







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
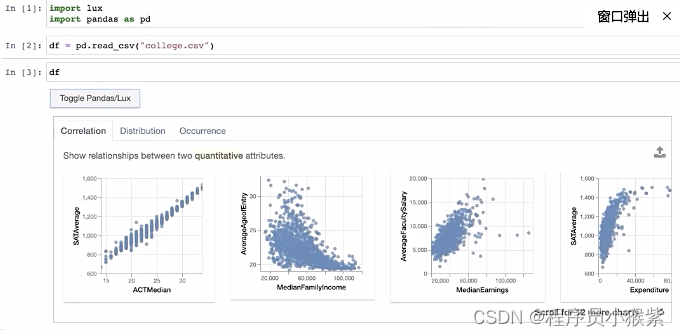
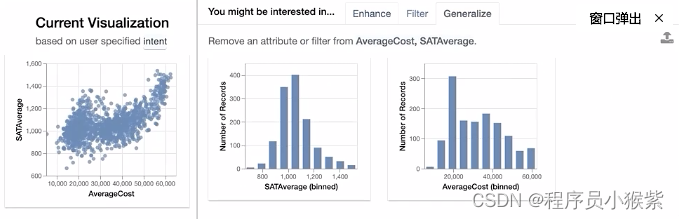
瞧!这是一组可视化,你还可以在 Lux 中指定您感兴趣的属性和值。基于此意图,Lux会指导用户朝着潜在的下一步发展,当然还有很多功能,有兴趣可以进一步探索。
官方链接
https://lux-api.readthedocs.io/en/latest/source/getting_started/installation.html
df.intent = [“AverageCost”,“SATAverage”]
df
### 安装方法
PyPI安装Python Lux API
pip install lux-api
#要安装小部件,我们需要安装webpack
npm install --save-dev webpack webpack-cli
npm安装Lux Jupyter小部件
npm i lux-widget
## 2、Translators
Translators 集成了谷歌、必应、有道、百度等多个翻译平台 API,支持上百种语言翻译,使用便捷,配置灵活。对于批量需要翻译的场景,绝对是提效利器。
### 安装
Windows, Mac, Linux
pip install translators --upgrade
Linux javascript runtime environment:
sudo yum -y install nodejs
### 示例展示
import translators as ts
wyw_text = ‘季姬寂,集鸡,鸡即棘鸡。棘鸡饥叽,季姬及箕稷济鸡。’
chs_text = ‘季姬感到寂寞,罗集了一些鸡来养,鸡是那种出自荆棘丛中的野鸡。野鸡饿了唧唧叫,季姬就拿竹箕中的谷物喂鸡。’
input languages
print(ts.deepl(wyw_text)) # default: from_language=‘auto’, to_language=‘en’
output language_map
print(ts._deepl.language_map)
professional field
print(ts.baidu(wyw_text, professional_field=‘common’)) # (‘common’,‘medicine’,‘electronics’,‘mechanics’)
requests
print(ts.youdao(wyw_text, sleep_seconds=5, proxies={}, use_cache=True))
host service
print(ts.google(wyw_text, if_use_cn_host=True))
print(ts.bing(wyw_text, if_use_cn_host=False))
### Github 官方链接
>
> https://github.com/UlionTse/translators
>
>
>
## 3、TextShot
推荐一款高精度免费 OCR 工具:TextShot。开发这款工具仅仅使用 139 行 Python 代码完成,就可快速提取截屏文本内容并复制到剪贴板。且适用于 Windows,macOS 和 Linux 系统。

## 4、Fancy-NLP
Fancy-NLP 是由腾讯商品广告策略组团队构建的用于建设商品画像的文本知识挖掘工具,其支持诸如实体提取、文本分类和文本相似度匹配等多种常见 NLP 任务。与当前业界常用框架相比,其能够支持用户进行快速的功能实现。
在当前的商品广告业务场景中,我们利用该工具快速挖掘海量商品数据的特征,从而支持广告商品推荐等模块中。
### 安装方式
pip install fancy-nlp
### 示例代码
输出文本中的实体信息
from fancy_nlp.applications import NER
ner_app = NER()
ner_app.analyze(‘同济大学位于上海市杨浦区,校长为陈杰’)
结果产出
{‘text’: ‘同济大学位于上海市杨浦区,校长为陈杰’,
‘entities’: [
{‘name’: ‘同济大学’,
‘type’: ‘ORG’,
‘score’: 1.0,
‘beginOffset’: 0,
‘endOffset’: 4},
{‘name’: ‘上海市’,
‘type’: ‘LOC’,
‘score’: 1.0,
‘beginOffset’: 6,
‘endOffset’: 9},
{‘name’: ‘杨浦区’,
‘type’: ‘LOC’,
‘score’: 1.0,
‘beginOffset’: 9,
‘endOffset’: 12},
{‘name’: ‘陈杰’,
‘type’: ‘PER’,
‘score’: 1.0,
‘beginOffset’: 16,
‘endOffset’: 18}]}
此外还可以进行文本类别识别、文本意图识别,测试后效果真的不错噢
### Github 官方链接
>
> https://github.com/boat-group/fancy-nlp
>
>
>
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618658159)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618658159)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









