







一:复习流水线基础知识
-1:指令类型:
R型: op(6位) + rs(5位) + rt (5位) + rd (5位) + shamt(5位) + funct(6位)
包括:add、sub、sll(逻辑左移)、and、or、slt(set on less than 小于则置位)
I型: op(6位) + rs(5位) + rt (5位) + mid(16位立即数)
包括:立即数运算或者逻辑 addi ,andi,ori 和 数据传送(lw、sw) 和 决策指令(beq、bne)和 取立即数高位指令(lui):
J型:op(6位) + 26位数
包括:无条件跳转 jump指令

-2:5级流水线
IF-ID-EX-MEM-WB
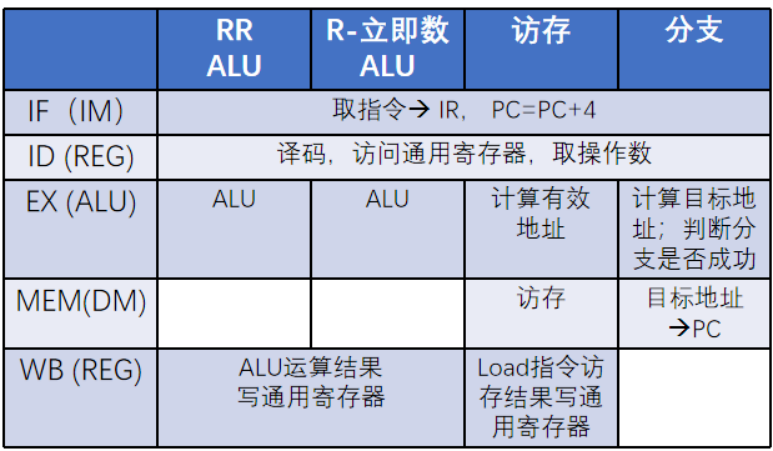
示例图:
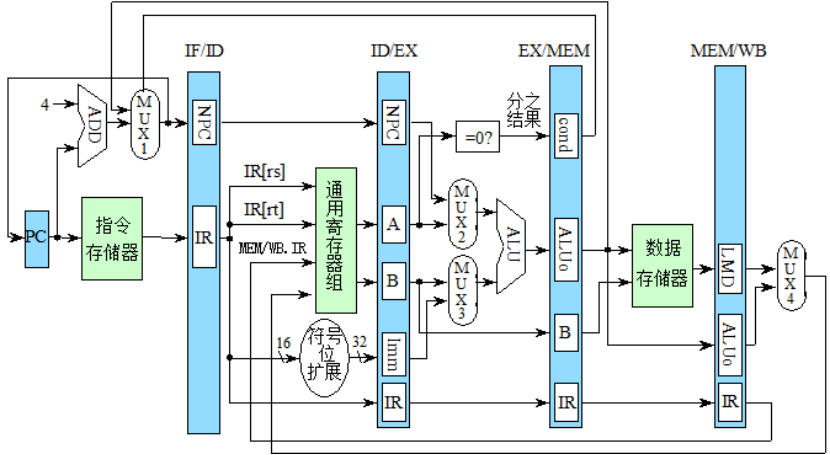
-3:一些术语:
相关:
两条指令之间存在某种依赖关系.(静态属性)
有:数据相关,名相关(反相关,输出相关),控制相关
数据相关(真数据相关)RAW:
对于两个指令i和j(先i后j),如果下面的条件有一个成立:
---1:j使用i产生的结果
---2:j和k数据相关,k和i数据相关(传递性和流动性)
例子:

1-我们先从R1中取出值放到F0中(产生了F0)
2-将F0和F2相加得到了F4(使用了F0,数据相关,产生了F4)
3-将F4存储到(R1)中 (使用了F4,数据相关)
4-移动R1指针 (使用了R1,产生了R1)
5-计算是否还需要继续循环 (使用了R1,数据相关)
注意:当我们的数据知识流经寄存器的话,比较容易进行检查 .但是如果是流经存储器,就比较的复杂了,如图:

(不同的地址可能对应相同的数据,相同的地址形式可能对应的是不同的数据)
名相关**:
如果两条指令使用了相同的名,但是他们之间没有数据流动,就称这两条指令存在名相关.
这里的名,是指:寄存器or存储器单元的名称
名相关有两种:
1.反相关WAR:如果(i前j后),j写入的名是i读的名 ,就说发生了反相关(注意这里的顺序!实际上只有不是顺序调取指令的时候,反相关才可能导致冲突)
2.输出相关WAW,如果j和i写入相同的名
为什么会出现名相关尼?(寄存器的数量有限)
我们去思考下名相关的特点:
first:两个指令之间没有数据的传送
second:两者不能颠倒顺序(正确性的保证)
third :如果一个指令的名改变了,另外一个指令不受影响(之后可以介绍换名技术:编译器换名or硬件动态换名)
举例:

(现在再去看看上面的特点,是不是1和2交换后就不对了,

是不是如果我的第二个F6和后面的F6换一个名字 s,值是一样的,他们之间就消除了名相关了!!)
控制相关:
由分支指令引起的相关(为了保证程序的正确性,必须正确的执行所有的顺序)

对于控制相关,我们给出了限制:
1.与一条分支指令控制相关的指令不能被移到该分支之前,否则这些指令就不受该分支控制了。(S1不能放在if p1 前面)里面的不能出来
2.如果一条指令与某分支指令不存在控制相关,就不能把该指令移到该分支之后.(S不能跑到{S1} or {S2}中)外面的不能进去
冲突:
对于具体的流水线来说,由于相关的存在,使得指令流中的下一条指令不能在指定的时钟周期执行。(动态属性)
有:结构冲突,数据冲突,控制冲突
结构冲突:
因硬件资源满足不了指令重叠执行的要求而发生的冲突
常见原因
功能部件不是完全流水 or 资源份数不够(一个端口)
举例,只有一个存储器,取数据or取指令会在同一个周期,导致结构冲突
可以通过插入气泡 or 指令存储器和数据存储器设置相互独立的cache解决
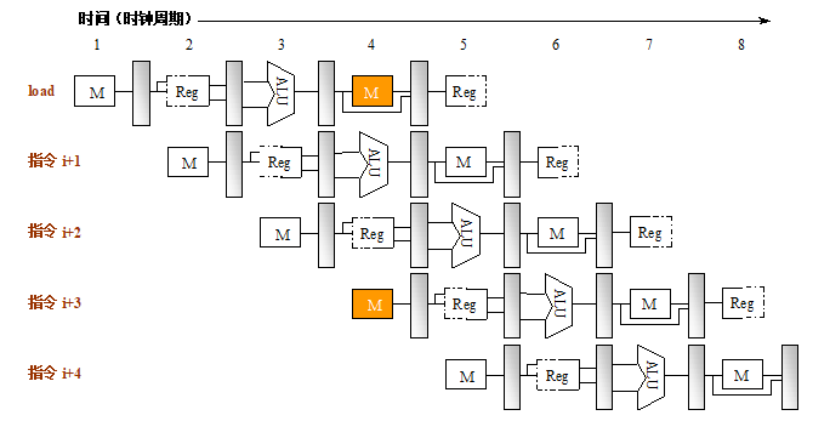
(有的时候为了减少成本,会允许结构冲突的存在(因为完全流水需要重复设置足够份数的部件,成本高))
数据冲突:
当指令在流水线中重叠执行or重新排序后导致时,因需要用到前面指令的执行结果而发生的冲突
举例:

冲突的后果:导致错误or引起停顿 (现在我们规定流水线中:暂停的及其之后的指令等待,流水线中的指令继续执行,直到消除冲突,被暂停的进入流水线or进入下一级流水)
1.先从 R2 和 R3 中取出值,将它们相加,把结果放到 R1 中(使用了 R2、R3,产生了 R1 )。
2.从 R1 和 R5 中取出值,将 R1 的值减去 R5 的值,把结果放到 R4 中(使用了 R1,数据相关,产生了 R4,由于产生R1是在EX,但是在WB写回,所以这个指令读入的不是正确的R1,需要产生气泡(数据冲突) )。
3.从 R1 和 R7 中取出值,对它们进行异或操作,把结果放到 R6 中(使用了 R1数据相关,产生了 R6,由于产生R1是在EX,但是在WB写回,所以这个指令读入的不是正确的R1,需要产生气泡(数据冲突) )。
4.从 R1 和 R9 中取出值,对它们进行与操作,把结果放到 R8 中(使用了 R1数据相关,产生了 R8 ,由于产生R1是在EX,但是在WB写回,所以这个指令读入的不是正确的R1,需要产生气泡(数据冲突) 可以用先写后读解决)。
5.从 R1 和 R11 中取出值,对它们进行或操作,把结果放到 R10 中(使用了 R1、R11,数据相关,产生了 R10 ,无冲突)。
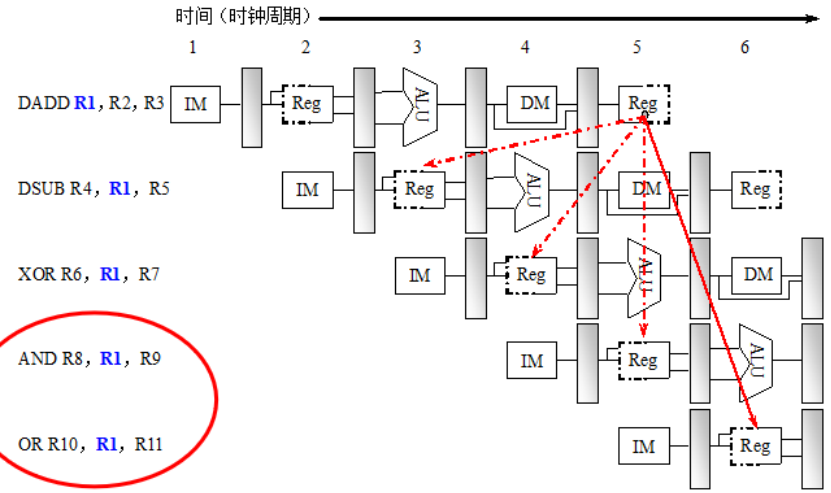
(有RAW,WAW(由于排序,j比i先写),WAR冲突)
一些解决办法:指令调度,定向传送,定向传送with气泡
控制冲突:
流水线遇到分支指令和其他会改变PC值的指令所引起的冲突
分支成功:PC值改变为指定的目标地址
分支失败:PC不改变,正常递增
但是PC最早也是EX产生,但是这个时候的下一个指令已经在ID了!!,所以需要气泡or提前判断or分支预测
冲突的解决方法**:
直接冻结流水线or加入气泡:(最简单的方法)
软件方法:
1.分支预测成功or失败
2.分支延迟
(上面几个方法都是静态的处理的)
3,循环展开 (因为我们判断是否进行循环的时候其实就是一个分支指令,比如100次循环,就是判断100次,如果我们10次循环融合到一起,是不是就只用判断10次了)
二:指令级并行概念和基本编译技术
1-:ILP的概念:
几乎所有的处理机都利用流水线来使指令重叠并行执行,以达到提高性能的目的。这种指令之间存在的潜在并行性称为指令级并行。
(这里的指令主要指机器语言)
特点:并行性由处理器硬件和编译程序自动识别和利用,不需要程序员对顺序程序作任何修改。下面去研究通过各种技术获得更多的指令级并行性(硬件+软件)
如何优化?
从计算式CPI下手:
实际CPI=理想CPI+结构冲突的停顿(硬件和流水线设计,不做考虑)+数据冲突的停顿+控制冲突的停顿
具体的可能需要从相关和冲突的方面考虑:
保持相关,但避免冲突(指令调度) ; 消除相关(寄存器换名)
-2:基于软件的静态开发方法
基本编译技术:循环展开 与 指令调度
找出不相关的指令序列,让它们在流水线上重叠并行执行。
增加指令间并行性最简单常用的方法:
--开发循环级并行性——循环的不同迭代之间存在的并行性。
--在把循环展开后,通过重命名和指令调度来开发更多的并行性。
编译器完成这种指令调度的能力受限于两个特性:
--程序固有的指令级并行性;
--流水线功能部件的执行延迟。
下面所有的指令都依照这里的延迟周期(默认5流水)
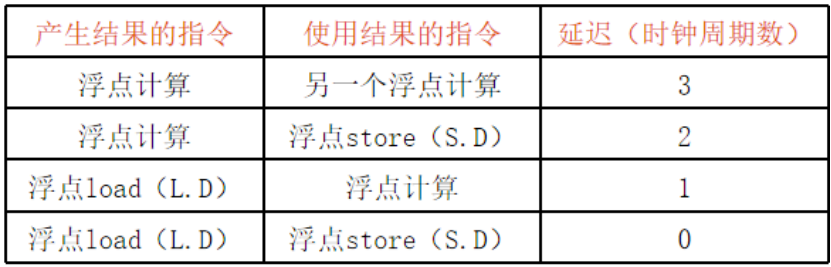
分支延迟:1个周期
整数load的延迟 :1个周期
流水线式全流水的
例题:
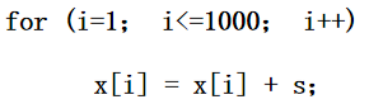
情况1:没指令调度
汇编语言如下
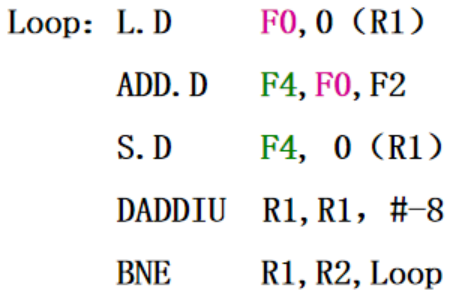
ID结果被浮点计算使用,空转1
浮点计算被SD使用 空转2
整数计算(DADDIU)被BNE使用,EX产生 iD使用,使用定向传送 空转1
BEN分支延迟 :空转1
具体的内容如下:

情况2:使用指令调度:
把BNE移动到LD下面,BNE移动到SD上面

(有着明显的优化)
情况3:使用循环展开+重命名,这里是4个循环展开一次
之前:

现在:

(优化了由于循环控制带来的DADDIU和BNE带来的一些延迟)
情况4:指令调度+循环展开+重命名
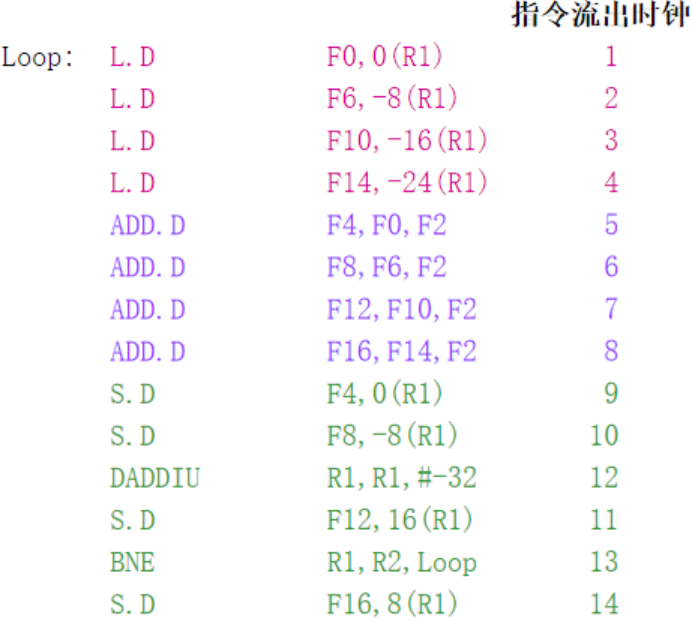
(没有空转!!!!)
主要注意的事;
-1:我们要确保调度和循环展开后的正确性
-2:找到不同循环之间的无关的性,才能够进行展开
-3:寄存器换名(使用不同的寄存器)
-4:删除多于的测试和转移指令
-5:注意避免引入其他的相关性
三:动态调度解决数据冒险
1-:静态调度
静态调度:是依靠编译器对代码进行调度,也就是在代码被执行之前进行调度;通过把相关的指令拉开距离来减少可能产生的停顿。
2-:动态调度:
在程序的执行过程中,依靠专门硬件对代码进行调度,减少数据相关导致的停顿。
指令顺序执行 和 指令乱序执行
指令顺序执行:指令放入流水线的顺序和指令完成的顺序一致;
指令乱序执行:指令放入流水线的顺序和指令完成的顺序不一致,也就是说有些指令进入流水线后被阻塞的,而在其后进入流水线的指令先完成了。
动态调度的基本思想:我们目前最大的障碍就是顺序流出和执行,万一个指令因为各种原因阻塞了,但是其实后面的指令和前面的没有任何的相关,其实可以做到自己继续流出的,但是由于一起被阻塞了,只有静静的等待
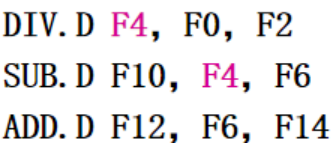
(ADD.D和上面的指令米有一点关系,但是还是被阻塞了)
之前的基本流水中,我们是在ID去检测(数据冲突和结构冲突的)和阻塞的,现在我们引入一些东西,希望来允许乱序执行
之前:
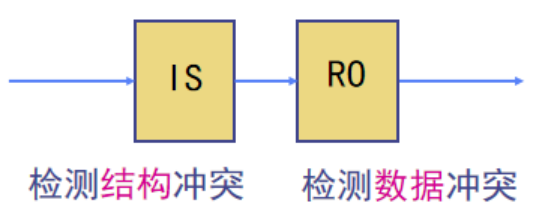
现在:ID被分为了两个部分(IS和RO)分别去检查数据冲突和结构冲突
流出(IS):指令译码,检查是否存在结构冲突.
读操作数(RO):等待数据冲突消失,然后读操作数
(发现引入了乱序执行还带来了之前流水线不会有的WAW和WAR问题因为可能:两个写的顺序出错 /先读后写,这里需要我们去使用寄存器重命名来解决)

总结下动态调度的思想:
1:相对于静态方法,让无关的指令尽量先执行,不背阻塞
2:可以处理编译时不清楚的一些相关(存储器的名相关)
3:让本来是面向特定流水的优化后的代码在其他的流水线也可以高效执行
4:乱序执行需要引入换名技术
5:难以处理异常
6:代价是硬件的复杂性
3-:两个动态调度的算法(***)
记分牌算法:
(思想:在没有资源冲突的前提下,尽可能早地执行其他没有数据相关的指令)
基本结构:
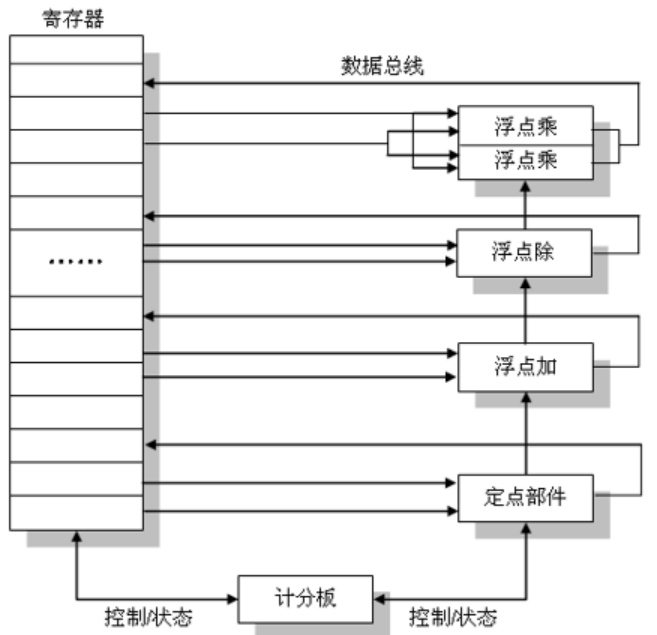
(作用:每条指令都从记分板通过,由记分板决定何时发射,何时取得操作数以及执行指令.
如果判断读出的指令不能执行,就去监视硬件上的变化,并决定何时执行,
最后控制写回目的寄存器)
记分牌内部结构:
-指令状态表:发射、读操作数、执行完成和写回结果
----发射:
发生条件: 1.对应的功能部件空闲(避免结构冲突);2.没有其他在执行的指令和他争夺目标寄存器(避免WAW)
举例:
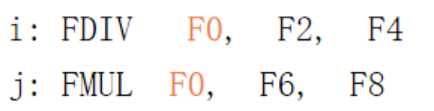
直到F0写回,再发射j
----读操作数:
执行条件:1.执行指令没有对操作数寄存器进行写 ;2.一个正在写的指令完成
举例:
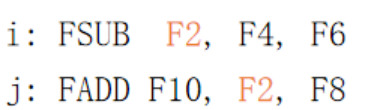
----执行完成:
功能部件获得操作数,开始执行,产生结果,通知计分板做好写回的监督
----写回结果:
执行完成后检查WAR,等read完之后写回
举例:
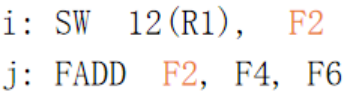
SW因为R1被阻塞.现在FADD先完成,进入写回,需要等到SW读完F2才会写回
-功能部件状态表:每个部件是否在用?在干嘛?
字段:

(一个操作数被取走后,对应的Rj和Rk会变成否)
-寄存器结果状态表:表中的条目数和寄存器个数相等,记录哪个部件写回那个寄存器
举例:

假设运行到这个状态(第1个指令结果写回):
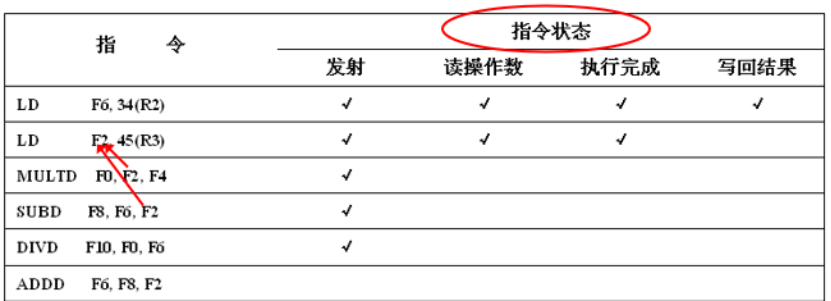
第1条LD指令:不存在冒险,从发射到写回结果。
第2条LD指令:执行完成,处于写回阶段。
第3、4条指令(MULTD和SUBD):读F2存在RAW冒险,处于暂停,等待各自的操作数。
第5条DIVD指令:读F0(MULTD)存在RAW冒险,处于暂停等待。
第6条ADDD指令:与SUBD使用一个“浮点加”部件,结构冒险被阻塞发射。
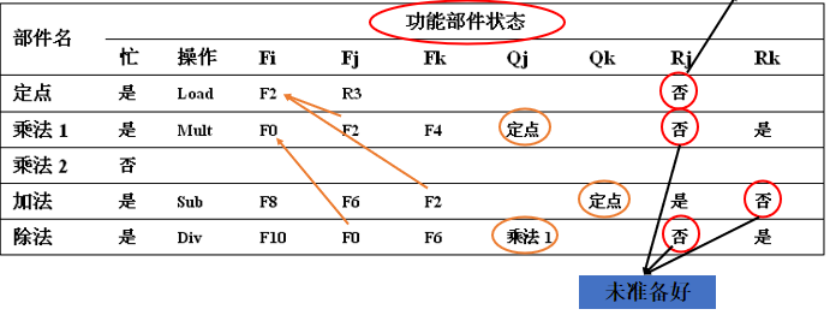
(注意,第一个否表示已经被取走了!其他的否才是没有准备好)

为了继续考虑,做出如下的要求:

再过1个周期,F2写回,第三个和第四个指令读操作数,第五个指令由于F0,等待第3个执行完,第六个指令加法部件被释放,发射
最先完成的是第4个指令



由于ADD之和SUB差距一个1周期,处在执行完成阶段
DIVD还在等MULTD,ADD接下来也要开始等DIVD读操作数后开始写回
下一个就是MULTD完成,DIVD读操作数,然后ADD写回
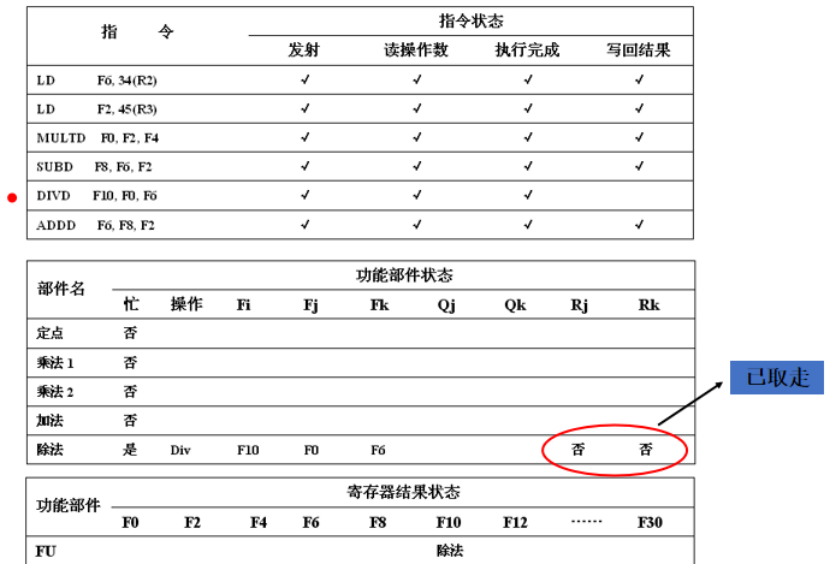
最后结束.
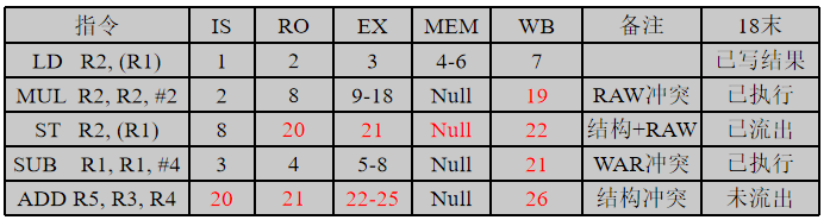
Tomasulo算法****:
核心思想是:记录和检测指令相关,操作数一旦就绪就立即执行,把发生RAW冲突的可能性减少到最小;通过寄存器换名来消除WAR冲突和WAW冲突
硬件结构:
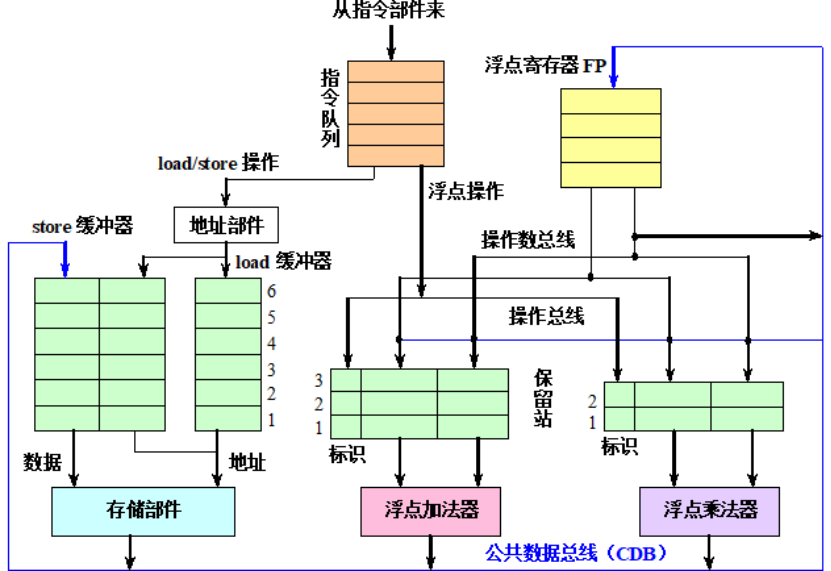
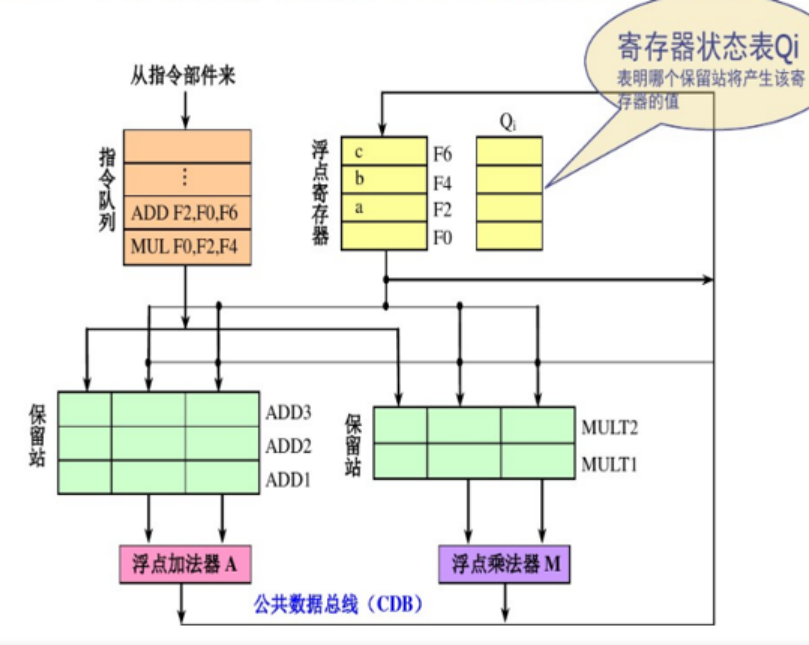
保留站:
每一个保留站中保存一条已经流出并等待到本功能部件执行的指令及其相关信息:包括操作码、操作数以及用于检测和解决冲突的信息。
在一条指令流出送到保留站的时候:
--1:如果该指令的源操作数已经在寄存器中就绪,则将操作数取到该保留站中。
--2:如果操作数还没有计算出来,则在该保留站中记录即将产生这个操作数的保留站的标识。
浮点加法器有3个保留站:ADD1,ADD2,ADD3
浮点乘法器有2个保留站:MULT1,MULT2
公共数据总线:
所有功能部件的计算结果都是送到CDB上,由它把这些结果直接送到(播送到)各个需要该结果的地方。
在具有多个执行部件且采用多流出(即每个时钟周期流出多条指令)的流水线中,需要采用多条CDB。
从存储器读取的数据也送到CDB。
CDB连接到除了load缓冲器以外的所有部件的入口。
浮点寄存器通过一对总线连接到功能部件,并通过CDB连接到store缓冲器的入口
load缓冲器:
存放用于计算有效地址的分量;前
记录正在进行的load访存,等待存储器的响应;中
保存已经完成了的load的结果(即从存储器取来的数据),等待CDB传输。后
store缓冲器:
存放用于计算有效地址的分量;
保存正在进行的store访存的目标地址,该store正在等待存储数据的到达;
保存该store的地址和数据,直到存储部件接收。
浮点寄存器FP
共有16个浮点寄存器:F0,F2,F4,…,F30。
它们通过一对总线连接到功能部件,并通过CDB连接到store缓冲器。
指令队列
指令部件送来的指令放入指令队列
指令队列中的指令按先进先出的顺序流出
运算部件
浮点加法器完成加法和减法操作
浮点乘法器完成乘法和除法操作
寄存器换名***:
寄存器换名是通过保留站和流出逻辑来共同完成的。
--当指令流出时,如果其操作数还没有计算出来,则将该指令中相应的寄存器号换名为将产生这个操作数的保留站的标识。
--指令流出到保留站后,其操作数寄存器号或者换成了数据本身(如果该数据已经就绪),或者换成了保留站的标识,不再与寄存器有关系。这样后面指令对寄存器的写入操作就不可能产生WAR冲突了。
简单的例子
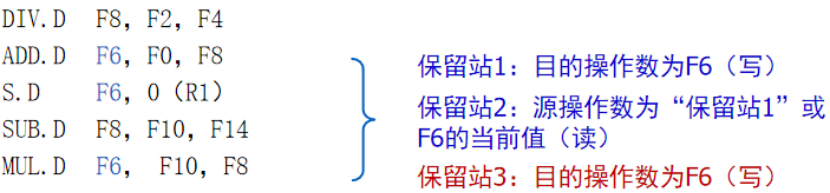
通过简单的例子进一步了解Tomasulo:
MUL的F2和F4就绪,流出到MUL的保留站,同时F0的Q0标志为MULT1,表示该寄存器的内容在保留站MULT1中
接下来ADD流出,由于MUL的F0没有产生,所以用MULT1来代替,同时F2的Q2标志位ADD1
最后完成执行,流回Fi
Tomasulo算法具有以下两个特点:
--冲突检测和指令执行控制是分布的:每个功能部件的保留站中的信息决定了什么时候指令可以在该功能部件开始执行。
--计算结果通过CDB直接从产生它的保留站传送到所有需要它的功能部件,而不用经过寄存器。
流水线***:
使用Tomasulo算法的流水线需3段:流出---执行---写结果
--流出:
----如果该指令的操作所要求的保留站有空闲的,就把该指令送到该保留站(操作数:就绪,值;没有就绪:保留站标志)
----完成对目标寄存器的预约工作:将目标寄存器设置为接受保留站r的结果,相当于提前完成了写操作(预约),由于指令是按程序顺序流出的,当出现多条指令写同一个结果寄存器时,最后留下的预约结果肯定是最后一条指令的。
----如果没有空闲的保留站,指令就不能流出。(发生了结构冲突)
这个算法可以消除反相关也可以消除WAW

(就算是MUL执行的更快,SD也能正确写入保留站1的值,但是如果MUL比DIV还快完成写回,就不对了,所以在这里我们需要顺序写回
--执行:
当两个操作数都就绪后,本保留站就用相应的功能部件开始执行指令规定的操作。这样对于RAW冲突依赖推迟方法解决。由于结果数据是从其产生的部件(保留站)直接(CDB)送到需要他的地方,已经最大限度地减少了RAW的冲突。
load和store指令的执行需要两个步骤:
1,计算有效地址(要等到基地址寄存器就绪)
2,把有效地址放入load或store缓冲器
--写结果
功能部件计算完毕后,就将计算结果放到CDB上,所有等待该计算结果的寄存器和保留站(包括store缓冲器)都同时从CDB上获得所需要的数据。
优点:冲突检测逻辑是分布的(通过保留站和CDB实现)
消除了WAW冲突和WAR冲突导致的停顿
各符号的意义
r:分配给当前指令的保留站或者缓冲器单元编号;
rd:目标寄存器编号;
rs、rt:操作数寄存器编号;
imm:符号扩展后的立即数;
RS:保留站;
result:浮点部件或load缓冲器返回的结果;
Qi:寄存器状态表;
Regs[ ]:寄存器组;
与rs对应的保留站字段:Vj,Qj
与rt对应的保留站字段:Vk,Qk
Qi、Qj、Qk的内容或者为0,或者是一个大于0的整数。
Qi为0表示相应寄存器中的数据就绪。
Qj、Qk为0表示保留站或缓冲器单元中的Vj或Vk字段中的数据就绪。
当它们为正整数时,表示相应的寄存器、保留站或缓冲器单元正在等待结果
每个保留站有以下几个字段:
Op:要对源操作数进行的操作。
Qj,Qk:将产生源操作数的保留站号。
等于0表示操作数已经就绪且在Vj或Vk中,或者不需要操作数。
Vj,Vk:源操作数的值。
对于每一个操作数来说,V或Q字段只有一个有效。
Busy:为“yes”表示本保留站或缓冲单元“忙”。
只要Busy为no,那么保留站所在行的数据无效
A:仅load和store缓冲器有该字段。开始是存放指令中的立即数字段,地址计算后存放有效地址。
算法举例********:


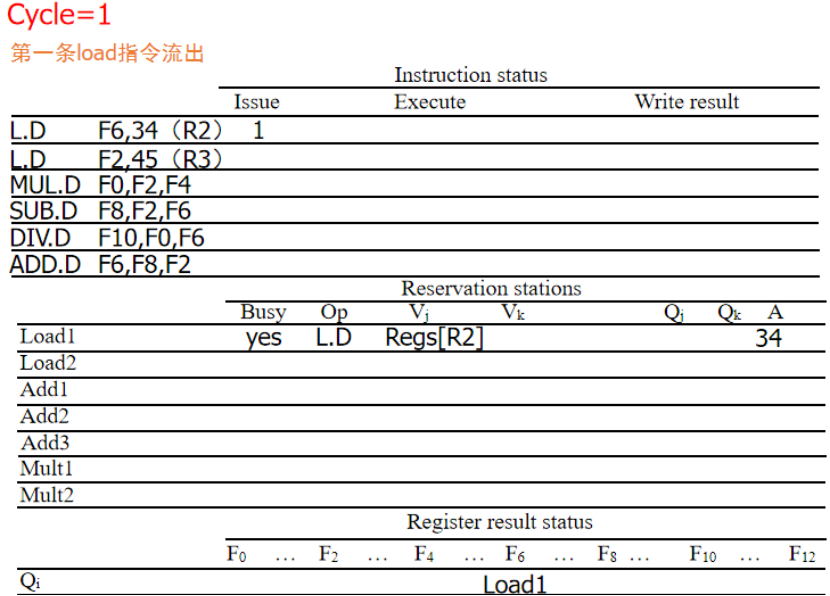
周期1:LD流出,Load1被占用,Vj是reg[R2],A是34
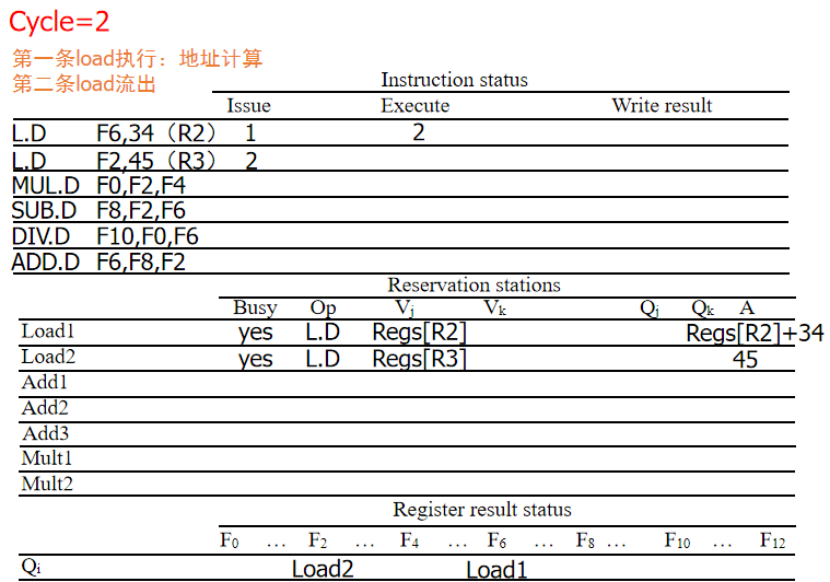
周期2:第一个load计算地址,第二个LD流出
周期3:第一个LD继续计算,第二个LD进入计算,MUL流出,Vk为对应的值,Qj为保留站标志
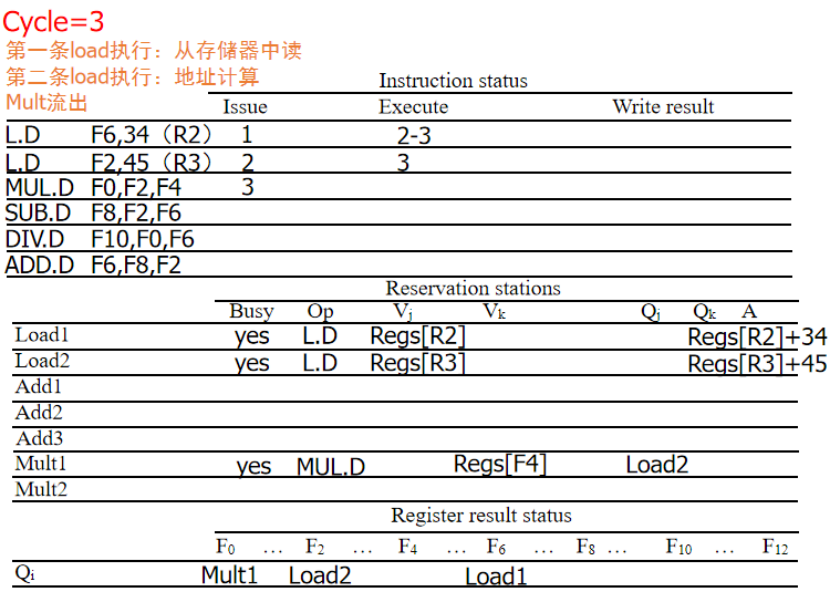
周期4:第一个LD写回,第二个LD继续执行,MUL等待F2,SUB流出,Vk为刚写回的F6,F2用Qj标记为对应的保留站标志
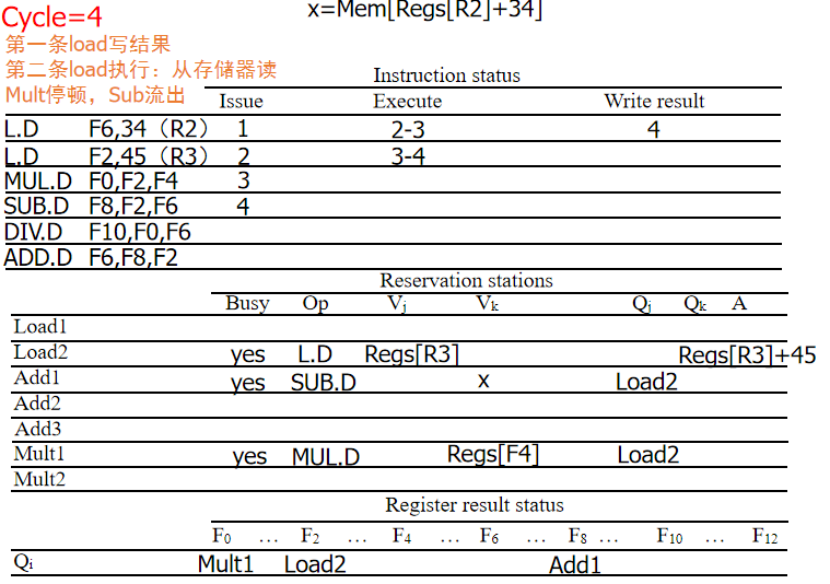
周期5:第二个LD写回,DIV流出,Qj标志位MULT1
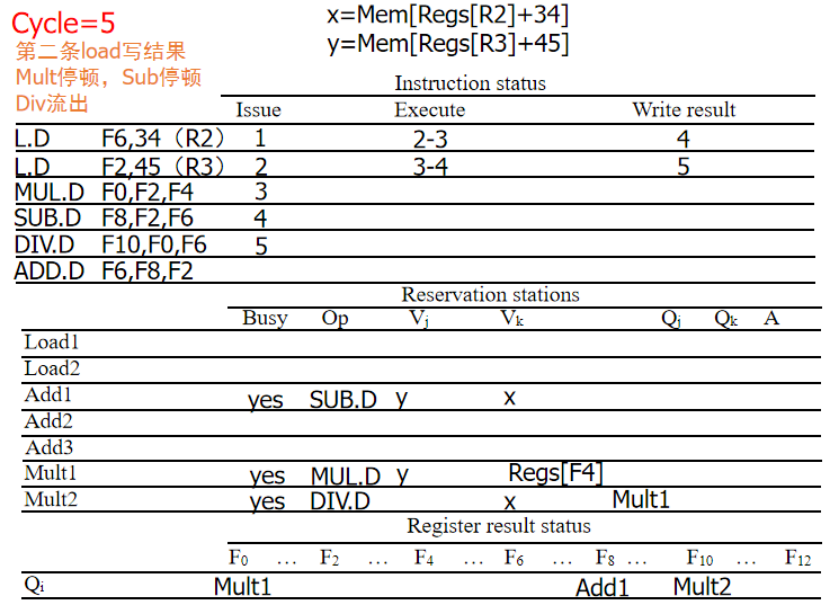
周期6:F2写回后,SUB和MULT从CDB接受F2,进入执行,ADD流出,Qj为SUB的保留站Add1
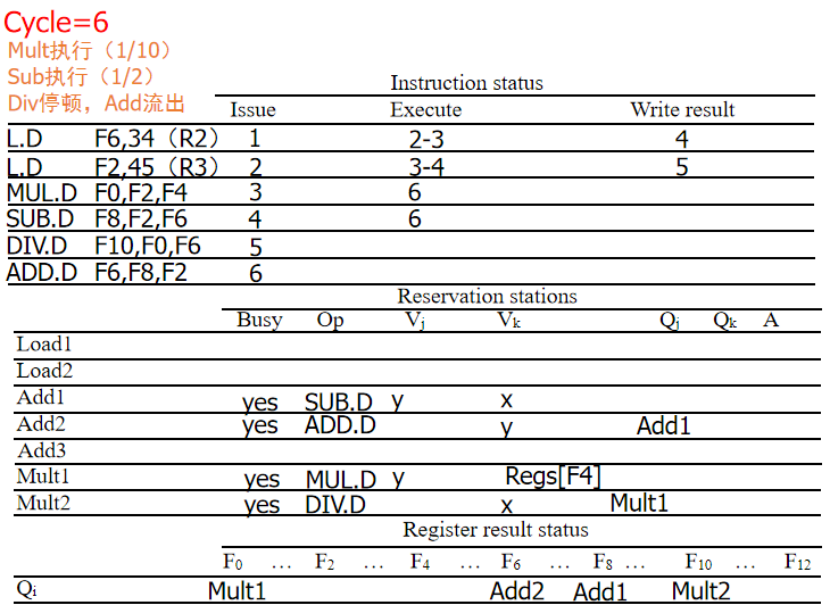
周期8:SUB写回,ADD进入执行,MULt继续执行,DIV等待,
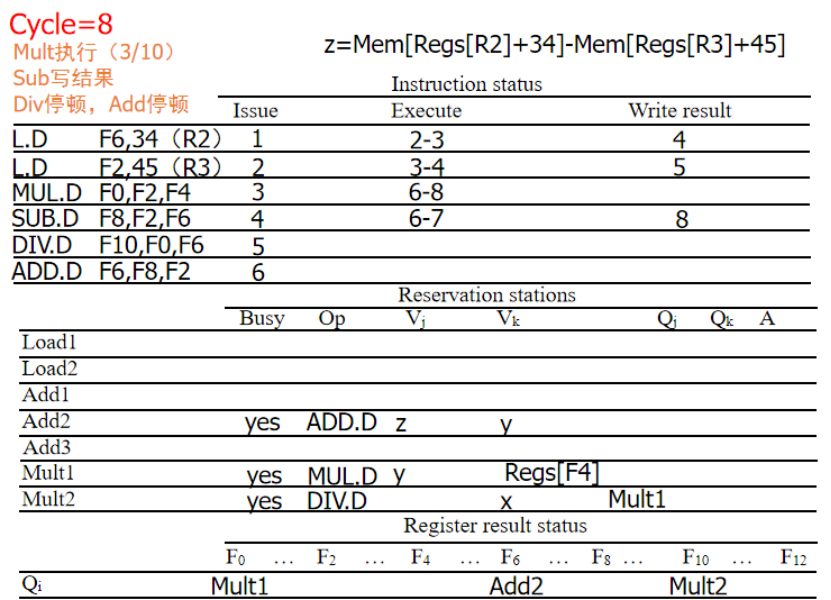
周期9:ADD进入执行.DIV等待,MULT执行
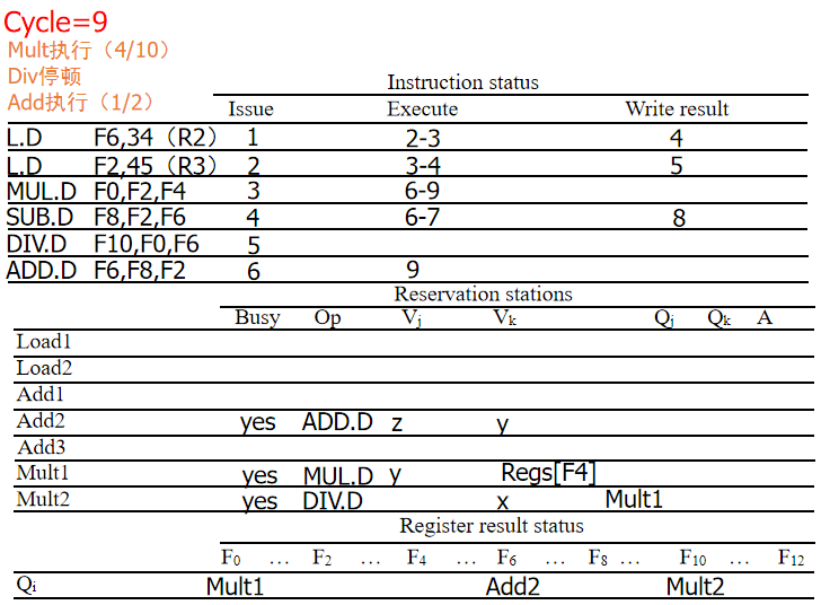
周期11:ADD写回:
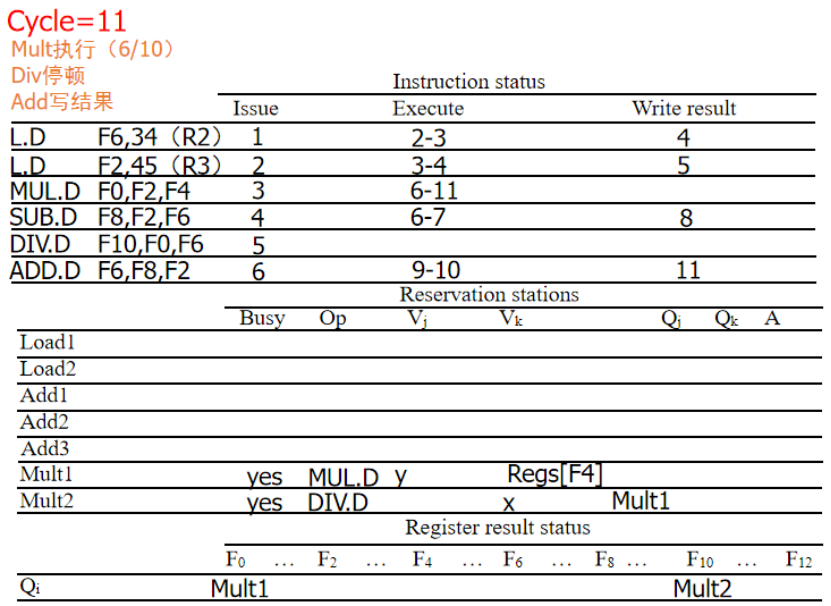
周期16,MUL写回
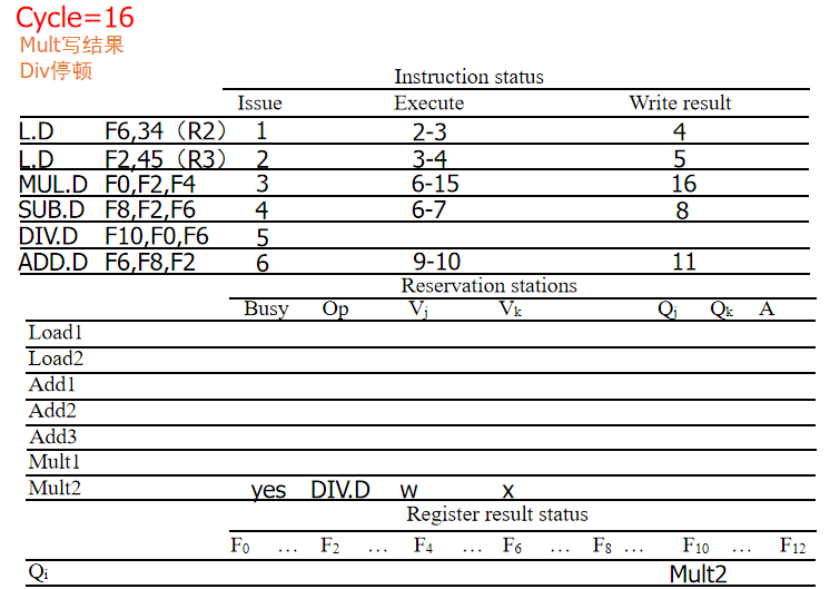
周期17:DIV执行:
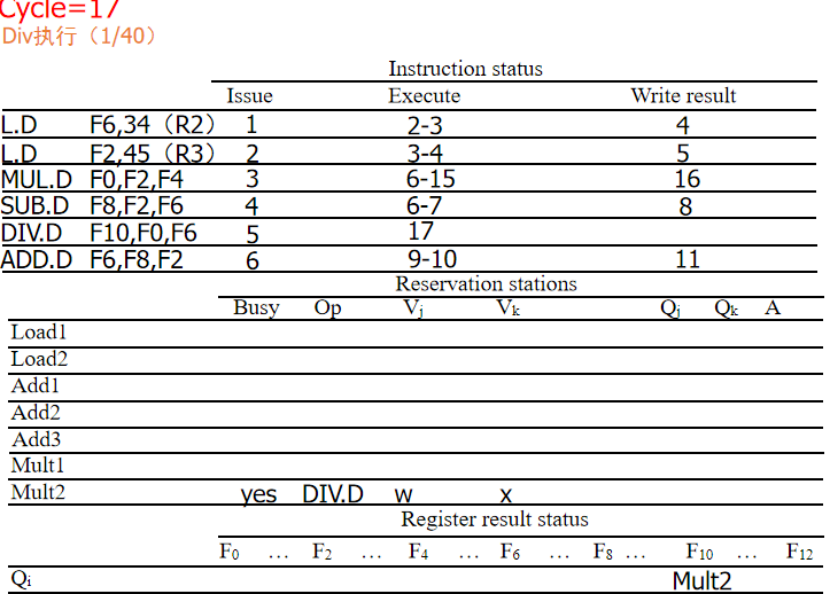
周期57.结束



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









