








网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
🦋2.6 Queue
Queue是一种具有先进先出(FIFO)特性的数据结构。它的实现可以通过数组或链表来完成。
在数组实现的Queue中,需要定义一个数组来保存元素,以及两个指针front和rear来分别指向队头和队尾。当元素入队时,rear指针向后移动,并将元素添加到rear指针所指向的位置;当元素出队时,front指针向后移动,将front指针所指向的元素删除。
在链表实现的Queue中,每个节点都有一个指针指向下一个节点,队头则是链表的第一个节点,队尾是链表的最后一个节点。元素入队时,将元素添加到链表的末尾;元素出队时,删除链表的第一个节点。
Queue的特性使得它在很多场景下都很有用,比如处理任务调度、消息队列、缓存等。实际上,很多编程语言都提供了Queue的实现,可以直接使用。
🦋2.7 Stack
Stack类可以用来创建栈对象,该栈对象按照先进后出的规则存储元素。
Stack类基于泛型定义,要求存储位置需要是一片连续的内存空间,初始容量大小为8,并且支持动态扩容。每次扩容大小是原始容量的1.5倍。Stack类底层基于数组实现,入栈和出栈操作都是在数组的一端进行。
Stack类和Queue类相比,Queue类基于循环队列实现,只能在一端进行删除操作,而在另一端进行插入操作。而Stack类则只在一端进行操作。
一般情况下,如果满足先进后出的场景,可以使用Stack类。
🦋2.8 线性容器的使用
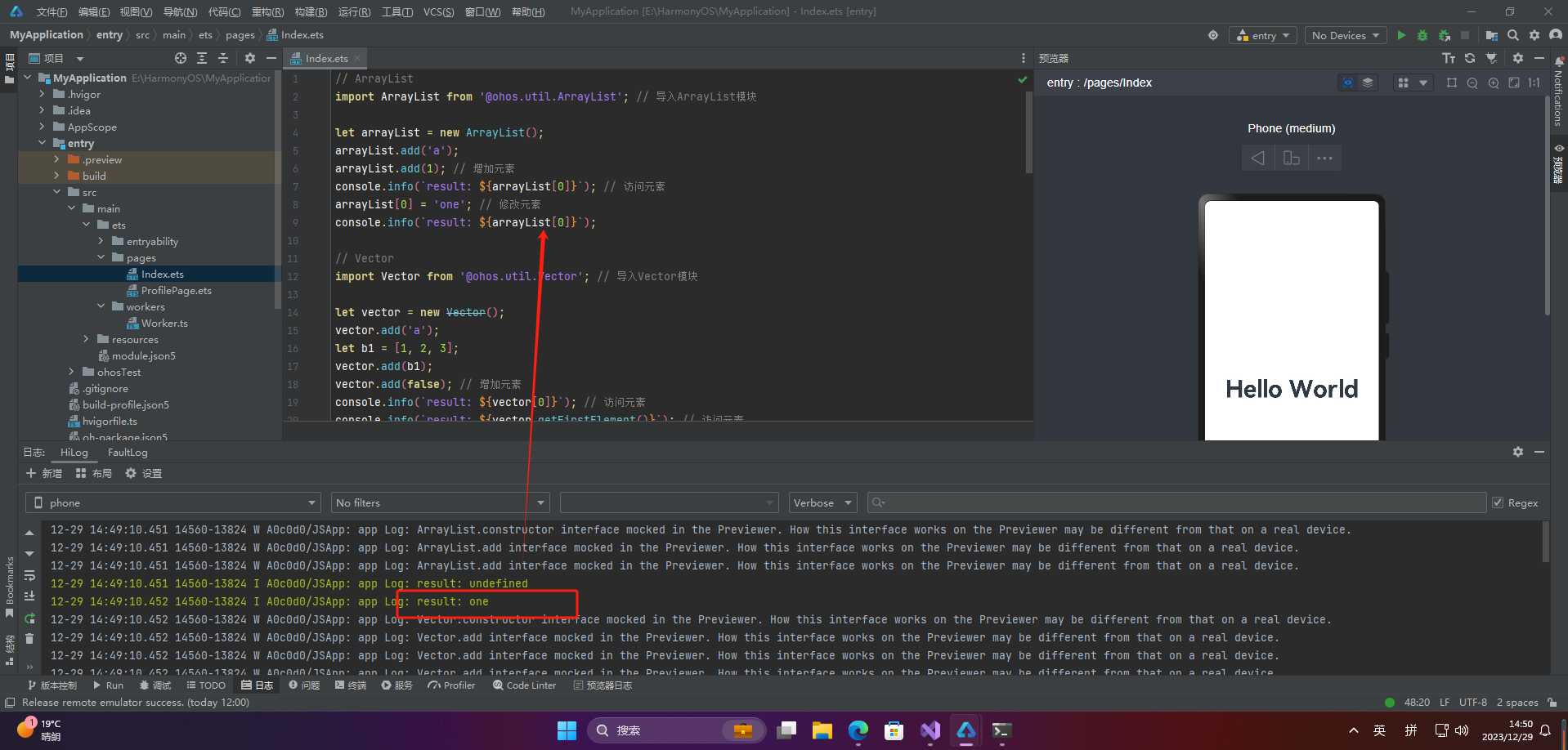
// ArrayList
import ArrayList from ‘@ohos.util.ArrayList’; // 导入ArrayList模块
let arrayList = new ArrayList();
arrayList.add(‘a’);
arrayList.add(1); // 增加元素
console.info(result: ${arrayList[0]}); // 访问元素
arrayList[0] = ‘one’; // 修改元素
console.info(result: ${arrayList[0]});
// Vector
import Vector from ‘@ohos.util.Vector’; // 导入Vector模块
let vector = new Vector();
vector.add(‘a’);
let b1 = [1, 2, 3];
vector.add(b1);
vector.add(false); // 增加元素
console.info(result: ${vector[0]}); // 访问元素
console.info(result: ${vector.getFirstElement()}); // 访问元素
// Deque
import Deque from ‘@ohos.util.Deque’; // 导入Deque模块
let deque = new Deque;
deque.insertFront(‘a’);
deque.insertFront(1); // 增加元素
console.info(result: ${deque[0]}); // 访问元素
deque[0] = ‘one’; // 修改元素
console.info(result: ${deque[0]});
// Stack
import Stack from ‘@ohos.util.Stack’; // 导入Stack模块
let stack = new Stack();
stack.push(‘a’);
stack.push(1); // 增加元素
console.info(result: ${stack[0]}); // 访问元素
stack.pop(); // 删除栈顶元素并返回该删除元素
console.info(result: ${stack.length});
// List
import List from ‘@ohos.util.List’; // 导入List模块
let list = new List;
list.add(‘a’);
list.add(1);
let b2 = [1, 2, 3];
list.add(b2); // 增加元素
console.info(result: ${list[0]}); // 访问元素
console.info(result: ${list.get(0)}); // 访问元素
好像在预览模式下,效果不尽人意
2.非线性容器
🦋2.1 HashMap
HashMap是一个非常常用的集合类,用来存储键值对。它通过key的hashCode值来确定key的存储位置,从而实现快速查找。由于HashMap的实现采用了链表来解决冲突问题,所以当存在多个key的hashCode相同时,它们会被放在同一个链表中。这也是为什么HashMap可以存储多个值对应同一个key的原因。
HashMap的初始容量为16,当容量不足时,会自动进行扩容,每次扩容容量会变为原来的两倍。这样可以减少扩容的次数,提高性能。
🦋2.2 HashSet
HashSet内部使用了HashMap作为其底层数据结构,将元素存储在HashMap的key中,而HashMap的value则统一为一个固定的对象(称为PRESENT)。HashSet中的元素实际上是HashMap的键值对中的key部分,而value部分无意义。
HashSet的存取速度很快,插入和删除操作的时间复杂度均为O(1)。HashSet具有去重的功能,即当添加重复元素时只保留一个副本。HashSet允许存储空值(null)。
HashSet的元素存储是无序的,即元素的顺序不固定。如果需要有序存储元素,可以使用LinkedHashSet。HashSet适用于需要存储不重复元素且对元素的顺序没有特殊要求的场景。
🦋2.3 TreeMap
TreeMap是一种用于存储键值对的有序映射的数据结构。并且根据键的自然顺序或按指定的比较器对键进行排序。TreeMap基于红黑树实现,因此它的键值对是有序的。与HashMap不同,TreeMap的键是唯一的,并且不能为null,而值可以为null。
TreeMap提供了一些常用的方法,例如put(key, value)用于将键值对添加到TreeMap中,get(key)用于根据键获取对应的值,containsKey(key)用于检查TreeMap中是否包含指定的键,remove(key)用于删除指定键的键值对等。
由于TreeMap是有序的,它的键值对是按照键的自然顺序或者按照指定的比较器进行排序的。这使得TreeMap非常适合用于根据键的排序来遍历数据,或者获取一段范围内的数据。
🦋2.4 TreeSet
TreeSet可用来存储一系列值的集合,存储的元素中value是唯一的。它依据泛型定义,集合中的value值是有序的,底层是一棵二叉树,可以通过树的二叉查找快速找到该value值,value的类型满足ECMA标准中要求的类型。TreeSet中的值是有序存储的,底层基于红黑树实现,可以进行快速的插入和删除。
TreeSet基于TreeMap实现,只对value对象进行处理。它可用于存储一系列值的集合,元素中value唯一且有序。
与HashSet相比,HashSet中的数据无序存放,而TreeSet是有序存放。它们集合中的元素都不允许重复,但HashSet允许放入null值,而TreeSet不建议插入空值,可能会影响排序结果。
一般需要存储有序集合的场景,可以使用TreeSet。
🦋2.5 LightWeightMap
LightWeightMap是一个用来存储具有关联关系的key-value键值对集合的数据结构。其中,每个key都是唯一的,且对应一个value值。LightWeightMap采用了更加轻量级的结构,并使用hash来标识唯一的key。在冲突发生时,采用线性探测法来解决。
集合中的key值的查找过程依赖于hash值和二分查找算法。首先将所有的key的hash值存储在一个数组中,然后通过这些hash值来映射到其他数组中的key值和value值。key的类型需要满足ECMA标准中的要求。
🦋2.6 LightWeightSet
LightWeightSet是一种用来存储一系列值的集合,其中存储的元素的value值是唯一的。它采用泛型定义,并使用了轻量级的结构。初始默认容量大小为8,每次扩容大小为原始容量的2倍。
在LightWeightSet中,value值的查找依赖于hash和二分查找算法。具体来说,它使用一个数组存储hash值,并将hash值映射到其他数组中的value值中。这里的value的类型需要满足ECMA标准中的要求。
LightWeightSet底层使用hash实现了对唯一value的标识,并采用了线性探测法作为冲突策略。它的查找策略基于二分查找法。
与HashSet相比,LightWeightSet占用的内存更小。因此,当需要存取某个集合或对某个集合进行去重时,推荐使用占用内存更小的LightWeightSet。
🦋2.7 PlainArray
PlainArray可以看作是一个轻量级的数组,其特点是key值的类型为number,并且每个key对应一个value值。它适用于存储具有关联关系的键值对集合,其中key是唯一的。
由于PlainArray采用了更加轻量级的结构,所以对于查找操作,它依赖于二分查找算法来找到对应key值的索引,然后再通过该索引映射到其他数组中的value值。
通过使用PlainArray,我们可以高效地存储和查找键值对集合,尤其适用于大规模数据的情况下。它提供了一种轻量级的、基于数组的存储方式,既可以保持键值对的关联关系,又可以提供高效的查找操作。
PlainArray和LightWeightMap都是用来存储键值对,且均采用轻量级结构,但PlainArray的key值类型只能为number类型。
🦋2.8 非线性容器的使用
// HashMap
import HashMap from ‘@ohos.util.HashMap’; // 导入HashMap模块
let hashMap = new HashMap();
hashMap.set(‘a’, 123);
hashMap.set(4, 123); // 增加元素
console.info(result: ${hashMap.hasKey(4)}); // 判断是否含有某元素
console.info(result: ${hashMap.get('a')}); // 访问元素
// TreeMap
import TreeMap from ‘@ohos.util.TreeMap’; // 导入TreeMap模块
let treeMap = new TreeMap();
treeMap.set(‘a’, 123);
treeMap.set(‘6’, 356); // 增加元素
console.info(result: ${treeMap.get('a')}); // 访问元素
console.info(result: ${treeMap.getFirstKey()}); // 访问首元素
console.info(result: ${treeMap.getLastKey()}); // 访问尾元素

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
辄止,不再深入研究,那么很难做到真正的技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









