








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
c.L.Unlock()
// 协程B
…
c.Broadcast()
不过,在实践中并不经常使用 sync.Cond ,因为在很多场景下,我们都可以使用更为强大的通道。不过为了更透彻地讲解 sync.Cond,我们再来看几个可能会用到 sync.Cond 的例子。
第一个场景是这样的。我们设计的营销策略希望当在线用户达到 100 人之后,对前 10 位用户进行奖励。代码如下所示。
这里的判断条件就是,用户是否达到 100 人。如果用户没有达到 100 人,执行就会陷入堵塞。 而另一个程序,每个用户上线后都会发送通知信号,唤醒等待的协程。
// 协程A
cond.L.Lock()
for len(users) < 100 {
cond.Wait()
}
givePrizes(users[:10])
cond.L.Unlock()
// 协程B
cond.L.Lock()
users = append(users, newUser)
cond.L.Unlock()
cond.Signal()
另外,如果程序收到了终止信号(例如开发者按下了 Ctrl+C), 我们也希望程序能够通知所有协程关闭资源并退出。这时,我们需要增加判断条件,只有当在线用户小于 100 人并且程序没有终止时才会陷入堵塞。代码修改如下:
cond.L.Lock()
for len(users) < 100 && !shutdown {
cond.Wait()
}
if shutdown {
cond.L.Unlock()
return
}
givePrizes(users[:10])
cond.L.Unlock()
sync.Cond 有**堵塞与唤醒**的语义,并且可以将通知者与等待者解耦,通知者不必知道具体的条件细节,所以程序会更加灵活。如果我们遇到了类似的场景,可以在合适的情况下使用 sync.Cond 。 不过我们也要小心,一旦忘记了释放锁或者忘记了唤醒协程,sync.Cond 可能遇到死锁问题。
我们还可以参考 Go 源码对 sync.Cond 的使用。例如[Go 在构建内存管道时](https://bbs.csdn.net/topics/618658159)使用了 sync.Cond。其中,pipe.Read 方法会循环读取管道中的数据,如果没有数据,则陷入到等待中。
func (p *pipe) Read(d []byte) (n int, err error) {
p.mu.Lock()
defer p.mu.Unlock()
for {
…
if p.b != nil && p.b.Len() > 0 {
return p.b.Read(d)
}
p.c.Wait()
}
}
而 pipe.Write 则会在管道另一端写入数据后,唤醒第一个等待读取的协程。
func (p *pipe) Write(d []byte) (n int, err error) {
p.mu.Lock()
defer p.mu.Unlock()
if p.c.L == nil {
p.c.L = &p.mu
}
defer p.c.Signal()
if p.err != nil {
return 0, errClosedPipeWrite
}
if p.breakErr != nil {
p.unread += len(d)
return len(d), nil // discard when there is no reader
}
return p.b.Write(d)
}
## Go并发模式
### Ping-Pong
ping-pong 模式即乒乓球模式,它比较形象地呈现了数据之间一来一回的关系。收到数据的协程可以在不加锁的情况下对数据进行处理,而不必担心有并发冲突。
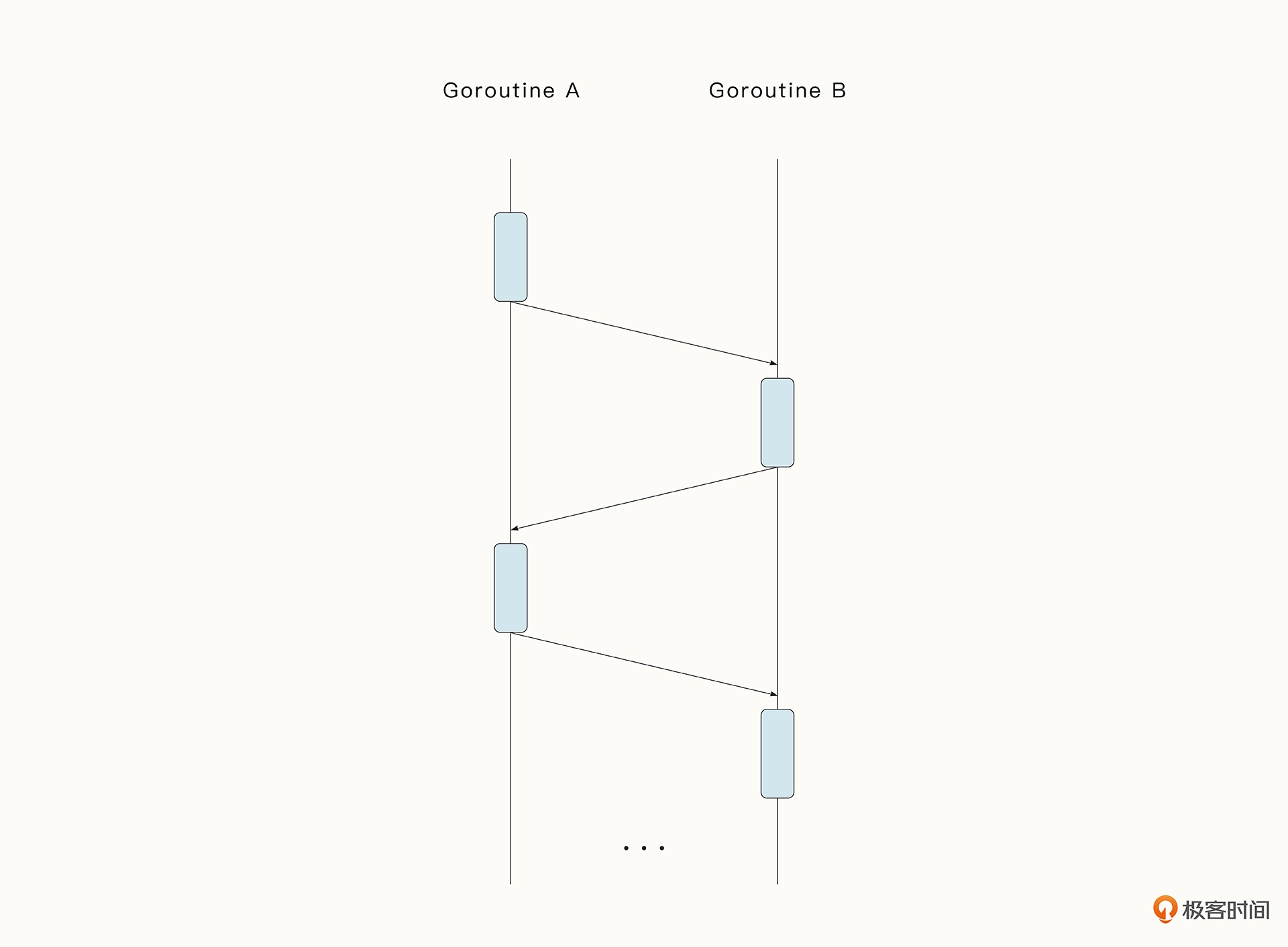
实例代码如下所示。两个协程 player 就相当于两个球员,而通道 table 则类似于球桌。
func main(){
var Ball int
table:= make(chan int)
go player(table)
go player(table)
table<-Ball
time.Sleep(1*time.Second)
<-table
}
func player(table chan int) {
for{
ball:=<-table
ball++
time.Sleep(100*time.Millisecond)
table<-ball
}
}
你可以想一想,如果我们把两个 player 扩展为多个 player,是不是就有点像很多人在踢毽子了。当我们遇到类型的问题,可以用这一简单的模式来进行抽象。
### fan-in
fan-in 模式又叫扇入模式,意思是多个协程把数据写入到通道中,但只有一个协程等待读取通道数据。
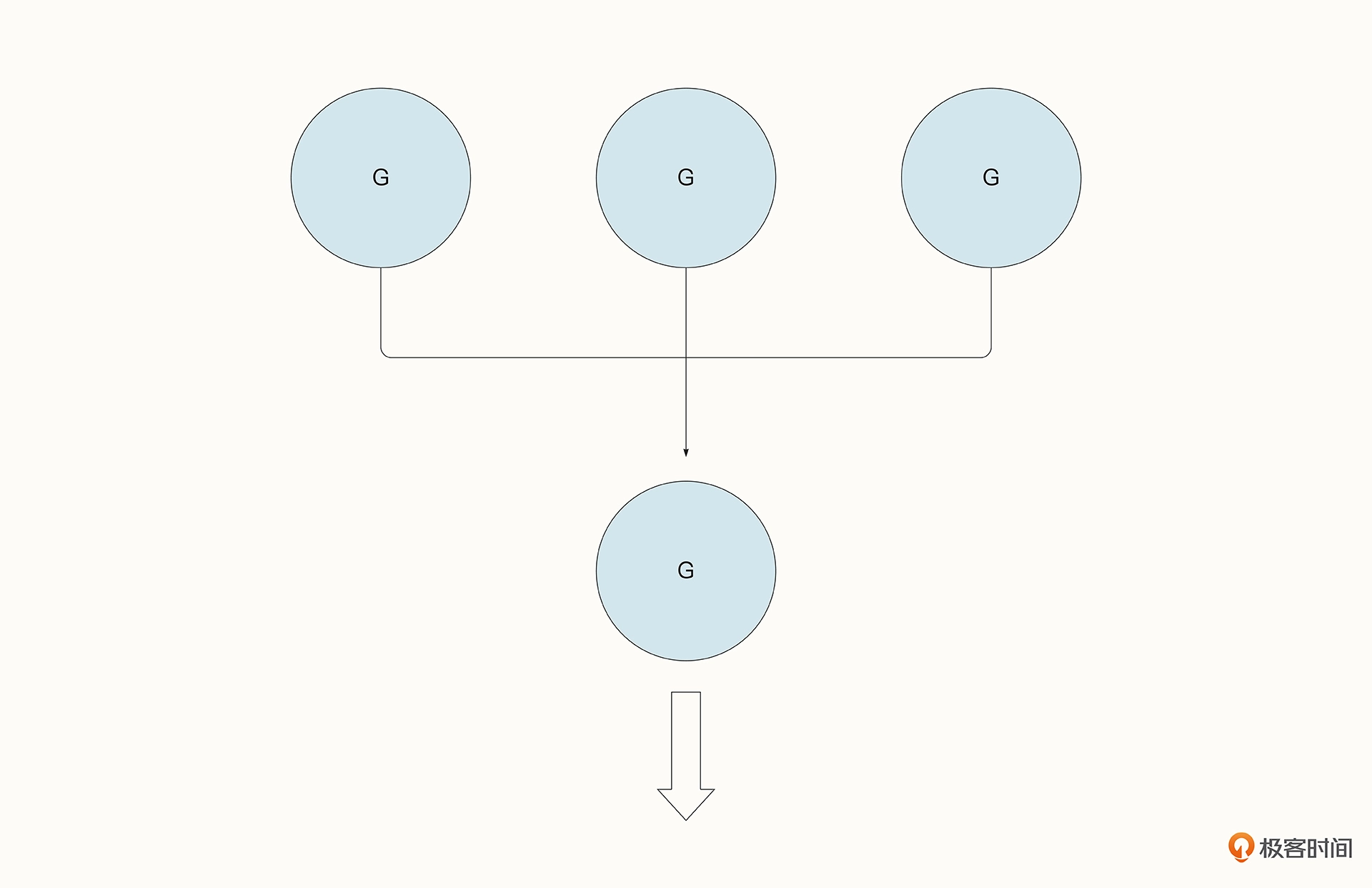
这种模式在实践中有很多应用场景。举个例子,我们想查找某一个文件夹中有没有特殊的关键字。当文件数量很多时,我们可以用并发的方式去查找,找到结果后输出到相同的通道中打印出来。
func search(ch chan string, msg string) {
var i int
for {
// 模拟找到了关键字
ch <- fmt.Sprintf(“get %s %d”, msg, i)
i++
time.Sleep(1000 * time.Millisecond)
}
}
func main() {
ch := make(chan string)
go search(ch, “jonson”)
go search(ch, “olaya”)
for i := range ch {
fmt.Println(i)
}
}
不过,fan-in 模式在读取数据时,并不总是只有一个通道。它也可以同时读取多个通道的内容,以多路复用的形式存在。让我们把上面的例子改造一下,现在 search 函数会返回一个新的通道,并新建协程把数据写入到这个通道中。在读取数据时,我们要监听 ch1、ch2 两个协程,并使用 select 来实现多路复用。
func search(msg string) chan string {
var ch = make(chan string)
go func() {
var i int
for {
ch <- fmt.Sprintf(“get %s %d”, msg, i)
i++
time.Sleep(100 * time.Millisecond)
}
}()
return ch
}
func main() {
ch1 := search(“jonson”)
ch2 := search(“olaya”)
for {
select {
case msg := <-ch1:
fmt.Println(msg)
case msg := <-ch2:
fmt.Println(msg)
}
}
}
fan-in 模式比较清晰,在实际中也是很常见的。例如我们之后在项目中会看到,通过 fan-in 模式来整合爬取到的数据,并存储起来。
### fan-out
fan-out 模式与 fan-in 模式相反,它描述的是一个协程完成数据的写入,但是多个协程抢夺同一个通道中的数据的场景。
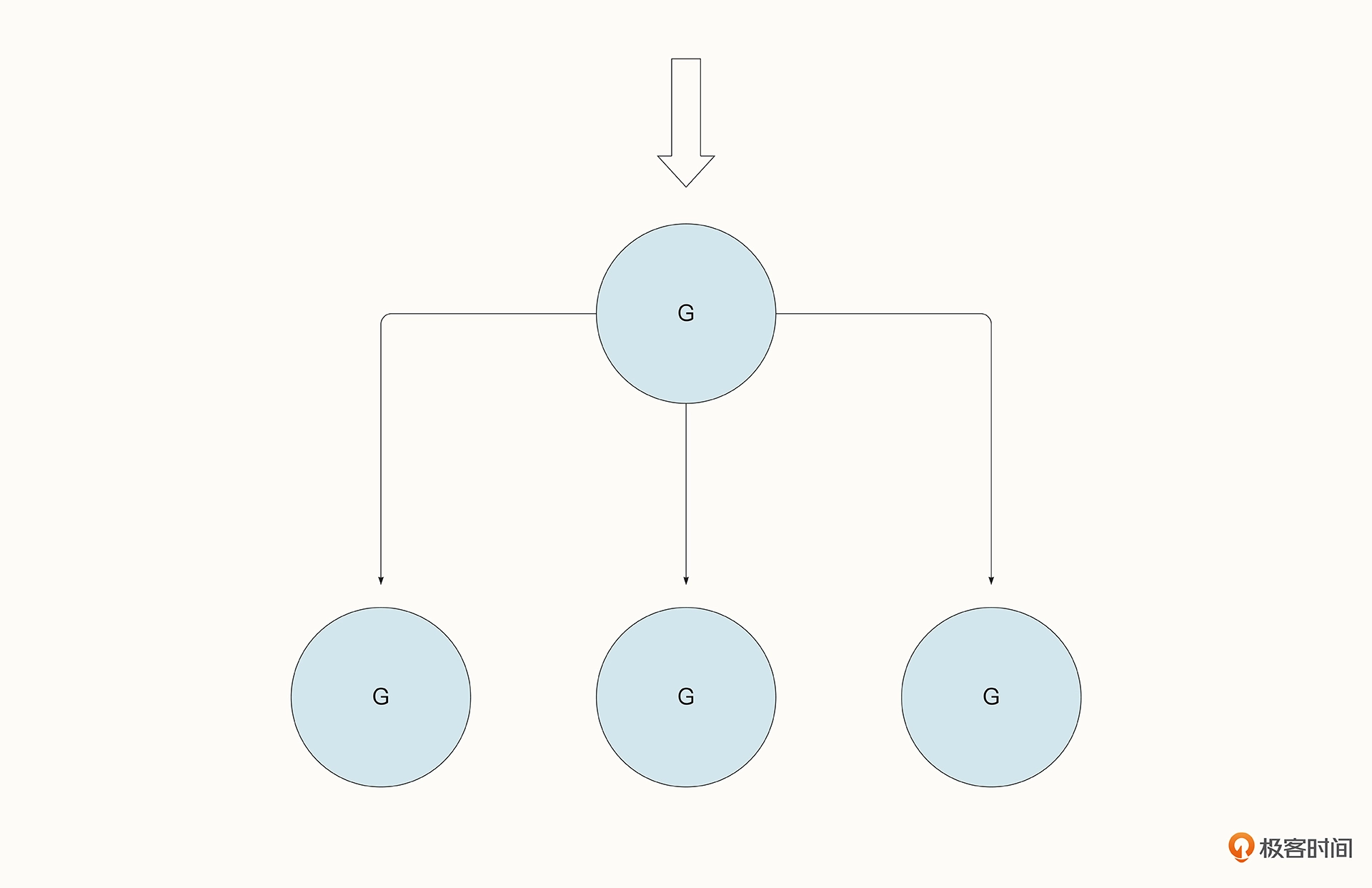
Fan-out 模式通常会用在任务的分配中。比方说,程序消费 Kafka、NATS 等中间件的数据,多个协程就会监听同一个通道中的数据,读到数据后立即进行后续的处理,处理完毕后再继续读取,循环往复。
以下面的代码为例。多个 Worker 监听同一个协程,而 tasksCh <- i 会把任务分配到 Worker 中去。fan-out 模式使 Worker 得到了充分的利用,并且任务的分配也实现了负载均衡,哪一个 Worker 闲下来了就会自动去领取新的任务(注意,示例代码中的 sync.WaitGroup 只是为了防止 main 函数提前退出):
func worker(tasksCh <-chan int, wg *sync.WaitGroup) {
defer wg.Done()
for {
task, ok := <-tasksCh
if !ok {
return
}
d := time.Duration(task) * time.Millisecond
time.Sleep(d)
fmt.Println(“processing task”, task)
}
}
func pool(wg *sync.WaitGroup, workers, tasks int) {
tasksCh := make(chan int)
for i := 0; i < workers; i++ {
go worker(tasksCh, wg)
}
for i := 0; i < tasks; i++ {
tasksCh <- i
}
close(tasksCh)
}
func main() {
var wg sync.WaitGroup
wg.Add(36)
go pool(&wg, 36, 50)
wg.Wait()
}
在生产实践中,我们还可以在上面这个例子的基础上构建出更复杂的模型,例如每一个 Worker 中还可以分出多个 Subwoker。
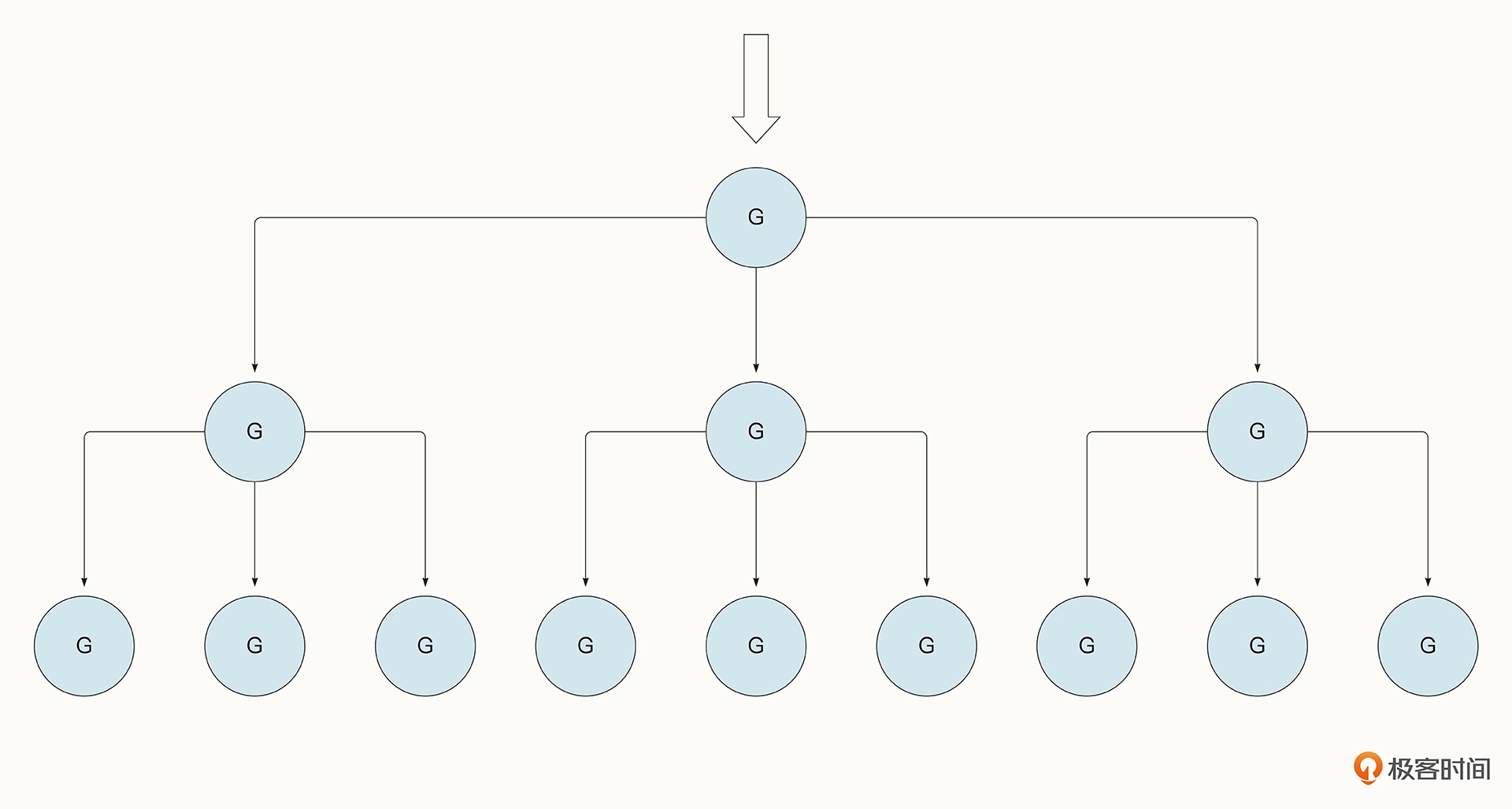
接下来我们就尝试在前例的基础上构建出具有 Subworker 的并发模式。
如下所示,Worker 也变成了类似调度的模式,Worker 创建出了多个 Subworker 的工作线程,并通过 subtasks <- task1 将任务分发到了 Subworker 中。
const (
WORKERS = 5
SUBWORKERS = 3
TASKS = 20
SUBTASKS = 10
)
func subworker(subtasks chan int) {
for {
task, ok := <-subtasks
if !ok {
return
}
time.Sleep(time.Duration(task) * time.Millisecond)
fmt.Println(task)
}
}
func worker(tasks <-chan int, wg *sync.WaitGroup) {
defer wg.Done()
for {
task, ok := <-tasks
if !ok {
return
}
subtasks := make(chan int)
for i := 0; i < SUBWORKERS; i++ {
go subworker(subtasks)
}
for i := 0; i < SUBTASKS; i++ {
task1 := task \* i
subtasks <- task1
}
close(subtasks)
}
}
func main() {
var wg sync.WaitGroup
wg.Add(WORKERS)
tasks := make(chan int)
for i := 0; i < WORKERS; i++ {
go worker(tasks, &wg)
}
for i := 0; i < TASKS; i++ {
tasks <- i
}
close(tasks)
wg.Wait()
}
### pipeline
pipeline 模式即管道模式,指的是由通道连接的一系列连续的阶段,以类似流的形式进行计算。每个阶段是一组执行特定任务的协程,每个阶段的协程都会通过通道获取从上游传递过来的值,经过处理后,再把新的值发送给下游。
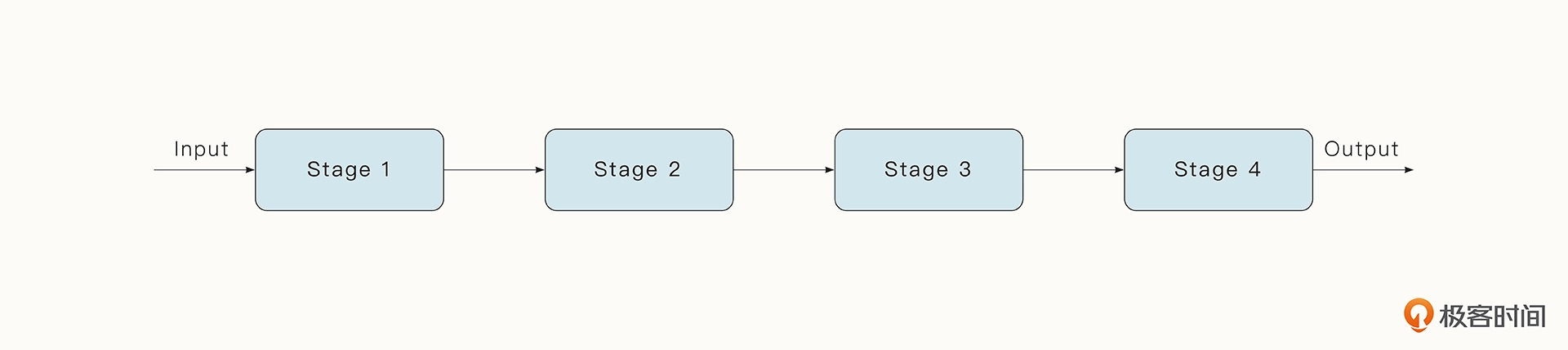
其实我们平时的四则运算就很像一个管道。举个例子,我们要计算 2\*(2\*number+1) 这串数字就可以用下面的方式实现。可以看到,multiply(v, 2) 首先被计算出来,计算的结果会紧接着被送入 add 函数中执行加 1 操作。之后,生成的结果将继续作为 multiply 函数的参数被处理。
func main() {
multiply := func(value, multiplier int) int {
return value * multiplier
}
add := func(value, additive int) int {
return value + additive
}
ints := []int{1, 2, 3, 4}
for _, v := range ints {
fmt.Println(multiply(add(multiply(v, 2), 1), 2))
}
}
《Concurrency in Go》 这本书中给出了将上例的算术操作转换为 pipeline 模式的例子,如下所示,我们梳理一下这段代码。
在这里,generator、multiply、add 是三个函数,代表管道的不同阶段。每个阶段会返回一个通道供下一个阶段消费。其中,multiply 代表乘法操作;add 代表加法操作 ;generator 是管道的第一个阶段,代表数据的产生。而在代码的最后,for v := range pipeline 代表管道的最后一个阶段,消费最后产生的结果。通道 done 则是为了实现协程的退出而设计的。
func main() {
generator := func(done <-chan interface{}, integers …int) <-chan int {
intStream := make(chan int)
go func() {
defer close(intStream)
for _, i := range integers {
select {
case <-done:
return
case intStream <- i:
}
}
}()
return intStream
}
multiply := func(
done <-chan interface{},
intStream <-chan int,
multiplier int,
) <-chan int {
multipliedStream := make(chan int)
go func() {
defer close(multipliedStream)
for i := range intStream {
select {
case <-done:
return
case multipliedStream <- i * multiplier:
}
}
}()
return multipliedStream
}
add := func(
done <-chan interface{},
intStream <-chan int,
additive int,
) <-chan int {
addedStream := make(chan int)
go func() {
defer close(addedStream)
for i := range intStream {
select {
case <-done:
return
case addedStream <- i + additive:
}
}
}()
return addedStream
}
done := make(chan interface{})
defer close(done)
intStream := generator(done, 1, 2, 3, 4)
pipeline := multiply(done, add(done, multiply(done, intStream, 2), 1), 2)
for v := range pipeline {
fmt.Println(v)
}
}
在管道中还有一个经典的案例:求素数。对于一个大于 1 的自然数,除了 1 和它自身外,不能被其他自然数整除的数就叫做素数。那我们怎么利用管道来计算前 1 万个素数呢?
我们可以在管道的每一个阶段都进行筛选。第一个阶段为数字的生成器,第二个阶段我们首先找到第 1 个素数 2,在这个阶段过滤出所有能够被 2 整除的数,这样我们就过滤出了 4、6、8 等偶数。这样我们也就能找到第一个不能被 2 整除的数字 3,可以推断出它一定是素数。因此第三个阶段,我们要排除所有能够被 3 整除的数字,这样就能够排除 9、15 等数字,而下一个不能被 3 整除的数是 5,它也一定是素数。把它作为第四个阶段筛选的依据,以此类推。

// 第一个阶段,数字的生成器
func Generate(ch chan<- int) {
for i := 2; ; i++ {
ch <- i // Send ‘i’ to channel ‘ch’.
}
}
// 筛选,排除不能够被prime整除的数
func Filter(in <-chan int, out chan<- int, prime int) {
for {
i := <-in // 获取上一个阶段的
if i%prime != 0 {
out <- i // Send ‘i’ to ‘out’.
}
}
}
func main() {
ch := make(chan int)
go Generate(ch)
for i := 0; i < 100000; i++ {
prime := <-ch // 获取上一个阶段输出的第一个数,其必然为素数
fmt.Println(prime)
ch1 := make(chan int)
go Filter(ch, ch1, prime)
ch = ch1 // 前一个阶段的输出作为后一个阶段的输入。
}
}
前面我们讲解了许多经典的并发模型。实际上,充满创意的并发模式还有很多,例如** or-channel **模式、**or-done-channel **模式、**tee-channel **模式、**bridge-channel **模式等。在实际生产中也可能存在多种模型的组合。受到篇幅限制我就不再做过多讲解了,如果你对这方面有兴趣也可以继续深挖,相信一定会有所启发。
## 并发检测
Go 1.1 版本之后提供了强大的检查工具 race 来排查数据争用问题。race 可以被用在多个 Go 指令中,当检测器在程序中找到数据争用时,会打印报告。这个报告会包含发生 race 冲突的协程栈,以及此时正在运行的协程栈。
$ go test -race mypkg
$ go run -race mysrc.go
$ go build -race mycmd
$ go install -race mypkg
## 思考题
### 你认为什么时候应该使用锁,什么时候应该使用通道?
>
> Share memory by communicating, don’t communicate by sharing memory.
> 通过通信共享内存,而不是通过共享内存而通信。
>
>


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618658159)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
o build -race mycmd
$ go install -race mypkg
思考题
你认为什么时候应该使用锁,什么时候应该使用通道?
Share memory by communicating, don’t communicate by sharing memory.
通过通信共享内存,而不是通过共享内存而通信。
[外链图片转存中…(img-SQwtrDYd-1715702793340)]
[外链图片转存中…(img-yNCYR5rh-1715702793341)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









