







深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
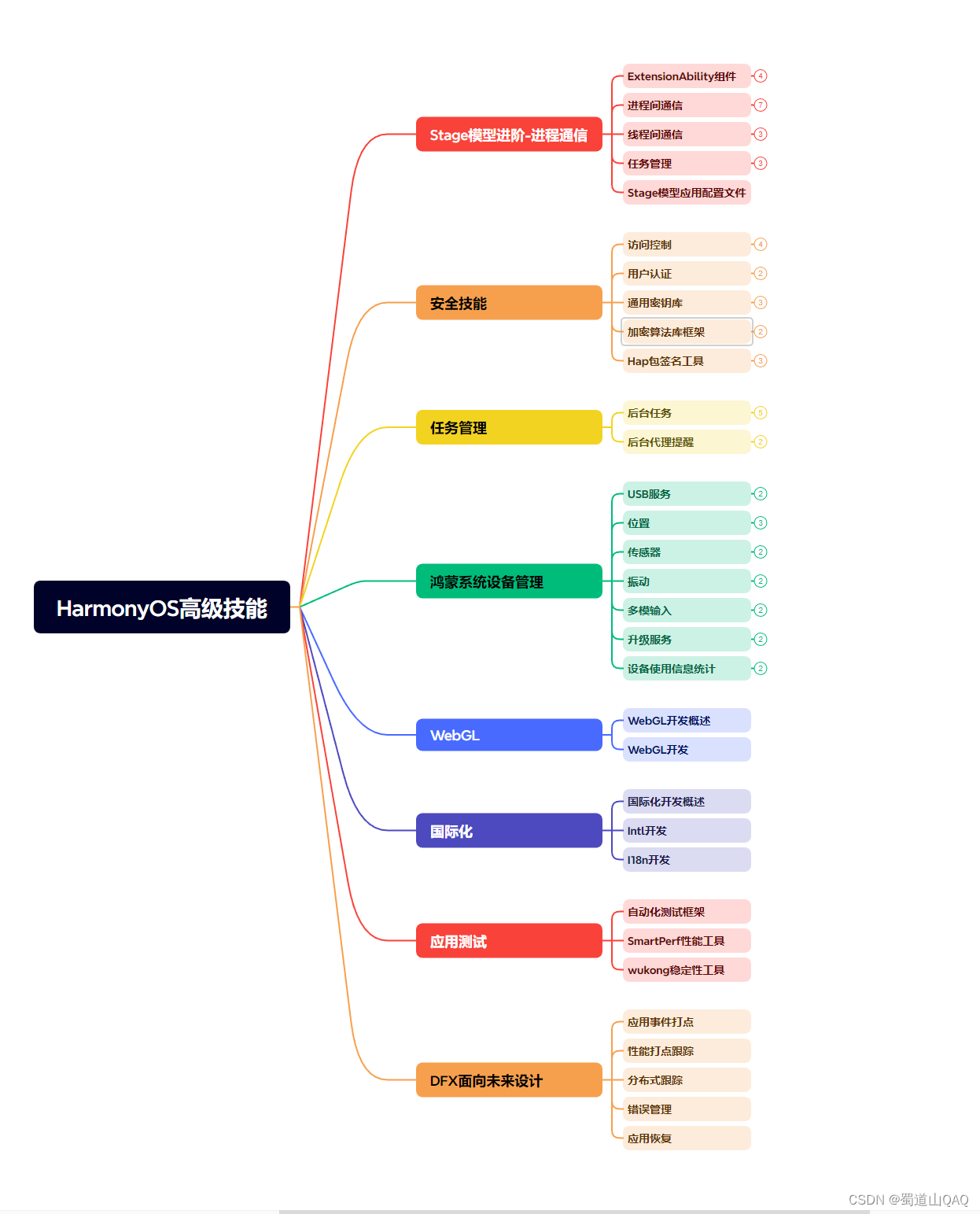

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
1.2 数据介绍
以下标签解释:
- Unnamed:学生编号
- race/ethnicity:种族
- parental level of education:父母受教育程度
- bachelor’s degree: 学士学位
- some college:大学肄业
- master’s degree:硕士学位
- associate’s degree:副学士
- high school:高中
- some high school:高中肄业
- lunch:午餐花费
- Standard: 标准
- free/reduced: 学校免费提供或低于标准
- test preparation course: 是否完成与考试相关课程
- none: 未完成
- completed: 完成
- math percentage:数学成绩
- reading score percentage: 阅读成绩
- writing score percentage: 写作成绩
- sex: 性别
2. 数据整理
data = pd.read_csv(‘Student Performance new.csv’)
data.info()
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 9 columns):
Column Non-Null Count Dtype
0 Unnamed: 0 1000 non-null int64
1 race/ethnicity 1000 non-null object
2 parental level of education 1000 non-null object
3 lunch 1000 non-null object
4 test preparation course 1000 non-null object
5 math percentage 1000 non-null float64
6 reading score percentage 1000 non-null float64
7 writing score percentage 1000 non-null float64
8 sex 1000 non-null object
dtypes: float64(3), int64(1), object(5)
memory usage: 70.4+ KB
本数据集共包含1000条数据,无数据缺失,数据类型包括整数,浮点数与对象类型
data.sample(n=5) # 随机抽取数据查看
| Unnamed: 0 | race/ethnicity | parental level of education | lunch | test preparation course | math percentage | reading score percentage | writing score percentage | sex | |
|---|---|---|---|---|---|---|---|---|---|
| 113 | 113 | group D | some college | standard | none | 0.51 | 0.58 | 0.54 | F |
| 342 | 342 | group B | high school | standard | completed | 0.69 | 0.76 | 0.74 | F |
| 475 | 475 | group D | bachelor’s degree | standard | completed | 0.71 | 0.76 | 0.83 | F |
| 181 | 181 | group C | some college | free/reduced | none | 0.46 | 0.64 | 0.66 | F |
| 41 | 41 | group C | associate’s degree | standard | none | 0.58 | 0.73 | 0.68 | F |
数据Unnamed列为学生编号,我们将其舍弃
data = data.drop(columns=[‘Unnamed: 0’], axis=1)
对于部分标签,存在多个变量, 我们需要对其进一步观察
labels = [‘race/ethnicity’, ‘parental level of education’, ‘lunch’, ‘test preparation course’]
for label in labels:
print(f’标签{label}情况:‘)
print(f’共有{data[label].nunique()}个变量,分别为’)
print(data[label].unique())
print(‘*’*20)
标签race/ethnicity情况:
共有5个变量,分别为
[‘group B’ ‘group C’ ‘group A’ ‘group D’ ‘group E’]
标签parental level of education情况:
共有6个变量,分别为
[“bachelor’s degree” ‘some college’ “master’s degree” “associate’s degree”
‘high school’ ‘some high school’]
标签lunch情况:
共有2个变量,分别为
[‘standard’ ‘free/reduced’]
标签test preparation course情况:
共有2个变量,分别为
[‘none’ ‘completed’]
对于分数标签,我们增加一列平均分(average score)
average_score = data[[‘math percentage’, ‘reading score percentage’, ‘writing score percentage’]].mean(axis=1)
data.insert(7, ‘average score’, np.round(average_score, 2))
在此基础上,我们对average_score进行分箱,以0-59,60-69,70-79,80-89,90-100为分隔,将分数分为对应的F, D, C, B, A。
performance_level = pd.cut(data[‘average score’], bins=[0, 0.59, 0.69, 0.79, 0.89, 100],
labels=[‘F’, ‘D’, ‘C’, ‘B’, ‘A’] )
data.insert(8, ‘performance level’, performance_level)
data.groupby(‘sex’)[‘sex’].count()
sex
F 518
M 482
Name: sex, dtype: int64
本数据集男女比例为:48.2%比51.8%。我们认为其基本符合男女比例在美国的分布,为了进一步进行验证,我们可以引入卡方拟合度检验:
- H0:在选取数据集时,男性与女性被选中的概率皆为50%
- H0:上述概率不成立
expected_number = [500, 500] # 理论上1000个样本中男女人数
observed_number = [482, 518] # 实际观察到的男女人数
result = stats.chisquare(f_obs=observed_number, f_exp=expected_number)
print(f’卡方拟合度检验的P值为:{result[1]}')
卡方拟合度检验的P值为:0.25494516431731784
据此,我们可以认为,如果从男女比例出发,这份数据为随机抽取。
至此,数据整理结束,我们再次查看此时的数据情况。
data.sample(n=5)
| race/ethnicity | parental level of education | lunch | test preparation course | math percentage | reading score percentage | writing score percentage | average score | performance level | sex | |
|---|---|---|---|---|---|---|---|---|---|---|
| 801 | group C | some high school | standard | completed | 0.76 | 0.80 | 0.73 | 0.76 | C | M |
| 200 | group C | associate’s degree | standard | completed | 0.67 | 0.84 | 0.86 | 0.79 | C | F |
| 417 | group C | associate’s degree | standard | none | 0.74 | 0.73 | 0.67 | 0.71 | C | M |
| 629 | group C | some high school | standard | completed | 0.44 | 0.51 | 0.55 | 0.50 | F | F |
| 944 | group B | high school | standard | none | 0.58 | 0.68 | 0.61 | 0.62 | D | F |
3. 学生成绩分析
3.1 学生整体成绩分布
fig = plt.figure(figsize=(5,10))
sns.set_style(‘darkgrid’)
subjects = [‘math percentage’, ‘reading score percentage’, ‘writing score percentage’, ‘average score’]
color = [‘green’, ‘blue’, ‘orange’, ‘purple’]
column = 1
for subject in subjects:
plt.subplot(len(subjects), 1, column)
sns.kdeplot(data=data, x=subject, color=color[column - 1])
column = column + 1
plt.tight_layout()
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zWSG3rHk-1639906825714)(output_26_0.png)]
整体来看,各学科成绩与平均成绩都符合正态分布,我们以样本均值加减两个标准差,可以得到约95%的学生成绩分区间:
lower_bound = data[‘average score’].mean() - data[‘average score’].std()*2
upper_bound = data[‘average score’].mean() + data[‘average score’].std()*2
print(f’95%的学生成绩分布下限:{lower_bound}‘)
print(f’95%的学生成绩分布上限:{upper_bound}’)
95%的学生成绩分布下限:0.3924529214957264
95%的学生成绩分布上限:0.9627870785042743
即约有95%的学生成绩分布在0.39分至0.96分之间。
3.2 不同学科成绩间的关联度以及不同学生人群擅长科目
我们数据集中共拥有三门学科,分别为读写与数学。我们可以分别将其看做**“文科”与“理科”**,并分别查看不同学科成绩之间的关联度。
data[subjects].corr()
| math percentage | reading score percentage | writing score percentage | average score | |
|---|---|---|---|---|
| math percentage | 1.000000 | 0.817580 | 0.802642 | 0.918442 |
| reading score percentage | 0.817580 | 1.000000 | 0.954598 | 0.970143 |
| writing score percentage | 0.802642 | 0.954598 | 1.000000 | 0.965643 |
| average score | 0.918442 | 0.970143 | 0.965643 | 1.000000 |
fig = plt.figure()
plt.subplot()
sns.heatmap(data[subjects].corr(), annot=True)
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kWpxCHDy-1639906825715)(output_33_0.png)]
从上面的表与图中,我们可以看出,“文科”学科成绩之间的相关程度,要高于“文科”与“理科”学科成绩之间的相关程度。而且考虑到本数据集中“文科”的科目要多于“理科”的科目,“文科”成绩与平均成绩的相关程度更高。
一般意义而言,社会认为上男生更擅长理科,而女生更擅长文科。我们将使用统计学验证这一看法是否适用于本数据集。
我们引入卡方独立性检验,判断性别与学科掌握程度方面是否是独立不相关的。
- H0:数学成绩与性别无关系。
- H1: 数学成绩与性别有关系。
将数学成绩进行分箱,分箱方式与前述对平均成绩的分箱方式相关
math_grading = pd.cut(data[‘math percentage’], bins=[0, 0.59, 0.69, 0.79, 0.89, 100],
labels=[‘F’, ‘D’, ‘C’, ‘B’, ‘A’] )
crosstab = pd.crosstab(math_grading, data[‘sex’])
引入卡方独立性检验
result = stats.chi2_contingency(crosstab)
print(f’p值为:{result[1]}')
p值为:3.052111718576621e-05
**原假设不成立,即学生的数学成绩与性别并不独立。**在此基础上,我们进一步查看不同性别下,学生在数学科目的表现。
data.groupby(‘sex’)[[‘math percentage’]].agg([np.mean, np.median])
| math percentage | |
|---|---|
| mean | |
| sex | |
| F | 0.636332 |
| M | 0.687282 |
fig, ax = plt.subplots(1,2, figsize=(10, 5))
sns.boxplot(data=data, y=‘math percentage’, x=‘sex’, palette=‘summer’, ax=ax[0])
sns.histplot(data=data, x=‘math percentage’, hue=‘sex’, fill=True, ax=ax[1], stat=‘probability’)
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qV7fOTYc-1639906825716)(output_41_0.png)]
在数学科目的平均分以及中位数两大统计指标上,我们可以看出,男性在该科目的确占有一定优势。两者的数学成绩分布大致都符合正态分布,但男性在样本方差明显更小,且在高分部分,男性出现的概率更大——男性在数学上的整体表现,要优于女性。
下面我们继续观察男女性在文科科目上的表现,在这里,我们选取writing score percentage标签,做为研究对象。
data.groupby(‘sex’)[[‘writing score percentage’]].agg([np.mean, np.median])
| writing score percentage | |
|---|---|
| mean | |
| sex | |
| F | 0.724672 |
| M | 0.633112 |
fig = px.histogram(
data, x=‘writing score percentage’,
marginal=‘box’, opacity=0.6,
color=‘sex’,
histnorm=‘probability’,
title=‘男生与女生在文科上的表现’,
template=‘plotly_white’
)
fig.update_layout(barmode=‘overlay’, width=800)
fig.show()
从所估计的概率密度图上看,女生在writing score percentage的高分领域,女性出现的概率要远高于男生,而在低分领域则正好相反。综合来看男生,男生的确更擅长理科,而女生则相反。
3.3 高分学生人群画像
3.3.1 父母学历
下面我们分析高分(均分高于90分)考生的画像,首先我们探究高分与父母受教育程度间的关系。
honor_students = data.loc[data[‘average score’]>=0.9] # 选取均分高于0.9的学生,组成子数据集honor_students
honor_count = honor_students[‘parental level of education’].value_counts().sort_index()
total_count = data[‘parental level of education’].value_counts().sort_index()
fig = make_subplots(rows=1, cols=2, specs=[[dict(type=‘domain’),{‘type’:‘domain’}]])
fig.add_pie(
values=total_count.values, hole=0.4, labels=total_count.index,
row=1, col=1, name=‘整体学生父母受教育程度’
)
fig.add_pie(
values=honor_count.values, hole=0.4, labels=honor_count.index,
row=1, col=2, name=‘高分学生父母受教育程度’
)
fig.update_layout(
title_text=“学生父母受教育程度”,
annotations=[dict(text=‘整体父母’, x=0.15, y=0.5, font_size=20, showarrow=False),
dict(text=‘高分父母’, x=0.85, y=0.5, font_size=20, showarrow=False)],
width=900
)
fig.show()
从上图所示,我们发现,高分考生父母的教育程度,要高于整体考生父母的教育程度,其中高分考生父母拥有副学士、学士、硕士的比例,相较于整体考生,分别从22.9%, 11.8%, 5.9%上升至31.5%, 24.1%, 11.1%。
整体来看,高分学生的父母,约有90%都曾接受过大学教育。
不仅仅是高分学生父母的所受教育程序较高,实际上,在本数据集中,所有学生的平均分,皆与父母的教育程度正相关。下表给出了不同教育程度的父母,以及对应考生群体平均分。其中,其中学历为硕士与高中的父母,子女的平均分分别为73分及63分。
data.groupby(‘parental level of education’)[‘average score’].mean().sort_values()
parental level of education
high school 0.631224
some high school 0.650726
some college 0.684469
associate’s degree 0.695586
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
ate’s degree 0.695586
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
[外链图片转存中…(img-3A5slTh3-1715189978159)]
[外链图片转存中…(img-1ofJVLxG-1715189978160)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









