







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
2.实例化出一个堆对象时,需要将往外面需要的数值赋值给elem,那么再来一个initElem方法;
public class TestHeap {
public int[] elem;
public int usedSize;
//给数组一个默认容量
private static final int DEFAULT_SIZE = 10;
public TestHeap() {
elem = new int[DEFAULT_SIZE];
}
public void initElem(int[] array) {
for (int i = 0; i < array.length; i++) {
elem[i] = array[i];
usedSize++;
}
}
}
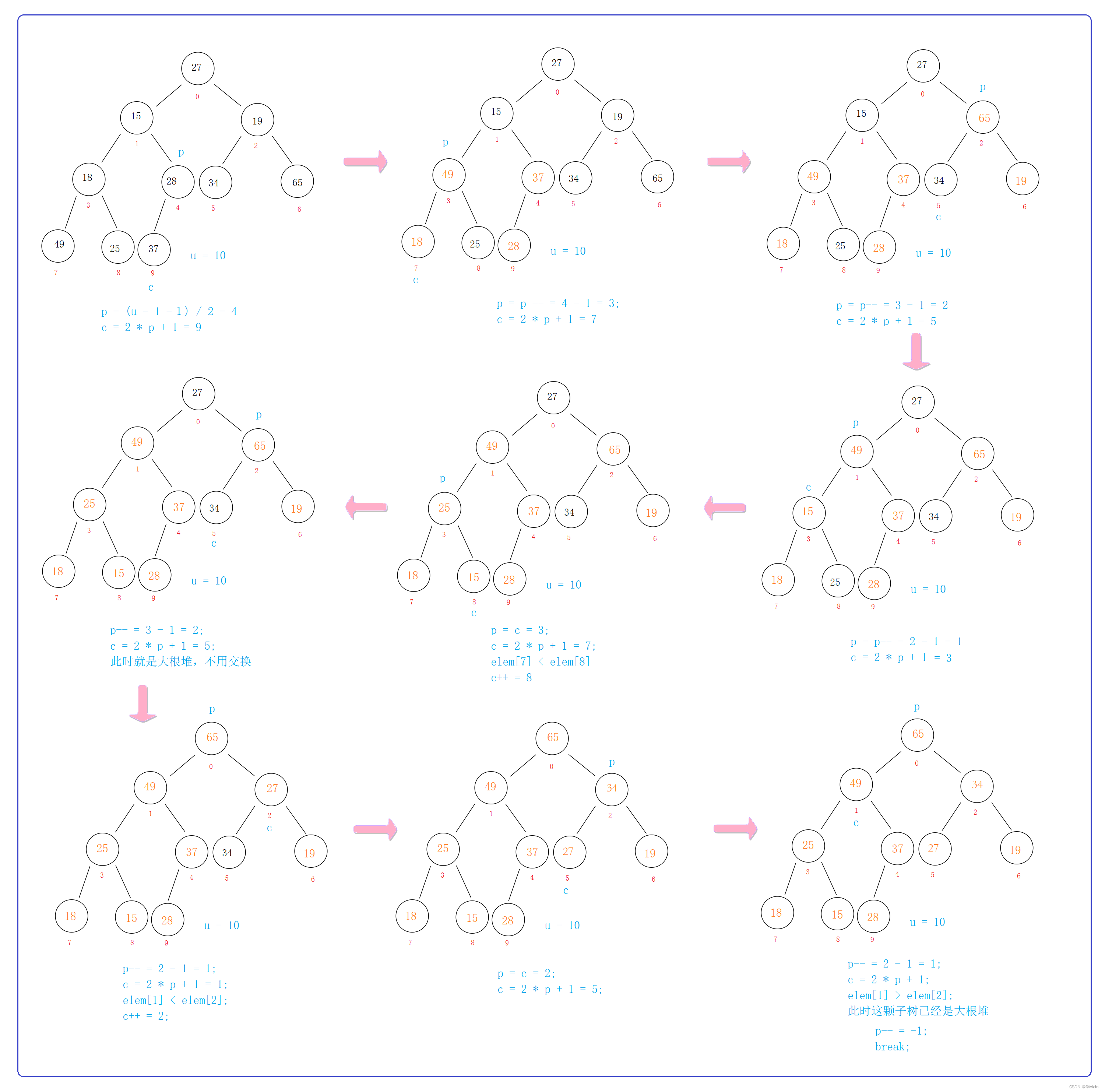
3.创建队就是将已知数组的元素插入到树的节点中的过程,但堆中的值比数组的要求更苛刻,要满足大根堆的要求,那我们就会想到,先直接将数组的所有元素直接按照顺序方式来创建成一颗完全二叉树,再向下调整每一棵子树的节点,直到每颗子树都满足大根堆,最终整棵树就是一个大根堆了;
4.向下调整:(最关键的细节)
先对最后一颗子树进行操作 ——> 拿到其父节点和子树节点中值最大的那一个 ——> 比较,如果不符合大根堆,就交换 ——> 继续向后比遍历这棵树,重复上述比较过程,直到每颗子树走到结束位置 ——> 当每颗子树都被调整成大根堆以后,整棵树就是大根堆了。
最详细的调整过程需要结合代码和下图进行推理:
/**
* 创建大根堆
* 复杂度:O(N)
*/
public void createHeap() {
for (int parent = (usedSize-1-1)/2; parent >= 0 ; parent--) {
shiftDown(parent,usedSize);
}
}
private void shiftDown(int parent,int len) {
int child = 2 * parent + 1;
while(child < len) {
//开始准备比较
//1.chile 是左子树节点,还要看它和右子树节点谁大,用大的来和parent比较
//所有要先看是否有有节点,没有的话就直接拿左子树节点去比较
if(child+1 < len && elem[child] < elem[child+1]) {
child++;
}
//此时的child一定是当前子树上最大的节点
//现在才可以开始比较
if(elem[child] > elem[parent]) {
int temp = elem[child];
elem[child] = elem[parent];
elem[parent] = temp;
//一次换完后还要看后面的节点是否也需要比较
parent = child;
child = 2 * parent + 1;
}
// 如果本来就是大根堆,那么这支树上就不需要交换
else {
break;
}
}
}
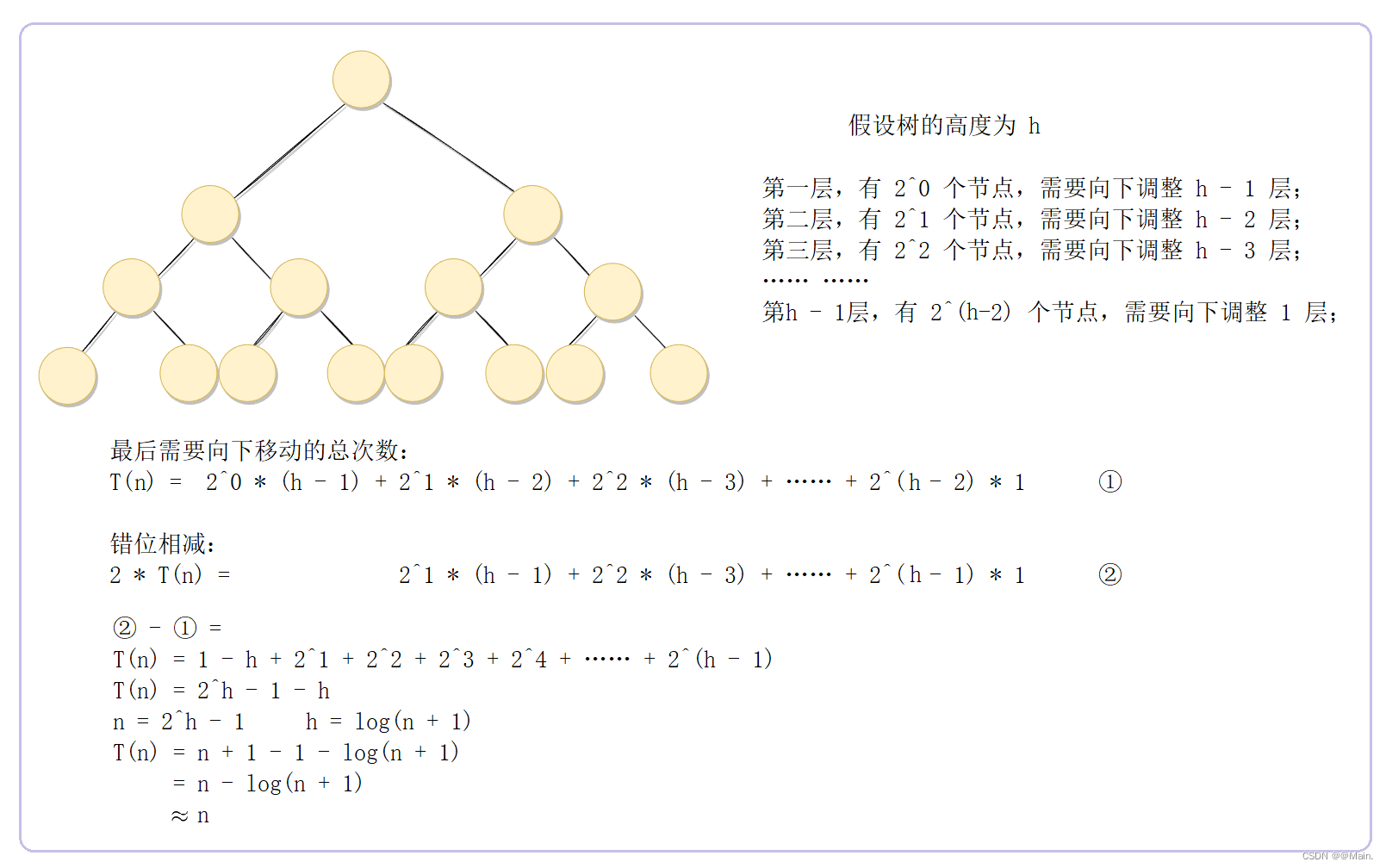
创建堆的复杂度:O(n)
推导过程:以满二叉树为例,假设每个节点都需要调整,这样就是最复杂的情况。
堆的插入:
对于堆的数组而言,插入元素即简单的尾插,但对于堆的二叉树而言,要时刻保持树是大根堆,就需要每次新增元素后向上调整根的大小;
思路:依然是大根堆
1.先检查数组是否需要扩容,插入新元素;
2.拿到最后一颗子树的最后一个节点,再拿到其父节点,两个节点值比较,不符合大根堆就交换,再向上检查,直到整棵树的根节点结束;
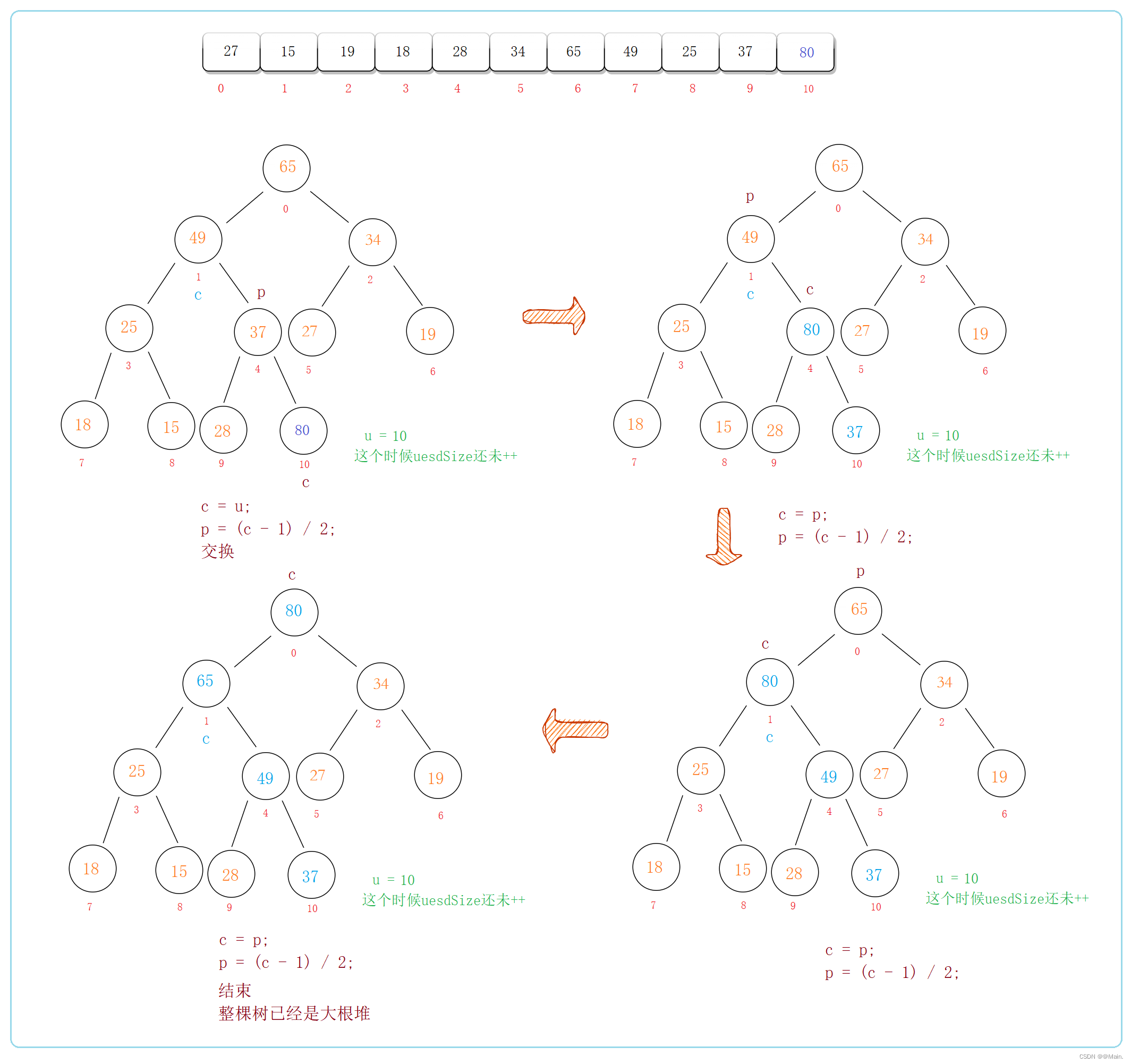
/**
* 插入元素 复杂度:O(logN)
* 对于自带的数组:肯定是尾插
* 对于树:插入后要保证依然是大根堆,因此要向上调整
*/
public void offer(int val) {
//满了要扩容
if(isFull()) {
elem = Arrays.copyOf(this.elem,2 * this.elem.length);
}
//未满 - 直接插入
elem[usedSize] = val;
//插入后要向上调整
shiftUp(usedSize);
//调整完
usedSize++;
}
private void shiftUp(int child) {
int parent = (child - 1) / 2;
while (parent >= 0) {
if(elem[child] > elem[parent]) {
int temp = elem[child];
elem[child] = elem[parent];
elem[parent] = temp;
//交换完后 - 向上走
child = parent;
parent = (child - 1) / 2;
} else {
break;
}
}
}
private boolean isFull() {
return usedSize == elem.length;
}
堆的删除:
思路:堆的删除,即弹出堆顶第一个元素;
1.先将树中下标为0的节点的值与树最后一个节点的值交换;
2.交换完从整棵树的根节点开始向下调整,同上,依然要保证树是大根堆;
/**
* 删除元素
* 先让下标为0的根节点数值与整棵树最后一个节点的数组交换
* 交换后 - 向下调整
*/
public int pop() {
//判断是否为空
if(isEmpty()) {
return -1;
}
//先交换
int temp = elem[0];
elem[0] = elem[usedSize - 1];
elem[usedSize - 1] = temp;
//交换完 - 向下调整
usedSize--;
shiftDown(0,usedSize);
return temp;
}
private boolean isEmpty() {
return usedSize == 0;
}
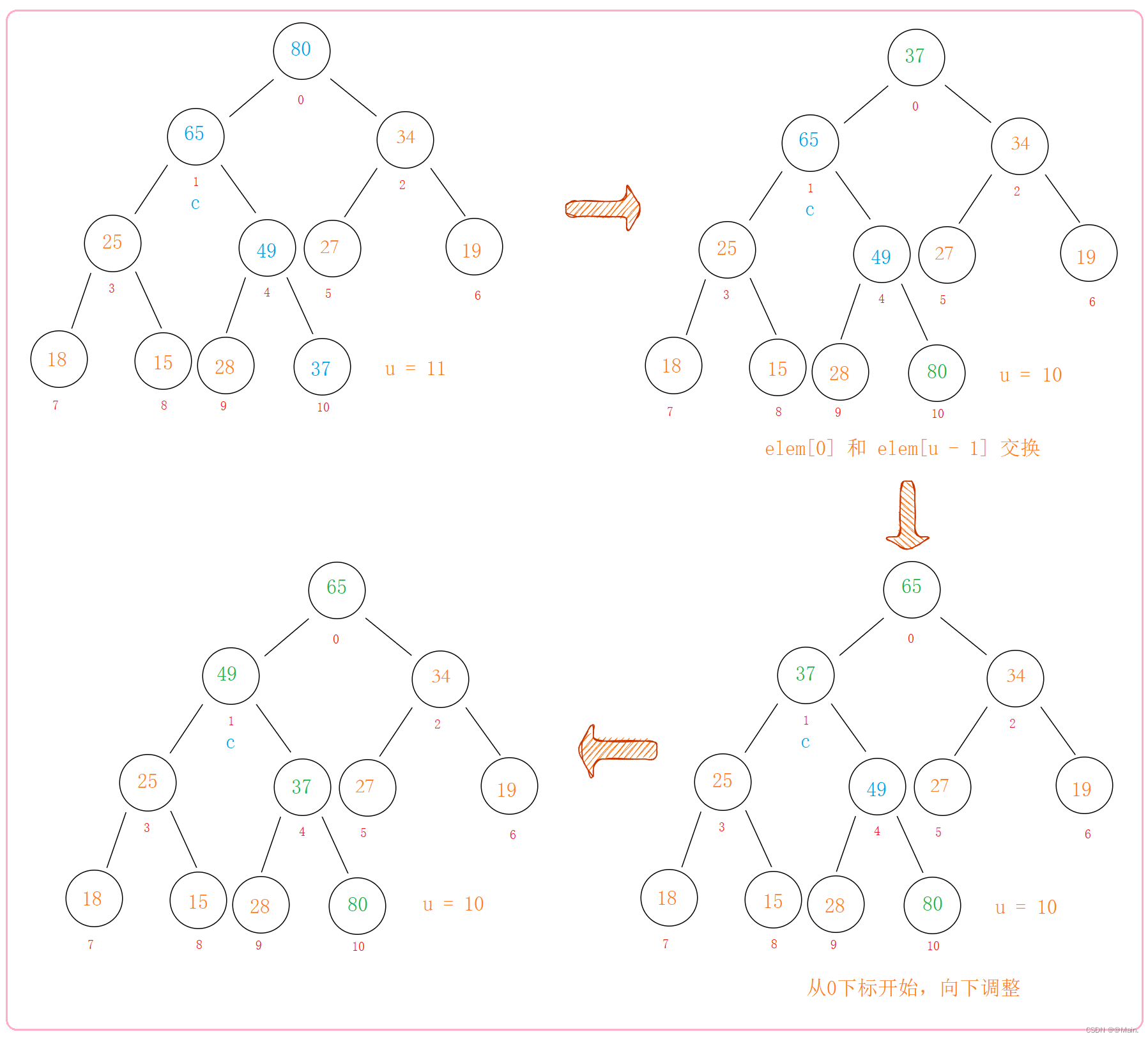
易错点:
usedSize–只有一次,因为下次插入元素时会直接将80覆盖掉。
易错题:
已知小根堆为8,15,10,21,34,16,12,删除关键字8之后需重建堆,在此过程中,关键字之间的比较次数是()
A: 1 B: 2 C: 3 D: 4

PriorityQueue集合类源码剖析

- PriorityQueue即优先级队列,其实现了Queue接口,所以具有Queue索具有的方法;
- 优先级队列有PriorityQueue和PriorityBlockingQueue之分,前者是线程不安全的,后者是线程安全的;
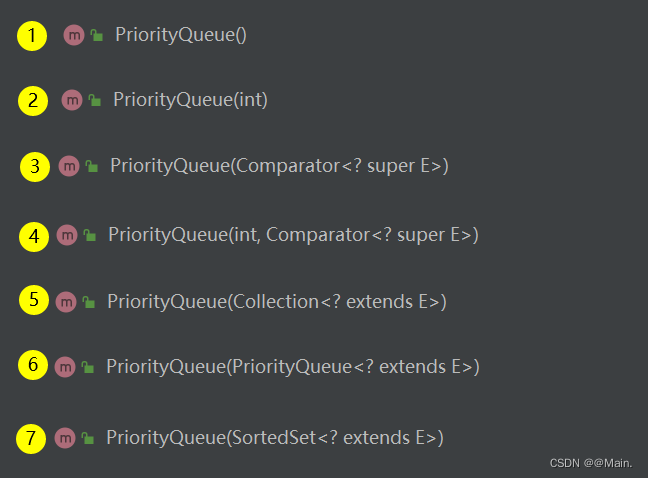
构造方法:
PriorityQueue类的构造方法有七种:
以下面这段代码为例展开源码剖析:
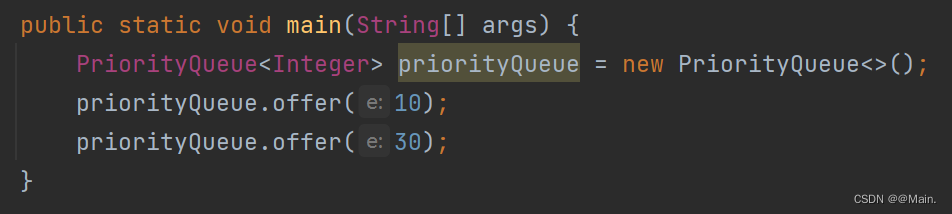
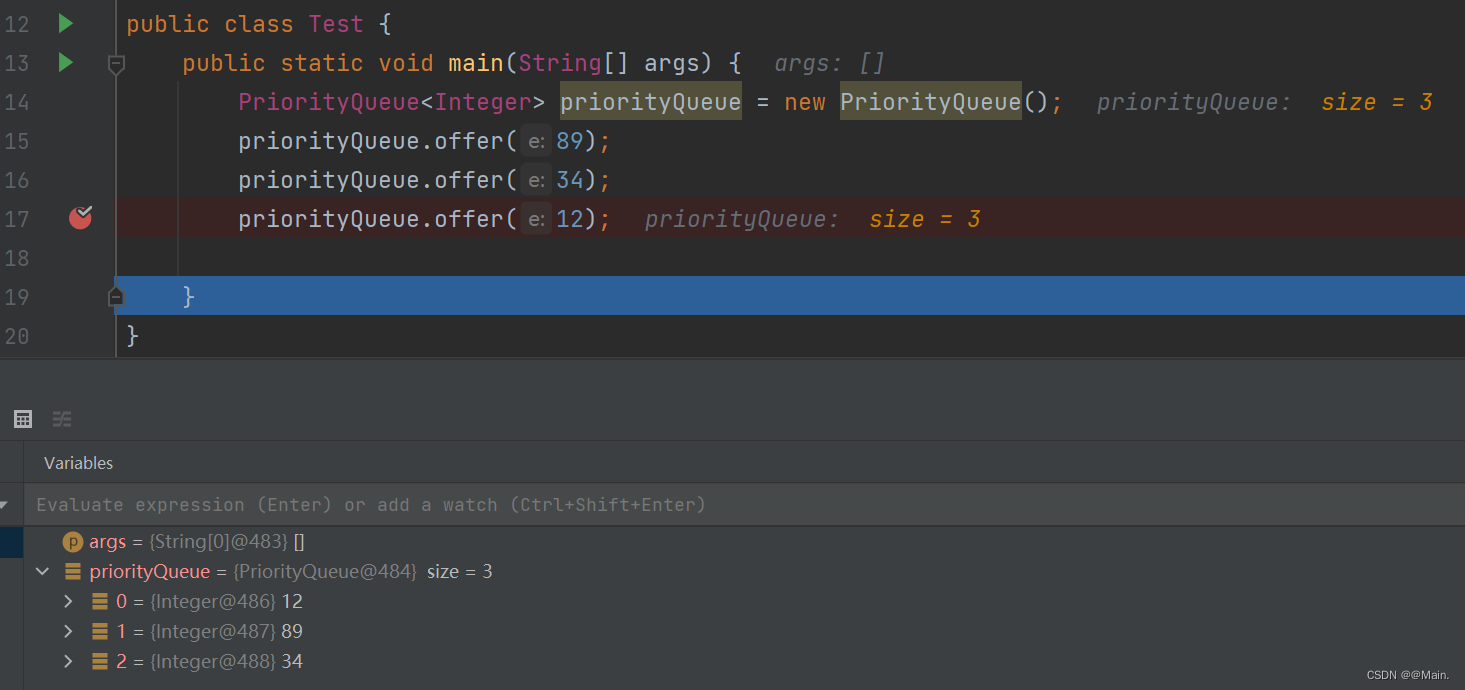
**PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();**
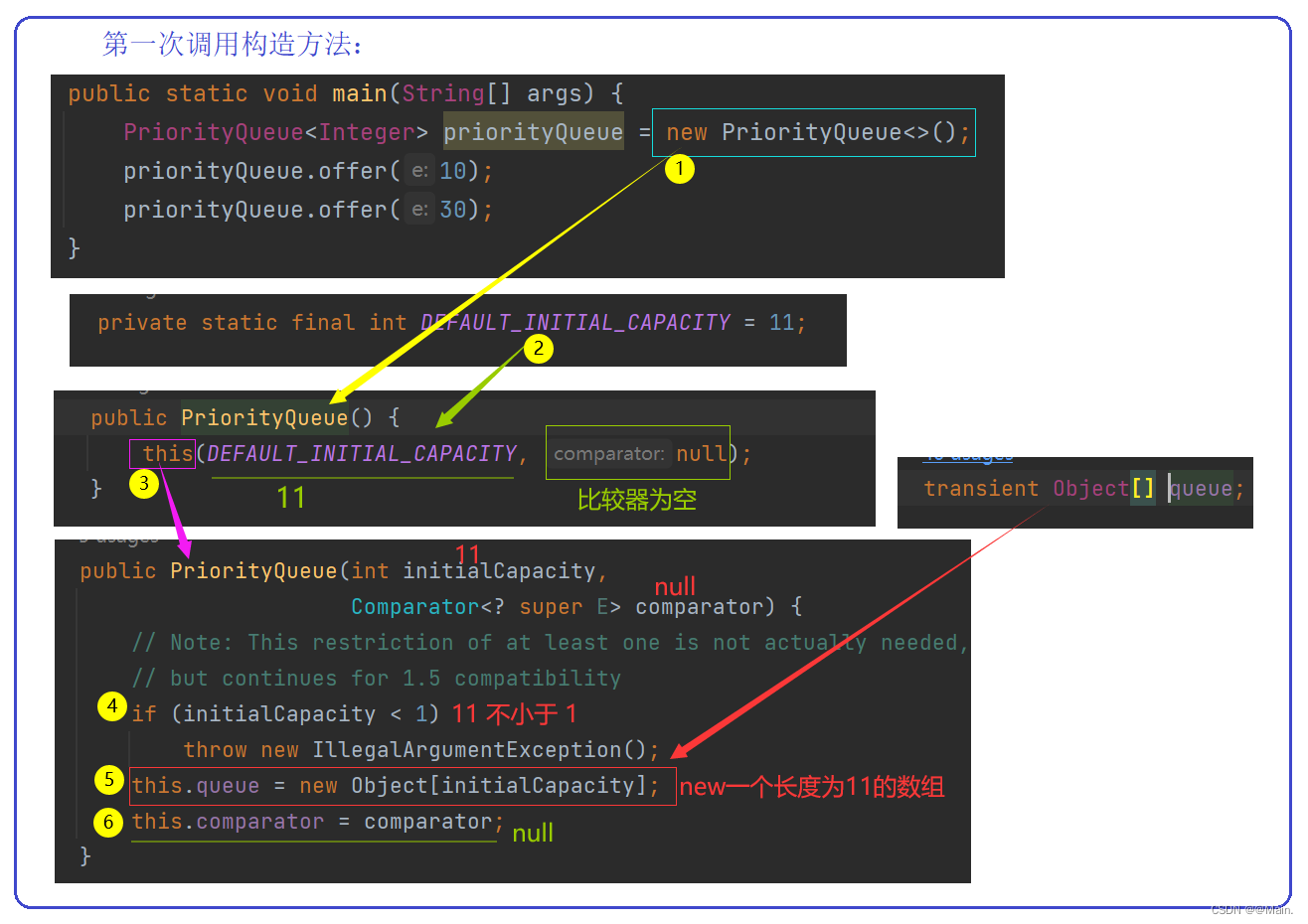
1.第一次调用构造方法:
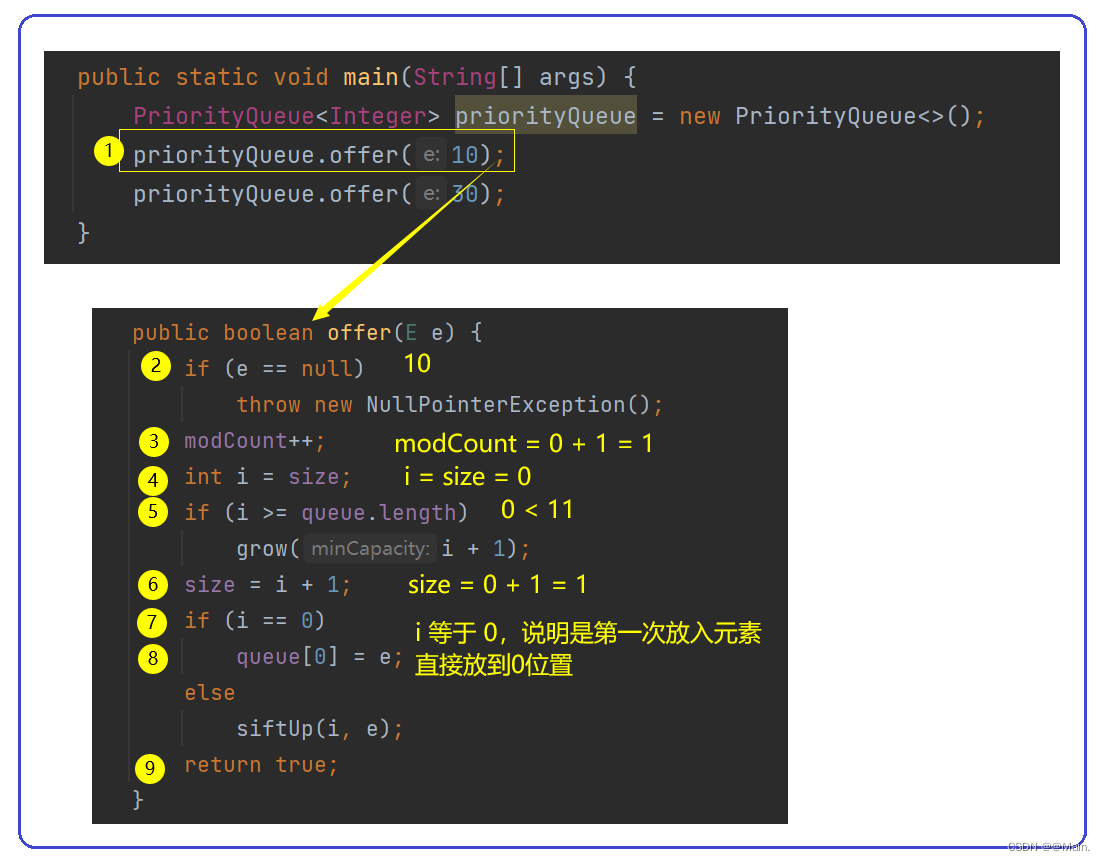
priorityQueue.offer(10);
2.第一次offer元素:
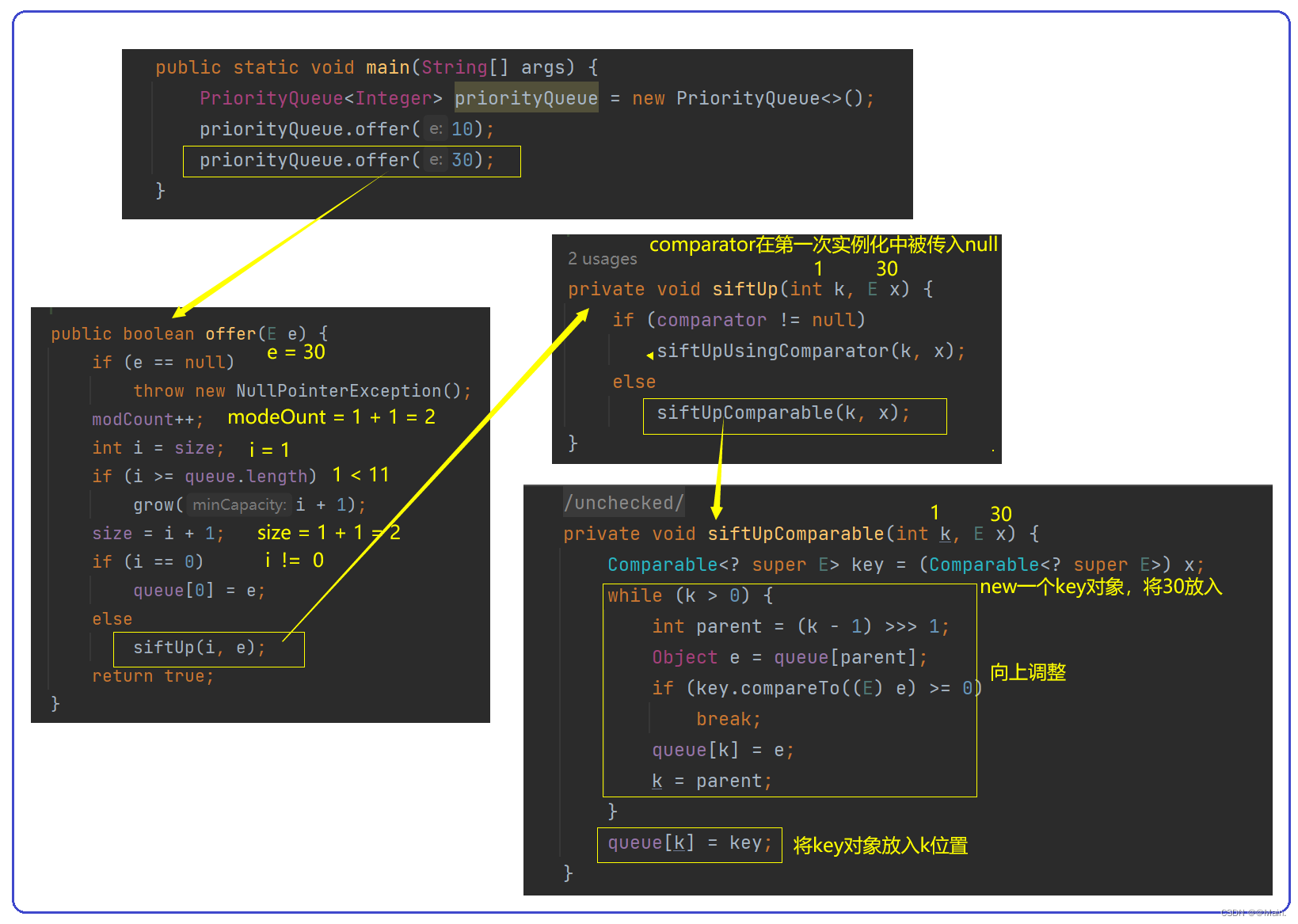
priorityQueue.offer(30);
3.第二次offer元素:
4.除了上述方法,我们还可以自己设置数组的默认长度,调用第②种构造方法:
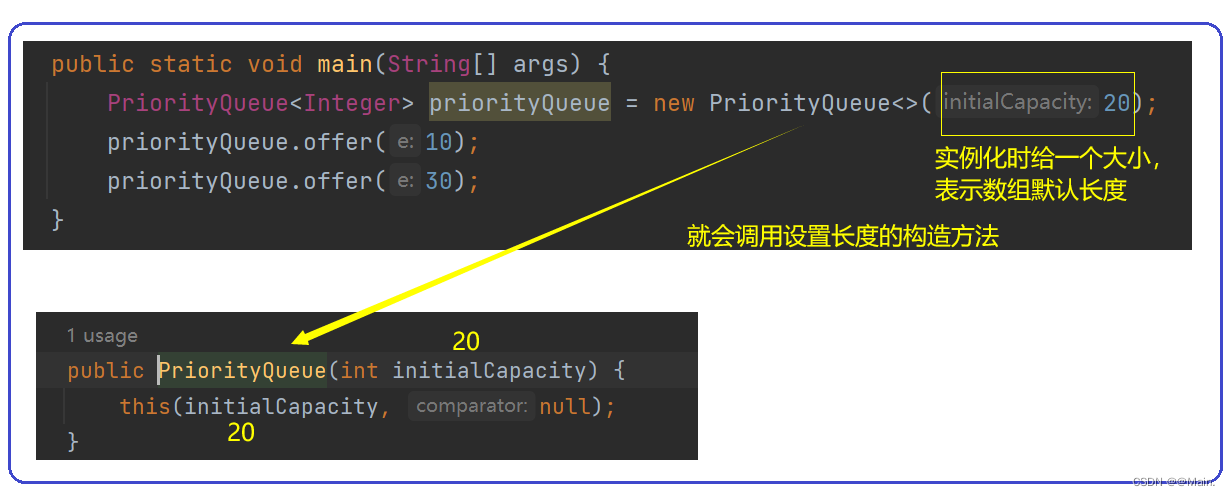
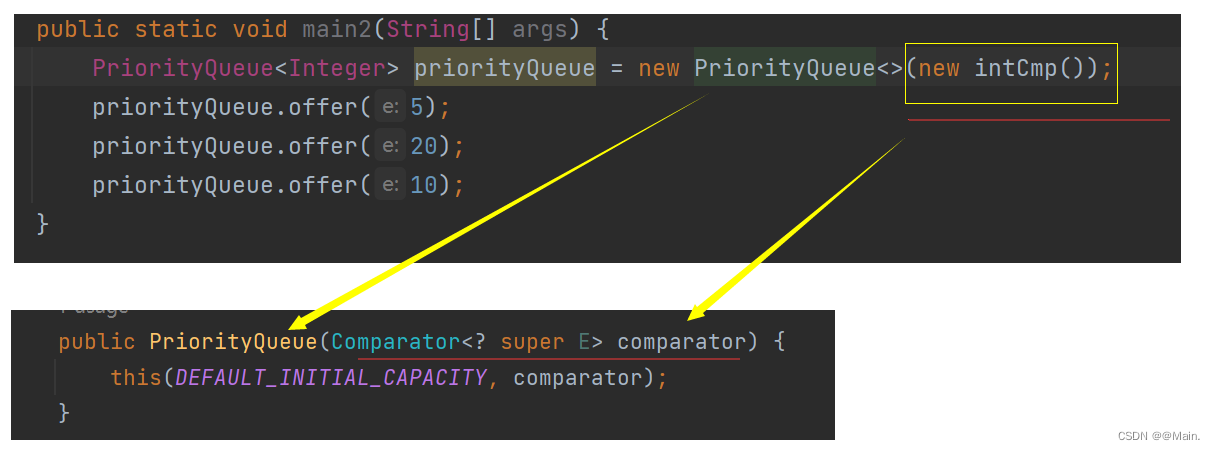
- 如果实例化时传入我们的比较器,就会调用第③种构造方法:
()比较器的写法在下面的“特性”中有介绍)
7.给堆传入Collection接口下的结构:
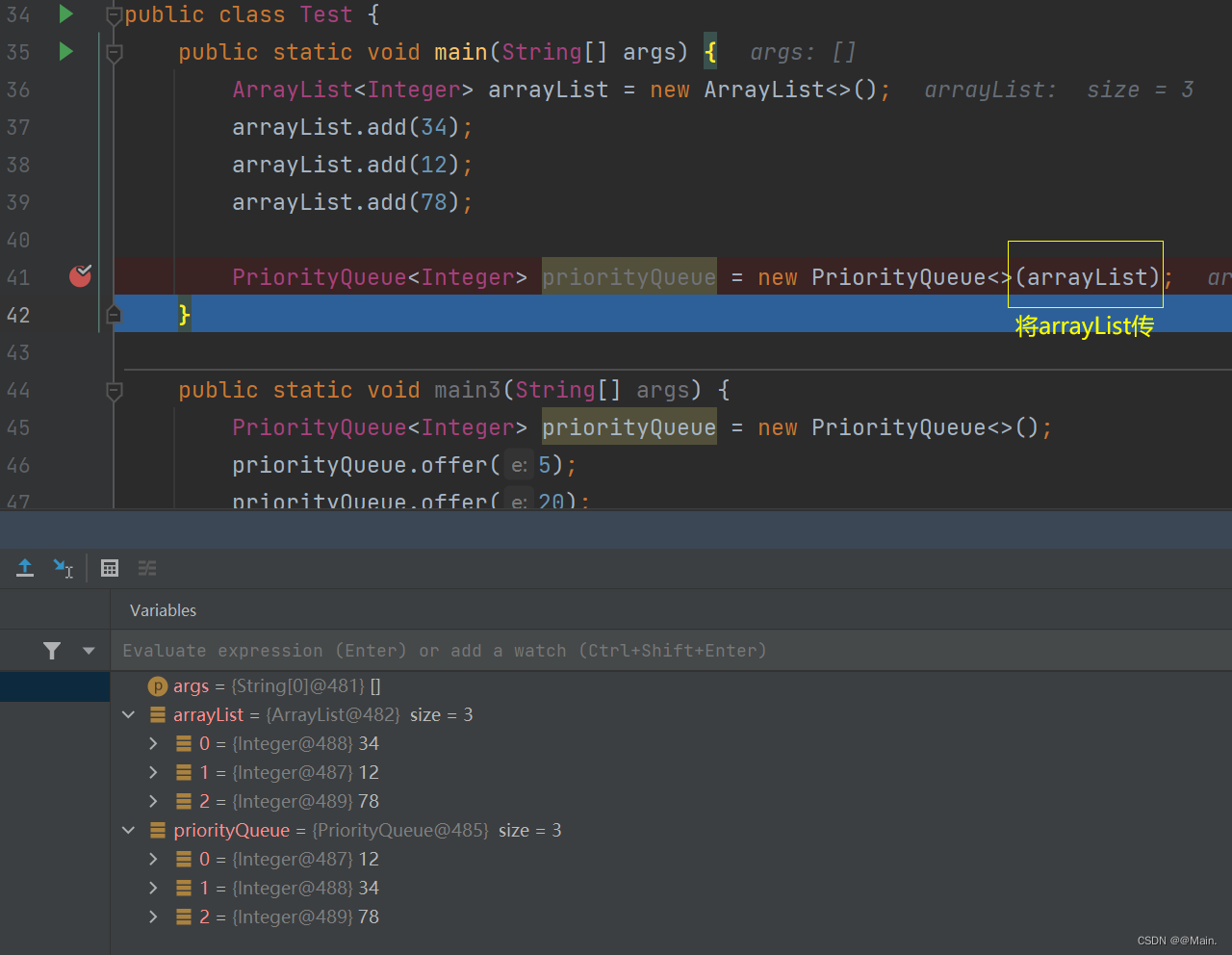
对应的构造方法:
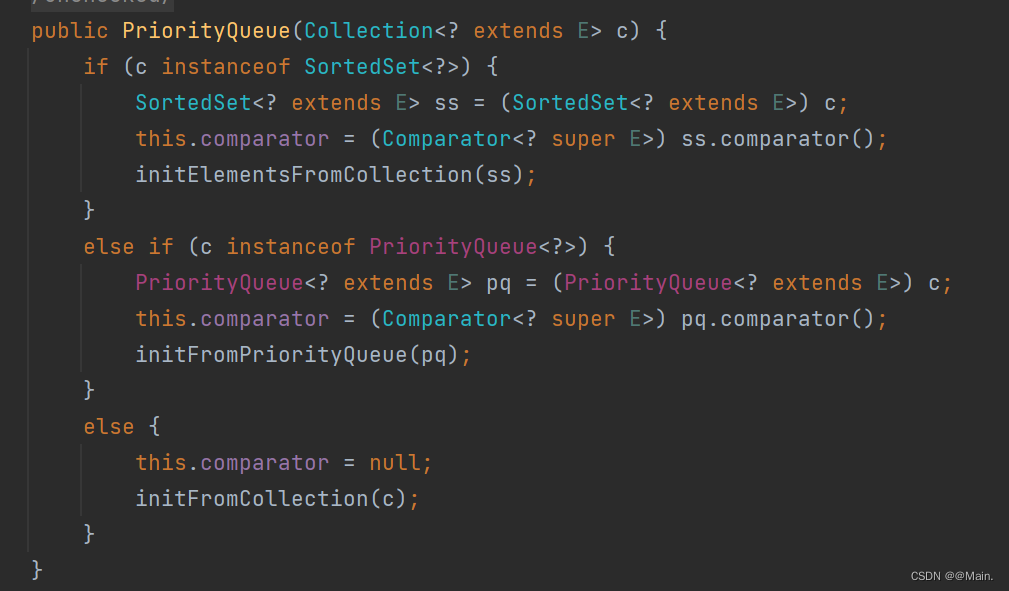
8.关于其他构造方法的时候,大家感兴趣可以自行阅读源码学习,如果这里的源码剖析有不明白的地方,可以学习完下面的“特性”后再回过来就一定可以完全理解。
总结:
1.第一次调用构造方法实例化出一个PriorityQueue对象时,相当于new一个长度为默认值的数组;
2.如果调用构造方法时,传入一个数值,就会调用初始化数组的构造方法;
如果调用构造方法时,传入一个比较器,就会调用实例化比较器的构造方法;
3.插入元素:
如果是第一次插入:直接放在0下标的位置;
如果不是第一次插入,并且没有传入比较器,那么首先要保证传入的对象是可比较的,其次offer方法会自动new一个可比较的key对象,再根据向上调整,最后选择合适位置放入元素;
如果不是第一次插入,并且传入了比较器,那么说明插入的数据是可比较的,因此offer方法会直接根据向上调整选择合适的位置放入元素;
4.优先使用比较器来比较;
PriorityQueue特性:
- PriorityQueue 本身实现的是小根堆:
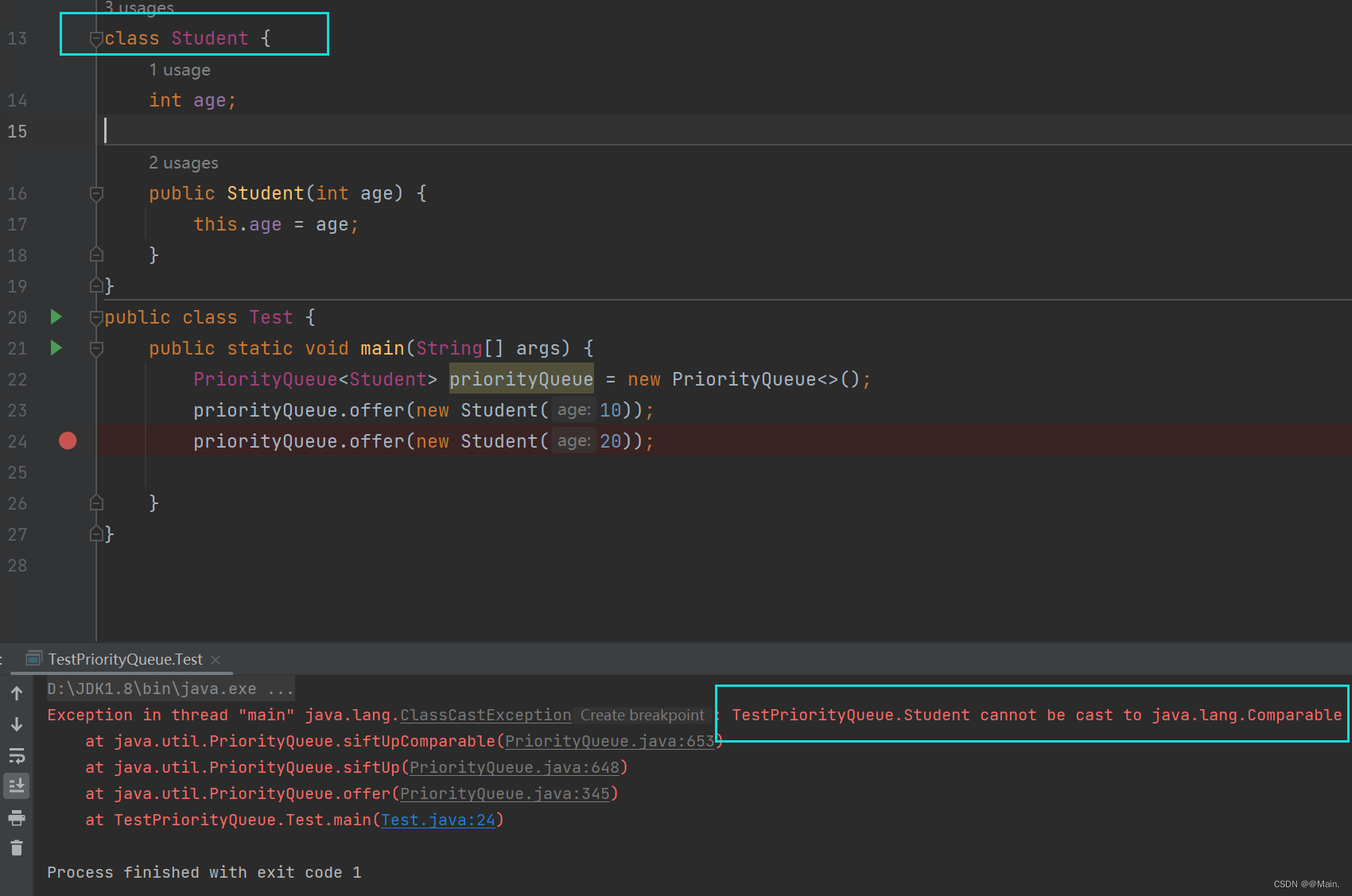
- PriorityQueue中放置的元素必须是能够比较大小的,否则会抛ClassCastExcepyion异常;
我们可以自己创建一个Student来,这个类是我们自己写的,并不具备比较功能,因此春给堆后就会抛异常;
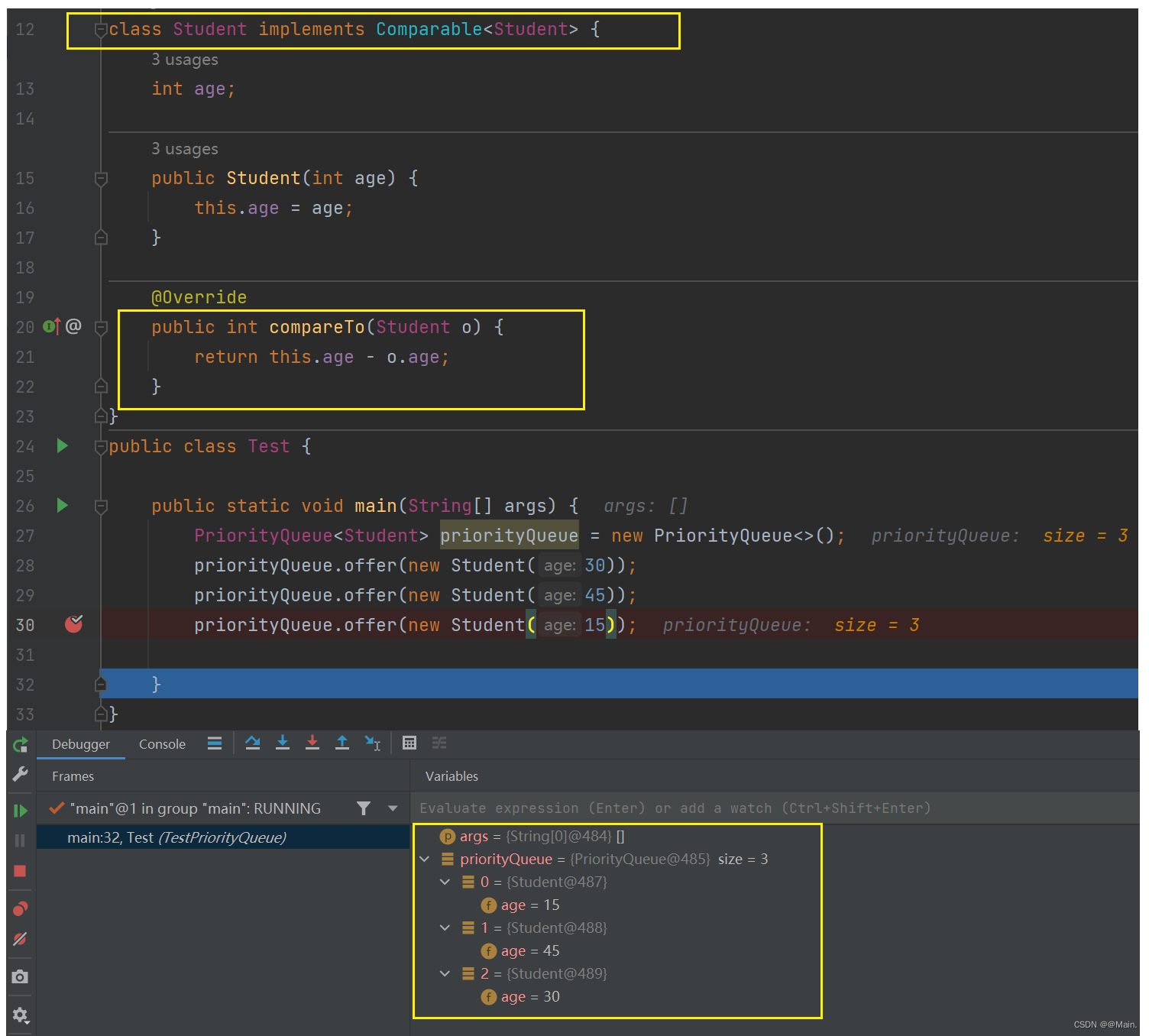
- 可以通过实现Comparable接口,重写CompareTo方法,传入我们的自定义类型:
如果要变成大根堆,只需要交换CompareTo方法的比较规则;
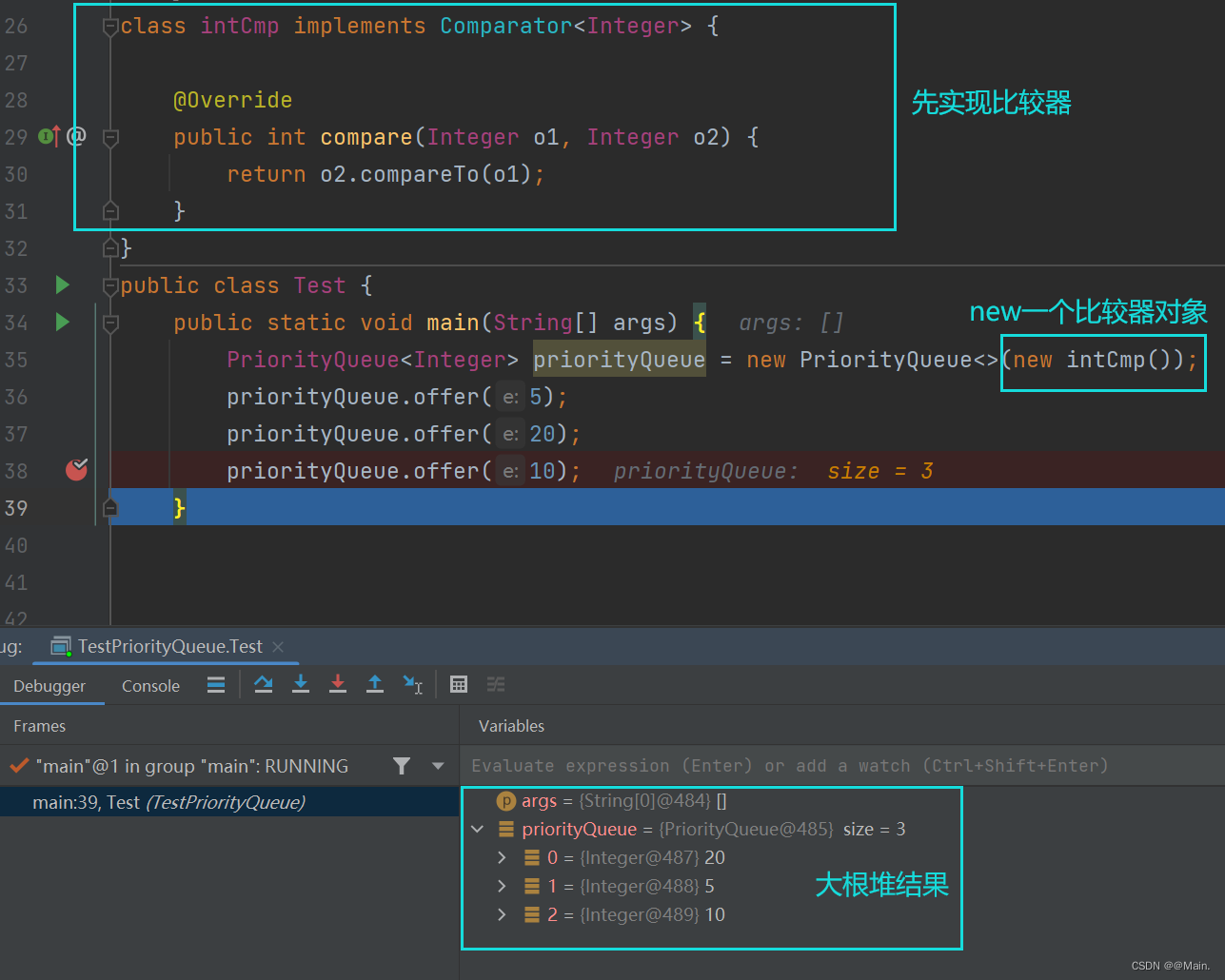
- 如果传入对象是语法中现有的类型,如Integer类、String类等,我们不能改变其源码中的比较规则,那怎么才能让它们变成大根堆呢?
方法:实现比较器
三种做题时的写法:
1.匿名内部类:
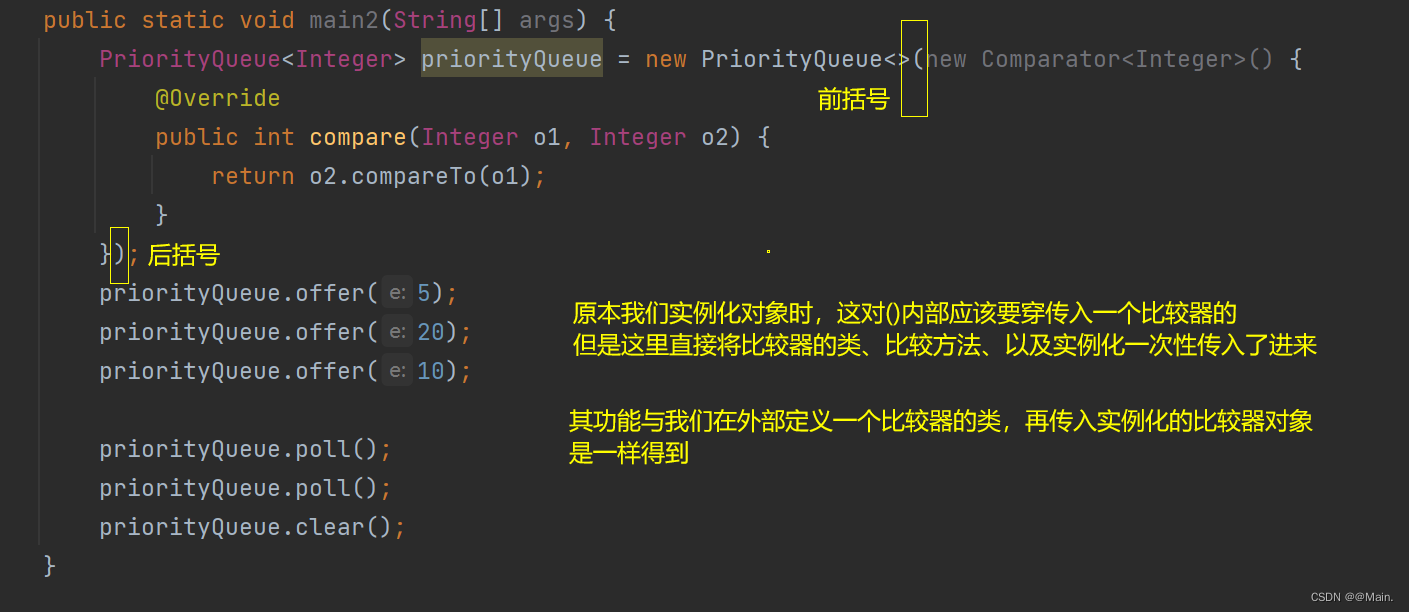
2.lambda表达式(JDK8语法):与上面等价
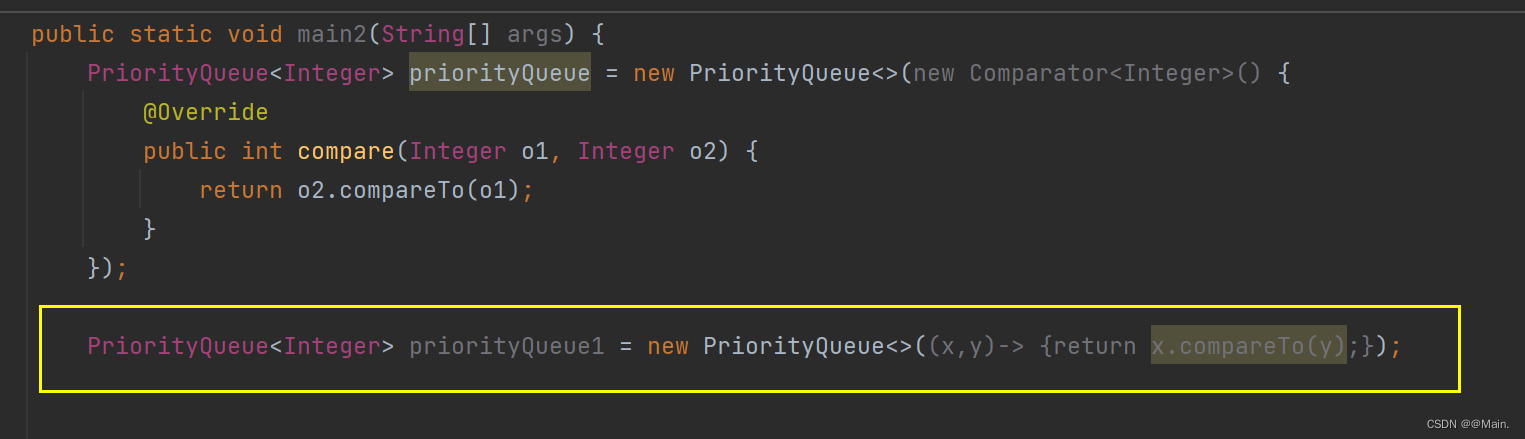
3.第三种也与上面的等价:
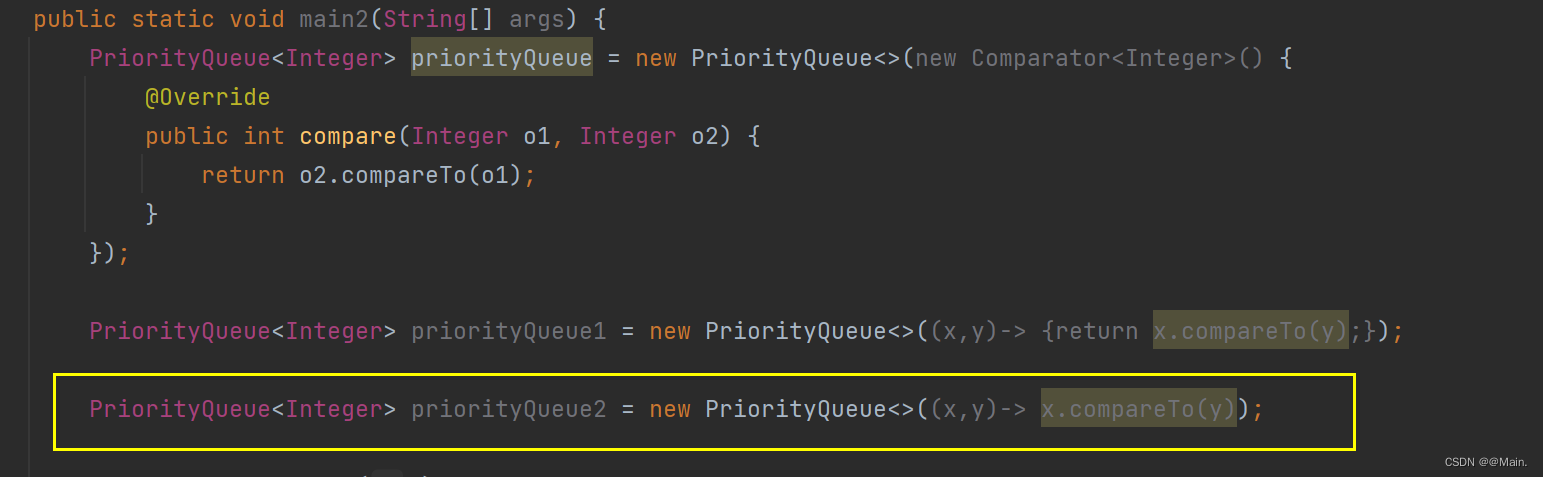
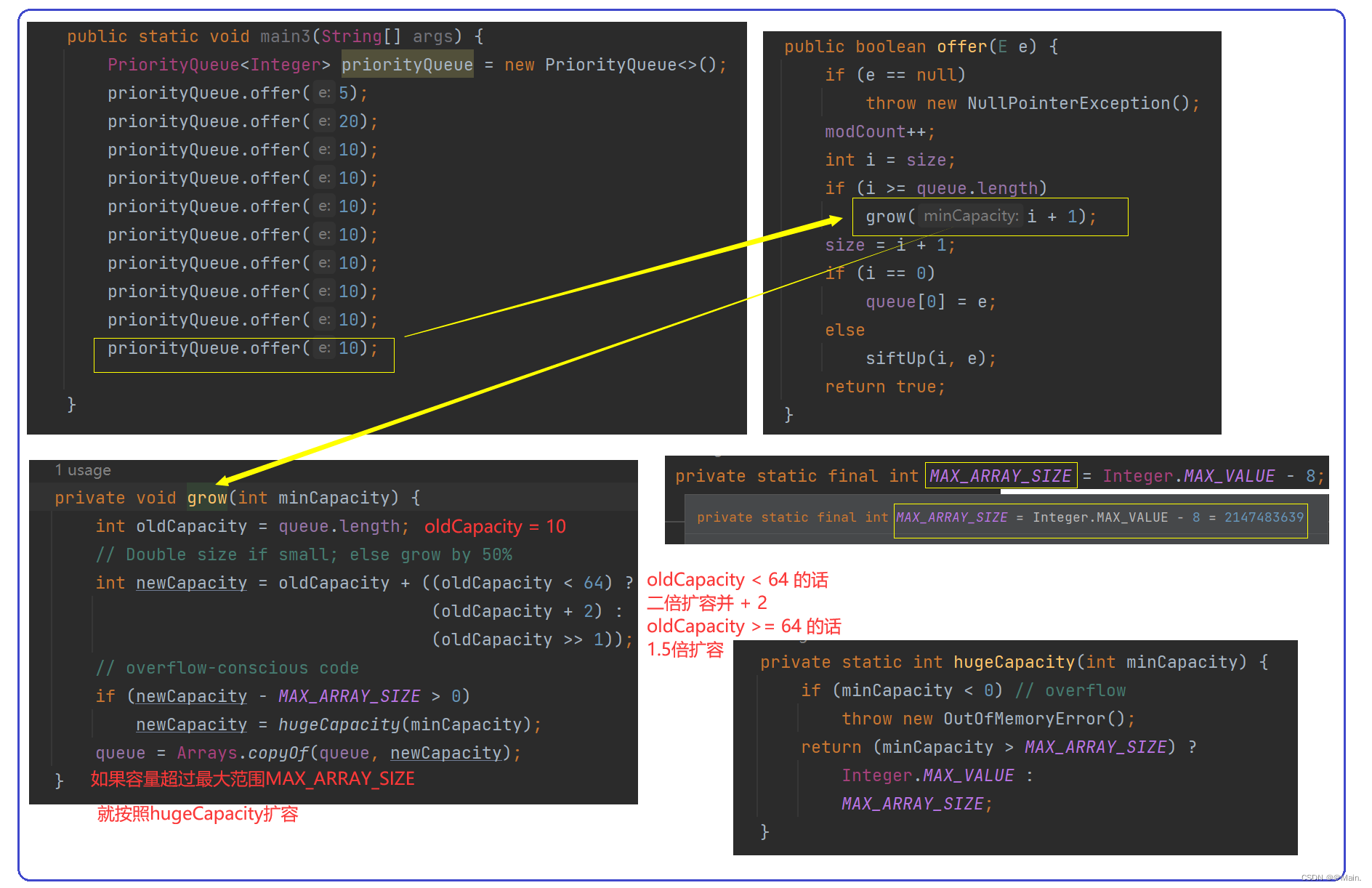
PriorityQueue的扩容机制:
经典OJ:
TOPK问题:
力扣 https://leetcode.cn/problems/smallest-k-lcci/
https://leetcode.cn/problems/smallest-k-lcci/
设计一个算法,找出数组中最小的k个数。以任意顺序返回这k个数均可。
示例:
输入: arr = [1,3,5,7,2,4,6,8], k = 4
输出: [1,2,3,4]
提示:0 <= len(arr) <= 100000
0 <= k <= min(100000, len(arr))来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/smallest-k-lcci
**①思路一:**对于初学者,一定会想到,我先把数组中的数据按照升序排列后,直接输出前k个数值即可。
是的,这种方法还是最简单分方法,但其实这种使用排序函数的方法对于数据量较小的情况更加适用,倘若数据量极大,那么借助排序函数不仅会使算法复杂度过高,还会导致数据无法一次性全部加载到内存中,因此我们建议使用堆来解决;
**②思路二:**先将数组中所有数据建立成小根堆,每次弹出堆顶元素(即最小的节点),再调整为小根堆(我们直接使用包中PriorityQueue集合类方法的话,会自动进行调整的,无需手动写调整方法),如此循环 k 次,每次弹出来的元素放入一个新数组中即可;
class Solution {
public int[] smallestK(int[] arr, int k) {
//1.建立一个小根堆 - PriorityQueue默认就是小根堆
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
//2.将数组放入小根堆中
for (int i = 0; i < arr.length; i++) {
priorityQueue.offer(arr[i]);
}
//3.从小根堆中弹出前k个值
int[] ret = new int[k];
for (int i = 0; i < k; i++) {
ret[i] = priorityQueue.poll();
}
return ret;
}
}
在思路二中,建立小根堆的过程时间复杂度为O(n),每弹出一个值就需要向下调整,结合本篇中介绍的“建堆”过程中可知,该过程的时间复杂度为 klogn ,最终整个过程的时间复杂度即为:
O(n + klogn)
**③思路三:**将思路二再做优化,同时也是最适用TOPK问题的通用方法;
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
gth; i++) {
priorityQueue.offer(arr[i]);
}
//3.从小根堆中弹出前k个值
int[] ret = new int[k];
for (int i = 0; i < k; i++) {
ret[i] = priorityQueue.poll();
}
return ret;
}
}
在思路二中,建立小根堆的过程时间复杂度为O(n),每弹出一个值就需要向下调整,结合本篇中介绍的“建堆”过程中可知,该过程的时间复杂度为 klogn ,最终整个过程的时间复杂度即为:
O(n + klogn)
**③思路三:**将思路二再做优化,同时也是最适用TOPK问题的通用方法;
[外链图片转存中...(img-yWdPnz8M-1715560196320)]
[外链图片转存中...(img-ZGXtm1iQ-1715560196321)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618668825)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1430
1430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









