










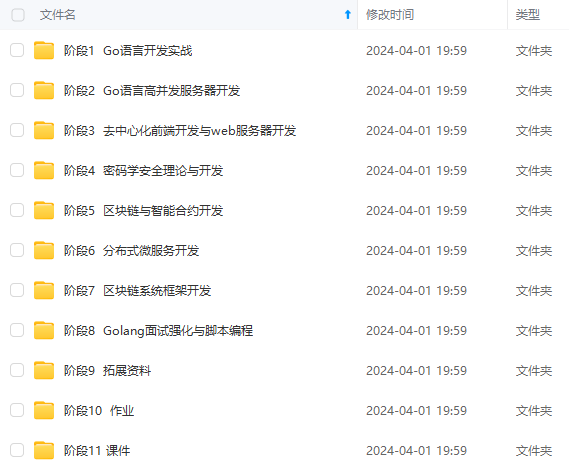
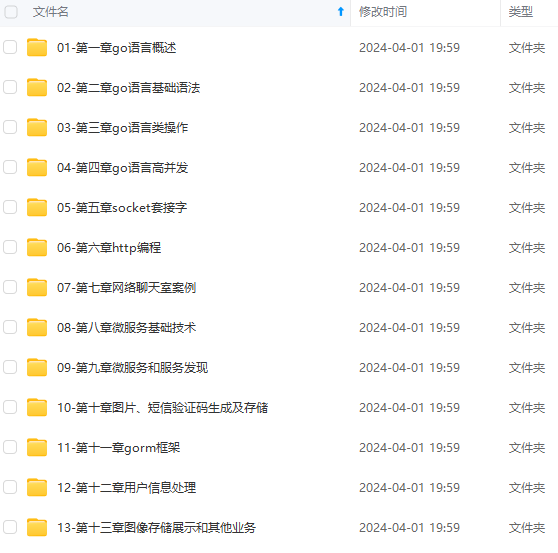
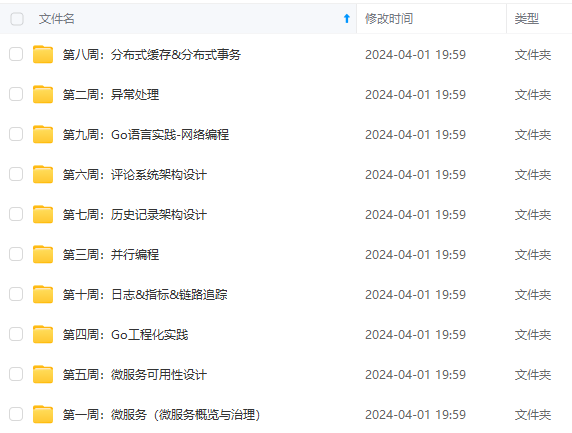
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
#lock是锁FSB(前端串行总线,front serial bus),FSB是处理器和RAM之间的总线,锁住了它,就能阻止其他处理器或core从RAM获取数据。
操作系统内核提供atomic_*系列原子操作
声明和定义:
void atomic_set(atomic_t *v, int i);
atomic_t v = ATOMIC_INIT(0);
读写操作:
int atomic_read(atomic_t *v);
void atomic_add(int i, atomic_t *v);
void atomic_sub(int i, atomic_t *v);
加一减一:
void atomic_inc(atomic_t *v);
void atomic_dec(atomic_t *v);
执行操作并且测试结果:执行操作之后,如果v是0,那么返回1,否则返回0
int atomic_inc_and_test(atomic_t *v);
int atomic_dec_and_test(atomic_t *v);
int atomic_sub_and_test(int i, atomic_t *v);
int atomic_add_negative(int i, atomic_t *v);
int atomic_add_return(int i, atomic_t *v);
int atomic_sub_return(int i, atomic_t *v);
int atomic_inc_return(atomic_t *v);
int atomic_dec_return(atomic_t *v);
编译器层面:gcc内置__sync_*系列built-in函数
gcc内置的__sync_*函数提供了加减和逻辑运算的原子操作,__sync_fetch_and_add系列一共有十二个函数,有加/减/与/或/异或/等函数的原子性操作函数,__sync_fetch_and_add,顾名思义,先fetch,然后自加,返回的是自加以前的值。以count = 4为例,调用__sync_fetch_and_add(&count,1),之后,返回值是4,然后,count变成了5. 有__sync_fetch_and_add,自然也就有__sync_add_and_fetch,先自加,再返回。这两个的关系与i++和++i的关系是一样的。
type可以是1,2,4或8字节长度的int类型,即:
int8_t / uint8_t
int16_t / uint16_t
int32_t / uint32_t
int64_t / uint64_t
type __sync_fetch_and_add (type *ptr, typevalue);
type __sync_fetch_and_sub (type *ptr, type value);
type __sync_fetch_and_or (type *ptr, type value);
type __sync_fetch_and_and (type *ptr, type value);
type __sync_fetch_and_xor (type *ptr, type value);
type __sync_fetch_and_nand(type *ptr, type value);
type __sync_add_and_fetch (type *ptr, typevalue);
type __sync_sub_and_fetch (type *ptr, type value);
type __sync_or_and_fetch (type *ptr, type value);
type __sync_and_and_fetch (type *ptr, type value);
type __sync_xor_and_fetch (type *ptr, type value);
type __sync_nand_and_fetch (type *ptr, type value);
下面是使用 __sync_fetch_and_add 和常规的 LInux 中 pthread 中的同步接口互斥锁 mutex 的一个程序性能对比。
代码讲解1:使用__sync_fetch_and_add操作全局变量
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/time.h>
#include <stdint.h>
int count = 0;
void *test_func(void *arg)
{
int i=0;
for(i=0;i<2000000;++i)
{
__sync_fetch_and_add(&count,1);
}
return NULL;
}
int main(int argc, const char *argv[])
{
pthread_t id[20];
int i = 0;
uint64_t usetime;
struct timeval start;
struct timeval end;
gettimeofday(&start,NULL);
for(i=0;i<20;++i)
{
pthread_create(&id[i],NULL,test_func,NULL);
}
for(i=0;i<20;++i)
{
pthread_join(id[i],NULL);
}
gettimeofday(&end,NULL);
usetime = (end.tv_sec-start.tv_sec)*1000000+(end.tv_usec-start.tv_usec);
printf("count = %d, usetime = %lu usecs\n", count, usetime);
return 0;
}
代码讲解2:使用互斥锁mutex操作全局变量
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/time.h>
#include <stdint.h>
int count = 0;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void *test_func(void *arg)
{
int i=0;
for(i=0;i<2000000;++i)
{
pthread_mutex_lock(&mutex);
++count;
pthread_mutex_unlock(&mutex);
}
return NULL;
}
int main(int argc, const char *argv[])
{
pthread_t id[20];
int i = 0;
uint64_t usetime;
struct timeval start;
struct timeval end;
gettimeofday(&start,NULL);
for(i=0;i<20;++i)
{
pthread_create(&id[i],NULL,test_func,NULL);
}
for(i=0;i<20;++i)
{
pthread_join(id[i],NULL);
}
gettimeofday(&end,NULL);
usetime = (end.tv_sec-start.tv_sec)*1000000+(end.tv_usec-start.tv_usec);
printf("count = %d, usetime = %lu usecs\n", count, usetime);
return 0;
}
结果说明:
[root@blake lock-free]#**./atom\_add\_gcc\_buildin**
count = 40000000, usetime = 756694 usecs
[root@blake lock-free]# **./atom\_add\_mutex**
count = 40000000, usetime = 3247131 usecs
可以看到,使用原子操作是使用互斥锁性能的5倍左右,随着冲突数量的增加,性能差距会进一步拉开。Alexander Sandler实测,原子操作性能大概是互斥锁的6-7倍左右。
有兴趣的朋友可以参考文章:http://www.alexonlinux.com/multithreaded-simple-data-type-access-and-atomic-variables
在语言层面: C++ atomic library、volatile
在C/C++中,所有的内存操作都被假定为非原子性的,即使是普通的32位整形赋值,除非编译器或硬件厂商有特殊说明这个赋值操作是原子的。在所有的现代x86,x64,Itanium,SPARC,ARM和PowerPC处理器中,普通的32位整形,只要内存地址是对齐的,那么赋值操作就是原子操作,这个保证是特定平台下编译器和处理器做出的保证。由于C/C++语言标准并没对整型赋值是原子操作做出保证,于是,要想写出真正可移植的C和C++代码时,我们只能使用C++11提供的原子库( C++11 atomic library)来保证对变量的load(读)和store(写)是原子的。
不能不说的关键字:volatile
通过上面我们知道,在现代处理器中,对于一个对齐的整形类型(整形或指针),其读写操作是原子的,而对于现代编译器,用volatile修饰的基本类型正确对齐的保障,并且限制了编译器对其优化。这样通过对int变量加上volatile修饰,我们就能对该变量进行原子性读写。
volatile int i=10;//用volatile修饰变量i
......//something happened
int b = i;//atomic read
由于volatile 在某种程度上限制了编译器的优化,而很多时候,对于同一个变量,我们在某些地方有原子性读写的需求,在某些地方我们又不需要原子性读写,这个时候希望编译器该优化的时候就优化。然而,不加volatile修饰,那么就做不到前面一点。加了volatile,后面这一方面就无从谈起,怎么办?其实,这里有个小技巧可以达到这个目的:
int i = 2; //变量i还是不用加volatile修饰
#define ACCESS_ONCE(x) (*(volatile typeof(x) *)&(x))
#define READ_ONCE(x) ACCESS_ONCE(x)
#define WRITE_ONCE(x, val) ({ ACCESS_ONCE(x) = (val); })
a = READ_ONCE(i);
WRITE_ONCE(i, 2);
通过上面我们知道,用volatile修饰的int在现代处理器中,能够做到原子性的读写,并且限制编译器的优化,每次都是从内存中读取最新的值,很多同学就误以为volatile能够保证原子性并且具有Memery Barrier的作用。其实vloatile既不能保证原子性,也不会有任何的Memery Barrier(内存栅栏)的保证。上面例子中,volatile仅仅是保证int的地址对齐,而对齐后的整形在现代处理器中,是能够做到原子性读写的。在C++中volatile具有以下特性:
- 易变性:所谓的易变性,在汇编层面反映出来,就是两条语句,下一条语句不会直接使用上一条语句对应的volatile变量的寄存器内容,而是重新从内存中读取。
- "不可优化"性:volatile告诉编译器,不要对我这个变量进行各种激进的优化,甚至将变量直接消除,保证程序员写在代码中的指令,一定会被执行。
- “顺序性”:能够保证Volatile变量间的顺序性,编译器不会进行乱序优化。非Volatile变量的顺序,编译器不保证顺序,可能会进行乱序优化。
2.2 CAS解法与ABA问题
2.2.1 CAS解法
一般采用原子级的read-modify-write原语来实现Lock-Free算法,而 compare-and-swap (CAS)被认为是最基础的一种原子性RMW操作,其伪代码如下:
bool CAS( int * pAddr, int nExpected, int nNew )
atomically {
if ( *pAddr == nExpected ) {
*pAddr = nNew ;
return true ;
}
else
return false ;
}
上面的CAS返回bool告知原子性交换是否成功,然而在有些应用场景中,我们希望CAS 失败后,能够返回内存单元中的当前值,于是就有一个称为 valued CAS的变种,伪代码如下:
int CAS( int * pAddr, int nExpected, int nNew )
atomically {
if ( *pAddr == nExpected ) {
*pAddr = nNew ;
return nExpected ;
}
else
return *pAddr;
}
CAS作为最基础的RMW操作,其他所有RMW操作都可以通过CAS来实现,例如 fetch-and-add(FAA),伪代码如下:
int FAA( int * pAddr, int nIncr )
{
int ncur = *pAddr;
do {} while ( !compare_exchange( pAddr, ncur, ncur + nIncr ) ;//compare_exchange失败会返回当前值于ncur
return ncur ;
}
在C++11的原子lib中,主要有以下RMW操作:
std::atomic<>::fetch_add()
std::atomic<>::fetch_sub()
std::atomic<>::fetch_and()
std::atomic<>::fetch_or()
std::atomic<>::fetch_xor()
std::atomic<>::exchange()
std::atomic<>::compare_exchange_strong()
std::atomic<>::compare_exchange_weak()
其中compare_exchange_weak()就是最基础的CAS,使用compare_exchange_weak()我们可以实现其他所有的RMW操作,C++11 atomic library中的原子RMW操作有点少,不能满足我们实际需求,我们可以自己动手实现自己需要的原子RMW操作。
例如:我们需要一个原子对内存中值执行乘法,也就是 atomic fetch_multiply,实现伪代码如下:
uint32_t fetch_multiply(std::atomic<uint32_t>& shared, uint32_t multiplier)
{
uint32_t oldValue = shared.load();
while (!shared.compare_exchange_weak(oldValue, oldValue * multiplier))
{
}
return oldValue;
}
以上的原子RMW操作都是只能对一个integer变量进行原子修改操作,如果我们想同时对两个integer变量进行原子操作,怎么实现呢?我们知道C++11的原子库std::atomic<>是一个模版,这样我们可以用一个结构体来包含两个integer变量,来对结构体进行原子修改。
C++11的原子库std::atomic<> template可以是任何类型(int、bool等buil-in type,或user-defined type),但并不是所有的类型的原子操作是lock-free的。C++11 标准库 std::atomic 提供了针对整形(integral)和指针类型的特化实现,其中 integal 代表了如下类型char, signed char, unsigned char, short, unsigned short, int, unsigned int, long, unsigned long, long long, unsigned long long, char16_t, char32_t, wchar_t,这些特化实现,都包含了一个is_lock_free()成员来用于判断该原子类型是原子操作是否是lock-free的。
现代处理器架构对CAS的实现分成两大阵营:(1)实现了原子性CAS原语 – X86、Intel Itanium、Sparc等处理器架构,最早实现于IBM System 370。(2)实现LL/SC对(load-linked/store-conditional) – PowerPC, MIPS, Alpha, ARM 等处理器架构,最早实现于DEC,通过LL/SC对可以实现原子性CAS,但在一些情况下它并不具有原子性。为什么会存在LL/SC对的使用,而不直接实现CAS原语呢?要说明LL/SC对存在的原因,不得不说一下无锁编程中的一个棘手问题:ABA问题。
2.2.2 ABA问题
一般的CAS在决定是否要修改某个变量时,会判断一下当前值跟旧值是否相等。如果相等,则认为变量未被其他线程修改,可以改。 但是,“相等”并不真的意味着“未被修改”。另一个线程可能会把变量的值从A改成B,又从B改回成A。这就是ABA问题。 很多情况下,ABA问题不会影响你的业务逻辑因此可以忽略。但有时不能忽略,这时要解决这个问题,一般的做法是给变量关联一个只能递增、不能递减的版本号。在compare时不但compare变量值,还要再compare一下版本号。 Java里的AtomicStampedReference类就是干这个的。
2.3、seqlock(顺序锁)
用于能够区分读与写的场合,并且是读操作很多、写操作很少,写操作的优先权大于读操作。 seqlock的实现思路是,用一个递增的整型数表示sequence。写操作进入临界区时,sequence++;退出临界区时,sequence再++。写操作还需要获得一个锁(比如mutex),这个锁仅用于写写互斥,以保证同一时间最多只有一个正在进行的写操作。 当sequence为奇数时,表示有写操作正在进行,这时读操作要进入临界区需要等待,直到sequence变为偶数。读操作进入临界区时,需要记录下当前sequence的值,等它退出临界区的时候用记录的sequence与当前sequence做比较,不相等则表示在读操作进入临界区期间发生了写操作,这时候读操作读到的东西是无效的,需要返回重试。 seqlock写写是必须要互斥的。但是seqlock的应用场景本身就是读多写少的情况,写冲突的概率是很低的。所以这里的写写互斥基本上不会有什么性能损失。 而读写操作是不需要互斥的。seqlock的应用场景是写操作优先于读操作,对于写操作来说,几乎是没有阻塞的(除非发生写写冲突这一小概率事件),只需要做sequence++这一附加动作。而读操作也不需要阻塞,只是当发现读写冲突时需要retry。 seqlock的一个典型应用是时钟的更新,系统中每1毫秒会有一个时钟中断,相应的中断处理程序会更新时钟(写操作)。而用户程序可以调用gettimeofday之类的系统调用来获取当前时间(读操作)。在这种情况下,使用seqlock可以避免过多的gettimeofday系统调用把中断处理程序给阻塞了(如果使用读写锁,而不用seqlock的话就会这样)。中断处理程序总是优先的,而如果gettimeofday系统调用与之冲突了,那用户程序多等等也无妨。 seqlock的实现非常简单: 写操作进入临界区时:
void write_seqlock(seqlock_t *sl)
{
spin_lock(&sl->lock); // 上写写互斥锁
++sl->sequence; // sequence++
}
写操作退出临界区时:
void write_sequnlock(seqlock_t *sl)
{
sl->sequence++; // sequence再++
spin_unlock(&sl->lock); // 释放写写互斥锁
}
读操作进入临界区时:
unsigned read_seqbegin(const seqlock_t *sl)
{
unsigned ret;
repeat:
ret = sl->sequence; // 读sequence值
if (unlikely(ret & 1)) { // 如果sequence为奇数自旋等待
goto repeat;
}
return ret;
}
读操作尝试退出临界区时:
int read_seqretry(const seqlock_t *sl, unsigned start)


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618658159)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
}
return ret;
}
读操作尝试退出临界区时:
int read_seqretry(const seqlock_t *sl, unsigned start)
[外链图片转存中...(img-whXXf23j-1715897494956)]
[外链图片转存中...(img-XcW6niof-1715897494956)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618658159)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









