







深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
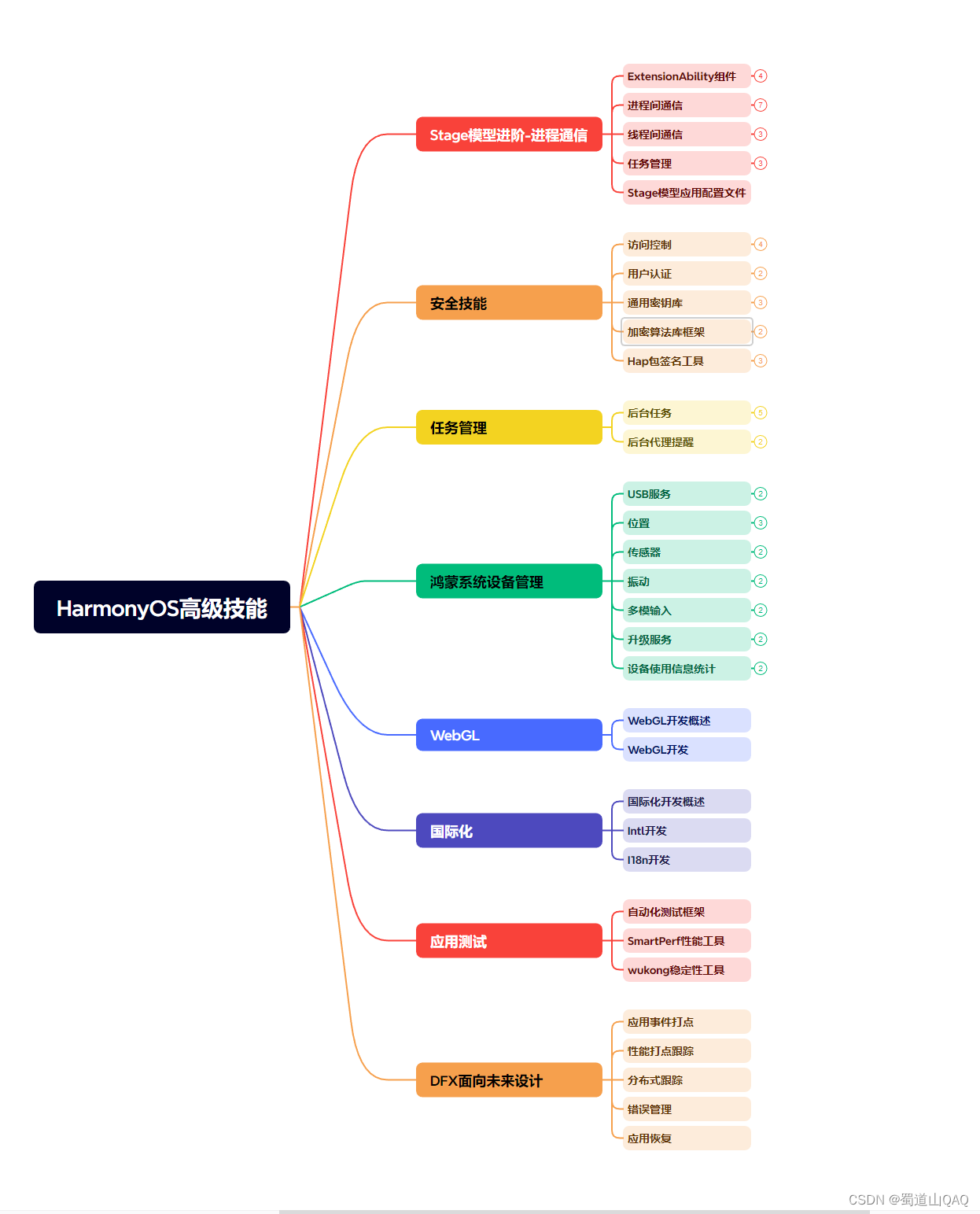


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
- Row(行):每一 row 代表着一个数据对象,每一 row 都是以一个 row key(行键)和一个或者多个 column 组成。row key 是每个数据对象的唯一标识的,按字母顺序排序,即 row 也是按照这个顺序来进行存储的。所以,row key 的设计相当重要,一个重要的原则是,相关的 row 要存储在接近的位置。比如网站的域名,row key 就是域名,在设计时要将域名反转(例如,org.apache.www、org.apache.mail、org.apache.jira),这样的话, Apache 相关的域名在 table 中存储的位置就会非常接近的。
- Column(列):column 由 column family 和 column qualifier 组成,由冒号(
:)进行进行间隔。比如family:qualifier。 - Column Family(列族):在 HBase,column family 是 一些 column 的集合。一个 column family 所有 column 成员是有着相同的前缀。比如, courses:history 和 courses:math 都是 courses 的成员。冒号(
:)是 column family 的分隔符,用来区分前缀和列名。column 前缀必须是可打印的字符,剩下的部分列名可以是任意字节数组。column family 必须在 table 建立的时候声明。column 随时可以新建。在物理上,一个的 column family 成员在文件系统上都是存储在一起。因为存储优化都是针对 column family 级别的,这就意味着,一个 column family 的所有成员的是用相同的方式访问的。 - Column Qualifier(列限定符):column family 中的数据通过 column qualifier 来进行映射。column qualifier 也没有特定的数据类型,以二进制字节来存储。比如某个 column family “content”,其 column qualifier 可以设置为 “content:html” 和 “content:pdf”。虽然 column family 是在 table 创建时就固定了,但 column qualifier 是可变的,可能在不同的 row 之间有很大不同。
- Cell(单元格):cell 是 row、column family 和 column qualifier 的组合,包含了一个值和一个 timestamp,用于标识值的版本。
- Timestamp(时间戳):每个值都会有一个 timestamp,作为该值特定版本的标识符。默认情况下,timestamp 代表了当数据被写入 RegionServer 的时间,但你也可以在把数据放到 cell 时指定不同的 timestamp。
2. map
HBase/Bigtable 的核心数据结构就是 map。不同的编程语言针对 map 有不同的术语,比如 associative array(PHP)、associative array(Python),Hash(Ruby)或 Object (JavaScript)。
简单来说,map 就是 key-value 对集合。下面是一个用 JSON 格式来表达 map 的例子:
{
“zzzzz” : “woot”,
“xyz” : “hello”,
“aaaab” : “world”,
“1” : “x”,
“aaaaa” : “y”
}
3. 分布式
毫无疑问,HBase/Bigtable 都是建立在分布式系统上的,HBase 基于 Hadoop Distributed File System (HDFS) 或者 Amazon’s Simple Storage Service(S3),而 Bigtable 使用 Google File System(GFS)。它们要解决的一个问题就是数据的同步。这里不讨论如何做到数据同步。 HBase/Bigtable 可以部署在成千上万的机器上来分散访问压力。
4. 排序
和一般的 map 实现有所区别,HBase/Bigtable 中的 map 是按字母顺序严格排序的。这就是说,对于 row key 是“aaaaa”的旁边 row key 应该是 “aaaab”,而与 row key 是“zzzzz”离得较远。
还是以上面的 JSON 为例,一个排好序的例子如下:
{
“1” : “x”,
“aaaaa” : “y”,
“aaaab” : “world”,
“xyz” : “hello”,
“zzzzz” : “woot”
}
在一个大数据量的系统里面,排序很重要,特别是 row key 的设置策略决定了查询的性能。比如网站的域名,row key 就是域名,在设计时要将域名反转(例如,org.apache.www、org.apache.mail、org.apache.jira)。
5. 多维
多维 map,即 map 里面嵌套 map。例如:
{
“1” : {
“A” : “x”,
“B” : “z”
},
“aaaaa” : {
“A” : “y”,
“B” : “w”
},
“aaaab” : {
“A” : “world”,
“B” : “ocean”
},
“xyz” : {
“A” : “hello”,
“B” : “there”
},
“zzzzz” : {
“A” : “woot”,
“B” : “1337”
}
}
6. 时间版本
在查询中不指定时间,返回的将是最近的一个时间的版本。如果给出 timestamp,返回的将是早于这个时间的数值。例如: 查询 row/column 是“aaaaa”/“A:foo”的,将返回 y;查询 row/column/timestamp 是“aaaaa”/“A:foo”/10的,将返回 m;查询 row/column/timestamp 是“aaaaa”/“A:foo”/2的,将返回 null。
{
// …
“aaaaa” : {
“A” : {
“foo” : {
15 : “y”,
4 : “m”
},
“bar” : {
15 : “d”, } }, “B” : { “” : { 6 : “w” 3 : “o” 1 : “w” } } }, // … }
7. 概念视图
下面表格是一个名为 webtable 的 table ,包含了两个 row(com.cnn.www 和 com.example.www)和三个 column family(contents、 anchor和people)。第一个 row(com.cnn.www)中,anchor 包含了两个 column(anchor:cssnsi.com和 anchor:my.look.ca),contents包含了一个 column(contents:html)。在这个例子里面,row key 是com.cnn.www的 row 包含了5个版本,而 row key 是com.example.www的 row 包含了1个版本。column qualifier 为 contents:html包含了给定网站的完整的 HTML。column family 是anchor的每个 qualifier 包含了网站的链接。人们列族代表与网站相关的人。column family 是people关联的是网站的人物资料。
| Row Key | Timestamp | ColumnFamily contents | ColumnFamily anchor | ColumnFamily people |
|---|---|---|---|---|
| “com.cnn.www” | t9 | anchor:cnnsi.com = “CNN” | ||
| “com.cnn.www” | t8 | anchor:my.look.ca = “CNN.com” | ||
| “com.cnn.www” | t6 | contents:html = “…” | ||
| “com.cnn.www” | t5 | contents:html = “…” | ||
| “com.cnn.www” | t3 | contents:html = “…” |
在这个表中显示为空的 cell 不占用空间,这使得 HBase 变得“稀疏”。除了表格方式来展现数据试图,也使用使用多维 map,如下:
{
“com.cnn.www”: {
contents: {
t6: contents:html: “…”
t5: contents:html: “…”
t3: contents:html: “…”
}
anchor: {
t9: anchor:cnnsi.com = “CNN”
t8: anchor:my.look.ca = “CNN.com”
}
people: {}
}
“com.example.www”: {
contents: {
t5: contents:html: “…”
}
anchor: {}
people: {
t5: people:author: “John Doe”
}
}
}
8. 物理视图
尽管在概念视图里,table 可以被看成是一个稀疏的 row 的集合。但在物理上,它的是按照 column family 存储的。新的 column qualifier (column_family:column_qualifier)可以随时添加进已有的 column family 。
下表是一个 ColumnFamily anchor:
| Row Key | Timestamp | Column Family anchor |
|---|---|---|
| “com.cnn.www” | t9 | anchor:cnnsi.com = “CNN” |
| “com.cnn.www” | t8 | anchor:my.look.ca = “CNN.com” |
下表是一个 ColumnFamily contents:
| Row Key | Timestamp | ColumnFamily contents: |
|---|---|---|
| “com.cnn.www” | t6 | contents:html = “…” |
| “com.cnn.www” | t5 | contents:html = “…” |
| “com.cnn.www” | t3 | contents:html = “…” |
值得注意的是在上面的概念视图中空白 cell 在物理上是不存储的,因为根本没有必要存储。因此若一个请求为要获取 t8 时间的contents:html,他的结果就是空。相似的,若请求为获取 t9 时间的anchor:my.look.ca,结果也是空。但是,如果不指明 timestamp,将会返回最新时间的 column。例如,如果请求为获取行键为“com.cnn.www”,没有指明 timestamp 的话,返回的结果是 t6 下的contents:html,t9下的anchor:cnnsi.com和 t8 下anchor:my.look.ca。
9. 数据模型操作
四个主要的数据模型操作是 Get、Put、Scan 和 Delete。通过 Table 实例进行操作。有关 Table 的 API 可以参见 http://hbase.apache.org/apidocs/org/apache/hadoop/hbase/client/Table.html。
Get
Get 返回特定 row 的属性。 Get 通过 Table.get 执行。有关 Get 的 API 可以参见 http://hbase.apache.org/apidocs/org/apache/hadoop/hbase/client/Get.html。
Put
Put 要么向 table 增加新 row(如果 key 是新的)或更新 row(如果 key 已经存在)。 Put 通过 Table.put(writeBuffer)或 Table.batch(非 writeBuffer)执行。有关 Put 的 API 可以参见 http://hbase.apache.org/apidocs/org/apache/hadoop/hbase/client/Put.html。
Scan
Scan 允许多个 row 特定属性迭代。
下面是一个在 Table 表实例上的 Scan 示例。假设 table 有几行 row key 为“row1”、“row2”、“row3”,还有一些 row key 值为“abc1”、 “abc2” 和“abc3”。下面的示例展示 Scan 实例如何返回“row”打头的 row。
public static final byte[] CF = “cf”.getBytes();
public static final byte[] ATTR = “attr”.getBytes();
…
Table table = … // instantiate a Table instance
Scan scan = new Scan();
scan.addColumn(CF, ATTR);
scan.setRowPrefixFilter(Bytes.toBytes(“row”));
ResultScanner rs = table.getScanner(scan);
try {
for (Result r = rs.next(); r != null; r = rs.next()) {
// process result…
}
} finally {
rs.close(); // always close the ResultScanner!
}
注意,通常最简单的方法来指定用于 scan 停止点是采用 InclusiveStopFilter 类,其 API 可以参见 http://hbase.apache.org/apidocs/org/apache/hadoop/hbase/filter/InclusiveStopFilter.html。


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
zXKE-1715607662214)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









