







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
- insert into Table1 ([Da
ta1] ,[Da
ta2] ,[Da
ta3] ,[Name1],[Name2] ,[Name3])
7. values(@i , 2* @i ,3*@i, CAST(@i AS NVARCHAR(50)), CAST(2*@i AS NVARCHAR(50)), CAST(3*@i AS NVARCHAR(50)))
8. set @i = @i + 1
9. end
10. update table1 set dtat= DateAdd (s, da
ta1, dtat)
复制代码
打开查询分析器的IO统计和时间统计:
- SET STATISTICS IO ON;
- SET STATISTICS TIME ON;
复制代码
显示实际的“执行计划”:
我们最常用的SQL查询是这样的:
- SELECT * FROM Table1 WHERE Da
ta1 = 2 ORDER BY DTAt DESC;
复制代码
先在Table1设主键ID,系统自动为该主键建立了聚簇索引。
然后执行该语句,结果是:
- Table ‘Table1’. Scan count 1, logical reads 911, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- SQL Server Execution Times:
- CPU time = 16 ms, elapsed time = 7 ms.
复制代码

然后我们在Data1和DTat字段分别建立非聚簇索引:
- CREATE NONCLUSTERED INDEX [N_Da
ta1] ON [dbo].[Table1]
2. (
3. [Da
ta1] ASC
4. )WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, IGNORE_DUP_KEY = OFF, ON
LINE = OFF) ON [PRIMARY]
5. CREATE NONCLUSTERED INDEX [N_DTat] ON [dbo].[Table1]
6. (
7. [DTAt] ASC
8. )WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, IGNORE_DUP_KEY = OFF, ON
LINE = OFF) ON [PRIMARY]
复制代码
再次执行该语句,结果是:
- Table ‘Table1’. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- SQL Server Execution Times:
- CPU time = 0 ms, elapsed time = 39 ms.
复制代码
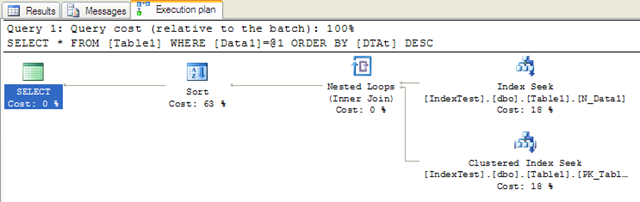
可以看到设立了索引反而没有任何性能的提升而且消耗的时间更多了,继续调整。
然后我们删除所有非聚簇索引,并删除主键,这样所有索引都删除了。建立组合索引Data1和DTAt,最后加上主键:
- CREATE CLUSTERED INDEX [C_Da
ta1_DTat] ON [dbo].[Table1]
2. (
3. [Da
ta1] ASC,
4. [DTAt] ASC
5. )WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, IGNORE_DUP_KEY = OFF, ON
LINE = OFF) ON [PRIMARY]
复制代码
再次执行语句:
- Table ‘Table1’. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- SQL Server Execution Times:
- CPU time = 0 ms, elapsed time = 1 ms.
复制代码
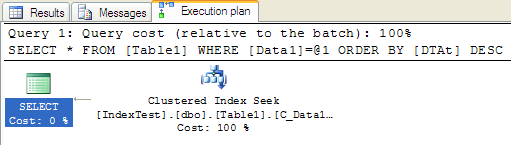
可以看到只有聚簇索引seek了,消除了index scan和nested loop,而且执行时间也只有1ms,达到了最初优化的目的。
组合索引小结
小结以上的调优实践,要注意聚簇索引的选择。首先我们要找到我们最多用到的SQL查询,像本例就是那句类似的组合条件查询的情况,这种情况最好使用组合聚簇索引,而且最多用到的字段要放在组合聚簇索引的前面,否则的话就索引就不会有好的效果,看下例:
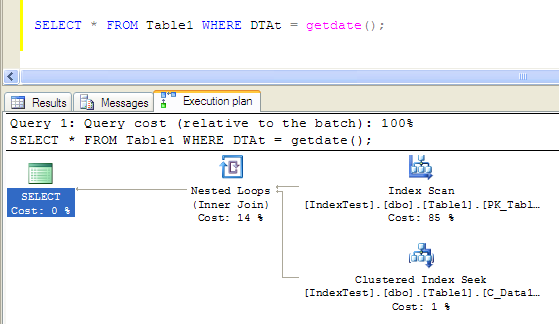
查询条件落在组合索引的第二个字段上,引起了index scan,效果很不好,执行时间是:
- Table ‘Table1’. Scan count 1, logical reads 238, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- SQL Server Execution Times:
- CPU time = 16 ms, elapsed time = 22 ms.
复制代码
而如果仅查询条件是第一个字段也没有问题,因为组合索引最左前缀原则,实践如下:
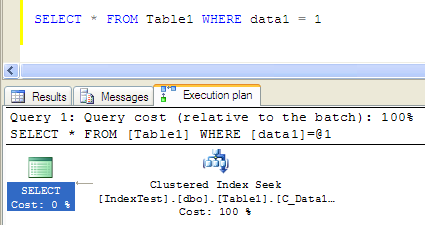
- Table ‘Table1’. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- SQL Server Execution Times:
- CPU time = 0 ms, elapsed time = 1 ms.
复制代码
从中可以看出,最多用到的字段要放在组合聚簇索引的前面。
Index seek 为什么比 Index scan好?
索引扫描也就是遍历B树,而seek是B树查找直接定位。
Index scan多半是出现在索引列在表达式中。数据库引擎无法直接确定你要的列的值,所以只能扫描整个整个索引进行计算。index seek就要好很多.数据库引擎只需要扫描几个分支节点就可以定位到你要的记录。回过来,如果聚集索引的叶子节点就是记录,那么Clustered Index Scan就基本等同于full table scan。
一些优化原则
1、缺省情况下建立的索引是非聚簇索引,但有时它并不是最佳的。在非群集索引下,数据在物理上随机存放在数据页上。合理的索引设计要建立在对各种查询的分析和预测上。一般来说:
a.有大量重复值、且经常有范围查询( > ,< ,> =,< =)和order by、group by发生的列,可考
虑建立群集索引;
b.经常同时存取多列,且每列都含有重复值可考虑建立组合索引;
c.组合索引要尽量使关键查询形成索引覆盖,其前导列一定是使用最频繁的列。索引虽有助于提高性能但不是索引越多越好,恰好相反过多的索引会导致系统低效。用户在表中每加进一个索引,维护索引集合就要做相应的更新工作。
2、ORDER BY和GROPU BY使用ORDER BY和GROUP BY短语,任何一种索引都有助于SELECT的性能提高。
3、多表操作在被实际执行前,查询优化器会根据连接条件,列出几组可能的连接方案并从中找出系统开销最小的最佳方案。连接条件要充份考虑带有索引的表、行数多的表;内外表的选择可由公式:外层表中的匹配行数*内层表中每一次查找的次数确定,乘积最小为最佳方案。
4、任何对列的操作都将导致表扫描,它包括数据库函数、计算表达式等等,查询时要尽可能将操作移至等号右边。
5、IN、OR子句常会使用工作表,使索引失效。如果不产生大量重复值,可以考虑把子句拆开。拆开的子句中应该包含索引。
Sql的优化原则2:
1、只要能满足你的需求,应尽可能使用更小的数据类型:例如使用MEDIUMINT代替INT
2、尽量把所有的列设置为NOT NULL,如果你要保存NULL,手动去设置它,而不是把它设为默认值。
3、尽量少用VARCHAR、TEXT、BLOB类型
4、如果你的数据只有你所知的少量的几个。最好使用ENUM类型
使用SQLServer Profiler找出数据库中性能最差的SQL
首先打开SQLServer Profiler:
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 1390
1390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









