
2.2 包扩展
void ShowList()
{
// 编译时递归的终止条件,参数包是0个时,直接匹配这个函数
cout << endl;
}
template<class T, class ...Args>
void ShowList(T x, Args... args)
{
cout << x << " ";
// args是N个参数的参数包
// 调用ShowList,参数包的第一个传给x,剩下N-1传给第二个参数包
ShowList(args...);
};
template <class ...Args>
void Print(Args... args)
{
ShowList(args...);
}
int main()
{
double x = 2.2;
Print(); // 包⾥有0个参数
Print(1); // 包⾥有1个参数
Print(1, string("xxxxx")); // 包⾥有2个参数
Print(1, string("xxxxx"), x); // 包⾥有3个参数
return 0;
}参数是0个时,直接匹配到普通的ShowList,参数是一个时,x就是参数包的第一个,剩下0个参数的参数包传给普通的ShowList,参数是两个时,x是参数包的第一个,剩下1个参数的参数包继续递归调自己,x是参数包的第一个,剩下0个参数的参数包传给普通的ShowList,参数是三个时,x是参数包的第一个,剩下2个参数的参数包继续递归调自己,x是参数包的第一个,剩下1个参数的参数包继续递归调自己,x是参数包的第一个,剩下0个参数的参数包传给普通的ShowList,,就依次解析出了所有的参数。在这里注意,是编译时递归展开,不是运行时,其次是虽然说是递归,但是每一次因为参数会变化,所以每一次函数模版都会实例化成不同的函数,那每一次调用的也就都是不同的函数,所以应该说是调自己的重载版本。

初次之外,C++还支持更复杂的包扩展,直接将参数包依次展开依次作为实参给一个函数去处理。
template <class T>
const T& GetArg(const T& x)
{
cout << x << " ";
return x;
}
template <class ...Args>
void Arguments(Args... args)
{
}
template <class ...Args>
void Print(Args... args)
{
Arguments(GetArg(args)...);
cout << endl;
}
int main()
{
double x = 2.2;
Print(); // 包⾥有0个参数
Print(1); // 包⾥有1个参数
Print(1, string("xxxxx"));
Print(1, string("xxxxx"), x);
return 0;
}把参数包的每个参数都传给getArg处理,处理后的返回值作为实参组合参数包传给Arguments,本质可以理解为编译器编译时,包的扩展模式,这种方法是比较抽象的。
但是在实际中,我们基本很少会把参数包的内容解析出来,下面我们来看看具体应用。
2.3 emplace系列接口
这里会涉及右值引用和移动语义以及完美转发,建议如果大家不是很熟悉的话先去看看上一篇文章,链接在这里:C++ 带你彻底了解右值引用和移动语义-CSDN博客文章浏览阅读253次,点赞18次,收藏8次。右值引用以及移动语义,是 C++11 中的一个很重要的知识,增加了移动构造和移动赋值,因为是直接转移资源,所以效率远比拷贝的代价低。C++11中还有很多新的特性,由于篇幅原因我们下一篇文章再介绍。!!https://blog.csdn.net/2401_84771520/article/details/147386164?spm=1001.2014.3001.5501而且也将继续用到自己实现的string类和list类,为了省略篇幅就不在这里再贴一份了,大家需要看的话也可以到上一篇中去看。

int main()
{
list<hx::string> lt;
cout << "*********************************" << endl;
hx::string s1("111111111111");
lt.emplace_back(s1);
lt.push_back(s1);
cout << "*********************************" << endl;
lt.emplace_back(move(s1));
lt.push_back(move(s1));
cout << "*********************************" << endl;
lt.emplace_back(hx::string("11111111111"));
lt.push_back(hx::string("11111111111"));
cout << "*********************************" << endl;
lt.emplace_back("111111111111");
lt.push_back("111111111111");
cout << "*********************************" << endl;
return 0;
}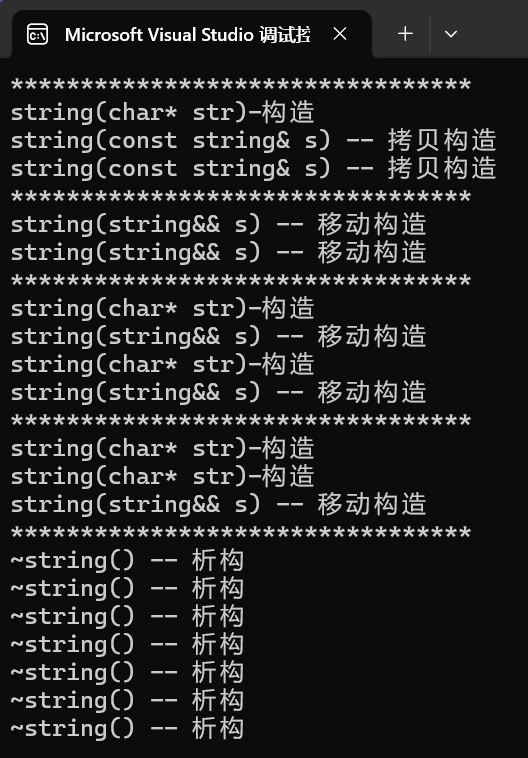
通过运行结果,可以看到的是,前三组的结果都是一样的, 第一组都是构造+拷贝构造,第二组都是移动构造,第三组都是构造+移动构造,但唯独第四组不同,emplace_back是构造,push_back是构造+移动构造,这是为什么呢?
这是因为,对于push_back来说,list实例化了,value_type就确定了,现在value_type就是string,const char*没法直接传给string,需要先构造一个临时对象,然后到结点上的时候,走移动构造转移资源。而对于emplace_back来说,list实例化了跟我没有关系,我是等到实参传给形参的时候推演类型,那传上来的是const char*,就推出来了const char*,然后构造string的参数包一路向下传,等到结点上时,直接用const char*去构造string。所以一个是直接构造,一个是构造+移动构造。
那再来看一组例子
int main()
{
list<pair<hx::string, int>> lt1;
cout << "*********************************" << endl;
pair<hx::string, int> kv("苹果", 1);
lt1.emplace_back(kv);
lt1.push_back(kv);
cout << "*********************************" << endl;
lt1.emplace_back(move(kv));
lt1.push_back(move(kv));
cout << "*********************************" << endl;
lt1.emplace_back(pair<hx::string, int>("111111", 1));
lt1.push_back(pair<hx::string, int>("111111", 1));
cout << "*********************************" << endl;
// 注意这里的写法
lt1.emplace_back("苹果", 1);
lt1.push_back({ "苹果", 1 });
cout << "*********************************" << endl;
return 0;
}
可以看到的是,存pair和存string的结果是一样的,只有第四组不同,而且这里的写法要注意一下,push_back必须要加{},emplace_back不能加{},那为什么第四组的结果不同呢?
这是因为,对于push_back来说,list实例化了,value_type就确定了,现在value_type就是pair<string, int>,形参只有一个参数,那也只能传一个参数,多参数构造函数的隐式类型转换必须加上{},所以push_back必须加{},先构造一个临时对象,然后到结点上的时候,走移动构造转移资源。而对于emplace_back来说,list实例化了跟我没有关系,我是等到实参传给形参的时候推演类型,那传上来的是const char*, int,就推出来了const char*, int,对于{}编译器会识别成initializer_list,但是initializer_list里面的值类型又是不一样的,编译器不能确定这到底是什么,所以emplace_back不能加{},然后构造pair<string, int>的参数包一路向下传,等到结点上时,直接用const char*, int去构造pair<string, int>。所以一个是直接构造,一个是构造+移动构造。
对于深拷贝的类来说,直接构造和构造+移动构造的区别不大,这里的区别反而在于浅拷贝,浅拷贝的类移动构造没有可以转移的资源,还是只能老老实实拷贝,这时和直接构造的效率就有区别了,所以综合来说emplace_back更加高效,推荐使用emplace系列替代insert和push系列。
接下来我们用我们自己的list来实现一下emplace系列
之前是push_back传给insert,现在是emplace_back传给emplace,由于参数包中的参数我们并不知道是什么,可能是左值也可能是右值,所以参数包往下一层传的时候需要完美转发,维持自身的属性。
template<class ...Args>
void emplace_back(Args&&... args)
{
emplace(end(), forward<Args>(args)...);
}
template<class ...Args>
void emplace(iterator pos, Args&&... args)
{
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* newnode = new Node(forward<Args>(args)...);
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = cur;
cur->_prev = newnode;
++_size;
}
template<class ...Args>
list_node(Args&&... args)
: _prev(nullptr)
, _next(nullptr)
, _val(forward<Args>(args)...)
{}三、类的新功能
3.1 默认的移动构造和移动赋值
这个在上一篇文章的结尾也已经提过了,移动构造和移动赋值是新增加的两个默认成员函数,如果没有显示实现移动构造、析构、拷贝构造、拷贝赋值中的任意一个,那编译器会生成一个默认的移动构造,默认的移动构造对于内置类型进行浅拷贝,对于自定义类型会去调它的移动构造,如果它没有移动构造,就调它的拷贝构造。
如果没有显示实现移动构造、析构、拷贝构造、拷贝赋值中的任意一个,那编译器会生成一个默认的移动赋值,默认的移动赋值对于内置类型进行浅拷贝,对于自定义类型会去调它的移动构赋值,如果它没有移动赋值,就调它的拷贝赋值。
3.2 成员变量声明时给缺省值
成员变量声明时给缺省值是给初始化列表用的,如果没有显示在初始化列表初始化,就会在初始化列表用这个缺省值初始化。
3.3 default和delete
class Person
{
public:
Person(const char* name = "1111", int age = 20)
:_name(name)
, _age(age)
{}
Person(const Person& p)
:_name(p._name)
, _age(p._age)
{}
// 指定生成
Person(Person&& p) = default;
private:
hx::string _name;
int _age;
};class Person
{
public:
Person(const char* name = "1111", int age = 20)
:_name(name)
, _age(age)
{}
// 指定不生成
Person(Person&& p) = delete;
private:
hx::string _name;
int _age;
};3.4 final和override
final修饰一个类,该类不能被继承。final修饰虚函数,该虚函数不能被重写。
override是检查派生类是否重写了父类的某个虚函数的,如果没重写就会报错。
四、STL中的一些变化
在C++11更新的新容器有array,forward_list,unordered_set,unordered_map,其中最有用的是unordered_set,unordered_map,另外两个在实际中使用的很少。
五、lambda
5.1 lambda表达式语法
int main()
{
auto add = [](int x, int y)->int {return x + y; };
cout << add(1, 2) << endl;
// 省略了参数和返回值
auto func = []
{
cout << "hello world" << endl;
return 0;
};
func();
int a = 0, b = 1;
// 省略了返回值
auto swap = [](int& x, int& y)
{
int tmp = x;
x = y;
y = tmp;
};
swap(a, b);
return 0;
}5.2 捕捉列表
如果我不想传参,并且还想在lambda内用外层作用域的变量,这时就要通过捕捉列表进行捕捉,捕捉的方式有两种,一种是值捕捉,一种是引用捕捉。
int main()
{
int a = 0, b = 1, c = 2, d = 3;
auto func1 = [a, b]
{
// 值捕捉的变量不能修改
// a++;
// b++;
int ret = a + b;
return ret;
};
cout << func1() << endl;
return 0;
}显示的值捕捉了a和b
需要注意的是,值捕捉是外面的拷贝,而且默认是带有const属性的,不可以修改。
int main()
{
int a = 0, b = 1, c = 2, d = 3;
auto func1 = [&a, &b]
{
// 引用捕捉的变量可以修改
a++;
b++;
int ret = a + b;
return ret;
};
cout << func1() << endl;
return 0;
}显示的引用捕捉了a和b
引用捕捉可以修改,而且在lambda内修改了后外面也就修改了。
如果这个时候外面的变量很多,假如有10个变量,在lambda内都要用,这时候捕捉10个变量很麻烦,所以可以用隐式的捕捉方式
int main()
{
int a = 0, b = 1, c = 2, d = 3;
auto func2 = [=]
{
int ret = a + b + c;
return ret;
};
cout << func2() << endl;
return 0;
}int main()
{
int a = 0, b = 1, c = 2, d = 3;
auto func3 = [&]
{
a++;
c++;
d++;
};
func3();
return 0;
}隐式的引用捕捉了a和b
在捕捉列表写⼀个&表示隐式引用捕捉,这样我们在lambda内用了哪些变量,编译器就会自动捕捉那些变量。
还可以在捕捉列表中混合使用显示捕捉和隐式捕捉
int main()
{
int a = 0, b = 1, c = 2, d = 3;
auto func4 = [&, a, b]
{
//a++;
//b++;
c++;
d++;
return a + b + c + d;
};
func4();
return 0;
}混合捕捉
a和b值捕捉,其他变量引用捕捉,所以c、d可以变,但是a、b不能变,混合捕捉的时候,隐式的一定要放在前面。
int main()
{
int a = 0, b = 1, c = 2, d = 3;
auto func5 = [=, &a, &b]
{
a++;
b++;
//c++;
//d++;
return a + b + c + d;
};
func5();
return 0;
}混合捕捉
a和b引用捕捉,其他变量值捕捉,所以c、d不能变,但是a、b可以变,混合捕捉的时候,隐式的一定要放在前面。
int x;
int main()
{
int a = 0, b = 1, c = 2, d = 3;
static int m = 0;
auto func6 = []
{
int ret = x + m;
return ret;
};
return 0;
}int x;
auto func = []
{
x++;
};
int main()
{
int a = 0, b = 1, c = 2, d = 3;
auto func7 = [=]()mutable
{
a++;
b++;
c++;
d++;
return a + b + c + d;
};
cout << func7() << endl;
cout << a << " " << b << " " << c << " " << d << endl;
return 0;
}5.3 lambda的应用
struct Goods
{
string _name; // 名字
double _price; // 价格
int _evaluate; // 评价
Goods(const char* str, double price, int evaluate)
:_name(str)
, _price(price)
, _evaluate(evaluate)
{}
};
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "⾹蕉", 3, 4 }, { "橙⼦", 2.2, 3}, { "菠萝", 1.5, 4 } };
return 0;
}在实际中我们直接对整型排序的情况是非常少的,大多数是对比如这里的价格,评价排序,就是对这种类里面的成员函数进行排序,我们就要自己控制sort的逻辑,需要传一个可调用对象上去,但是因为函数指针的类型定义起来太费劲,所以在C++中更喜欢用仿函数来替代函数指针。
struct ComparePriceLess
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price < gr._price;
}
};
struct ComparePriceGreater
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price > gr._price;
}
};
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "⾹蕉", 3, 4 }, { "橙⼦", 2.2, 3}, { "菠萝", 1.5, 4 } };
sort(v.begin(), v.end(), ComparePriceLess());
sort(v.begin(), v.end(), ComparePriceGreater());
return 0;
}
仿函数肯定是能达到要求的,但是我们现在还是只有价格、评价,如果成员变量更多呢,那我们就需要写很多个类,就非常重,而且我们这里还是命名规范,比较的是什么、升序降序都写的很明确,有人命名可能就写一个Compare1, Compare2,那看起来就很费劲,这时候仿函数就不是很好用了,我们就可以用lambda,直接定义局部的函数。
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "⾹蕉", 3, 4 }, { "橙⼦", 2.2, 3}, { "菠萝", 1.5, 4 } };
sort(v.begin(), v.end(), ComparePriceLess());
sort(v.begin(), v.end(), ComparePriceGreater());
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._price < g2._price; });
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._price > g2._price; });
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._evaluate < g2._evaluate; });
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._evaluate > g2._evaluate; });
return 0;
}由上面的例子大家可以看出,在这种场景下,lambda是非常好用的。
5.4 lambda的原理
class Rate
{
public:
Rate(double rate)
: _rate(rate)
{}
double operator()(double money, int year)
{
return money * _rate * year;
}
private:
double _rate;
};
int main()
{
double rate = 0.49;
auto r2 = [rate](double money, int year)->double {
return money * rate * year;
};
Rate r1(rate);
r1(10000, 2);
r2(10000, 2);
return 0;
}lambda的捕捉列表是rate,仿函数类的成员变量是rate,lambda的参数列表和仿函数类的operator()的参数列表一样都是money和year,lambda的参数列表和仿函数类的operator()的返回值一样都是double,lambda的参数列表和仿函数类的operator()的函数体一样,都是money*rate*year
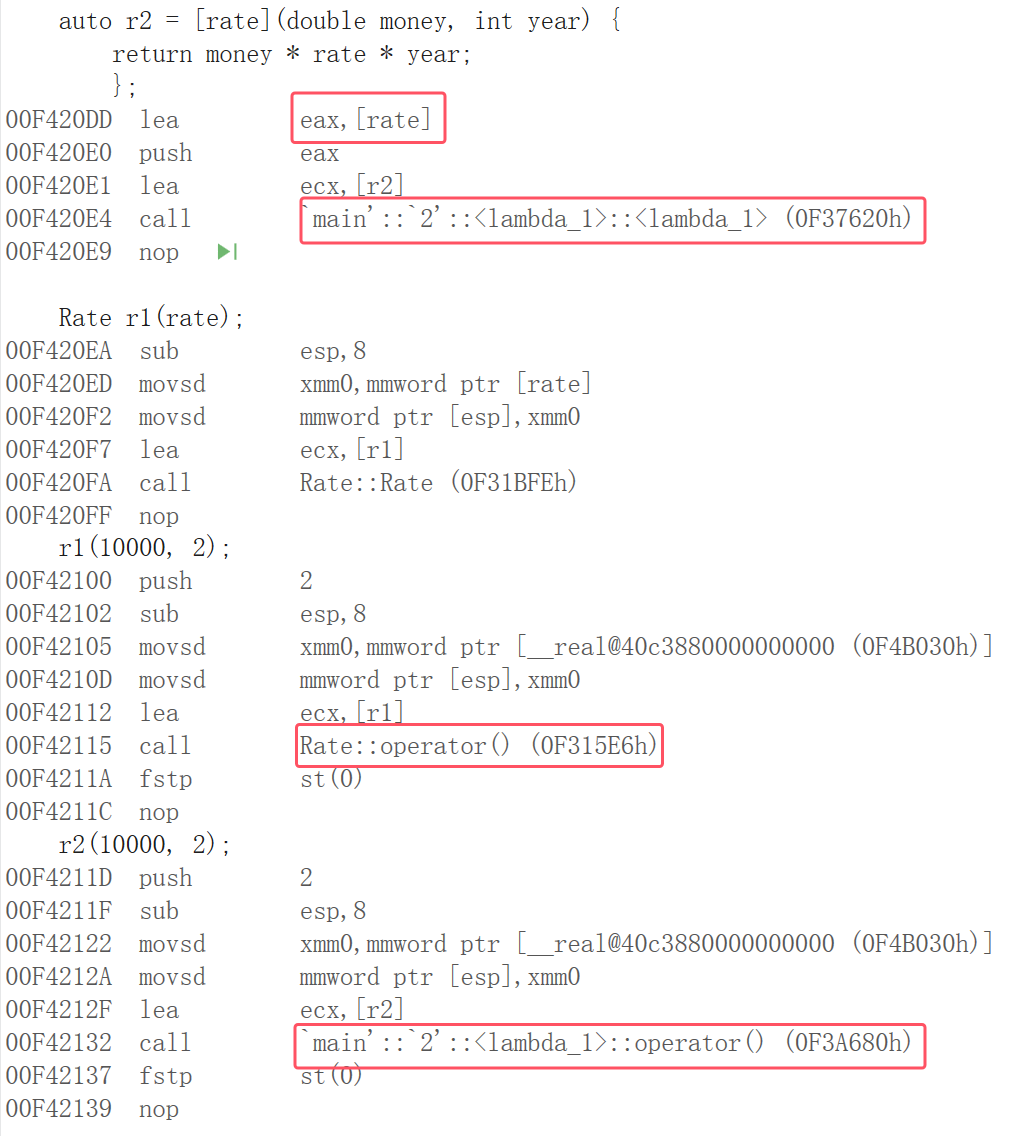
通过汇编我们验证了,捕捉列表的rate,可以看到作为lambda_1类构造函数的参数传递了,这样要拿去初始化成员变量,r2这个lambda对象调用本质还是调用operator(),类型是lambda_1,这个类型名的规则是编译器自己定制的,保证不同的lambda不冲突,而且编译器的规则也不同,所以我们语法层是拿不到这个类型的。
六、包装器
6.1 function
template <class T>
class function; // undefined
template <class Ret, class... Args>
class function<Ret(Args...)>;int f(int a, int b)
{
return a + b;
}
struct Functor
{
public:
int operator() (int a, int b)
{
return a + b;
}
};
class Plus
{
public:
Plus(int n = 10)
:_n(n)
{}
static int plusi(int a, int b)
{
return a + b;
}
double plusd(double a, double b)
{
return (a + b) * _n;
}
private:
int _n;
};int main()
{
// 包装各种可调用对象
function<int(int, int)> f1 = f;
function<int(int, int)> f2 = Functor();
function<int(int, int)> f3 = [](int a, int b) {return a + b; };
// 用vector存起来很方便
vector<function<int(int, int)>> v = { f1, f2, f3 };
cout << f1(1, 1) << endl;
cout << f2(1, 1) << endl;
cout << f3(1, 1) << endl;
return 0;
}
包装成员函数时要注意指定类域,其次就是静态成员函数前面可以加上&,也可以不加,但是非静态成员函数必须要加
int main()
{
// 包装静态成员函数
// 成员函数要指定类域,静态的可以不加&,非静态必须加
function<int(int, int)> f4 = &Plus::plusi;
cout << f4(1, 1) << endl;
function<int(int, int)> f5 = &Plus::plusd;
cout << f5(1, 1) << endl;
return 0;
}但是在这里我们会发现,f5会报错,这其实是因为,非静态的成员函数是有this指针的,所以包装的时候以及在调用的时候都要显示的写出来
int main()
{
// 包装静态成员函数
// 成员函数要指定类域,静态的可以不加&,非静态必须加
function<int(int, int)> f4 = &Plus::plusi;
cout << f4(1, 1) << endl;
// 包装非静态成员函数
function<int(Plus*, int, int)> f5 = &Plus::plusd;
Plus ps;
cout << f5(&ps, 1, 1) << endl;
return 0;
}除了这样写,还有其他的方式,传对象上去也是可以的
int main()
{
function<int(Plus, int, int)> f6 = &Plus::plusd;
cout << f6(ps, 1, 1) << endl;
function<int(Plus&, int, int)> f7 = &Plus::plusd;
cout << f7(ps, 1, 1) << endl;
function<int(Plus&&, int, int)> f8 = &Plus::plusd;
cout << f8(move(ps), 1, 1) << endl;
function<int(Plus&&, int, int)> f9 = &Plus::plusd;
cout << f9(Plus(), 1, 1) << endl;
return 0;
}下面我们来看一下包装器在实际中的具体应用,我们用一道题:逆波兰表达式来介绍

逆波兰表达式的求解方法是:遇见操作数就入栈,遇见操作符就取两个栈顶元素,计算完的结果重新放回栈中。
我们可以用map来映射string和function,遇见+的可调用对象是什么,遇见-的可调用对象是什么
class Solution {
public:
int evalRPN(vector<string>& tokens)
{
stack<int> st;
map<string, function<int(int, int)>> cal = {
{"+", [](int x, int y) {return x + y;}},
{"-", [](int x, int y) {return x - y;}},
{"*", [](int x, int y) {return x * y;}},
{"/", [](int x, int y) {return x / y;}}
};
for(auto str : tokens)
{
// 操作符
if(cal.count(str))
{
int right = st.top();
st.pop();
int left = st.top();
st.pop();
// cal[str]拿到可调用对象,再传参调用
int ret = cal[str](left, right);
st.push(ret);
}
// 操作数
else
st.push(stoi(str));
}
return st.top();
}
};这样的好处是不管有多少个运算符,直接增加映射关系就好,写起来很方便。
6.2 bind
template <class Fn, class... Args>
/* unspecified */ bind(Fn&& fn, Args&&... args);
template <class Ret, class Fn, class... Args>
/* unspecified */ bind(Fn&& fn, Args&&... args);int Sub(int a, int b)
{
return (a - b) * 10;
}
int SubX(int a, int b, int c)
{
return (a - b - c) * 10;
}
class Plus
{
public:
static int plusi(int a, int b)
{
return a + b;
}
double plusd(double a, double b)
{
return a + b;
}
};int main()
{
auto sub1 = bind(Sub, placeholders::_1, placeholders::_2);
cout << sub1(10, 5) << endl;
return 0;
}这里的调用逻辑是:_1传给a,_2传给b,无论顺序,就算是_2在前,_1在后也是一样,_2传给a,_1传给b,这里的规则就是在第一个就传给第一个形参,在第二个就传给第二个形参,不管是_几在前。但是传参的时候是按照顺序的,第一个实参传给_1/,第二个实参传给_2,10传给_1,5传给_2。
int main()
{
auto sub2 = bind(Sub, placeholders::_2, placeholders::_1);
cout << sub2(10, 5) << endl;
return 0;
}_2传给a,_1传给b,但是传参的时候是按照_1/_2传的,10传给_1,5传给_2,这样不就达到了交换参数顺序的目的吗
但是在实际中,bind通常用来绑死部分参数,还以上面的Sub函数为例,假如想控制成100-b,就想只传一个a,或者就想是a-100,就想只传一个把,那这时只需要在bind内写死就可以
int main()
{
// 绑死第一个参数
auto sub3 = bind(Sub, 100, placeholders::_1);
cout << sub3(5) << endl;
// 绑死第二个参数
auto sub4 = bind(Sub, placeholders::_1, 100);
cout << sub4(5) << endl;
return 0;
}其余的参数依然遵循上面我们说的传参的规则
int main()
{
// 绑死第一个参数
auto sub5 = bind(SubX, 100, placeholders::_1, placeholders::_2);
cout << sub5(5, 1) << endl;
// 绑死第二个参数
auto sub6 = bind(SubX, placeholders::_1, 100, placeholders::_2);
cout << sub6(5, 1) << endl;
// 绑死第三个参数
auto sub7 = bind(SubX, placeholders::_1, placeholders::_2, 100);
cout << sub7(5, 1) << endl;
return 0;
}调用SubX函数,分别绑死第一二三个参数
绑定成员函数时也需要指定类域并且取地址,现在我们可以直接把第一个参数,成员函数对象可以直接绑死,这样就不需要每次再显示传了
int main()
{
function<double(double, double)> f8 = bind(&Plus::plusd, Plus(), placeholders::_1, placeholders::_2);
cout << f8(1.1, 1.1) << endl;
return 0;
}总结
本篇文章讲解了 C++11 的新特性,用起来非常很方便,比如可变模版参数,就是把我们的任务交给编译器了,lambda的发明,以及包装器统一可调用对象的类型,都很值得我们去了解,那 C++11 还有一个智能指针,但是由于智能指针占据的篇幅会有点长,所以我们下一篇文章再讲智能指针,如果大家觉得小编写的不错,可以给一个三连表示感谢,谢谢大家!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









