






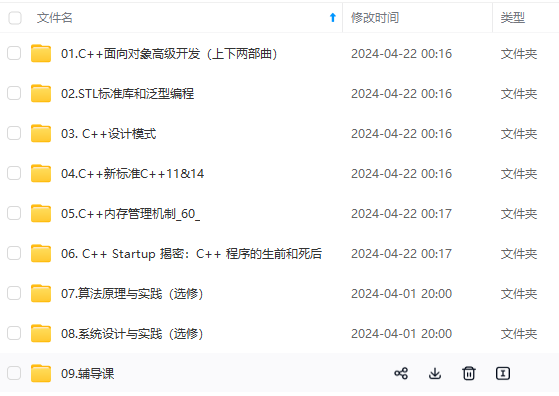
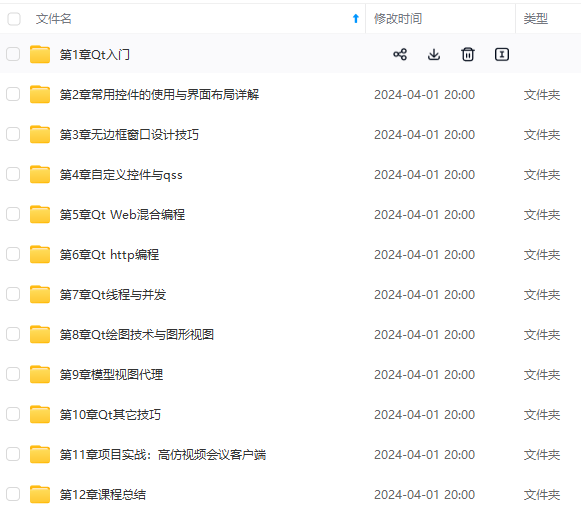
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
O
(
l
o
g
n
)
O(logn)
O(logn) 的空间。
所以我们需要使用自底向上非递归形式的归并排序算法。
基本思路是这样的,总共迭代
l
o
g
n
logn
logn次:
- 第一次,将整个区间分成连续的若干段,每段长度是2:
[
a
0
,
a
1
]
,
[
a
2
,
a
3
]
,
…
[
a
n
−
1
,
a
n
−
1
]
[
a
0
,
a
1
]
,
[a0,a1],[a2,a3],…[an−1,an−1][a0,a1],
[a0,a1],[a2,a3],…[an−1,an−1][a0,a1],然后将每一段内排好序,小数在前,大数在后;
2. 第二次,将整个区间分成连续的若干段,每段长度是4:
[
a
0
,
…
,
a
3
]
,
[
a
4
,
…
,
a
7
]
,
…
[
a
n
−
4
,
…
,
a
n
−
1
]
[
a
0
,
…
,
a
3
]
[a0,…,a3],[a4,…,a7],…[an−4,…,an−1][a0,…,a3]
[a0,…,a3],[a4,…,a7],…[an−4,…,an−1][a0,…,a3],然后将每一段内排好序,这次排序可以利用之前的结果,相当于将左右两个有序的半区间合并,可以通过一次线性扫描来完成;
3. 依此类推,直到每段小区间的长度大于等于
n
n
n 为止;
另外,当
n
n
n 不是2的整次幂时,每次迭代只有最后一个区间会比较特殊,长度会小一些,遍历到指针为空时需要提前结束。

举个例子:
根据图片可知,从底部往上逐渐进行排序,先将长度是1的链表进行两两排序合并,再形成新的链表head,再在新的链表的基础上将长度是2的链表进行两两排序合并,再形成新的链表head … 直到将长度是n / 2的链表进行两两排序合并
step=1: (3->4) -> (1->7) -> (8->9) -> (2->11) -> (5->6)
step=2: (1->3->4->7) -> (2->8->9->11) -> (5->6)
step=4: (1->2->3->4->7->8->9->11) ->5->6
step=8: (1->2->3->4->5->6->7->8->9->11)
具体操作,当将长度是i的链表两两排序合并时,新建一个虚拟头结点dummy,[j,j + i - 1]和[j + i, j + 2 * i - 1]两个链表进行合并,在当前组中,p指向的是当前合并的左边的链表,q指向的是当前合并的右边的链表,o指向的是下一组的开始位置,将左链表和右链表进行合并,加入到dummy的链表中,操作完所有组后,返回dummy.next链表给i * 2的长度处理
注意的是:需要通过l和r记录当前组左链表和右链表使用了多少个元素,用的个数不能超过i,即使长度不是 2n 也可以同样的操作
时间复杂度分析: 整个链表总共遍历
l
o
g
n
logn
logn 次,每次遍历的复杂度是
O
(
n
)
O(n)
O(n),所以总时间复杂度是
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn)。
空间复杂度分析: 整个算法没有递归,迭代时只会使用常数个额外变量,所以额外空间复杂度是
O
(
1
)
O(1)
O(1).
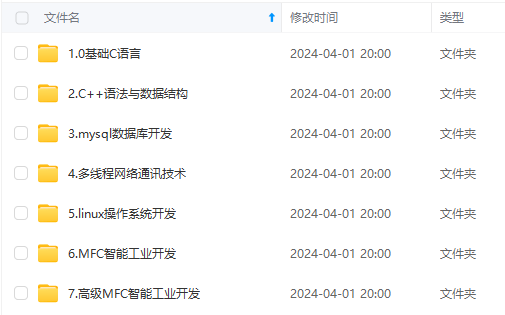
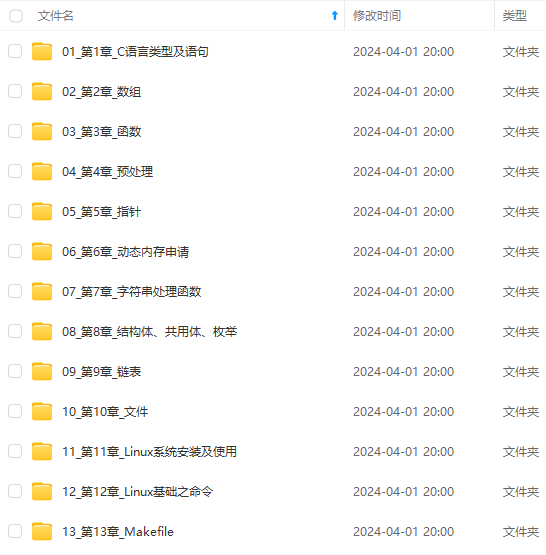
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
)
O(nlogn)
O(nlogn)。
空间复杂度分析: 整个算法没有递归,迭代时只会使用常数个额外变量,所以额外空间复杂度是
O
(
1
)
O(1)
O(1).
[外链图片转存中…(img-NcBbpJqM-1715816286133)]
[外链图片转存中…(img-IsFgBmOR-1715816286133)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 5236
5236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









