







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
- 在执行的关键阶段请求并行化,尽可能把串行改为并行。
你可能听说过华罗庚烧水泡茶的故事,这个故事的要点,就是将整个大任务分割为小任务,让关键任务并行进行处理,这个方案可以大大减少整个任务的处理时间。 - 合理选择与实际系统匹配的并发模型
根据自身服务的不同,需要了解 Go 语言在网络 I/O、磁盘 I/O,CPU 密集型系统在程序处理过程中的不同处理模型。并根据不同的场景选择不同的高并发模型。 - 无锁化与缓存化,保证并发的威力。
试想一个极端的不合理的锁设计,它可能会让所有的用户协程等待某一个协程执行完成,导致并行处理退化为串行执行。无锁化并不是完全不加锁,而是要合理设计并发控制。
例如设计无锁的结构,在多读少写场景用读锁替代写锁,用局部缓存来减少对于全局结构的访问(关于如何设计无锁化结构,你可以参考 sync.pool 库、go 内存分配、go 调度器等模块在并行处理中的极致优化)。
怎么用工具和指标来验证程序实际并行的效率呢?
- 协程数量
- 调度器的运行方式
获取协程数量的方式:
- 借助 Debug 库中的 NumGoroutine 函数,GOMAXPROCS 还可以获取逻辑处理器 P;
- 使用 runtime/metrics 包,获取运行时 metric,进而获取到协程数量;
- 通过 pprof 获取当前的协程数量。
调度器:Go调度跟踪
- 启动 GODEBUG 特定环境变量方式,查看调度器日志;
- 通过 pprof 和 trace 工具,可视化分析调度器的运行状态。
代码实施级别
-
合理代码优化
-
代码规范
- 目录结构规范
- 测试规范
- 版本规范
- 目录结构规范
- 代码评审规范
- 开发规范
- 参考UBER 开源的 Go 语言开发规范
-
数据结构与算法
- 算法优化
- 数据结构优化
-
缓存:空间换时间
- CPU多级缓存
- Go运行时调度器
- Go内存分配器
- sync.pool
-
复杂度
-
benchmark对比
-
-
刻意的优化
-
放入接口中的数据会进行内存逃逸,需不需要优化?
-
字节数组与 String 互转导致的性能损失需不需要优化?
-
无用的内存需不需要复用?
-
定位瓶颈问题
-
工具:pprof、trace、dlv、gdb
-
数据结构与算法
-
序列化
-
Go 语言的编译时和运行时。例如,之前介绍过的将环境变量 GOMAXPROC 调整为更合适的大小,本质上就是在修改运行时可并行的线程数量。
-
此外,当并发量上来之后,垃圾回收(GC)也可能成为系统的瓶颈所在。GC 有一段 STW 的时长完全不能执行用户协程,并且在并行标记期间会占用 25% 的 CPU 时间。如果 STW 时间过长,或者并发标记阶段由于频繁的内存分配触发了辅助标记,都会导致程序无法有效处理用户协程,产生严重的响应超时问题。
一般这类 GC 问题可以通过修改代码逻辑减少内存分配频繁,或是借助 sync.pool 等内存池复用内存来解决。 -
另外,运行时也暴露了一些有限的 API 能够干预垃圾回收的运行,在特殊情况下调整这些参数能够提高程序运行效率:
- 运行时环境变量 GOGC 可以调整 GC 的内存触发水位,当 GOGC=off 时,它甚至能够关闭 GC 的执行;
- Runtime.GC() 可以手动强制执行 GC。
-
另外,设置运行时环境变量 GODEBUG=gctrace=1 可以让运行时打印 GC 的相关日志。
-
-
-
危险的尝试
- 少用CGO
- unsafe 库本身不是向后兼容的,这意味着在当前版本中有效的代码在之后的版本中的行为是未知的。
- 另外,对指针进行运算的 uintptr 类型本质上是一个整数,Go 内置的垃圾回收无法对它进行管理。操作指针时,由于 Go 运行时栈的自动扩容,可能导致之前指针指向的内容无效。这些危险的操作,需要开发者摸透使用规则并进行正确的权衡(unsafe 包的具体用法可以参考这篇文章)。
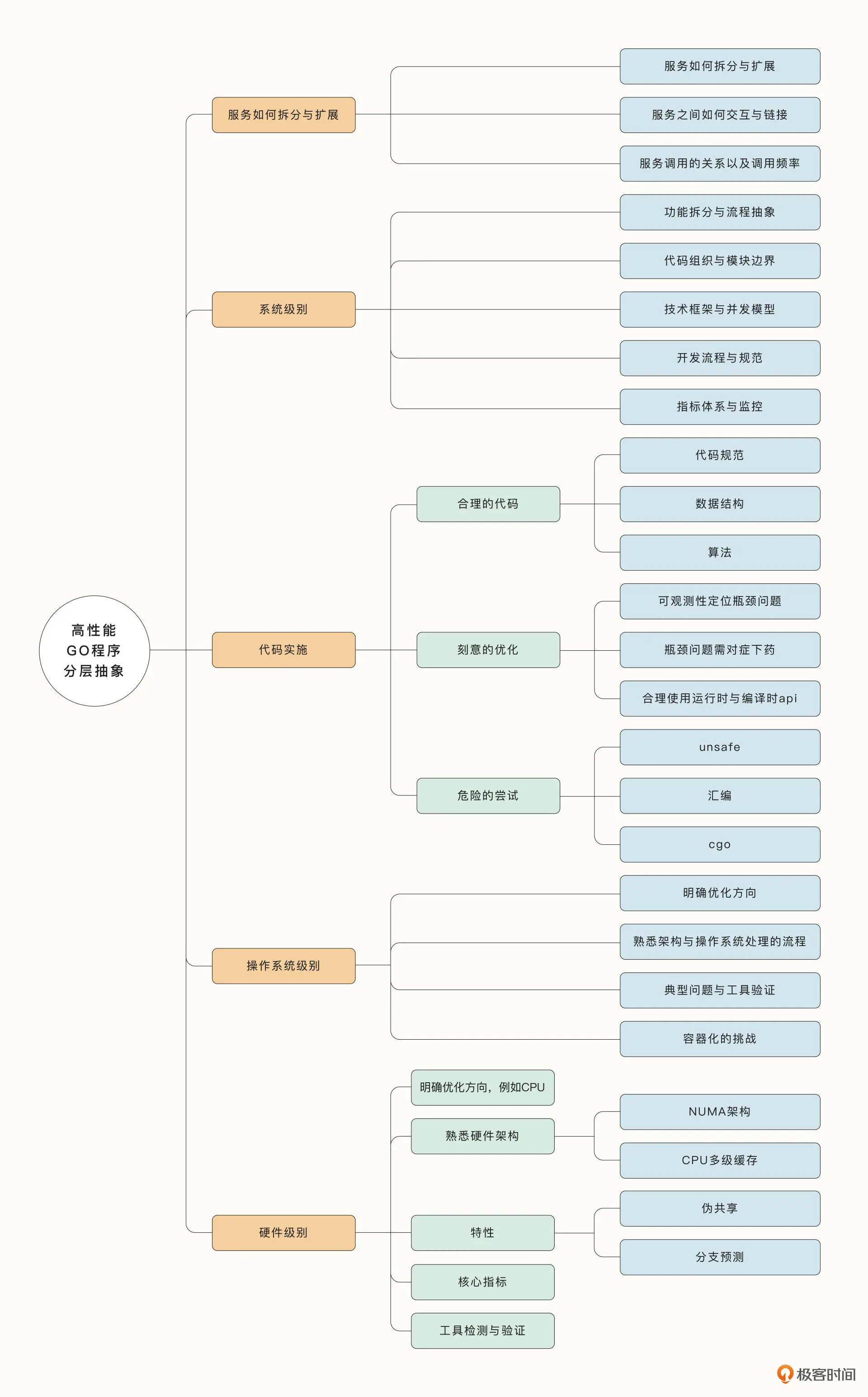
思维导图
思考题
对一个爬虫服务,通常一个网站之中又会有若干需要进一步爬取的网站,就像一棵树一样。如果放在一个协程中处理,将会非常慢。那么你会考虑怎样的程序设计来保证爬虫的高性能?
下载器和解析器解耦分离,通过chan联系起来,各司其职,不够就增加worker;
所有要爬取的网页连接可以看做是一个DAG图。 可以采用BFS遍历的方式来实现爬取。维护一个待爬取url的channel, 每次从一个网页上获取到下一级的url就加入到这个channel中。 同时, channel的另一侧读取channel, 待爬取url channel 不为空时就读取url并启动一个新的协程去爬取对应url 并解析返回内容。
假如当前服务响应时间 P99 太高,导致了 QPS 无法增加,你觉得可以用什么指标和工具来定位和解决问题?
- 资源瓶颈,如CPU、内存、磁盘和文件系统 I/O、网络以及内核资源等各类软硬件资源出现了瓶颈,从而导致应用程序的运行受限。对于这种情况,我们就可以用前面系统资源瓶颈模块提到的各种方法来分析。
- 依赖服务的瓶颈,也就是诸如数据库、分布式缓存、中间件等应用程序,直接或者间接调用的服务出现了性能问题,从而导致应用程序的响应变慢,或者错误率升高。这说白了就是跨应用的性能问题,使用全链路跟踪系统,就可以帮你快速定位这类问题的根源。
- 应用程序自身的性能问题,包括了多线程处理不当、死锁、业务算法的复杂度过高等等,用火焰图辅助分析.
推荐资料
- 《Designing Data-Intensive Applications》
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









