







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
为什么拆几列出去查询性能就变快了?
MySQL底层使用的是 B+ 树, B+ 树本质上就是一个个 16KB 的数据页实现的,表里的一行行数据是放在数据页里面的。当查询表里的某行数据时,先将数据页从磁盘加载到内存中,就产生磁盘 I/O,磁盘 I/O 很慢。
拆分几列出去,表里的每行数据就会变少,单个 16KB 数据页就能放入更多的行,查询时需要的数据页就变少了,磁盘 I/O 也变少了,性能就变快了。
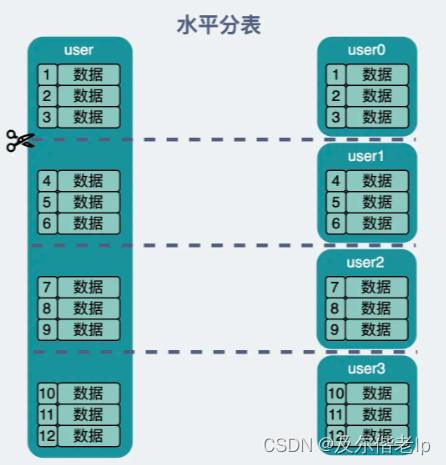
2、水平分表
水平分表,就是把一个表的数据拆分到多个库的多个表里去,但是每个表的结构都一样,只不过每个表放的数据行数是不同的,所有库表的数据加起来就是全部数据。水平拆分的意义,就是将数据均匀放更多的库里,然后用多个库来扛更高的并发,还有就是用多个库的存储容量来进行扩容。简单来说,就是选定一个分片键,把原来的大表拆分成 N 张小张,一般一张小表保存 500 W 到 2 KW 行数据。
三、具体做法
1、根据 ID 取模分表
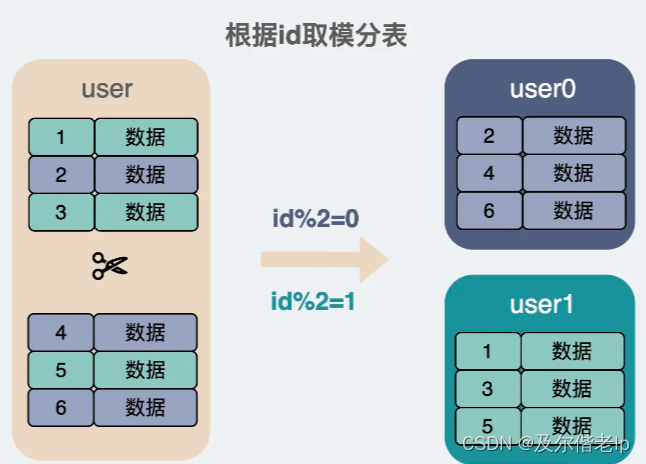
- 优点:简单、读写数据都可以很均匀的分摊到每个分表上。
- 缺点:数据迁移、资源浪费。表的数量扩展后,重新取模,对应的表变了,需要迁移数据到新表。为了避免后续扩展的问题,有些业务会在开始就将数据量预估的很大,然后分成好多张表,但到了最后,可能数据量很小,后面的表根本没用到,造成浪费。
2、根据 ID 范围分表
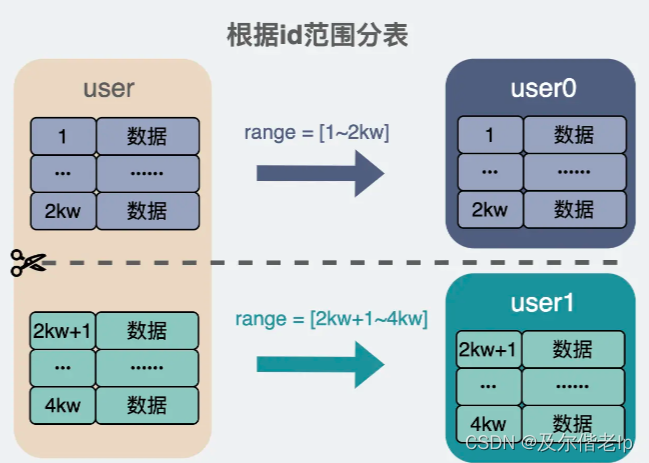
- 优点:解决了按照 ID 取模时,数据表的扩展问题,数据少的时候,表也少,随着数据增多表会慢慢变多,数据表可以无限扩展。
- 缺点:读写热点问题。假设用户ID是不断 +1 的,那么在某段时间内,ID会集中在某个分片范围内,比如在4kw到6kw的范围里,数据会不断写入这个特定的分表,虽然有很多个分表,但大部分时候只有一两张分表会被频繁读写,其他表很空闲,没有起到分摊数据读写压力的效果,这就是读写热点问题。
怎么解决读写热点问题?
让 ID 变得随机,这样ID就能随机分散到所有表上,分摊读写压力。
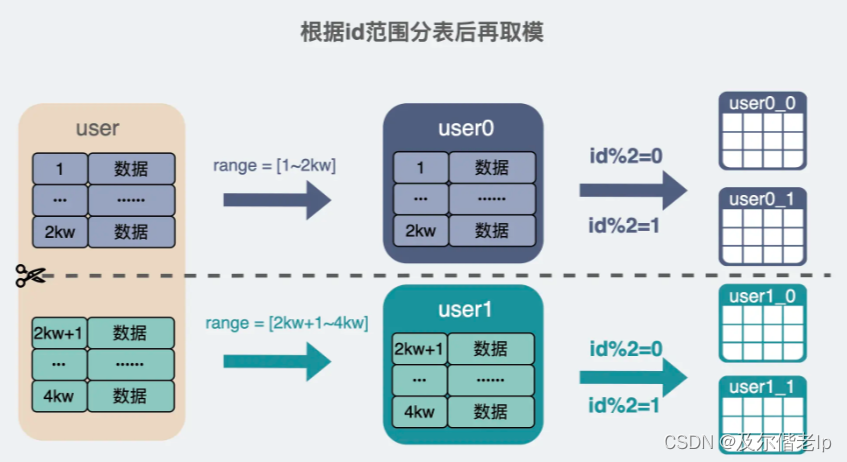
3、结合 ID 范围和 ID 取模分表
根据 ID 取模分表最大的好处是,新写入的数据分散到了多张表上,而根据 ID 范围分表,因为 ID 是递增的,那新写入的数据一般都会落到某一张表上,如果你的业务场景写数据特别频繁,那这张表就会出现写热点的问题。这时候就可以将 ID 取模和 ID 范围分表的方式结合起来,先用 ID 范围去分表,在某个 ID 范围内引入取模的功能,再分成多个表,将写单表分摊为写多表。
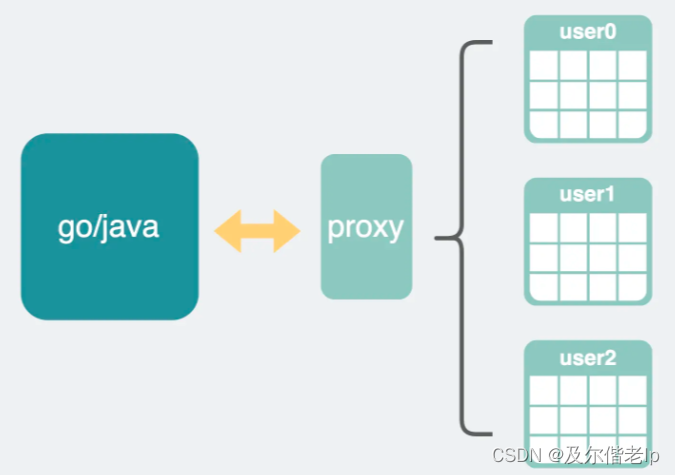
四、中间层(proxy)
不管是单库分表还是分库分表,都需要通过一个中间层逻辑做路由,我们把这部分逻辑封装起来,放在数据库和业务代码之间,这样对于业务代码来说,他只知道自己在读写一张 user 表,根本不知道底下还分了那么多张小表。对于数据库来说,他并不知道自己被分表了,他只知道有那么几张表,只是正好名字长得比较像而已。还真的就应了那句话,没有什么是加中间层不能解决的,如果有就多加一层。
至于这个中间层的实现方式就更灵活了,它可以像第三方 ORM 库那样加在业务代码中,但这样就需要根据不同语言实现不同的代码库,比较繁琐。所以不少大厂都选择在 MySQL 和业务代码之间加个 proxy (代理层)服务去做这个中间层分表路由逻辑,这样就不需要关心上游服务用的是什么语言了。
比较常用的中间件包括:
- Sharding-jdbc 当当开源的,属于 client 层方案。优点在于不用部署,运维成本低,不需要代理层的二次转发请求,性能很高,但是如果遇到升级啥的需要各个系统都重新升级版本再发布,各个系统都需要耦合 Sharding-jdbc 的依赖。
- Mycat 基于 Cobar 改造的,属于 proxy 层方案,支持的功能非常完善,缺点在于需要部署,自己运维一套中间件,运维成本高,但是好处在于对于各个项目是透明的,如果遇到升级之类的都是在自己中间件那里搞就行了。
五、读扩散问题
1、什么是读扩散问题?
分库分表时,都使用了 ID 这一列作为分表的依据,这其实就是所谓的分片键,实际上我们一般也是用数据库的主键作为分片键。我们已知一个ID,不管是根据哪种规则,我们都能很快定位到该读哪个分表。
但很多情况下,我们的查询又不是只查主键,还会查询其他字段,比如用户表里有一列是用来保存用户名字的,并且加了个普通索引。假设我现在需要查询名字叫“小李”的用户有哪些?我需要执行 SQL 语句 select * from user where name = “小李”? 由于 name 并不是分片键,我们没法定位到具体要到哪个分表去执行这条SQL,于是就会对所有的分表都并发执行上面的 SQL 语句。假设我有 100 张分表,就执行 100 次 SQL 查询,如果我有 200 张表,就执行 200 次 SQL 查,随着我的表越来越多,查询的次数也会越来越多,这就是所谓的读扩散问题。
分库分表时,一般我们使用数据库的主键作为分片键,但大多数情况下,我们除了把主键作为查询条件外,还会把其他字段作为查询条件外,由于其他字段并不是分片键,没法定位到具体查那个分表,于是就会查所有的分表,查询次数变多,这就是读扩散问题。mysql水平分表后,对于非分片键字段的查询会有读扩散的问题。
2、怎么解决读扩散问题?
- 普通索引列做分片键,加上 ID ,建立新的分片表。查询时,先去新的分片表里查,获取主键 ID,再拿主键 ID 去旧的分片表里查,得到结果数据。本质上是借鉴了倒排索引的思路。缺点:成本大,需要维护两套表,普通索引列更新时要两张表同时进行更改。
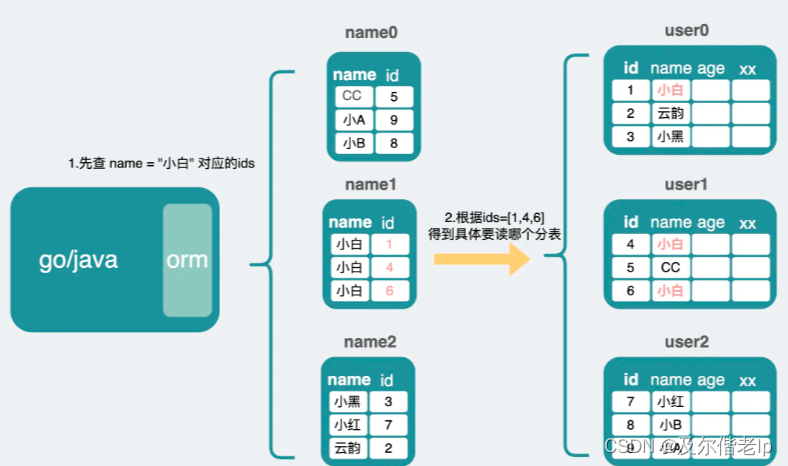
- 使用其他更合适的存储 es。上面的方案利用了倒排索引的思路,原始需求是在大量数据的场景下依然能提供普通索引列或其他更多维度的查询,这种场合,更适合使用es,es天然分片,而且内部利用倒排索引的形式来加速数据查询。
举个例子,我同样是一行数据 id,name,age。在mysql里,你得根据id分片,如果要支持name和age的查询,为了防止读扩散,你得分别再建一个name的分片表和一个age的分片表。而如果你用es,它会在它内部以id分片键进行分片,同时还能建一个name到id,和一个age到id的倒排索引。
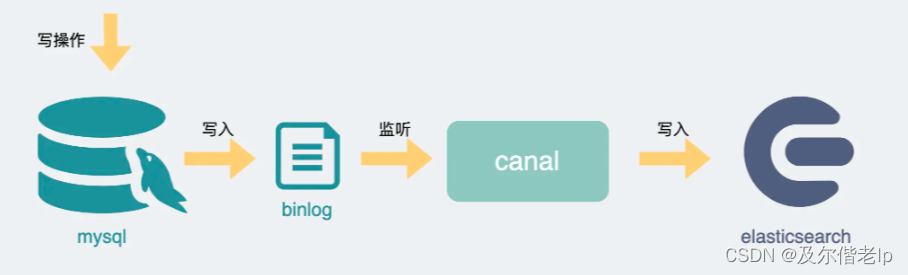
将mysql接入es也非常简单,我们可以通过开源工具 canal 监听mysql的binlog日志变更,再将数据解析后写入es,这样es就能提供近实时的查询能力。
- 使用分布式数据库 tidb。它通过引入Range的概念进行数据表分片,它支持普通索引,并且普通索引也是分片的。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 283
283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









