









既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
此时又出现了新的问题:如果right找不到比key小的,就会出现越界的风险,所以在进行`a[right]>=a[keyi]`条件判断的前面还要加上一个条件,下面是代码的进一步优化:(最终版)
int PartSort(int *a,int left,int right)//快速排序单趟排序
{
int keyi = left;
while (left < right)
{
//右边找小
while (left<right && a[right] >= a[keyi])
{
right–;
}
//左边找大
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);
return left;//返回相遇的位置
}
此时进行接下来的分析及操作:
**此时keyi所在的数据就不需要再进行移动了,已经放在了正确的位置。如果keyi的左边有序,右边再有序,那么整体就是有序的**。此时就需要运用分治的思想,此时分别对右边进行单趟排序的递归,直到所有数据都有序,然后重复上面的数据,直到只有一个数据时为止,此时退出递归,整体就是有序的。
**快速排序主函数代码:**
void QuickSort(int* a,int begin,int end)
{
//当出现错位或者二者相等的时候就停止
if (begin >= end)
return;
int keyi = PartSort(a, begin, end);
//分割出了两个子区间:[begin,keyi-1]keyi[keyi+1,end]
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi+1, end);
}
>
> **问:return的条件判断为什么是`begin >= end`?而不能只是一个==呢?**
>
>
> **答:比如当进入这个函数时,begin = 0,end = 2,keyi = 1,此时就会出现两个区间,就是[0,0]和[2,1],如果只是相等的话,判断前面的条件自然没有什么问题,但是判断后面的不存在的区间时就不行了。**
>
>
>
2. 挖坑法
动图展示:
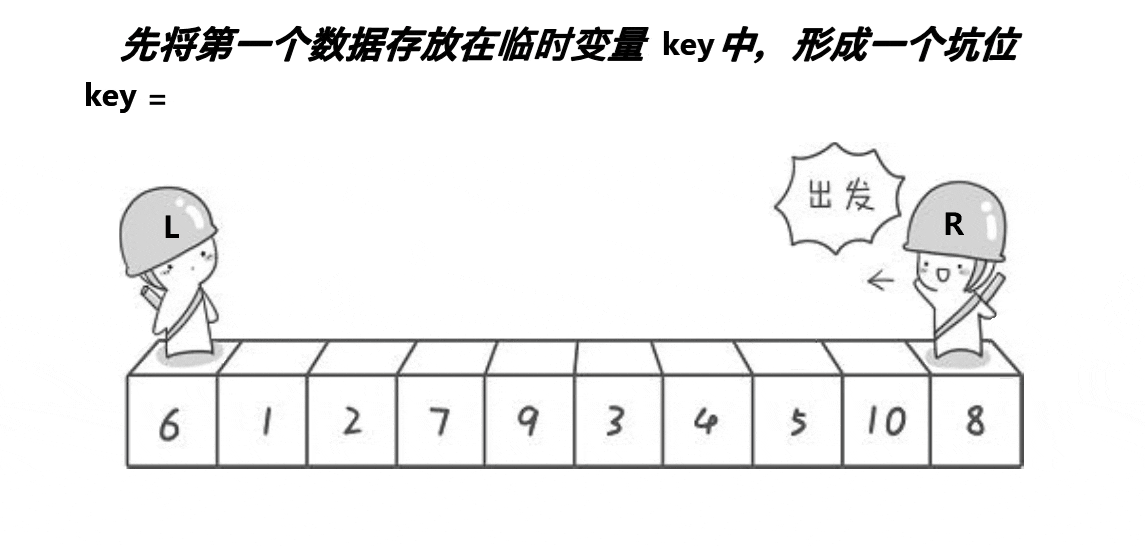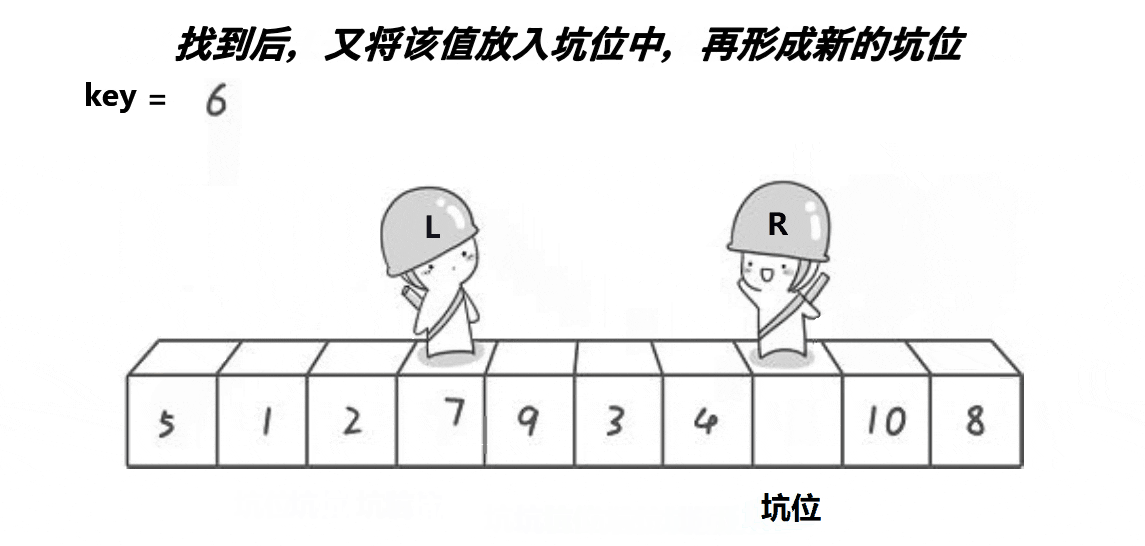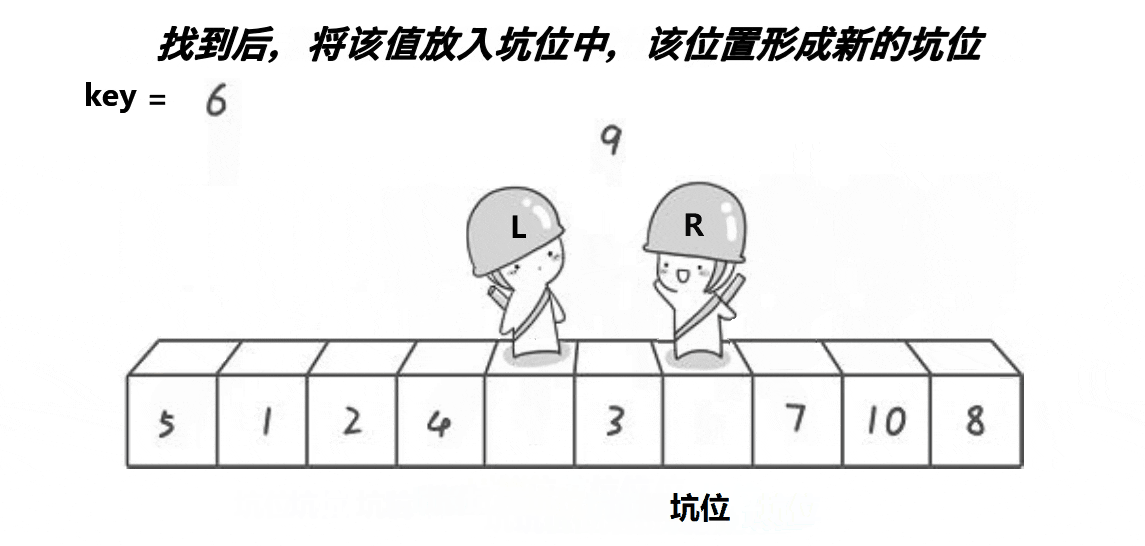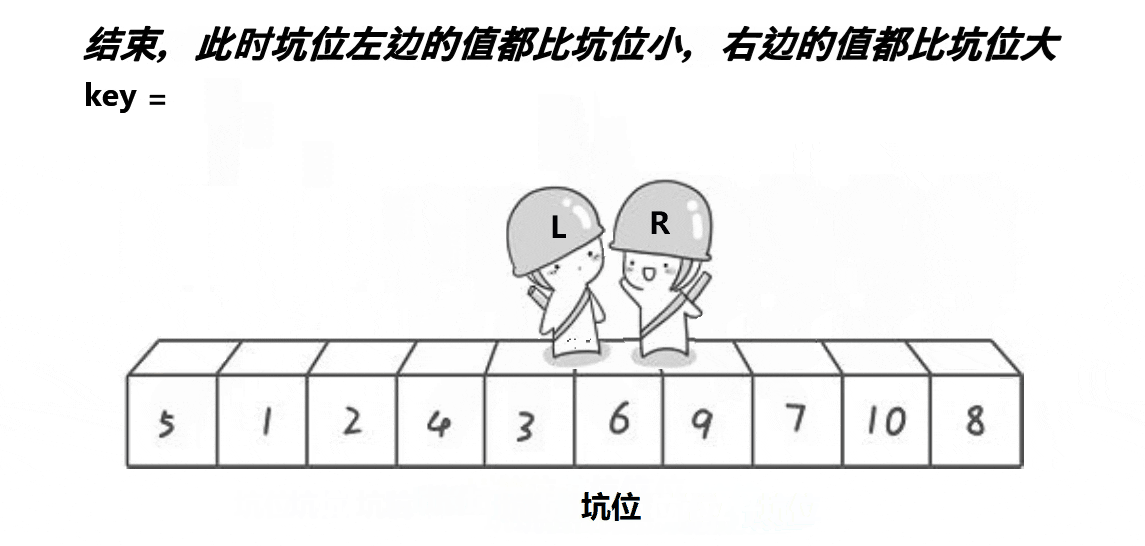
代码:
int PartSort2(int* a, int left, int right)
{
int key = a[left];
int hole = left;//记录坑的下标
while (left < right)
{
while (left<right&& a[right] >= key)//从右边找小于key的
{
right–;
}
a[hole] = a[right];//把找到的值放到坑位上去
hole = right;//形成新的坑
while (left<right&&a[left] <= key)//从左边找大于key的
{
left++;
}
a[hole] = a[left];//把找到的值放到坑位上去
hole = left;//形成新的坑
}
a[left] = key;//将key放到相遇的位置上去(相遇的位置一定是坑)
return left;//返回相遇位置的下标
}
>
> **问:挖坑法和hoare有什么区别吗?两个的效率是否一样?挖坑法是否就一定比hoare方法好呢?**
>
>
> **答:挖坑法和hoare方法没有本质的区别,两个的时间复杂度也都是一样的,不存在谁优谁劣的问题,两者的好坏并没有严格的限定,挖坑法相对hoare方法来说,更容易理解,hoare方法过于抽象,有些不太好理解。需要注意的是:在使用两种方法经过第一轮排序后形成的结果并不一定是相同的,或者说二者大多数情况下都是不相同的,只有少数情况下才是相同的。**
>
>
>
3. 前后指针法
动图展示:
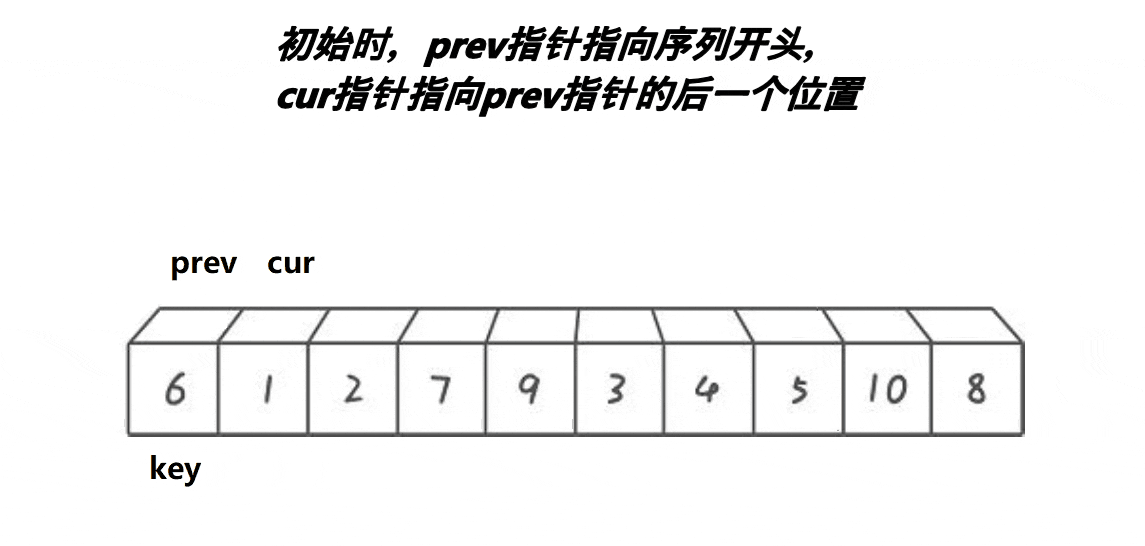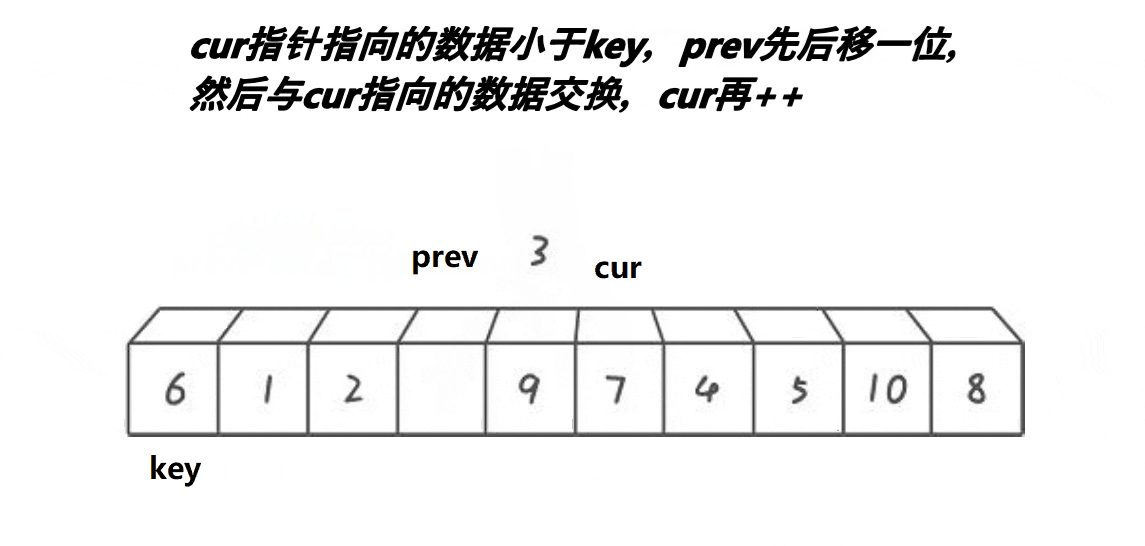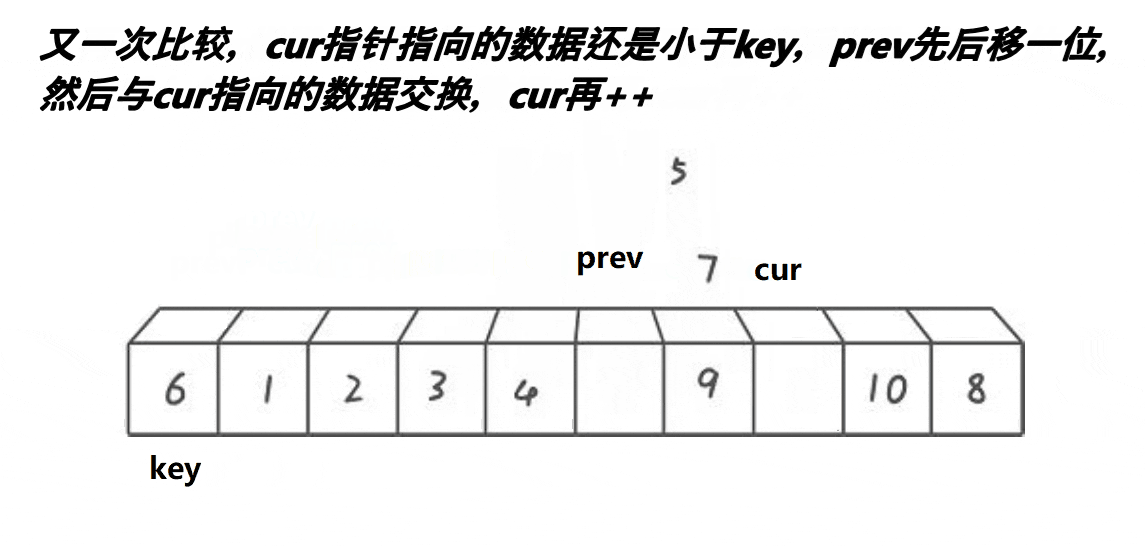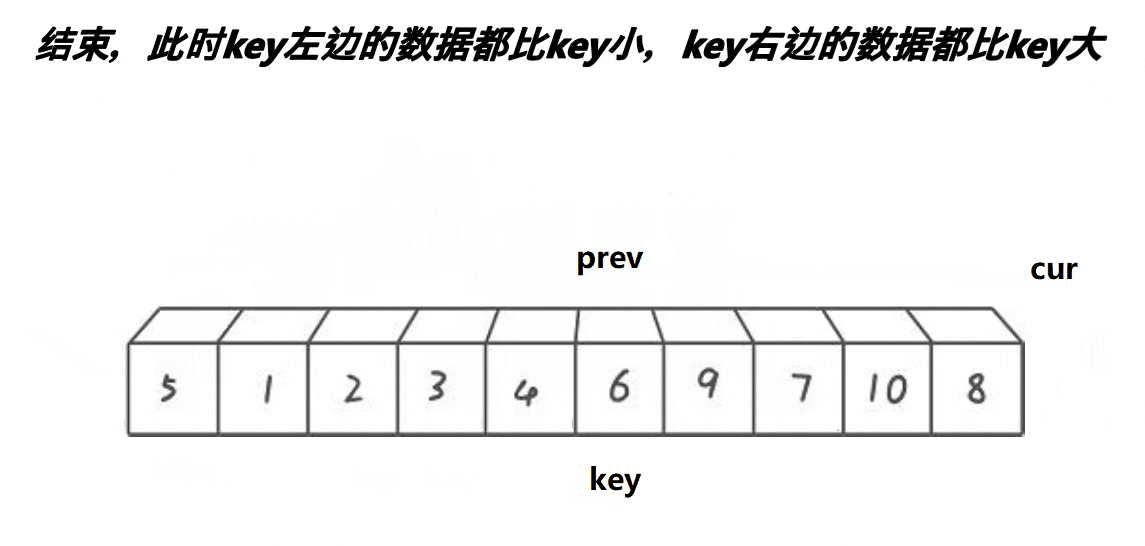
代码:
//left作keyi
int PartSort3(int* a, int left, int right)
{
int keyi = left;
int prev = left;
int cur = left + 1;
while (cur <= right)
{
//下面这一行代码的作用:当cur遇到比a[keyi]小的值后++prev,并且防止自己跟自己进行交换
if (a[cur] < a[keyi] && a[++prev]!= a[cur])
Swap(&a[cur], &a[prev]);
cur++;
}
Swap(&a[prev], &a[keyi]);//将a[prev]和a[keyi]进行交换
return prev;
}
//right作keyi
int PartSort3(int* a, int left, int right)
{
int keyi = right;
int cur = left;
int prev = left - 1;
while (cur<right)
{
if (a[cur] < a[keyi] && a[++prev] != a[cur])
{
Swap(&a[cur], &a[prev]);
}
cur++;
}
Swap(&a[++prev], &a[keyi]);
return prev;
}
>
> **prev和cur的关系:**
>
>
> **1、cur还没遇到比key大的值时,prev紧跟着cur,一前一后。**
>
>
> **2、cur遇到比key大的值时,prev和cur之间间隔着一段比key大的值的区间。**
>
>
>
##### 2.3.2.2 时间复杂度
快速排序的时间复杂度:
最好情况:每次选的都是中位数O(N\*log2N)
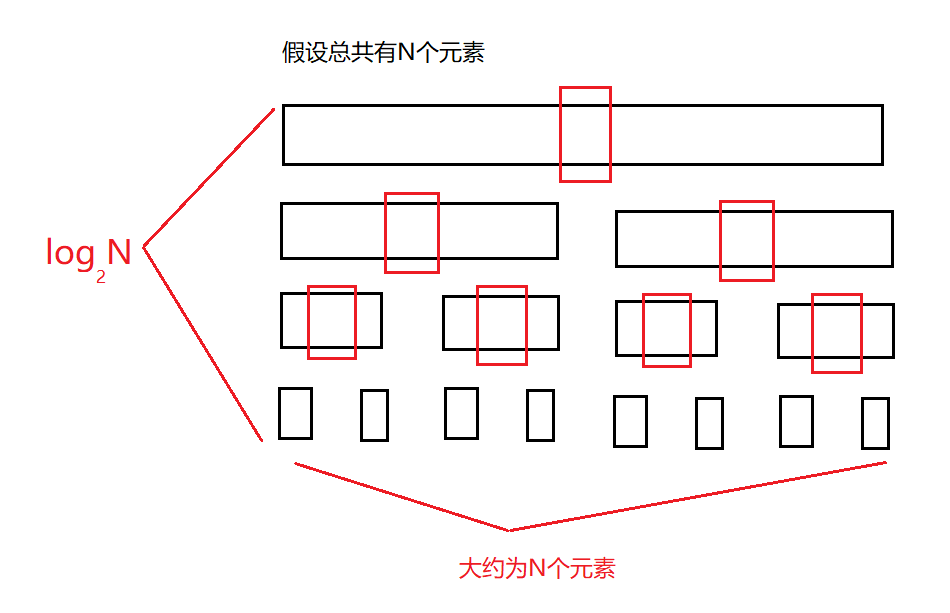
最坏情况:每次选的key是最小的或最大的O(N2)
##### 2.3.2.3 快速排序的优化
**1.随机选key**
**2.三数选中**
int GetMidIndex(int*a,int left,int right)
{
int mid = left + (right- left) / 2;
if (a[left] < a[mid])// left mid
{
if (a[mid] < a[right])//left mid right
{
return mid;
}
else if (a[left] > a[right])//right left mid
{
return left;
}
else//left right mid
{
return right;
}
}
else//mid left
{
if (a[right] > a[left])//mid left right
{
return left;
}
else if (a[mid] < a[right])//mid right left
{
return right;
}
else//right mid left
{
return mid;
}
}
}
//left作keyi
int PartSort3(int* a, int left, int right)
{
int midi = GetMidIndex(a, left, right);
Swap(&a[midi], &a[left]);
int keyi = left;
int prev = left;
int cur = left + 1;
while (cur <= right)
{
//下面这一行代码的作用:当cur遇到比a[keyi]小的值后++prev,并且防止自己跟自己进行交换
if (a[cur] < a[keyi] && a[++prev]!= a[cur])
Swap(&a[cur], &a[prev]);
cur++;
}
Swap(&a[prev], &a[keyi]);//将a[prev]和a[keyi]进行交换
return prev;
}
注意:三数取中法依然无法完全解决针对某种特殊情况序列复杂度变为O(n2)的情况。
3.小区间优化
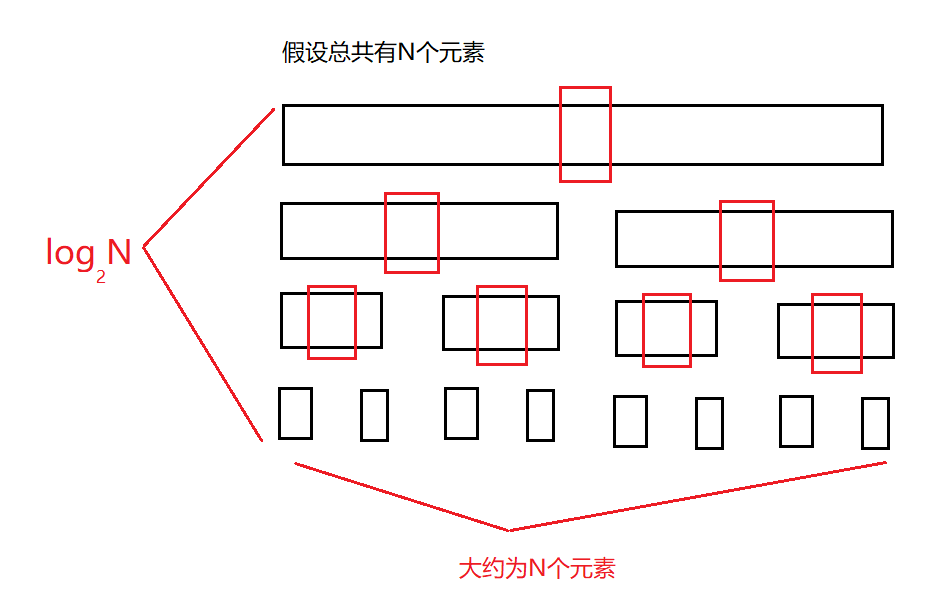
**快排递归调用就是展开简化图就是一个二叉树,我们从上图中可以看到,快速排序的主要花销在数据比较少的时候,就是begin和end之间的数比较少或者begin和end相等的时候,这个时候的递归次数相当多,我们可以在数字比较少的时候去调用其它的排序函数,以此来达到优化开快排的目的。**
简而言之:区间很小时,不再使用递归划分的思路让它有序,而是直接使用插入排序对小区间排序,减少递归调用。
代码:
void QuickSort(int* a,int begin,int end)
{
//当出现错位或者二者相等的时候就停止
if (begin >= end)
return;
//小区间直接使用插入排序控制有序
if (end - begin <= 10)
{
InsertSort(a + begin, end - begin + 1);
}
int keyi = PartSort3(a, begin, end);
//分割出了两个子区间:[begin,keyi-1]keyi[keyi+1,end]
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi+1, end);
}
##### 2.3.2.3 快速排序非递归
两种思路进行实现:
###### 2.3.2.3.1 栈模拟递归实现
思路:
**将需要使用到的下标放到栈上临时存储(为什么只存下标?因为PartSort()函数只需要用到函数名和下标),然后使用栈的性质,每当拿出一对下标时,将得到的新下标依次压入栈中,这样,始终都是先对右边的下标进行排序,模拟了递归的性质。**

代码实现:
//快速排序的非递归形式1:通过栈来实现
void QuickSort3(int* a, int begin, int end)
{
ST st;
StackInit(&st);
StackPush(&st, begin);
StackPush(&st, end);
while (!StackEmpty(&st))
{
int end = StackTop(&st);
StackPop(&st);
int begin = StackTop(&st);
StackPop(&st);
int keyi = PartSort(a, begin, end);
//[begin , keyi - 1] [keyi+1,end]
if (begin < keyi - 1)
{
StackPush(&st, begin);
StackPush(&st, keyi - 1);
}
if (keyi + 1 < end)
{
StackPush(&st, keyi + 1);
StackPush(&st, end);
}
}
StackDestory(&st);
}
###### 2.2.2.3.2 队列模拟二叉树遍历实现
思路:
将需要使用到的下标放到队列中来进行临时存储,每次从队列中拿出一对下标时,又将新形成的下标放入到队列中去,直到队列为空时停止。
图示:

代码:
//快速排序的非递归形式1:通过队列来实现
void QuickSort3(int* a, int begin, int end)
{
Queue q;
QueueInit(&q);
QueuePush(&q, begin);
QueuePush(&q, end);
while (!QueueEmpty(&q))
{
int left = QueueFront(&q);
QueuePop(&q);
int right = QueueFront(&q);
QueuePop(&q);
int keyi = PartSort(a, left, end);//[left,keyi-1][keyi+1,right]
if (left < keyi - 1)
{
QueuePush(&q, left);
QueuePush(&q, keyi - 1);
}
if (keyi + 1 < right)
{
QueuePush(&q, keyi + 1);
QueuePush(&q, right);
}
}
QueueDestory(&q);
}
### 2.4 归并排序
#### 2.4.1 基本思想
**归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有 序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。 归并排序**
核心步骤:
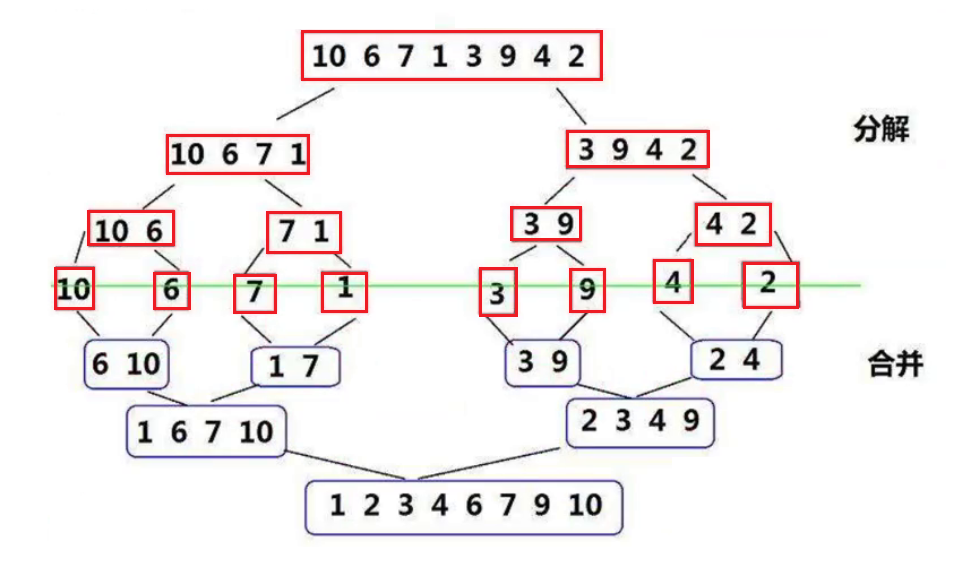
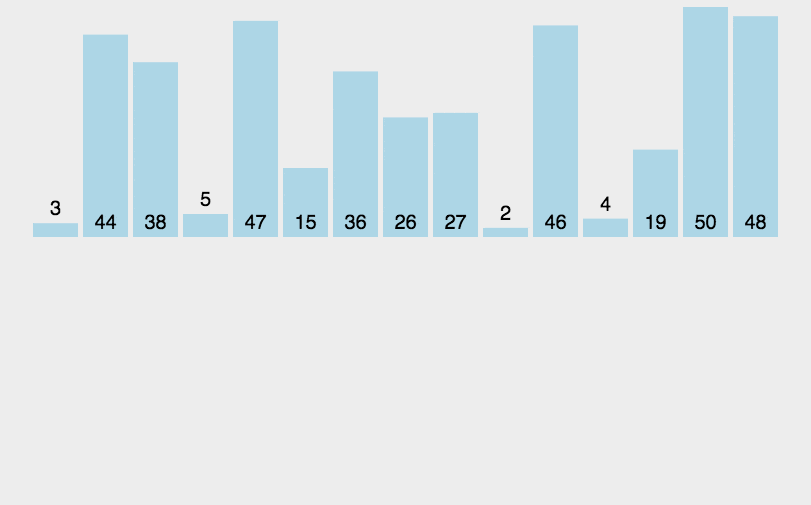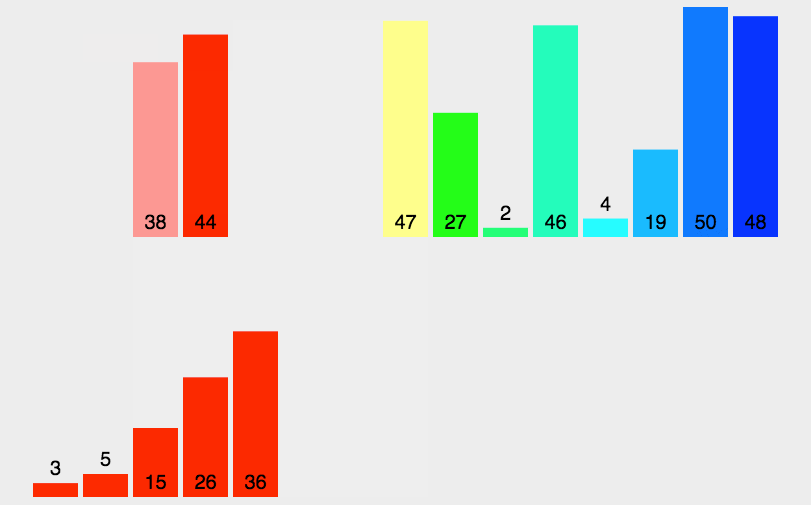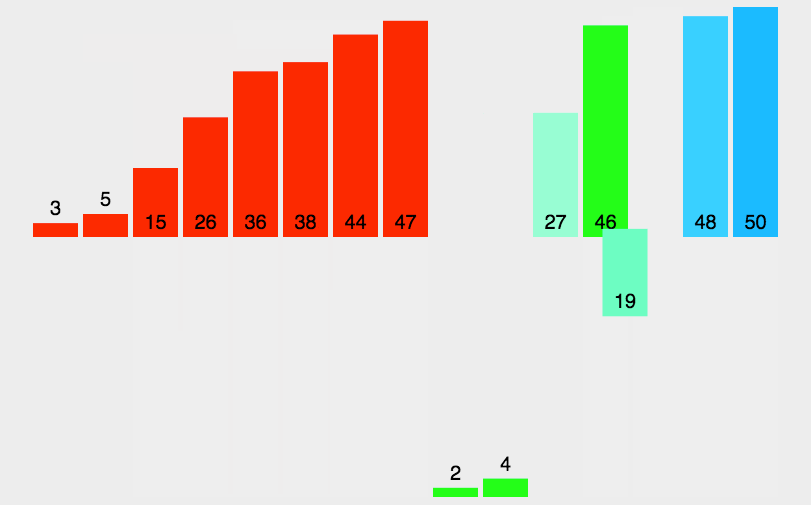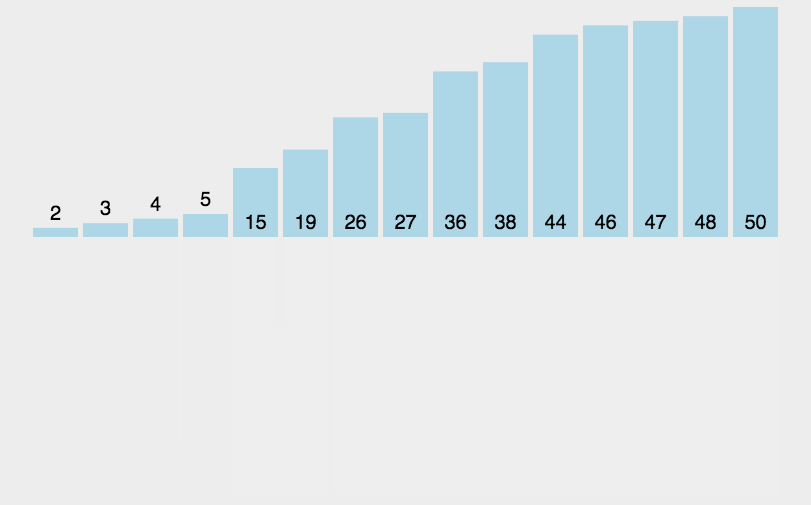
#### 2.4.2 归并排序的实现
##### 2.4.2.1 方法一:递归版
分解思路:
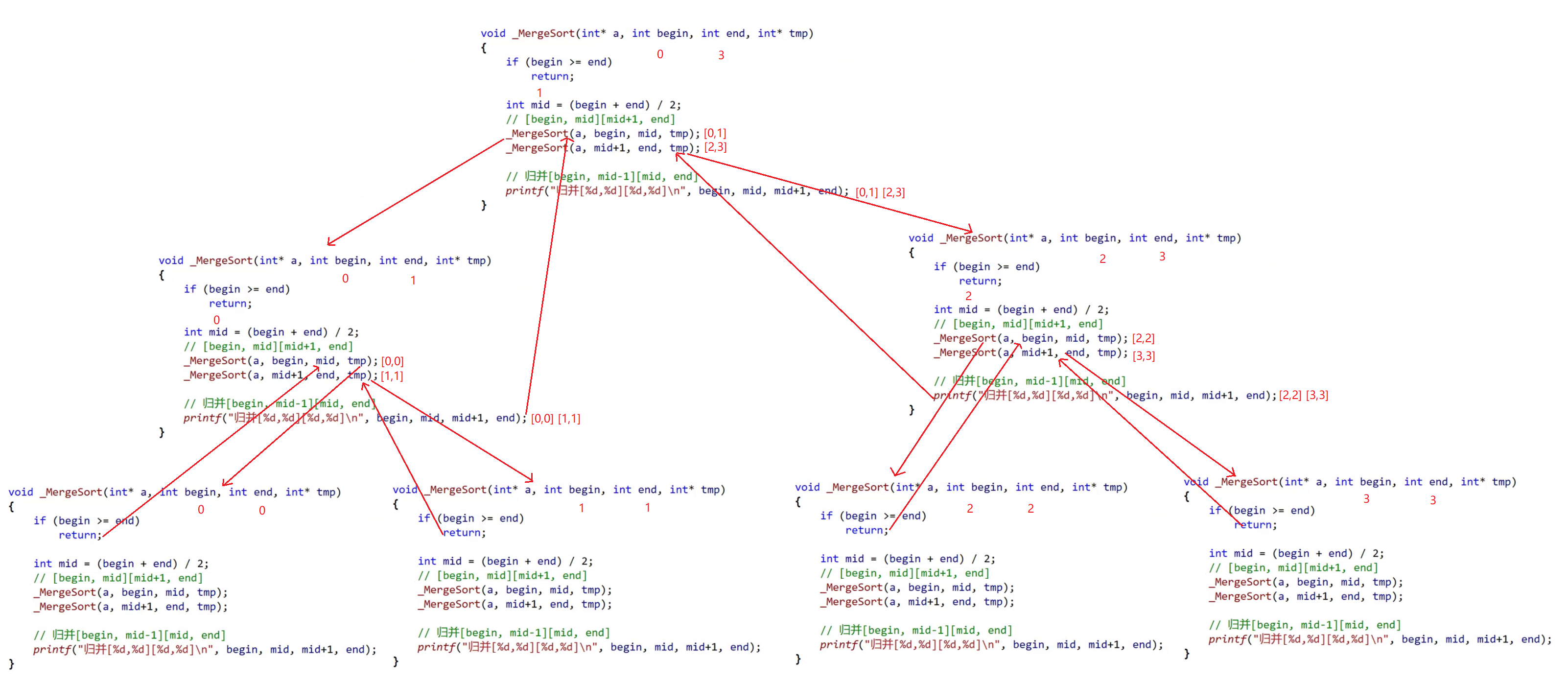
归并思路:
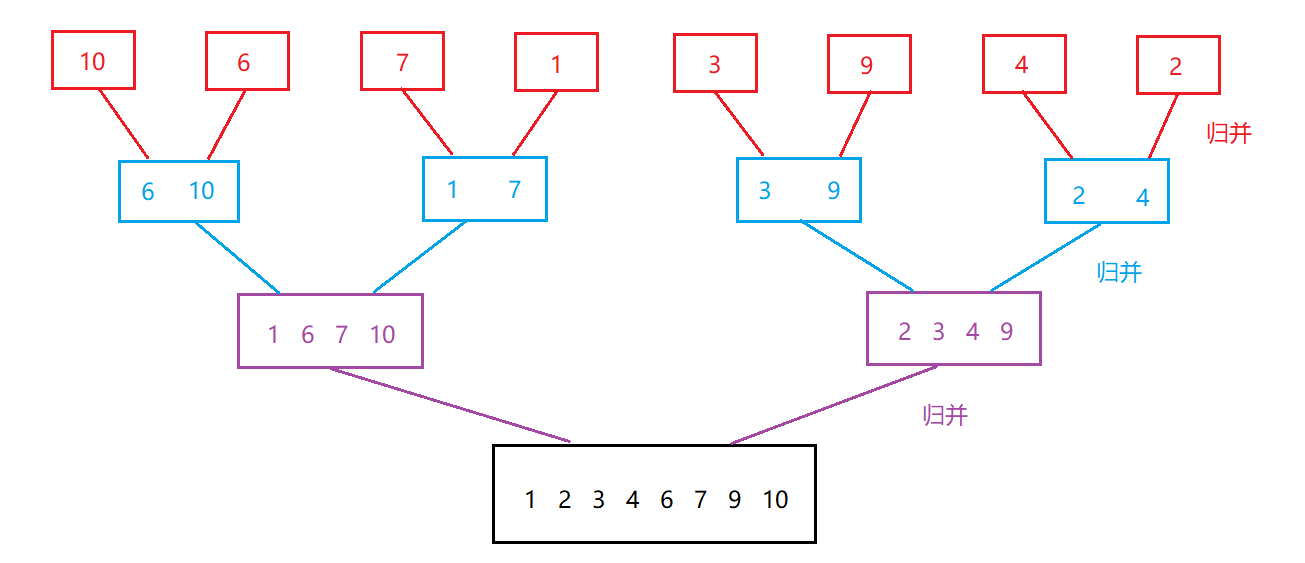
代码:
//归并排序
void _MergeSort(int* a, int begin, int end,inttmp)//辅助函数
{
if (begin >= end)
{
return;
}
int mid = (begin + end) / 2;
//[begin,mid][mid+1,end]
_MergeSort(a, begin, mid, tmp);
_MergeSort(a, mid + 1, end, tmp);
//此处必须这样划分区间,如果划分为[begin,mid-1][mid,end]时就会出现死循环的现象,比如[1,2]
//归并
int begin1 = begin, end1 = mid;//begin1和end1用来控制第一个区间
int begin2 = mid + 1, end2 = end;//begin2和end2用来控制第二个区间
int index = begin;//下标每次都从begin位置开始
while (begin1 <= end1 && begin2 <= end2)//当两个区间有一个区间到达最后时就停止
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)//如果第一个区间没有结束就从第一个区间继续挪动数据
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)//如果第二个区间没有结束就从第二个区间继续把挪动数据
{
tmp[index++] = a[begin2++];
}
memcpy(a+begin, tmp+begin, (end - begin + 1) * sizeof(int));//运用内存拷贝函数
}
void MergeSort(int a,int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);//开辟临时数组空间
assert(tmp);//防止开辟失败
_MergeSort(a, 0, n - 1,tmp);
free(tmp);
}
##### 2.4.2.2 方法二:非递归版
第一个版本:
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
assert(tmp);
int gap = 1;
while (gap<n)
{
for (int i = 0;i<n;i+=2gap)//为什么在gap前面有一个2,因为是两组数据进行归并
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i+gap, end2 = i + 2 * gap - 1;
int index = i;
//printf(“[%d,%d] [%d,%d]\n”, begin1 , end1 , begin2 , end2);
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
}
memcpy(a, tmp, nsizeof(int));
gap *= 2;
}
free(tmp);
}
上面的代码经过打印,在测试非2的幂次方个数目的数组时程序就会出现问题,例如当我们测试10个数时看一下打印的下标:
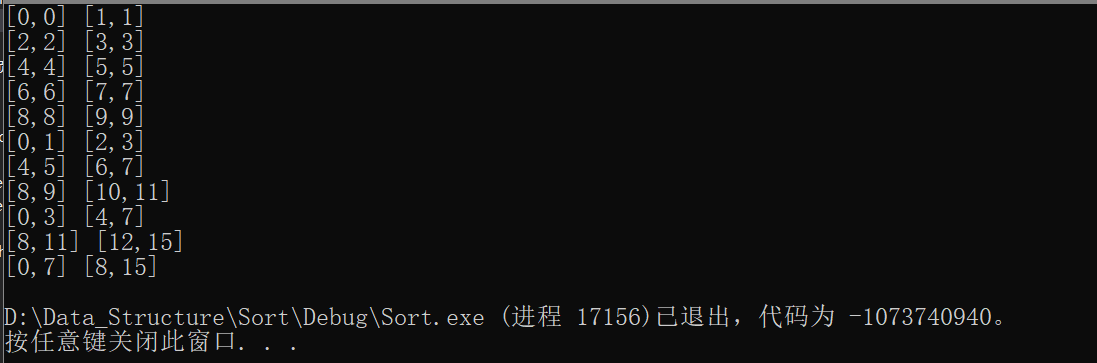
发生了越界(总共有10个数字,下标最大为9,所以程序出现了问题)
下面将进行一次修正,将越界的下标数字强制修改为n-1,修正部分的代码如下所示:
if (end1 >= n)
{
end1 = n - 1;
}
if (begin2 >= n)
{
begin2 = n - 1;
}
if (end2 >= n)
{
end2 = n - 1;
}
修正后打印结果为:
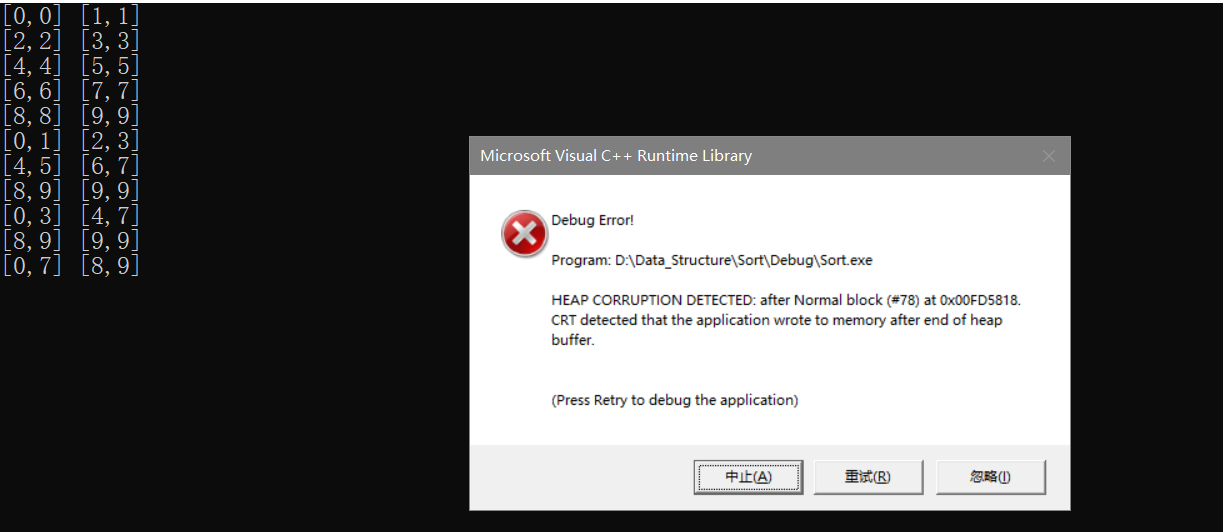
**此时程序依旧不对,为什么?因为index会发生越界,当下标为[8,9]和[9,9]的时候,程序会在`while(begin1 <= end1 && begin2 <= end2)`这个位置进入循环两次,然后此时index会变成10(最开始的index为8),然后后面因为`begin2==end2`会再次进入循环,此时的index就会出现越界访问的现象。**
此处进行分析:如果end1越界,我们是可以修正的,如果end2越界,begin2没有越界,我们也是可以修正end2的,如果begin2越界了,那么第二个区间就会直接不存在,此时需要再对上面的代码进行修改。
if (end1 >= n)
{
end1 = n - 1;
}
if (begin2 >= n)
{
begin2 = n;
end2 = n - 1;
}
if (end2 >= n)
{
end2 = n - 1;
}
修改的部分就是:如果begin2越界,直接让[begin2,end2]这个区间不存在即可。
完整代码如下所示:
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
assert(tmp);
int gap = 1;
while (gap<n)
{
for (int i = 0;i<n;i+=2*gap)//为什么在gap前面有一个2,因为是两组数据进行归并
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i+gap, end2 = i + 2 * gap - 1;
//end1越界
if (end1 >= n)
{
end1 = n - 1;
}
//begin2越界
if (begin2 >= n)
{
begin2 = n;
end2 = n - 1;
}
//只有end2越界
if (end2 >= n)
{
end2 = n - 1;
}
int index = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
}
memcpy(a, tmp, n*sizeof(int));
gap *= 2;
}
free(tmp);
}
#### 2.4.3 归并排序的外排序
##### 2.4.3.1 归并外排序的思想
**思想:当所要排序的的数据量太多或者文件太大,无法直接在内存里排序,而需要依赖外部设备时,就会使用到外部排序。**
>
> 算法描述:
>
>
> 1. 将所要排序的文件平均分割成若干个可以加载到内存中的小文件
> 2. 将每个小文件中的数据加载到内存中,使用快速排序法或者其它排序方法将每个小文件中的数据排成有序
> 3. 将内存中有序的数据重新写回到文件中,此时达到了文件中归并的先决条件
>
>
>
4. 归并思路如下图所示:
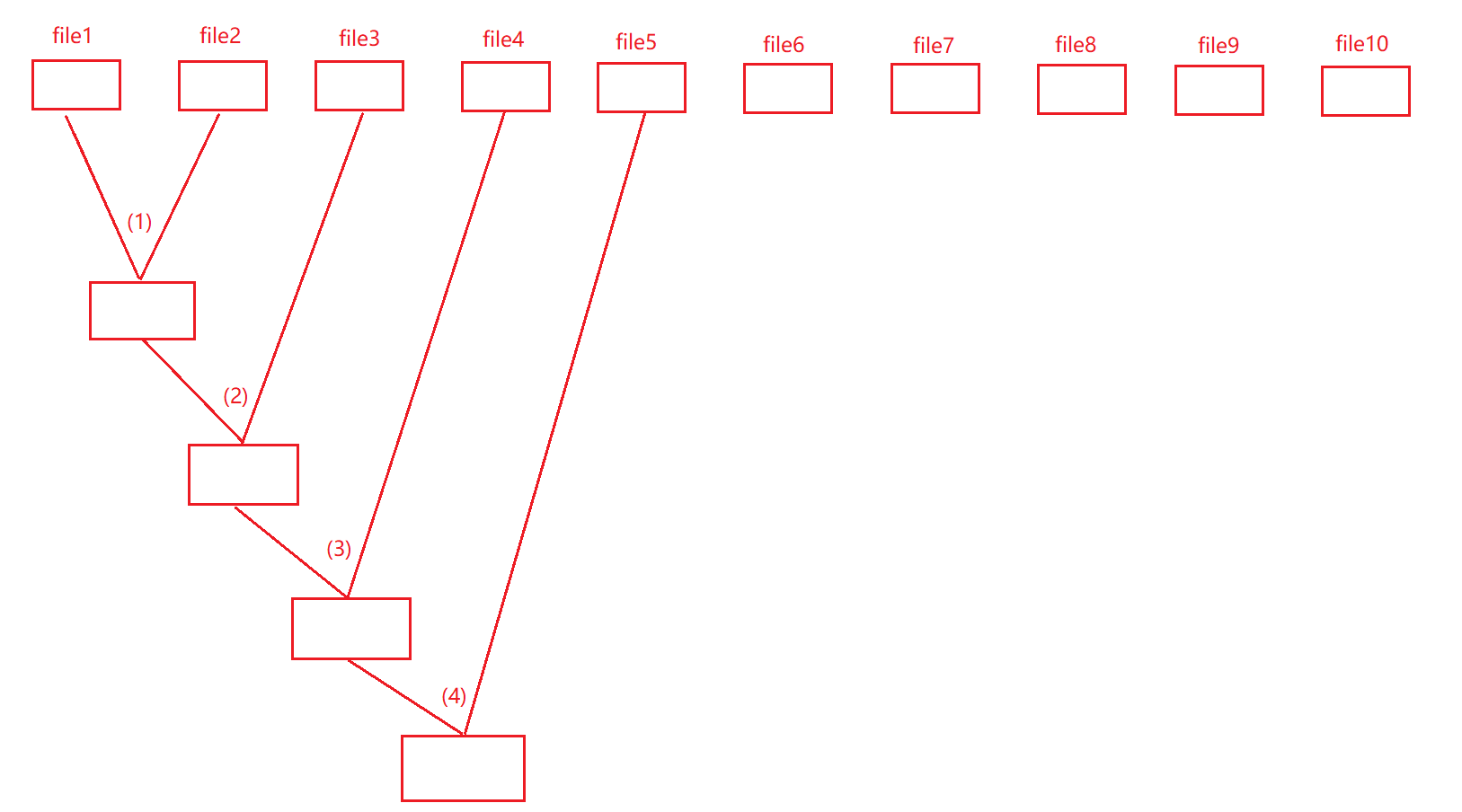
上图中的(1)和(2)和(3)和(4)分别是第一次归并、第二次归并、第三次归并和第四次归并,后面的没有再列举出来。
注意:实际中的归并思路有很多种,并不是只有这一种,此处把这个思路列举出来只是为了后面的应用举例。
##### 2.4.3.2 归并外排序的实现
归并排序外排序函数代码:
//归并排序的文件排序
//file1和file2是要被归并的文件,mfile是存放归并后的数据的文件
void _MergeFile(const charfile1, const charfile2,const char* mfile)
{
//将三个文件打开
FILE* fout1 = fopen(file1, “r”);
if (fout1 == NULL)
{
printf(“打开文件失败!\n”);
exit(-1);
}
FILE* fout2 = fopen(file2, "r");
if (fout2 == NULL)
{
printf("打开文件失败!\n");
exit(-1);
}
FILE* fin = fopen(mfile, "w");
if (fin == NULL)
{
printf("打开文件失败!\n");
exit(-1);
}
//开始归并
int num1, num2;//存储file1和file2中读取的数据
//先从文件中读取出一个数据,ret1是为了判断是否读取结束,如果等于EOF就说明已经读取结束
int ret1 = fscanf(fout1, "%d\n", &num1);
int ret2 = fscanf(fout2, "%d\n", &num2);
//存放新的数据
while (ret1!= EOF && ret2 != EOF)//当有一个文件读取结束时读取就结束
{
//此处是因为要排升序,所以将小的数据读入新的文件中
if (num1 < num2)
{
fprintf(fin, "%d\n", num1);//将小的数据num1读入新的文件中
ret1 = fscanf(fout1, "%d\n", &num1);//重新读入新的数据
}
else
{
fprintf(fin, "%d\n", num2);//同上
ret2 = fscanf(fout2, "%d\n", &num2);
}
}
//如果存在未读取完的文件,将剩余的数据读取到新的文件mfile中
while (ret1!=EOF)
{
fprintf(fin, "%d\n", num1);
ret1 = fscanf(fout1, "%d\n", &num1);
}
while (ret2!=EOF)
{
fprintf(fin, "%d\n", num2);
ret2 = fscanf(fout1, "%d\n", &num2);
}
fclose(fout1);
fclose(fout2);
fclose(fin);
}
##### 2.4.3.3 归并外排序使用举例
这个例子中有文件file,此文件中总共是有100个数据,我们是要将它分成10组,每组数据有10个数据,每个数据放在一个文件中,文件名从`1到10`,然后存放新文件的名字最开始是`12`,表示这个文件要存放文件1和2归并后的数据,同理,后面的123就是存放文件12和3归并后的数据。
代码实现:
void MergeSortFile(const char* file)//此处的file是要被排序的文件
{
FILE* fout = fopen(file, “r”);
if (fout == NULL)
{
printf(“打开文件失败!\n”);
exit(-1);
}
//分割成一段一段数据,内存排序后写到小文件
int n = 10;
int a[10];
int i = 0;
int num = 0;
char subfile[20] = { 0 };
int filei = 1;
while (fscanf(fout, “%d\n”, &num) != EOF)
{
if (i < n-1)//前9个数据进去
{
a[i++] = num;
}
else
{
a[i] = num;//这是第10个数据
QuickSort(a, 0, n - 1);
sprintf(subfile, “%d”, filei++);
FILE* fin = fopen(subfile, “w”);
if (fin == NULL)
{
printf(“打开文件失败\n”);
exit(-1);
}
for (int i = 0; i < n; i++)
{
fprintf(fin, “%d\n”, a[i]);
}
fclose(fin);
i = 0;
memset(a, 0, sizeof(int)*n);
}
}
//利用互相归并到文件,实现整体有序
//····
char mfile[100] = “12”;
char file1[100] = “1”;
char file2[100] = “2”;
for (int i = 2; i <= n; i++)
{
//读取file1和file2,进行归并出mfile
_MergeFile(file1, file2, mfile);//将file1和file2进行归并到mfile中
strcpy(file1, mfile);//此处将mfile的名字复制给file1
sprintf(file2, “%d”, i+1);
sprintf(mfile, “%s%d”, mfile,i + 1);
}
fclose(fout);
}
#### 2.4.4 归并排序的特性总结
1. 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
2. 时间复杂度:O(N\*logN)
如何理解归并排序的时间复杂度?
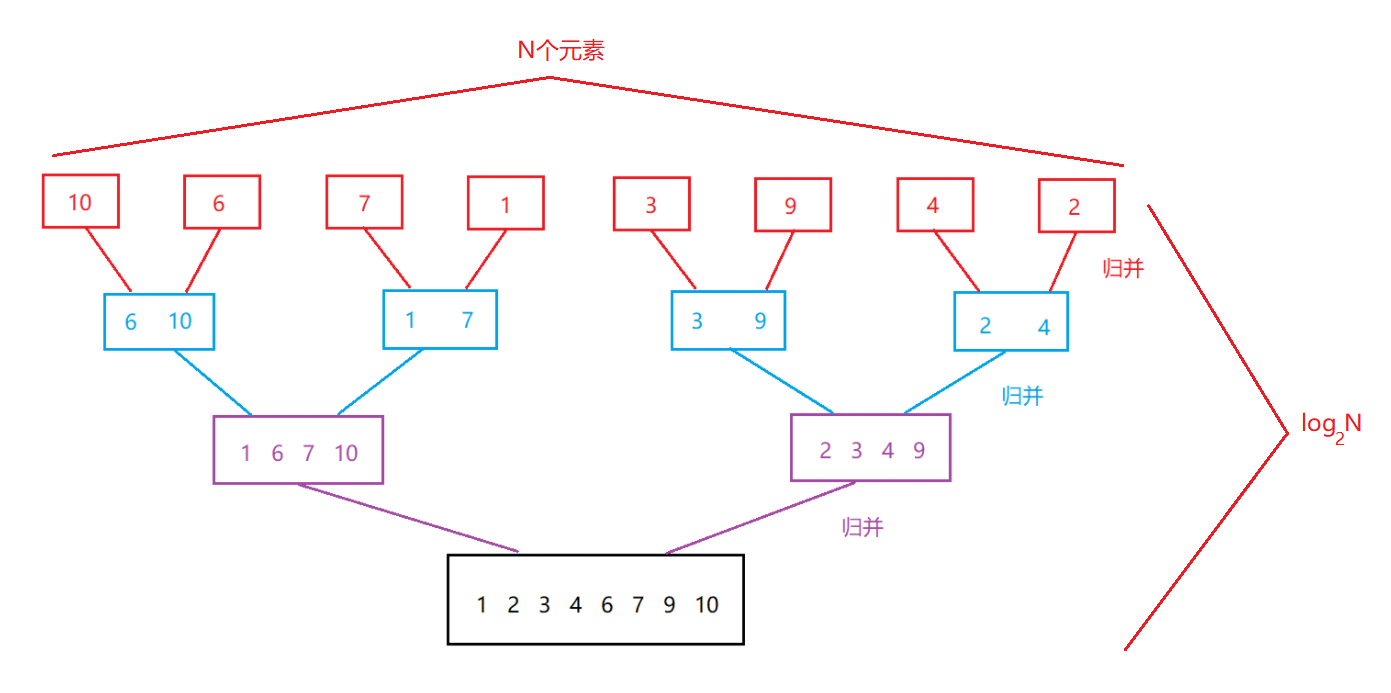
3. 空间复杂度:O(N)
注意:实际上应该是O(N + log2N)(N是开辟的数组的空间,log2N是开辟栈帧的层数(递归版本,非递归就没有),log2N太小,可以看成是常数,几乎忽略不计,所以就是O(N))
4. 稳定性:稳定
### 2.5 七大排序性能测试比较
#### 2.5.1 测试比较代码
代码:
// 测试排序的性能对比
void TestOP()
{
srand((unsigned)time(0));
const int N = 100000;
int* a1 = (int*)malloc(sizeof(int) * N);
int* a2 = (int*)malloc(sizeof(int) * N);
int* a3 = (int*)malloc(sizeof(int) * N);
int* a4 = (int*)malloc(sizeof(int) * N);
int* a5 = (int*)malloc(sizeof(int) * N);
int* a6 = (int*)malloc(sizeof(int) * N);
int* a7 = (int*)malloc(sizeof(int) * N);
assert(a1);
assert(a2);
assert(a3);
assert(a4);
assert(a5);
assert(a6);
assert(a7);
for (int i = 0; i<N; i++)
{
a1[i] = rand();
a1[i] = N-i;
a2[i] = a1[i];
a3[i] = a1[i];
a4[i] = a1[i];
a5[i] = a1[i];
a6[i] = a1[i];
a7[i] = a1[i];
}
int begin1 = clock();
InsertSort(a1, N);
int end1 = clock();
int begin2 = clock();
ShellSort(a2, N);
int end2 = clock();
int begin3 = clock();
SelectSort(a3, N);
int end3 = clock();
int begin4 = clock();
HeapSort(a4, N);
int end4 = clock();
int begin5 = clock();
QuickSort(a5, 0, N - 1);
int end5 = clock();
int begin6 = clock();
MergeSort(a6, N);
int end6 = clock();
int begin7 = clock();
BubbleSort(a7, N);
int end7 = clock();
printf("InsertSort:%d\n", end1 - begin1);
printf("ShellSort:%d\n", end2 - begin2);
printf("SelectSort:%d\n", end3 - begin3);
printf("HeapSort:%d\n", end4 - begin4);
printf("QuickSort:%d\n", end5 - begin5);
printf("MergeSort:%d\n", end6 - begin6);
printf("BubbleSort:%d\n", end7 - begin7);
free(a1);
free(a2);
free(a3);
free(a4);
free(a5);
free(a6);
free(a7);
}
#### 2.5.2 测试比较结果
注意:在VS2019release版本下进行测试,此时编译器进行了一系列优化。
当N为10000时:
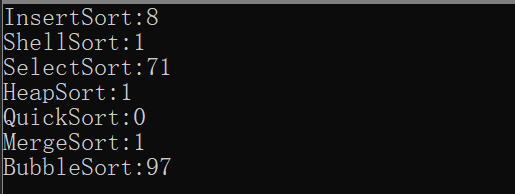
当N为100000时:
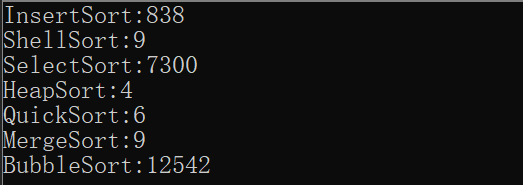
此时继续进行测试快速排序、堆排序、希尔排序、归并排序:
当N为1000000:

当N为10000000:

当N为20000000:

### 2.6 非比较排序
#### 2.6.1 计数排序
##### 2.6.1.1 计数排序的思想
思想:计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。 操作步骤:
1. 统计相同元素出现次数
2. 根据统计的结果将序列回收到原来的序列中
图示: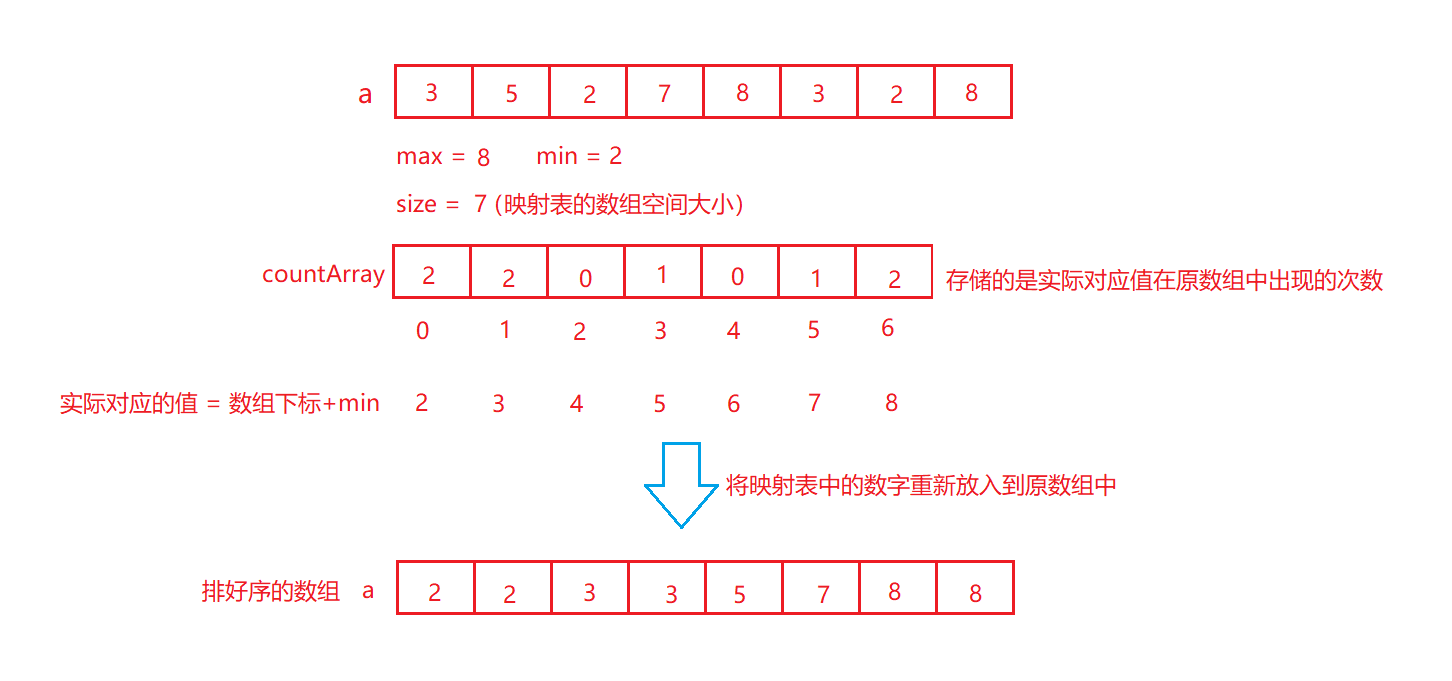
代码:
void CountSort(int* a,int n)
{
//求出最大值和最小值
int max = a[0];
int min = a[0];
for (int i = 1; i < n; i++)
{
if (a[i] > max)
{
max = a[i];
}
if (a[i] < min)
{
min = a[i];
}
}
int size = max - min + 1;//映射表数组的大小
//建立映射数组
int* countArray = (int*)calloc(size,sizeof(int));
assert(countArray);
//计数
for (int i = 0; i < n; i++)
{
countArray[a[i] - min]++;
}
//放回到原来的数组中:排序
int j = 0;//j用来记录原来数组的下标
for (int i = 0; i < size; i++)//i用来记录映射表数组元素的小标
{
while(countArray[i]–)
{
a[j++] = i + min;
}
}
}
##### 2.6.1.2 计数排序的复杂度
>
> 时间复杂度:O(N + range)
>
>
> 空间复杂度:O(range)
>
>
>
**注意:range = max - min +1**
说明:计数排序适用于范围集中的数据
注意:计数排序支持负数但是不支持浮点数、字符串等。
## 3.排序算法复杂度及稳定性分析

稳定性分析:
直接插入排序:稳定。
希尔排序:不稳定。**相同的数可能被分配到不同的gap组中。**
选择排序:不稳定。如下图所示:



**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618668825)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
for (int i = 0; i < n; i++)
{
countArray[a[i] - min]++;
}
//放回到原来的数组中:排序
int j = 0;//j用来记录原来数组的下标
for (int i = 0; i < size; i++)//i用来记录映射表数组元素的小标
{
while(countArray[i]--)
{
a[j++] = i + min;
}
}
}
2.6.1.2 计数排序的复杂度
时间复杂度:O(N + range)
空间复杂度:O(range)
注意:range = max - min +1
说明:计数排序适用于范围集中的数据
注意:计数排序支持负数但是不支持浮点数、字符串等。
3.排序算法复杂度及稳定性分析

稳定性分析:
直接插入排序:稳定。
希尔排序:不稳定。相同的数可能被分配到不同的gap组中。
选择排序:不稳定。如下图所示:

[外链图片转存中…(img-eKlpovwT-1715667941177)]
[外链图片转存中…(img-WCvSnhIM-1715667941177)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









