








连接本地Mysql
注:由于-u -h选项可以加空格后再加内容,但-p后不能加空格,所以博主干脆都不加了。
SQL语句
介绍
SQL语言不是Mysql独有的,sqlserver、Oracle也是使用SQL语言,但有一些区别,Mysql中特有的有LIMIT、show databases等。以分号结尾,不区分大小写!!!
分类
- DDL(Data Definition Language,数据定义语言) - Create、Alter、Drop 这些语句自动提交,无需用Commit提交。
- DQL(Data Query Language,数据查询语言) - Select 查询语句不存在提交问题。
- DML(Data Manipulation Language,数据操纵语言) - Insert、Update、Delete 这些语句需要Commit才能提交。
- DTL(事务控制语言) - Commit、Rollback 事务提交与回滚语句。
- DCL(Data Control Language,数据控制语言) - Grant、Revoke 授予权限与回收权限语句。也有称TCL。
自带表介绍
- information_schema
- performance_schema
- mysql
- test
在Mysql注入点知识讲了表Information_schema,有一些用户、表、列的数据,在注入后可以获得。
注释
注释分为行注释、行中间注释和多行注释
这个注释直到该行结束
– 这个注释直到该行结束
/* 这是一个在行中间的注释 */
/*
这是一个
多行注释的形式
*/
数据库的添加与删除

mysql命令
- show:展示数据库、表等,例如,show databases; show tables;
- use:使用哪个数据库等,例如,use test;
- source: 导入数据,执行sql脚本文件
命令行
create database lady_killer9;

创建数据库并导入数据
show create database lady_killer9;

查看创建数据库的语句
可以看到使用字符集utf8
lady_killer9.sql脚本可从本文后面的资源一节下载。
缺点:sql脚本路径不能含中文
删除数据库
mysql> drop database lady_killer9;
Query OK, 3 rows affected (0.11 sec)
图形化
新建查询->输入sql语句->运行即可

创建数据库
重连一下即可看见创建的数据库
也可这样创建数据库
MySQL连接右键

字符集选择utf8
选择数据库->运行SQL文件

路径可以含中文


运行成功
刷新即可看见表
接下来就看看表的创建,Navicat 中运行SQL语句不再赘述,之后的图形化只会展示非SQL语句运行方式。
表的添加与删除
- DEPT 部门表
- EMP 员工表
- SALGRADE 工资等级表
以EMP表为例,sql语句如下:
CREATE TABLE EMP
(EMPNO int(4) not null ,
ENAME VARCHAR(10),
JOB VARCHAR(9),
MGR INT(4),
HIREDATE DATE DEFAULT NULL,
SAL DOUBLE(7,2),
COMM DOUBLE(7,2),
primary key (EMPNO),
DEPTNO INT(2)
);
命令行:
mysql> use lady_killer9;
Database changed
mysql> show tables;
±-----------------------+
| Tables_in_lady_killer9 |
±-----------------------+
| dept |
| emp |
| salgrade |
±-----------------------+
3 rows in set (0.00 sec)mysql> drop table emp;
mysql> CREATE TABLE EMP(
-> EMPNO int(4) not null,
-> ENAME VARCHAR(10),
-> JOB VARCHAR(9),
-> MGR INT(4),
-> HIREDATE DATE DEFAULT NULL,
-> SAL DOUBLE(7,2),
-> COMM DOUBLE(7,2),
-> primary key (EMPNO),
-> DEPTNO INT(2)
-> );
Query OK, 0 rows affected (0.04 sec)

desc 查看表结构
图形化
删除表
删除表左侧按钮,新建表

创建表EMP
点击添加字段来新建一行,
输入名,选择类型,输入长度,为浮点数的话输入小数点位数,点击不是null选框插入该字段时不能为空,键代表主键,注释可不写也可写名的中文含义等
下方为默认值,可不填,也可根据需要,对应DEFAULT

点击保存,输入表名,点击确定即可

右键设计表,查看表结构
表的字段含义
emp表
- EMPNO 员工编号
- EMPNAME 员工名
- JOB 工作岗位
- MGR 上级领导
- HIREDATE 入职日期
- SAL 薪资
- COMM 津贴
- DEPTNO 部门编号
dept表
- DEPTNO 部门编号
- DNAME 部门名称
- LOC 部门位置
salgrade表
- GRADE 薪资等级
- LOSAL 最低工资
- HISAL 最高工资
查询语法
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr …]
[FROM table_references
[PARTITION partition_list]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], … [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], …]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[PROCEDURE procedure_name(argument_list)]
[INTO OUTFILE ‘file_name’
[CHARACTER SET charset_name]
export_options
| INTO DUMPFILE ‘file_name’
| INTO var_name [, var_name]]
[FOR UPDATE | LOCK IN SHARE MODE]]
基础查询
SELECT〈目标列组〉
FROM〈数据源〉
简单来说,就是从哪些表查什么条件的数据,查多少条,查到后怎么分组,怎么排序,是否将数据保存到文件。
最简单的,从某表查询所有数据
select * from emp;

某表查询所有数据
添加目标列,例如,查员工名,及年薪。
select ENAME,SAL * 12 from EMP;

由于一般情况下,项目的瓶颈是数据库,所以会查出数据后使用项目的编程语言来进行处理,不会直接乘12这种。
重命名,使用关键字AS,也可省略。
select ENAME as 员工名,SAL * 12 as 年薪 from EMP;

建议: 出现’员工名’、‘年薪’这种,可使用单引号,虽然也可以使用双引号,但是sqlserver、Oracle都是使用的单引号,所以统一一下,学习其他数据库的时候就简单点。
读者自行尝试:
select ENAME ‘员工名’,SAL * 12 ‘年薪’ from EMP;
条件查询
根据条件进行筛选。
SELECT〈目标列组〉
FROM〈数据源〉
[WHERE 条件1 [AND [OR]] 条件2 …]
设A为10、B为20。
操作符
| 操作符 | 描述 | 实例 |
|---|---|---|
| = | 等号,检测两个值是否相等,如果相等返回true | (A = B) 返回false。 |
| <>, != | 不等于,检测两个值是否相等,如果不相等返回true | (A != B) 返回 true。 |
| > | 大于号,检测左边的值是否大于右边的值, 如果左边的值大于右边的值返回true | (A > B) 返回false。 |
| < | 小于号,检测左边的值是否小于右边的值, 如果左边的值小于右边的值返回true | (A < B) 返回 true。 |
| >= | 大于等于号,检测左边的值是否大于或等于右边的值, 如果左边的值大于或等于右边的值返回true | (A >= B) 返回false。 |
| <= | 小于等于号,检测左边的值是否小于或等于右边的值, 如果左边的值小于或等于右边的值返回true | (A <=B) 返回 true。 |
| between A and B | >= and <= | between A and B [A,B]区间的都可以 |
| is null | 为空 | where emo is null |
| in | 在,一般后加数值元组 | in (10,20) |
| not | 取非,用于is null 或 in中 | is not null,不为空;not in 不在 |
| like | 模糊查询,支持%和下划线匹配 | like %张_ |
查询工资大于等于2000的员工名字
select ename from emp where sal >= 2000;

查询工资在1100到5000的员工名及工资,包含1100和5000
select ename,sal from emp where sal between 1100 and 5000;

between and 适合某值在闭区间中
查询津贴为NULL的员工名,工资和津贴
select ename,sal,comm from emp where comm is null;

在前面查询这个表所有信息的时候,TURNER的津贴为0.00,注意,数据库中null表示有或没有,不能当做数值使用"="等操作符,0.00可以认为是有津贴,但是员工犯错误,扣光了。
查询津贴扣光或没有津贴的可以这样写
select ename,sal,comm from emp where comm is null or comm = 0.00;
或
select ename,sal,comm from emp where comm > 0.00;
读者自行尝试,不再截图。
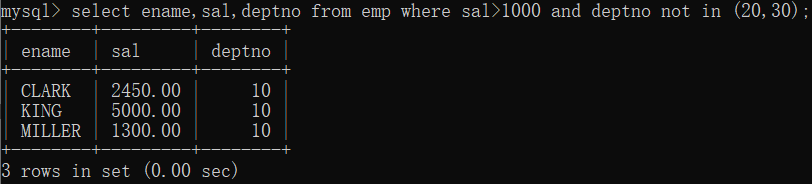
查询薪资大于1000并且部门编号为20或30的员工名,薪资,部门编号
select ename,sal,deptno from emp where sal>1000 and deptno=20 or deptno=30;

看似没有问题,但是实际查询的是薪资大于1000并且部门编号为20的员工,以及部门编号为30的所有员工。原因是and的优先级高于or, sal>1000和deptno=20两个条件合并了。
可以通过加小括号的方式来进行限制,括号的优先级最高。
select ename,sal,deptno from emp where sal>1000 and (deptno=20 or deptno=30);

**in 等同于 or,**in 后面加的是等于多少的值所构成的数值元组,也可解决上面的问题
select ename,sal,deptno from emp where sal>1000 and deptno in (20,30);

select ename,sal,deptno from emp where sal>1000 and deptno in (20,30);
not in 就是不在元组中
模糊查询like
- %:任意多个
- _:任意一个
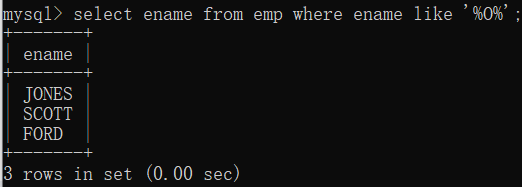
查询名字中包含O的员工名
select ename from emp where ename like ‘%O%’;
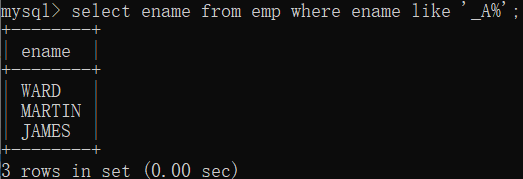
查询名字第二个字母是’A’的员工名
select ename from emp where ename like ‘_A%’;
如果查找名字中含下划线或百分号的,可以使用转义字符 ‘’
select ename from emp where ename like ‘%\_%’;
当然,本数据表里面没有,以后碰到了记得使用转义字符即可。
排序查询
SELECT〈目标列组〉
FROM〈数据源〉
[WHERE 条件1 [AND [OR]] 条件2 …]
[ORDER BY {列名 | 表达式 | 位置}
查询工作岗位是 'MANAGER’的员工,并按工资升序排列
select * from emp where job = ‘MANAGER’ order by sal;

默认升序,需要降序添加关键字 desc 即可。 使用asc是升序,你可以像我一样省略。
多条件,逗号隔开,先按前,再按后。
查询员工姓名和工资,并按工资升序排列,如果工资相同,按名字降序排列。
select ename,sal from emp order by sal,ename desc;

位置,按结果的第几列排序,健壮性太差,位置一换就不行了,尽量不用。
select ename,sal from emp order by 2;

分组查询
SELECT〈目标列组〉
FROM〈数据源〉
[WHERE 条件1 [AND [OR]] 条件2 …]
[ORDER BY {列名 | 表达式 | 位置}
[GROUP BY {列名 | 表达式 | 位置}
[HAVING 条件子句]
分组函****数
- count 计数
- sum 求和
- avg 平均值
- max 最大值
- min 最小值
分组函数自动忽略null
查询津贴有几种情况
select count(comm) from emp;
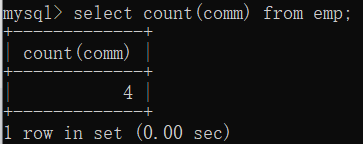
从前面可以看到,comm除了null还有四个。
当出现group by时,select 之后只能加分组字段以及分组函数

数据错误
按多个字段分组
查询每个部门不同工作岗位的最高薪资
select deptno,job,max(sal) from emp group by deptno,job;

分组函数不可直接使用在where子句中
查询工资高于平均工资的员工的名字和工资。
select ename,sal from emp where sal > avg(sal);

解决办法见子查询一节
查询每个工作岗位的最高薪资
select max(sal) from emp group by job;

分组函数在分组之后运行,先按job分组,之后再算每一组的最大值。
having 分组后的数据再次过滤
查询每个部门最高薪资,仅显示大于2900的部门编号及最大薪资。
select deptno,max(sal) from emp group by deptno having max(sal) > 2900;
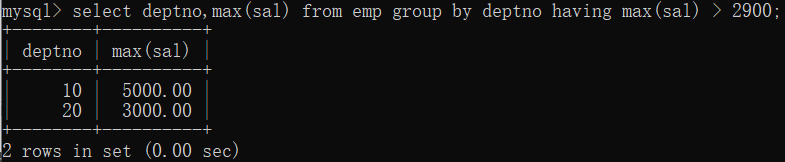
运行顺序:
from 子句 -> where 子句 -> group by 子句 ->having子句 -> select列 子句 -> order by 子句
where 和having的选择
having的效率是比较低的
select deptno,max(sal) from emp where sal > 2900 group by deptno;
上面也可以完成“查询每个部门最高薪资,仅显示大于2900的部门编号及最大薪资”, 而且where子句在 group by 子句前执行,过滤掉后再进行分组时会少写数据,但是having是在分组之后再运行。
所以,能用where优先使用where,不行再使用having
查询每个部门平均薪资,仅显示大于2900的部门编号及平均薪资
select deptno,avg(sal) from emp group by deptno having avg(sal) > 2900;
where子句是无法办到的,原因还是执行顺序。

去重
除了分组,还可以使用关键字 distinct 来进行去重。
select distinct job from emp;

注:distinct只能出现在所有字段的最前方,多个字段则表示后面所有字段看做合并字段进行去重。
连接查询
为防止数据冗余,会将有关系的数据放在不同的表中,表之间有关系,这也是关系型数据库的由来。
内连接
等值连接
连接条件是等量关系
查询每个员工的员工名和所在部门名
select e.ename,d.dname from emp e,dept d where e.deptno = d.deptno;

以上为92年的SQL语法,现在多使用92年的SQL语法,使用join on进行表连接
select e.ename,d.dname from emp e join dept d on e.deptno = d.deptno;
请读者自行尝试。
非等值连接
连接条件是非等值关系
查找每个员工的工资等级,显示员工名,薪资,薪资等级
select e.ename,e.sal,s.grade from emp e join salgrade s on e.sal between s.losal and hisal;

自连接
自己连自己
查询员工的上级领导,显示员工名、领导名(不必查出所有员工)
select e.ename,m.ename from emp e join emp m on e.mgr = m.empno;

注:join前省略了inner,读者可自行尝试
外连接
分为主表和副表,主要主表中的数据全部查询出来,当副表中的数据和主表的数据匹配不上,副表自动模拟出NULL与之匹配。
join前加left或right
左(外)连接
左表为主表
查询员工的上级领导,显示员工名、领导名(查出所有员工,没有领导时显示NULL)
select e.ename,m.ename from emp e left join emp m on e.mgr = m.empno;

注意,KING是大BOSS,没有领导,所以是NULL,另外,left和join之间省略了outer,读者可自行尝试。
右(外)连接
右表为主表
找出哪个部门没有员工
select d.* from emp e right join dept d on e.deptno = d.deptno where empno is null;
使用右连接,部门必全部查出来,如果没有员工,则员工号为NULL

当然,条条大路通罗马,也可以使用子查询。
select * from dept where deptno not in (select deptno from emp group by deptno);
多表连接
看成多次两表连接即可。
查询每个员工的员工名,部门名,工资等级
select e.ename,d.dname,s.grade from emp e join dept d on e.deptno = d.deptno join salgrade s on e.sal between s.losal and hisal;

子查询
where子句中
查询高于平均薪资的员工信息
select * from emp where sal > (select avg(sal) from emp);

可以看到,结果都是大于平均薪资的员工
from子句中
查询每个部门平均薪资所属的薪资等级
select t.*,s.grade from (select deptno,avg(sal) avgsal from emp group by deptno) t join salgrade s where t.avgsal between s.losal and s.hisal;

将上面的查询结果,当做临时表t,临时表t与salgrade表进行连接,连接条件是平均工资在最低和最高工资之间。
Select子句中
查询每个员工所在部门的名称,显示员工名和部门名
使用表连接的话可以这样写:
select e.ename,d.dname from emp e join dept d on e.deptno = d.deptno;
也可不进行表连接,写到select子句中
select e.ename,(select d.dname from dept d where e.deptno = d.deptno) from emp e;

Union查询
这个在SQL注入中是一种注入技巧
两个查询结果必须列数相同
查询工作岗位是SALESMAN和MANAGER的员工
select ename,job from emp where job = ‘MANAGER’ union select ename,job from emp where job = ‘SALESMAN’;

Limit(分页查询)
Mysql独有的,用于取结果的部分数据,sqlserver、Oracle中不能使用,Oracle中有rownum差不多。
limit [startIndex] length
- startIndex :起始位置,从0开始,默认为0
- length:个数
查询工资前5名的员工名和工资
select ename,sal from emp order by sal desc limit 0,5;

select ename,sal from emp order by sal desc limit 5;
每页显示pageSize条记录,pageNo从1开始,则
第pageNo页:?,pageSize ==> ? 为 (PageNo - 1)*pageSize,pageSize
例如,pageSize = 3,pageNo = 1, limit 0,3
DDL
Create
创建表
语法
CREATE TABLE 表名称
(
列名称1 数据类型,
列名称2 数据类型,
列名称3 数据类型,
....
)
常见字段类型
- int:整型
- bigint:长整型
- float:浮点型
- char:定长字符串
- varchar:可变长字符串
- date:日期类型
- BLOB:(Binary Large Object,二进制大对象),存储 图片/视频 等流媒体信息
- CLOB:(Character Large Object,字符大对象),
建立学生表t_student,学号 no,bigint类型,姓名 name,varchar类型,性别 sex char类型,班号 classno,varchar类型,生日 birth char类型
create table t_student(
no bigint,
name varchar(255),
sex char(1),
classno varchar(255),
birth char(10)
);

从其他表获取
create table table_name as select 语句;
创建emp1表, 仅包含emp表的ename和sal字段。
create table emp1 as select ename,sal from emp;

Drop
语法
drop table [if exists] table_name;

ALTER
使用图形化界面即可,例如Navicat 表右键->设计表,一般创建时很谨慎,设计好再创建,很少修改表结构。
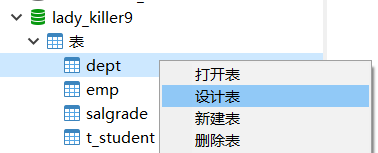
DML
INSERT
语法
INSERT INTO table_name VALUES (值1, 值2,…),(值1, 值2,…),
我们也可以指定所要插入数据的列,这样,其他列就是默认值:
INSERT INTO table_name (列1, 列2,…) VALUES (值1, 值2,…),(值1, 值2,…)
insert into t_student values(1,‘zhangsan’,‘1’,‘gaosan1ban’,‘1996-11-20’);

一次多行插入
insert into t_student values(2,‘lisi’,‘0’,‘gaosan1ban’,‘1996-10-20’),(3,‘wangwu’,‘1’,‘gaosan1ban’,‘1994-01-12’);

从其他表插入
列,类型之类的要一样,很少用,提一下,不截图了。
insert into table_name select 语句;
创建dept1表与dept表数据一致,在dept1表后再插入一次dept表的所有内容
create table dept1 as select * from dept;
insert into dept1 select * from dept;

UPDATE
语法
update table_name set 字段名1=值1,字段名2=值2,… [where 语句];
注意,没有条件,整张表全部更新。
将dept1表中部门编号为10的LOC字段改为BEIJING
update dept1 set loc = 'BEIJING ’ where deptno = 10;

DELETE
语法
delete from table_name [where 子句];
没有条件全部删除
删除部门20的所有数据
delete from dept1 where deptno = 20;

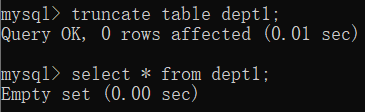
大表删除数据
对于亿级及以上的大表,删除快,但无法回滚
语法
truncate table table_name;
删除表dept1
truncate table dept1;
约束
创建表时,添加相应约束
非空约束
不能为null
create table t_user( id int, username varchar(255) not null, password varchar(255));

唯一约束
关键字:unique
单字段,列级约束
不能重复,但可以为NULL。可以认NULL和NULL不一样。
drop table if exists t_user;
create table t_user( id int, username varchar(255) unique);

多字段唯一,表级约束
drop table if exists t_user;
create table t_user( id int, username varchar(255), phonenum int,unique(username,phonenum));

可以看成将两个字段合并为一个组,组不能重复。
主键约束
关键字:primary key
既不能为null,也不能重复
单一主键
drop table if exists t_user;
create table t_user( id int primary key, username varchar(255),email varchar(255));

第二行由于主键约束,运行失败。
insert into t_user values(1,‘zs’,‘zs@126.com’),(2,‘ls’,‘ls126.com’);
insert into t_user values(2,‘ww’,‘ww@126.com’);

你可以尝试一下,id 为 null 是不是不能插入。
复合主键、业务主键
和unique表级约束语法差不多,primary key(字段1,字段 2)
不推荐,可能产生依赖或业务改变造成影响
自然主键
推荐,使用自然数1、2、3。。。,使用关键字auto_increment
id int primary key auto_increment
外键约束
为解决数据冗余问题,将一张表的主键作为另一张表的外键,用于select时的表连接。
建一个学生表和班级表,学生表有一个外键班号,来自班级表
drop table if exists t_student;
drop table if exists t_class;
create table t_class( cno int, cname varchar(255), primary key(cno) );
create table t_student( sno int, sname varchar(255), classno int, foreign key(classno) references t_class(cno));

insert into t_class values(101,‘xxxxxxxxxxxxxxx’);
insert into t_class values(102,‘yyyyyyyyyyyyyyy’);
insert into t_student values(1,‘zs1’,101);
insert into t_student values(2,‘zs21’,101);
insert into t_student values(3,‘zs4’,102);
insert into t_student(sno,sname) values(4,‘zs5’);
insert into t_student values(5,‘zs6’,103);
最后一句无法运行,因为103不在表t_class中。

外键可以为NULL,可以理解为,学校来了个转学的学生,先添加进来,再分配班级。

下一节使用Navicat,有一些提示,一些函数名字过长,总是手打,浪费时间。
常见函数
语法
select 函数名() [from 表名]
mysql相关
database()
返回当前使用数据库
version()
返回mysql版本


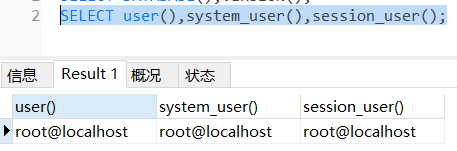
user()、system_user()、session_user()
返回当前用户
单行处理函数
字符函数
长度相关
返回字符串字节长度
length(s)
s:字符串
一个汉字是算三个字节,一个数字或字母算一个字节。这是在utf-8字符集下。
char_length(s)
s:字符串
不管汉字还是数字或者是字母都算是一个字节。

字符串拼接
CONCAT(s1,s2…sn) 字符串 s1,s2 等多个字符串合并为一个字符串
CONCAT_WS(x, s1,s2…sn) 同 CONCAT(s1,s2,…) 函数,但是每个字符串之间要加上 x,x 可以是分隔符

大小写
UPPER(s) 将字符串转换为大写
LOWER(s) 将字符串 s 的所有字母变成小写字母

查询员工表员工名,小写展示
SELECT LOWER(ename) 员工名 from emp;

子串
SUBSTR(s, start [,length]) 从字符串 s 的 start 位置截取长度为 length 的子字符串,位置从1开始。
SUBSTRING、MID 一样

SUBSTRING_INDEX(s, delimiter, number) 返回从字符串 s 的第 number 个出现的分隔符 delimiter 之后的子串。
如果 number 是正数,返回第 number 个字符左边的字符串。
如果 number 是负数,返回第(number 的绝对值(从右边数))个字符右边的字符串。
例如,查询’lady_killer9’中’_'左面的子串,'lady_killer9’中第二个’l’右边的子串
SELECT SUBSTRING_INDEX(‘lady_killer9’,‘_’,1),SUBSTRING_INDEX(‘lady_killer9’,‘l’,-2);

去空格
LTRIM(s) 去掉字符串 s 开始处的空格
RTRIM(s) 去掉字符串 s 结尾处的空格
TRIM(s) 去掉字符串 s 开始和结尾处的空格

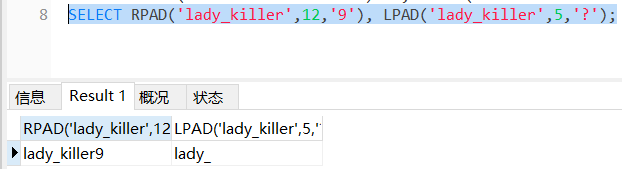
填充
LPAD(s1,len,s2) 在字符串 s1 的开始处填充字符串 s2,使字符串长度达到 len
RPAD(s1,len,s2) 在字符串 s1 的结尾处添加字符串 s2,使字符串的长度达到 len
注:最终长度必为len,不够填充,多了截断
替换
REPLACE(s,s1,s2) 将字符串 s2 替代字符串 s 中的字符串 s1
前面去空格的时候,“Hello World”中间的空格没有去掉,可以使用replace进行替换

索引/位置
LOCATE(s1,s) 从字符串 s 中获取 s1 的开始位置
POSITION(s1 IN s) 从字符串 s 中获取 s1 的开始位置
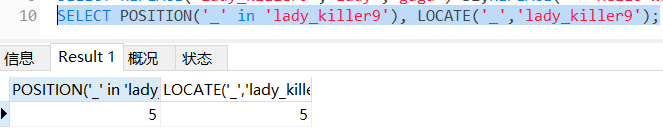
比较字符串
STRCMP(s1,s2) 比较字符串 s1 和 s2,如果 s1 与 s2 相等返回 0 ,如果 s1>s2 返回 1,如果 s1<s2 返回 -1

最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数网络安全工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上网络安全知识点!真正的体系化!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
,查询’lady_killer9’中’_'左面的子串,'lady_killer9’中第二个’l’右边的子串
SELECT SUBSTRING_INDEX(‘lady_killer9’,‘_’,1),SUBSTRING_INDEX(‘lady_killer9’,‘l’,-2);
去空格
LTRIM(s) 去掉字符串 s 开始处的空格
RTRIM(s) 去掉字符串 s 结尾处的空格
TRIM(s) 去掉字符串 s 开始和结尾处的空格
填充
LPAD(s1,len,s2) 在字符串 s1 的开始处填充字符串 s2,使字符串长度达到 len
RPAD(s1,len,s2) 在字符串 s1 的结尾处添加字符串 s2,使字符串的长度达到 len
注:最终长度必为len,不够填充,多了截断
替换
REPLACE(s,s1,s2) 将字符串 s2 替代字符串 s 中的字符串 s1
前面去空格的时候,“Hello World”中间的空格没有去掉,可以使用replace进行替换
索引/位置
LOCATE(s1,s) 从字符串 s 中获取 s1 的开始位置
POSITION(s1 IN s) 从字符串 s 中获取 s1 的开始位置
比较字符串
STRCMP(s1,s2) 比较字符串 s1 和 s2,如果 s1 与 s2 相等返回 0 ,如果 s1>s2 返回 1,如果 s1<s2 返回 -1
最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数网络安全工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
[外链图片转存中…(img-7FfvZxC4-1715714705042)]
[外链图片转存中…(img-UkIpgFEr-1715714705043)]
[外链图片转存中…(img-ZvPTGVO9-1715714705043)]
[外链图片转存中…(img-11negLc4-1715714705043)]
[外链图片转存中…(img-PC55m89Q-1715714705044)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上网络安全知识点!真正的体系化!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









