






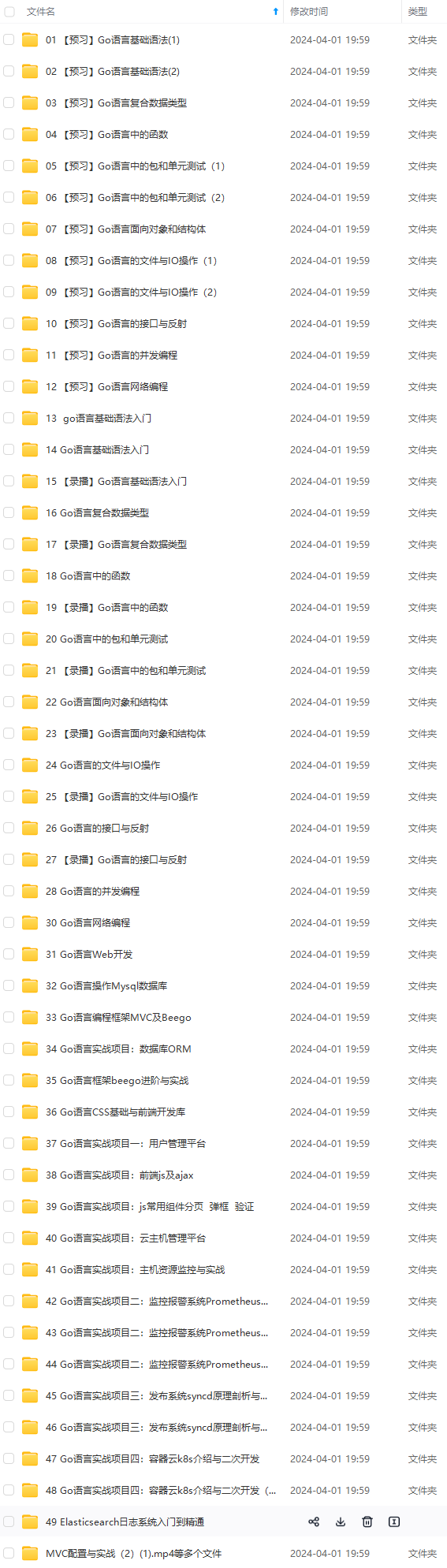
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
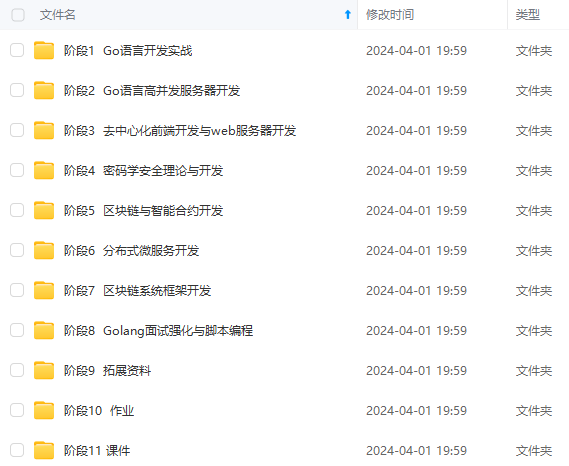
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
9.1. 修改节点内容:
BeautifulSoup 提供了 replace_with 方法来替换节点的内容。可以使用该方法修改节点的文本内容或标签。
例如,将一个节点的文本内容替换为新的内容可以这样写:
node = soup.find('p')
node.string.replace_with('New Content')
这将把该节点的文本内容替换为 'New Content'。
9.2. 遍历节点树:
使用 BeautifulSoup,可以通过遍历节点树的方式来访问和处理文档中的节点。可以使用 children、descendants、next_sibling、previous_sibling 等方法来访问不同层级和关系的节点。
例如,遍历并打印所有子节点的文本内容可以这样写:
for child in soup.body.children:
print(child.string)
9.3. 处理 XML 文档:
BeautifulSoup 不仅可以用于解析 HTML 文档,也可以用于解析 XML 文档。可以使用相同的方法和属性来处理 XML 文档。
例如,解析 XML 文档可以这样写:
soup = BeautifulSoup(xml_string, 'xml')
然后就可以使用 BeautifulSoup 提供的方法和属性来访问和处理 XML 文档。
以上是一些关于 BeautifulSoup 库的其他功能和扩展的说明。通过学习和实践这些功能,你可以更加灵活地处理和操作文档中的节点,完成更复杂的任务和需求。阅读官方文档和参考示例代码也是掌握这些功能的好方法。
10. 案例
案例1: 修改节点内容
假设我们有一个 HTML 文档,其中一个 <p> 标签包含了一段旧的文本内容。我们想要将这段文本内容替换为新的内容。
from bs4 import BeautifulSoup
html = '''
<html>
<body>
<p>旧的文本内容</p>
</body>
</html>
'''
soup = BeautifulSoup(html, 'html.parser')
node = soup.find('p')
node.string.replace_with('新的文本内容')
print(soup)
输出:
<html>
<body>
<p>新的文本内容</p>
</body>
</html>
在这个案例中,我们使用 find 方法找到了 <p> 标签的节点,然后使用 replace_with 方法将节点的文本内容替换为 '新的文本内容'。
案例2: 遍历节点树
假设我们有一个 HTML 文档,其中包含了一些嵌套的标签,我们想要遍历并打印所有的文本内容。
from bs4 import BeautifulSoup
html = '''
<html>
<body>
<div>
<p>第一个段落</p>
<p>第二个段落</p>
</div>
</body>
</html>
'''
soup = BeautifulSoup(html, 'html.parser')
for child in soup.body.children:
if child.string:
print(child.string)
输出:
第一个段落
第二个段落
在这个案例中,我们使用了 children 方法来访问 body 标签下的子节点。然后我们使用了 string 属性来获取节点的文本内容,并进行打印。
案例3: 处理 XML 文档
除了解析 HTML 文档,BeautifulSoup 也可以用于解析 XML 文档。我们可以使用相同的方法和属性来处理 XML 文档。
from bs4 import BeautifulSoup
xml = '''
<root>
<person>
<name>John</name>
<age>30</age>
</person>
<person>
<name>Jane</name>
<age>25</age>
</person>
</root>
'''
soup = BeautifulSoup(xml, 'xml')
persons = soup.find_all('person')
for person in persons:
name = person.find('name').string
age = person.find('age').string
print(f"Name: {name}, Age: {age}")
输出:
Name: John, Age: 30
Name: Jane, Age: 25
在这个案例中,我们使用了 'xml' 参数来指定解析器,告诉 BeautifulSoup 这是一个 XML 文档。然后我们使用了 find_all 方法来找到所有的 person 标签,进而获取每个 person 标签下的 name 和 age 的文本内容,并进行打印。
这些案例展示了 BeautifulSoup 库的其他功能和扩展的用法。你可以根据自己的需求和任务,使用这些功能来解析、处理和操作文档中的节点。
11. 练习题
练习题1: 获取所有链接
给定一个 HTML 文档,编写一个程序来获取所有的链接,并打印出链接的文本内容和对应的 URL。
from bs4 import BeautifulSoup
html = '''
<html>
<body>
<a href="https://www.example1.com">Link 1</a>
<a href="https://www.example2.com">Link 2</a>
<a href="https://www.example3.com">Link 3</a>
</body>
</html>
'''
soup = BeautifulSoup(html, 'html.parser')
links = soup.find_all('a')
for link in links:
text = link.string
url = link['href']
print(f"Text: {text}, URL: {url}")
练习题2: 提取图片链接
给定一个 HTML 文档,编写一个程序来提取所有图片的链接,并打印出链接的 URL。
from bs4 import BeautifulSoup
html = '''
<html>
<body>
<img src="https://www.example.com/image1.jpg">
<img src="https://www.example.com/image2.jpg">
<img src="https://www.example.com/image3.jpg">
</body>
</html>
'''
soup = BeautifulSoup(html, 'html.parser')
images = soup.find_all('img')
for image in images:
url = image['src']
print(f"URL: {url}")
练习题3: 计算总字数
给定一个 HTML 文档,编写一个程序来计算文档中所有节点的文本内容的总字数。
from bs4 import BeautifulSoup
html = '''
<html>
<body>
<h1>标题</h1>
<p>第一段文本</p>
<p>第二段文本</p>
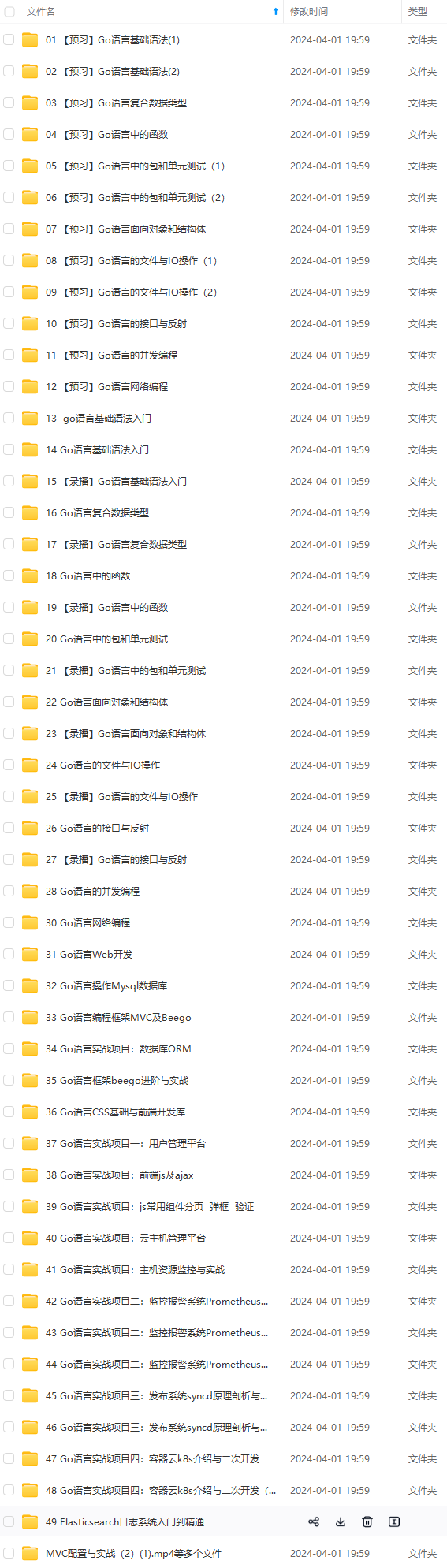
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618658159)**
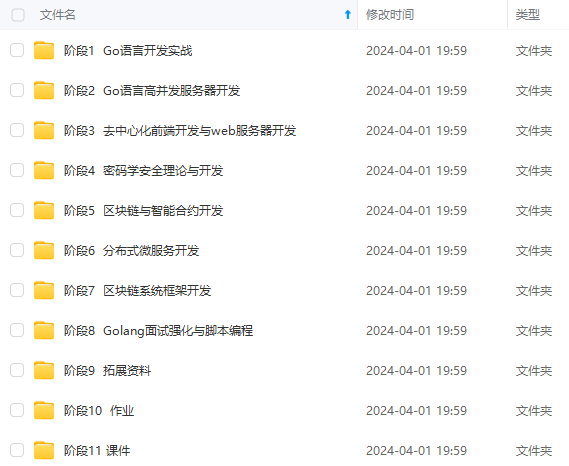
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
285)]
[外链图片转存中...(img-2LWI6BBP-1715826724285)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618658159)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









