







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
其中当用户使用社区ClickHouse Client连接ByteHouse企业版查询网关可支持直接通过SQL语句来切换连接的ClickHouse节点
设置网关连接指定节点 示例:
clickhouse client --host <HOST> --user <USER> --password <PASSWORD>
ByteHouse Gateway :) set custom_gw_force_ck_node='<node_ip>'
设置网关在全部ClickHouse节点执行SQL 示例:
clickhouse client --host <HOST>.bytehouse-ce.volces.com --user <USER> --password <PASSWORD>
ByteHouse Gateway :) set custom_gw_force_all_nodes=true
ByteHouse Gateway :) CREATE TABLE default.test(`id` Int64,`info` String COMMENT '1') ENGINE = MergeTree ORDER BY id SETTINGS index_granularity = 8192
CREATE TABLE default.test
(
`id` Int64,
`info` String COMMENT '1'
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 8192
ByteHouse企业版查询网关为了避免执行查询时客户端和服务端连接中断导致无法获取查询结果,实现了异步查询来增强ByteHouse的查询能力。
对于HTTP协议基础的查询,可以通过在Header中添加X-Async-Query即可使用。
示例:
curl --location --request POST 'http://<gateway-address>:8123/?user=<user_name>&password=<password>&query_id=<queryID>' \
--header 'X-Async-Query: 1' \
--data-raw 'show tables FORMAT JSON;'
Query In Progress
HTTP Header: X-Async-Query: running
Query Finished
HTTP Header: X-Spend-Time: 100 (milliseconds)
 为了更好地了解ByteHouse企业版查询网关,首先需要深入探究ClickHouse所提供的查询协议和接口。了解ClickHouse服务端如何处理客户端请求,有助于我们理解如何构建高性能的查询网关。
为了更好地了解ByteHouse企业版查询网关,首先需要深入探究ClickHouse所提供的查询协议和接口。了解ClickHouse服务端如何处理客户端请求,有助于我们理解如何构建高性能的查询网关。
在与ClickHouse服务端通信时,客户端使用的查询协议主要有两种:
**一种基于HTTP协议的查询协议:**HTTP协议通用性较强,在任何平台或编程语言中使用HTTP Client都可以调用ClickHouse的HTTP API进行查询和数据写入。
**另一种基于TCP(Native)协议的查询协议:**TCP协议则具有更少的额外开销,通过在Socket连接上自定义查询协议和优化的数据类型序列化过程,避免了HTTP七层协议带来的不必要的网络IO开销,并且原生支持session。
下面简要介绍这两种协议的不同特点。
/ ClickHouse HTTP协议的特点 /
ClickHouse服务端默认使用8123端口提供HTTP API供客户端进行查询和数据写入操作。在设计和实现上,ClickHouse为HTTP协议查询提供了很大的灵活性。
例如,Query Settings可以放置在HTTP Query Parameters中,查询SQL可以放在GET请求的query参数中或者POST请求body里,甚至分割开放置在两部分中也是允许的。
以下是一些例子
$ echo 'SELECT 1' | curl 'http://localhost:8123/' --data-binary @-
1
$ echo 'SELECT 1' | curl 'http://localhost:8123/?query=' --data-binary @-
1
$ echo '1' | curl 'http://localhost:8123/?query=SELECT' --data-binary @-
1
ClickHouse本身也提供了一个可交互的前端页面,通过浏览器访问,用户可以直接在Web
页面上进行ClickHouse数据库的查询操作。
HTTP协议是无状态的,因此在使用session时需要在参数中添加session_id。通过设置session id,ClickHouse服务端能够确定请求属于哪个session。对于带有session id参数的请求,同时只能有一条SQL语句正在执行,并且不能跨节点设置session。
因此,对于查询网关来说,需要将带有session id参数的HTTP Query请求转发到同一台ClickHouse节点上,以确保session生效。
/ ClickHouse TCP协议的特点**/**
ClickHouse TCP协议是ClickHouse Client和ClickHouse服务端之间默认的连接协议,也是用于ClickHouse节点间通信的协议格式。相较于HTTP协议,它具有更少的额外网络IO开销,因此效率更高。
但是,由于它是基于TCP连接底层的二进制数据流编解码,因此实现上相对复杂,需要考虑各种数据类型如何编解码以更高效地进行传输。
例如,当Client需要发送查询请求时,它会将查询语句和查询参数转换为ClickHouse TCP协议格式的字节流,并将其通过Socket连接发送到ClickHouse服务端。服务端会解析字节流并执行查询操作,最终将结果以相同的协议格式返回给Client。在这个过程中,需要考虑如何对各种数据类型进行编解码,以确保传输效率和数据准确性。
总之,ClickHouse TCP协议虽然实现上相对复杂,但由于具有更高的效率和更少的网络IO开销,因此在高负载环境下使用它可以提高系统的性能和吞吐量。
例:Client与Server基于Socket传输字节流通信
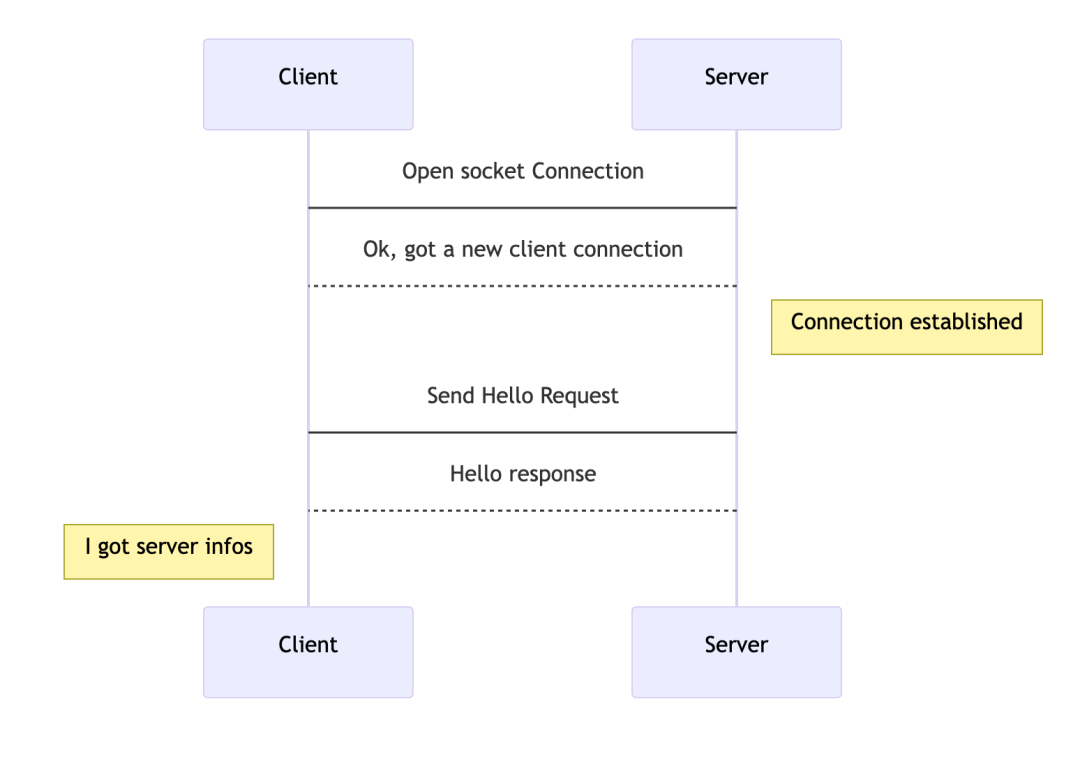
当Client端与ClickHouse Server端建立tcp连接后,Client会发送一个Client Hello数据块给Server。这个数据块包含了Client的版本信息以及用于身份验证的信息等。Server在收到来自Client的Hello数据块后,会返回一个Server Hello数据块给Client,其中包含Server的版本信息以及一些其他的配置信息。这些信息可以用于确定Client和Server之间使用哪个协议版本以及哪些功能。
一旦Client和Server之间成功建立了连接并且进行了协议交换,Client就可以开始发送查询请求到Server了。这些查询请求可以包括SELECT、INSERT、ALTER等语句,同时也可以包含一些参数和设置来控制查询的行为。Server会解析这些请求并且返回结果给Client。在整个过程中,Client和Server之间通过tcp连接来传输数据。
例:TCP协议 Client Hello数据块格式
| 字段 | 类型 | 值 | 描述 |
| client_name | String | “Go Client” | 客户端名字 |
| version_major | UVarInt | 1 | 客户端major版本 |
| version_minor | UVarInt | 10 | 客户端minor版本 |
| protocol_version | UVarInt | 54451 | TCP协议版本 |
| database | String | “default” | database |
| username | String | “default” | 账户名 |
| password | String | “secret” | 密码 |
许多语言ClickHouse Driver通过支持TCP Native协议提高读写性能,例如:
● 社区 ClickHouse Native JDBC(https://github.com/housepower/ClickHouse-● Native-JDBC)
● clickhouse-go(https://github.com/ClickHouse/clickhouse-go)
● 官方JDBC Driver(https://github.com/ClickHouse/clickhouse-java)
由于ClickHouse TCP协议天然具有session状态,不同于HTTP只能在查询结束才能返回查询结果不同,TCP协议允许ClickHouse服务端将查询进度及时返回给Client。

例:TCP协议 ClickHouse服务端返回给Client的几种不同类型的数据块
| value | name | 描述 |
| 0 | Hello | Server响应Client Hello |
| 1 | Data | 数据块 |
| 2 | Exception | 异常 |
| 3 | Progress | 查询进度 |
/ 探索ClickHouse批量写入 /
由于ClickHouse引擎底层依赖LSM数据结构进行数据存储,因此它具有独特的引擎特点。为了充分利用这些特点,ClickHouse推荐以批量的形式进行数据写入,以提高写入的效率并避免产生大量细碎的part文件。因此,在实现上,HTTP和TCP协议都支持批量插入,但在底层实现上存在一些区别。
HTTP协议支持将批量写入的行数据以各种不同的格式放在HTTP Body中,并可以通过压缩来提高数据写入的效率。
例:
$ echo -ne '10\n11\n12\n' | curl 'http://localhost:8123/?query=INSERT%20INTO%20t%20FORMAT%20TabSeparated' --data-binary @-
而TCP协议支持发送多个数据块来避免重复提供写入效率,从图中可以看出Client发送给Server的data类型数据块可以很大(受max_block_size参数约束,默认值为65505)
例:TCP协议发起batch insert过程
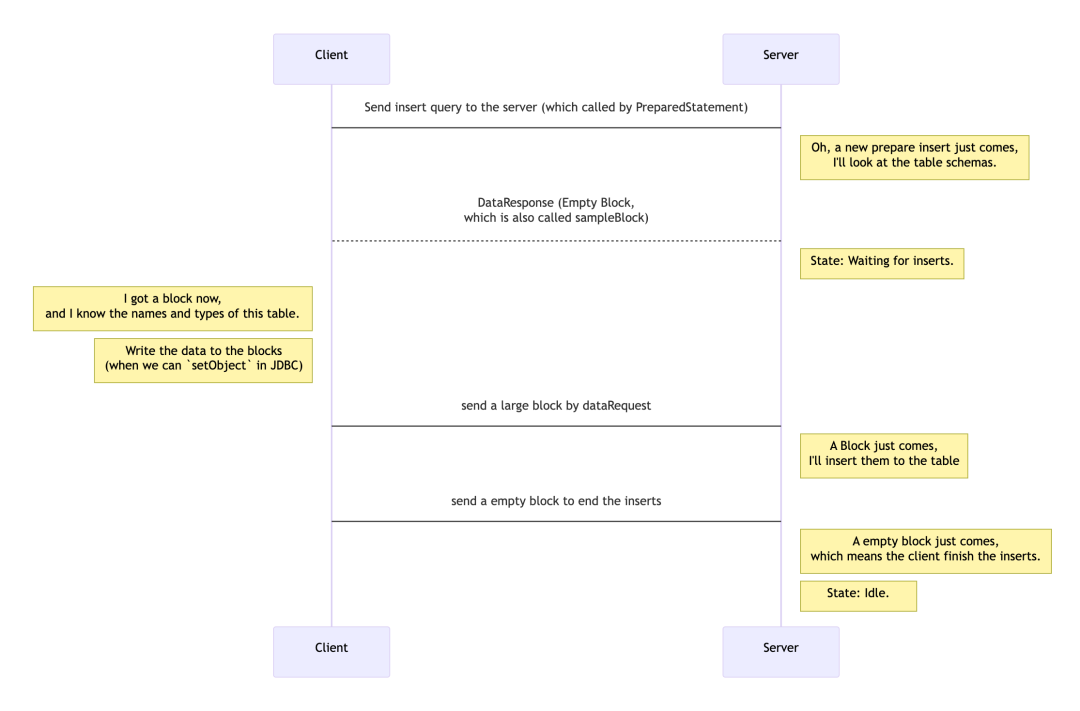
例:TCP协议 Data数据块格式
| 字段 | 类型 | 描述 |
| info | BlockInfo | Encoded block info |
| columns | UVarInt | Columns count |
| rows | UVarInt | Rows count |
| columns | []Column | Columns with data |
例:TCP协议 Column结构体格式
| 字段 | 类型 | 描述 |
| name | string | 字段名 |
| type | string | 字段类型 |
| data | byte数组 | 整列数据 |
就TCP协议而言,在进行batch insert时,插入的数据以整列的形式进行传输。这种方式不仅有利于数据在传输过程中得到更高效的压缩,而且由于自定义了数据类型的序列化机制,所以在读写过程中不需要插入分隔符,直接读取或写入定长的字节数组即可,从而大大提高了IO效率。
相比之下,HTTP协议下的batch insert需要通过FORMAT来分割行数据进行写入。同时,数据以整行传输不利于压缩,这也是HTTP协议相较于TCP协议下的batch insert效率较低的一个原因。

/ 功能比较 /
火山引擎ByteHouse企业版查询网关与 chproxy 差异对比:

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
7310)]
[外链图片转存中…(img-vaLLINoa-1715684037310)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2636
2636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









