







同一个数据Model对象,比如一个卡片Model,每次更新都是全局可见的。但是很明显,
-
对数据Model的要求很高。一个业务层数据Model类型,要全局统一,比如,一个视频卡片业务层的类型是“ModelA”,那么全局场景不能有“ModelB”表示卡片。在很多场景下,业务层会对原始数据Model进行包装适配;
-
内存占用很大;可能要缓存很多个列表。
特点
-
以命名空间+指定字段值 为key,匹配相同注解名的字段的映射,打平了Model类型的不同、层级嵌套的约束;
-
直接更新结果到数据model(如article),与数据model视角的同步;
-
打平了多个页面、复杂view层级嵌套的差异;
-
自动处理更新,使用者仅需要关心怎么更新UI,不需要考虑数据Model的一致性;
-
任意场景的支持。
思考
-
数据状态同步,到底同步的是什么?
-
上述的方案中大致有几个角色:事件、监听者、数据Model、UI。到底谁应该是主导者?
-
基于事件的方案都需要把状态同步给数据Model,能简化吗?
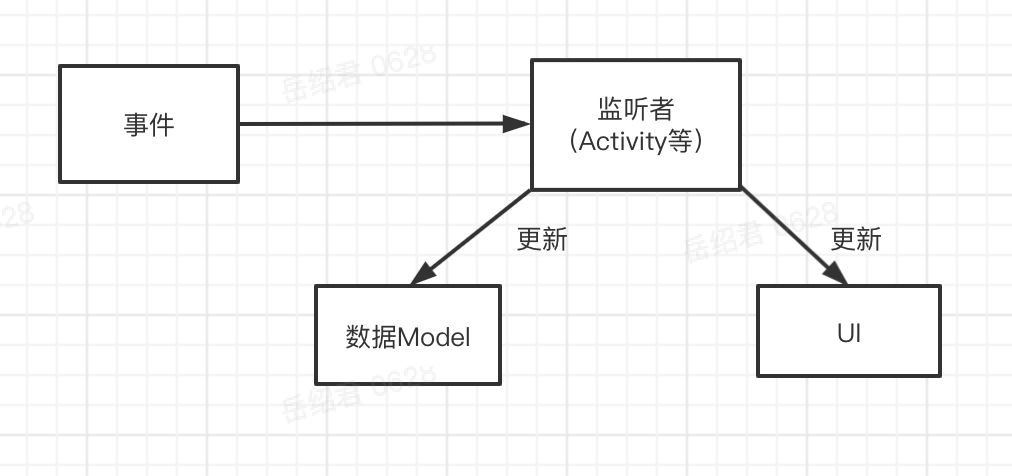
这个过程中有四个角色,三个操作。
突破View层级的限制
从MVVM说起。
MVVM是一种软件设计典范,用一种业务逻辑、数据、界面显示分离的方法组织代码。

MVVM本质上是一种数据驱动UI的理念。从这个理念看,数据状态同步,同步的是数据Model,UI的变更是由数据的变更引起的,真正关注的点应该在数据本身上。
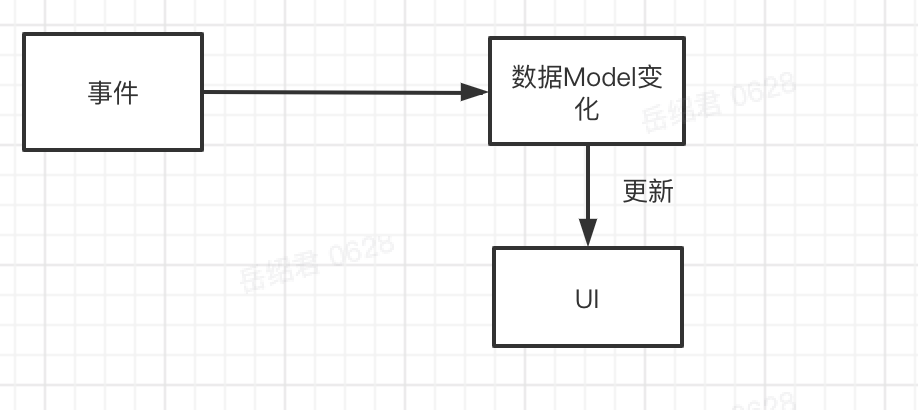
这样,就不再需要额外一个接受事件的“容器”,来控制数据和UI了。到现在,只有三个角色,两个操作了。
再回过头看,为什么跨页面、跨多View层级很难找到一个通用方案,是因为总在找一个“容器”来承载事件的接受,然后再做双份(数据和View)的同步。而且这个“容器”通常本身就是一个页面,或者其它不同层级上的view,本身就存在很多样化,为这种多样化适配,就会让事情变得复杂。
假如不再找额外的“容器”,直接把监听绑定在数据上,那么View层级的限制也就不存在了。因为不管在什么场景,什么层级,真正的逻辑中心都是数据,View也是通过数据渲染出来的,View不关心自己在什么层级,只关心数据的变化。
突破类型的限制
这里有几个类型的限制:
- 数据Model的类型是否只能一成不变,假如网络请求的原始数据是A类型,在场景1直接用了A类型,在场景2为了适配UI对A做了包装:
虽然类型不同,但是对A、B来说,都是要更新diggStatus的;
-
在Android,数据Model的类型是强类型,是从网络由二进制流反序列化出来的,那么同一个二进流,既可以反序列化成A类型,又可以反序列化成B类型,只要满足反序列化规则就行。但是事实上,他们的业务本质还是一个东西。
-
事件本身也是一个数据,只是它是用户操作发起的,表象看和数据Model无关,但是一个事件既然能更新某个数据Model,那他们一定存在着对应关系。
这个问题的本质是,类型约束是语言特性,但是和业务属性无关,只要他们能确认是一个业务含义,不管他们怎么换“马甲”,他们总是能匹配上的。
这样就演变成了:
-
怎么确定两个类型是一个业务含义;
-
怎么确定属性的对应关系(字段匹配)。
第一个好说,主要能有唯一的业务标识,就能确定是一个业务含义;怎么确定属性的对应关系呢?
现有的技术体系里就有可以借鉴的思想:数据库的使用。像jetpack 的Room组件:
可以看到,我们只要要在应用层这么定义一个数据Model叫User,为它加上注解,就可以把数据库中的字段和我们的数据对应上。那么方案呼之欲出,注解是可以完成属性匹配的。
于是乎整个流程就简化成了:
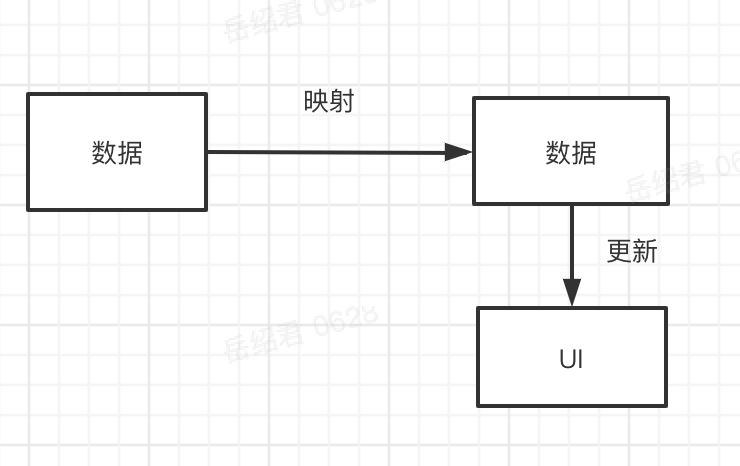
这个流程可以看到,只剩下了两个角色,和两个操作了。
所谓数据更新UI,就是View-Model;数据映射数据,就是Data-Mapping,于是这个方案的名称就是VM-Mapping。
需要对上述抽象流程做实现。
映射
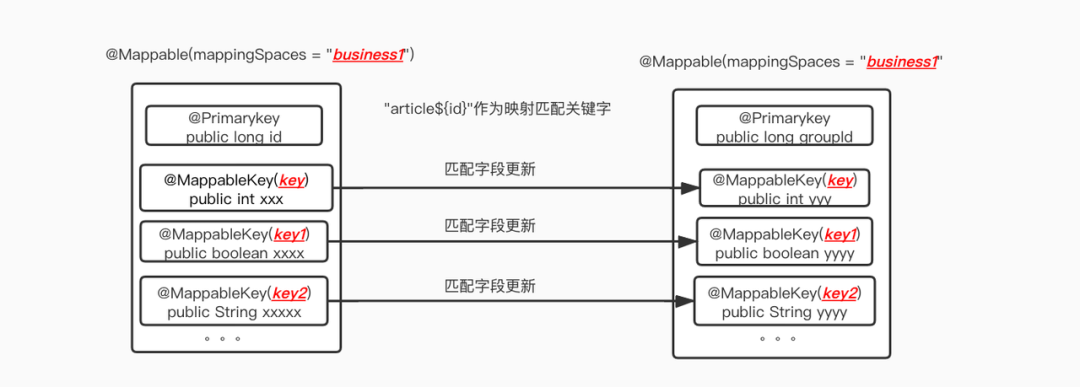
前面说到,映射关系由注解维护,一个有三个注解:
- Mappable注解 :
标注在class上,用来识别这个类是不是可以被处理。
其中mappingSpace是命名空间,表示是“一类”数据,可以和数据库表名对比理解,mappingSpace就是tableName。
- PrimaryKey注解:
标记在字段上,被标记的字段作为Model对象的唯一标识。
mappingSpace+PrimaryKey的值,就是在映射关系中的唯一业务标识。
- MappableKey注解:
标注在字段上,需要被映射对应的字段
映射关系说明:
数据驱动UI
Android里有很多类似理念的东西,比如LiveData,就是数据更新通知到UI上。本质上数据驱动UI,就是在数据Data<->UI 之间建一个“桥梁”。
这个不过LiveData并不适合用在这里,理由是:
-
LiveData绑定的生命周期是LifecycleOwner,也就是Activity、Fragment维度,明显我们的场景维度更细;
-
直接observeForever也可以,但是由于View层级的多样,调用方通常需要合适的时机移除;
-
LiveData 强引用了数据Data,这个“桥梁”本身对数据Data的生命周期造成了影响。
VM-Mapping做了个简单方案。用了两级HashMap,一级HashMap使用业务唯一标识(mappingSpace+PrimaryKey的值)为KEY,二级使用WeakHashMap,以数据Model实例为KEY,XGViewModel为VALUE。维护数据Data 和 UI回调之间的关系:
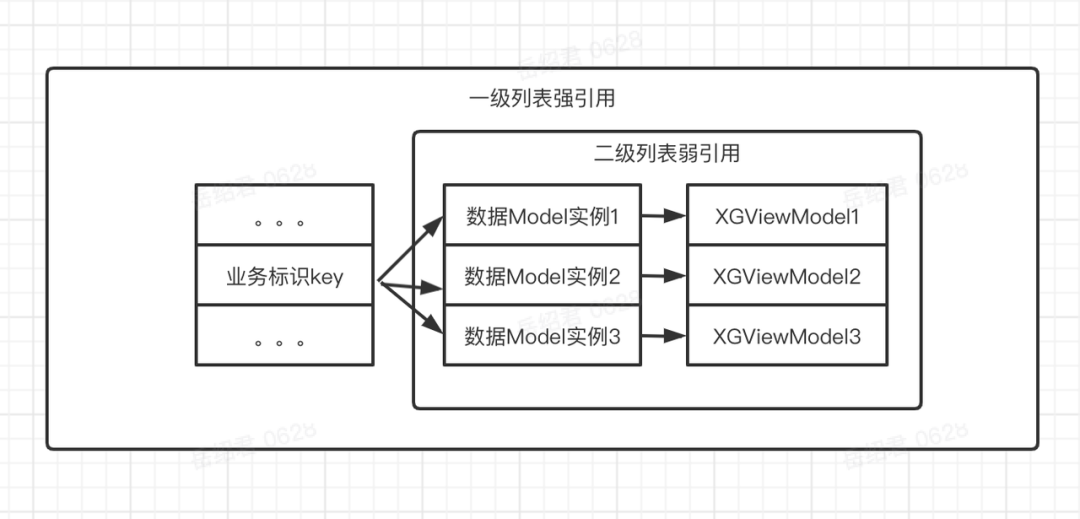
XGViewModel维护了通知给UI的弱引用回调合集。一个数据Model实例对应了一个XGViewModel。
当映射发生时,会通过业务标识Key,查找所有还没有被回收的数据Model实例,然后通过对应的XGViewModel通知UI自己的变更。
总体流程
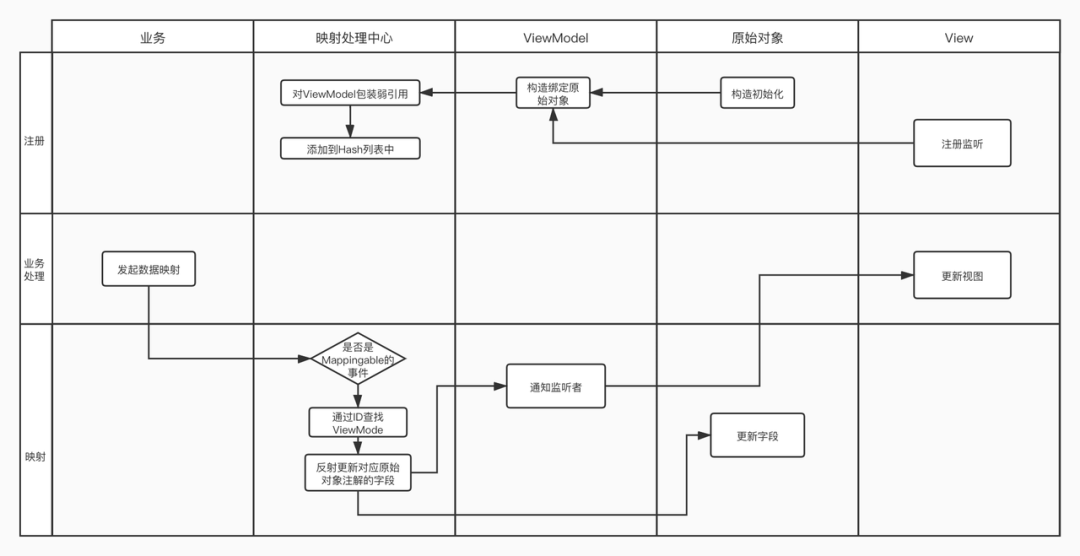
在这个流程中,业务使用只需要关心发起映射数据和更新视图。
因为存在列表,那么会有一个列表的维护者,就是所谓的映射中心。映射中心有两个核心能力:
-
收集需要被更新的数据Model列表;
-
查找匹配。
其它细节
- 因为使用了反射,为了减少性能损耗,会对收集的数据Model类型做class和相关字段的缓存。















 436
436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









