







深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
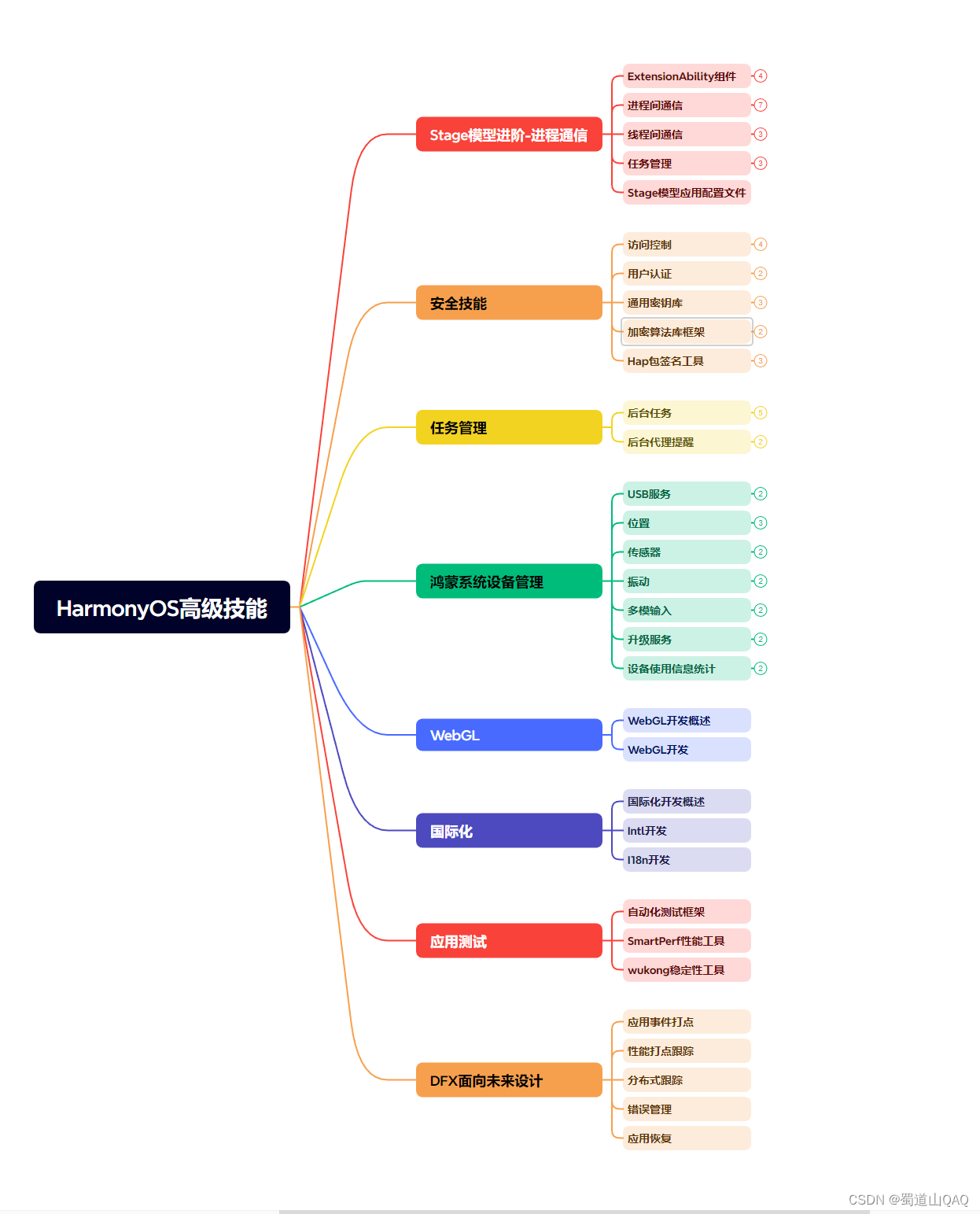
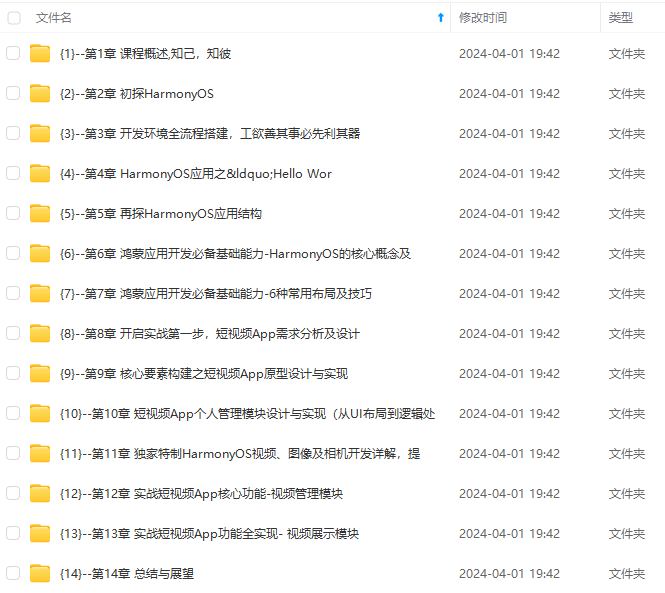

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
(1) 遍历A
判断B.contains(A[i])
若不包含,则 A[w] = A[i] w从0递增
(2) 遍历完成则将 A[w]往后部分置为 null
(3) 看下上面(1)的B.contains(A[i])的逻辑:
遍历B,一个个匹配,匹配到则返回B的index
简单来讲,两层循环时间复杂度就是O(n*m),如果ArrayList的大小为m,参数c的大小为c,且c < m,则在最坏情况下(即c中的所有元素都存在于ArrayList中),总的时间复杂度为O(m^2)
这就是平方级的时间复杂度。看来要解决此问题,就需要寻找其他方案
三、使用linkeList
对于删除操作,链表肯定是具备先天优势的,但是使用后发现, 时间有提升,但是效果不大,查看代码发现:
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
boolean modified = false;
Iterator<?> it = iterator();
while (it.hasNext()) {
if (c.contains(it.next())) {
it.remove();
modified = true;
}
}
return modified;
}
它是循环使用next 取,完后remove 的,那效果自然也不行,但是如果我们自定义链表,直接修改删除区间集合的指针,倒是一个完美的解决方案,但是自定义数据结果,在业务中使用风险太大。
四、利用hashSet 解决
上面的耗时基本是来自两个方面
- 遍历
- 遍历 + 移动元素
那我们可以优先从遍历入手,大家都知道Hash 的查询时间是O(1), 这样的话用hash和LinkedList 就能更进一步优化耗时了
看下代码:
public static <T> List<T> removeAll(List<T> source, List<T> target) {
LinkedList<T> result = new LinkedList<>();
HashSet<T> hashSet = new HashSet<>(source);
for (T t : source) {
if (!hashSet.contains(t)) {
result.add(t);
}
}
return result;
}
从source列表中移除与target列表中相同的元素,并将移除后的结果存储在一个新的列表中返回,以达到我们想要的效果,

在当时的业务中也是优化到了100ms 以内。
但是这个方式还存在一个弊端,当source非常大,target 又比较小时、或者都非常大时,还是会存在耗时。
五、利用空间换时间
我们在学习算法的时候,大家都听过一句话,算法优化基本就是时间换空间或者空间换时间,当我们需要确定一个参数优化到极致时,我们就可以在另一个方向上做优化。
我们验证一下:
思路是这样的,我们直接反取目标数据,
比如,从10万条数据中删除第1000到3000 的数据,那我们可以反取数据,取出0到999生成一个新集合,再取3001到10万为一个集合,最后再将二者的数据合并,加到目标集合中。
public static void main(String[] args) {
ArrayList<Demo> list = new ArrayList<>();
for (int i = 0; i < 100000; i++) {
list.add(new Demo("index=", i));
}
long start = System.currentTimeMillis();
// 创建集合
ArrayList<Demo> demos1 = new ArrayList<>(list.subList(0, 999));
ArrayList<Demo> demos2 = new ArrayList<>(list.subList(1000, list.size() - 1));
// removeAll(list, demos);
list.clear();
list.addAll(demos1);
list.addAll(demos2);
System.out.println("用时 " + (System.currentTimeMillis() - start));
}

在我们业务中,从900ms 优化到5ms, 效果是非常不错的,并且复杂数据测试的规模是10万中删除3000,基本满足大型列表删除场景了。
六、总结
为什么要写这个记录,都是一个非常简单的场景及使用方式,但是从发现这个问题到思考怎么解决却是一次算法学习的实际应用。我们在开发中,不会经常使用算法,但是像这种问题,我们可以用算法的角度去分析优化,这大概就是算法学习的意义
为了帮助到大家更好的全面清晰的掌握好性能优化,准备了相关的核心笔记(还该底层逻辑):https://qr18.cn/FVlo89
性能优化核心笔记:https://qr18.cn/FVlo89
启动优化

内存优化

UI优化

网络优化

Bitmap优化与图片压缩优化:https://qr18.cn/FVlo89

多线程并发优化与数据传输效率优化

体积包优化

《Android 性能监控框架》:https://qr18.cn/FVlo89


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
么很难做到真正的技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









