








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
📒我和大家一样都是初次踏入这个美妙的“元”宇宙🌏 希望在输出知识的同时,也能与大家共同进步、无限进步🌟
📌导航小助手📌
💡本章重点
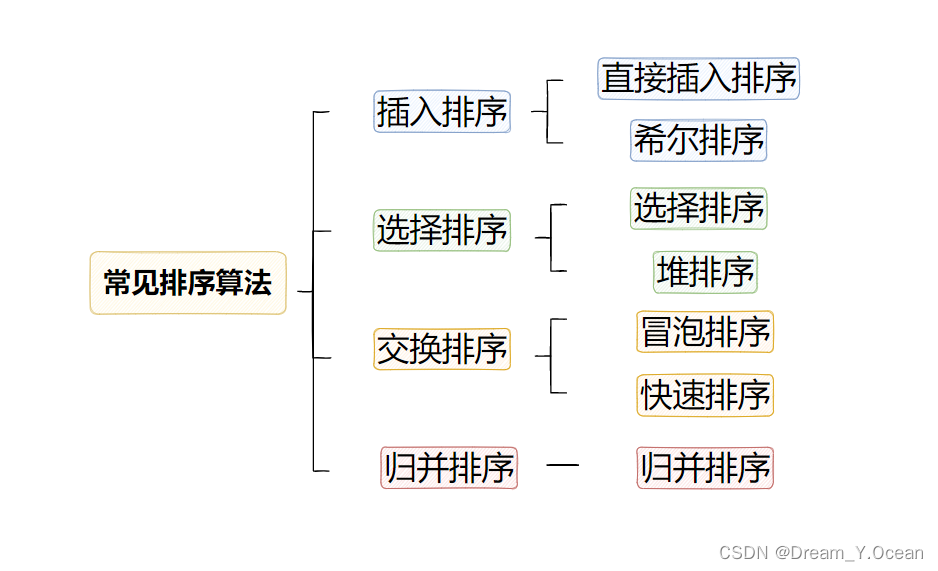
- 深入了解与实现
交换排序 - 深入了解与实现
归并排序
🍞一.交换排序
💡基本思想:
- 所谓
交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置 - 交换排序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动
👆简单来说:
- 就是通过依次的比较大小,从而将
大值(或小值)往后挪动,而小值(或大值)往前挪动,最终达到排序的效果
而对于交换排序类型最常见的有两种排序算法:
- 1️⃣冒泡排序
- 2️⃣快速排序
👉接下来就让我们来深入了解这两种排序算法吧~
🥐Ⅰ.冒泡排序
💡算法思想:
- 1️⃣每一次遍历数组,通过前后比较的方式,让每一趟排序下的
最大值都到正确的排序位置上 - 2️⃣反复如此,即可完全排序
❗特别注意:
-
冒泡排序的本质:可以理解为一个
双向选择的过程- 每一趟一边选出最大值,并将最大值放到最后的位置上
- 也一边将最小值在每一趟下不断往前移动,直至到达完全排序的位置上
-
针对特殊情况如:已经是
有序(或中途有序)的情况下,我们一般对冒泡排序采取优化措施 - 加一个有序标识符- 这样就可以在 一旦有序的情况下,跳出排序进程,减少执行次数,降低时间复杂度
✊动图示例:

👉代码实现:
void BubbleSort(int \*a, int n)
{ //多趟
for (int j = 0; j < n; j++)
{
int exchange = 0;
//单趟 -- 每次从前往后的将最后面的 给放好了
for (int i = 0; i < n - 1 - j; i++)
{
if (a[i] > a[i + 1])
{
Swap(&a[i], &a[i + 1]);
exchange = 1;
}
}
if (exchange == 0)
{
break;
}
}
}
🔥排序特性:
-
时间复杂度:
- 最坏的情况下:
O
(
N
2
)
O(N^2)
O(N2)
- 最好的情况下:
O
(
N
)
O(N)
O(N)
-
稳定性:稳定
-
冒泡排序和插入排序相比之下:
- 在已经有序的情况下,它们的时间复杂度一样
- 在接近有序的情况下,插入排序优于冒泡排序【因为插入排序对于接近有序的情况适应性更强】
🥐Ⅱ.快速排序
💡算法思想:
- 1️⃣任取待排序元素序列中的某元素作为
基准值,按照该排序码将待排序集合分割成两子序列:左子序列、右子序列 - 2️⃣
左子序列中所有元素均小于基准值 - 3️⃣
右子序列中所有元素均大于基准值 - 4️⃣然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止
👆快排常见版本:
- Hoare版本(左右指针法)
- 挖坑法
- 前后指针版本
✨接下来让我们逐一讲解上述三个版本吧~
🧇1.Hoare版本(左右指针法)
➡️算法思想:
-
1️⃣在未排序序列中选出一个值作为
key(基准值)【一般选择最左边的值 or 最右边的值】 -
2️⃣对于未排序序列的每一趟排序后,都要保证:
key值放到正确的位置上key值左边的序列的值都要小于keykey值右边的序列的值都要大于key
即需要对于每趟排序都有两个记录下标的标识符:【让与key位置相对的位置标识符先走】
left:从未排序序列最左边开始出发,负责找比key大的值,一旦找到就停下来right:从未排序序列最右边开始出发,负责找比key小的值,一旦找到就停下来- 然后将
left与right下标所对应的值进行交换 【当left与right相遇的时候,再将key与left交换,达到2️⃣中的要求】 - 3️⃣对未排序序列重复上述的操作,直至排序完全
⬆️不难发现:
- 通过上述的算法拆分,我们可以利用递归帮助完成
Hoare版本的快排【也就是采用了分治的算法思想】
✊动图示例:

👉代码实现:
int PartSort(int\*a, int left, int right)
{
int key = left;
//相等 or 错过 的时候 就挑出循环
while (left < right)
{
//右边先走
//找小
while (left < right && a[right] >= a[key])
{
right--;
}
//找大
while (left < right && a[left] <= a[key])
{
left++;
}
Swap(&a[left], &a[right]);
}
//相遇
Swap(&a[key], &a[left]);
return left;
}
void QuickSort(int\*a, int begin, int end)
{
if (begin >= end)
{
return;
}
int meet = PartSort(a,begin,end);
QuickSort(a, begin, meet - 1);
QuickSort(a, meet + 1, end);
}
❓为什么要让⌈right⌋先走呢
- 因为⌈right⌋是与
key位置相对的位置标识符【即此时的key是在最左边,所以与此位置相对的位置就是最右边,即⌈right⌋】 - 之所以有上述要求,是因为这样可以保证直至⌈left⌋与⌈right⌋相遇时,此时下标所对应的数字仍小于
key所对应的数字 - 那再与
key交换后,也可以依然保证key左边的序列的值都小于key,key右边的序列的值都大于key
🧇2.挖坑法
➡️算法思想:
- 与
Hoare版本的快速排序算法思想基本一致,都是利用递归(即分治的算法思想)去实现排序
但不同点在于:
挖坑法实则是⌈right⌋和⌈left⌋这两个下标标识符只要遇到满足条件的(即找比key大 or 小的值),就直接放到合适的位置上去【即一边找、一边放】- 而
Hoare版本是利用两个下标标识符去记录符合条件的位置,最后再统一交换位置
✊动图示例:

❗特别注意:
- 我们在操作中并不是真正的形成
坑位,只是在逻辑操作上想象成坑位即可【即实际中坑位还是放着原来的元素,只是我们操作的时候先将原来的元素保存起来,然后直接将要放置到坑位上的元素去覆盖原来的元素即可】 - 在⌈left⌋与⌈right⌋最后相遇的位置一定是一个
坑位,刚好给key放置
👉代码实现:
int PartSort(int\*a, int left, int right)
{
int key = a[left];
while (left < right)
{
//找小
while (left < right && a[left] >= key)
{
right--;
}
//放到左边的坑位中
a[left] = a[right];
//找大
while (left < right && a[left] <= key)
{
left++;
}
//放到右边的坑位中,左边就形成新的坑
a[right] = a[left];
}
//一定会相遇,且相遇的位置一定是坑
a[left] = key;
return left;
}
void QuickSort(int\*a, int begin, int end)
{
if (begin >= end)
{
return;
}
int meet = PartSort(a,begin,end);
QuickSort(a, begin, meet - 1);
QuickSort(a, meet + 1, end);
}
🧇3.前后指针法
➡️算法思想:
-
有两个指针:
cur、prev【cur的位置在prev的下一个位置】 -
期间通过
cur去遍历数组,通过一个一个元素与key值比较大小- 若发现比
key值小的,就让prev++(即走到下一个位置),再与cur此时对应的元素进行交换
- 若发现比
-
借助
递归(即分治算法思想)重复上述的步骤,即可实现完全排序
✨简单来说:
prev与一开始key所在的位置之间的间隔区间:实则是在维护一段元素都比key值小的区域【即最终要达到key的左边的序列的值都要比key值小的效果】prev++与cur之间的间隔区间:实则是在维护一段元素都比key值大的区域【即最终要达到key的右边的序列的值都要比key值大的效果】- 而不断让
cur去找比key小的值并与prev++交换的目的:就是为了找到还在序列后面比key小的元素,并将其交换到prev与一开始key所在位置的这段比key小的序列内,最终保证key的左子序列的值都比key小,右子序列都比key大
✊动图示例:

👉代码实现:
int PartSort(int\*a, int left, int right)
{
int midIndex = GetMidIndex(a, left, right);
Swap(&a[left], &a[midIndex]);
int key = left;
int prev = left;
int cur = left + 1;
while (cur <= right)
{
if (a[cur] < a[key] && ++prev != cur)
//这里省了一步:就是 prev++后如果和cur是在同一位置下
//就可以没必要交换了,没必要 自己交换自己
{
Swap(&a[cur], &a[prev]);
}
cur++;
}
Swap(&a[key], &a[prev]);
return prev;
}
void QuickSort(int\*a, int begin, int end)
{
if (begin >= end)
{
return;
}
int meet = PartSort(a,begin,end);
QuickSort(a, begin, meet - 1);
QuickSort(a, meet + 1, end);
}
🔥快速排序的优化
💡快速排序的优化两种方式:
- 三数取中
- 小区间优化排序
1️⃣三数取中
⭐我们先来看看第一种优化方式:三数取中
- 本质:这是针对
key选值的优化,避免一开始key可能选取最大值 or 最小值的情况【所以可以将此优化方式放在排序最开始key选值的部分】 - 运用了
三数取中即可通过一开始就比较序列中的头、中、尾的三个数字的大小,选出大小为中间值的作为key
❗特别注意:
- 我们依然让
key在序列最左边的位置,这样可以方便排序 - 所以我们需要再
三数取中的优化后,将中间值所在的位置换去序列的最左边的位置
👉代码实现:
int GetMidIndex(int\*a, int left, int right)
{
int mid = (left + right) >> 1;//相当于除2
//left mid right
if (a[left] < a[mid])
{
if (a[mid] < a[right])
{
return mid;
}
//这种情况就是:mid是最大的
else if(a[left] > a[right])
{
return left;
}
else
{
return right;
}
}
else //a[left] > a[mid]
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[left] > a[right])
{
return right;
}
else
{
return left;
}
}
}
2️⃣小区间优化排序
⭐我们先来看看第二种优化方式:小区间优化排序
- 本质:优化排序的时间复杂度,减少不必要的调用递归次数
- 即在执行第一次的排序递归操作后,已然分为两个待排序区间
左子序列、右子序列,若这两个序列区间都为小区间,便可以直接对小区间进行排序,无须再继续快速排序的递归操作
❗特别注意:
- 因为是
小区间,所以对于有限个数的区间进行排序,我们优先选择直接插入排序【此排序的适应性强】
👉代码实现:
void QuickSort(int\*a, int begin, int end)
{
if (begin >= end)
{
return;
}
//1.如果这个子区间是数据较多的
//继续选key进行单趟排序,然后分割子区间进行分治递归
if (end - begin > 10)
{
int meet = PartSort(a, begin, end);
QuickSort(a, begin, meet - 1);
QuickSort(a, meet + 1, end);
}
else
//否则,对于数据量小的区间来说
//可以直接选择排序,无需再递归
{
InsertSort(a + begin, end - begin + 1);
}
}
🥯Ⅲ.总结
🔥快速排序特性:
-
快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序
-
时间复杂度:
- 最好的情况下:
O
(
N
l
o
g
N
)
O(NlogN)
O(NlogN)
- 最坏的情况下:
O
(
N
2
)
O(N^2)
O(N2)
-
空间复杂度:

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
🥯Ⅲ.总结
🔥快速排序特性:
-
快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序
-
时间复杂度:
- 最好的情况下:
O
(
N
l
o
g
N
)
O(NlogN)
O(NlogN)
- 最坏的情况下:
O
(
N
2
)
O(N^2)
O(N2)
-
空间复杂度:
[外链图片转存中…(img-EaZceyQC-1715884270433)]
[外链图片转存中…(img-QoBZq6ju-1715884270433)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









