







* [having 操作 是月 group by 配套使用的。](about:blank#having___group_by__288)
* [联合查询 - 多表查询 - 重点](about:blank#_____302)
* * [多表查询的更复杂使用情况](about:blank#_325)
* * [实例1:查询同学姓名 和 对应的班级名字](about:blank#1___328)
* [准备工作 - 上面那个还算简单的,下面才是重头戏](about:blank#___332)
* * [实战1:查询“许仙”的成绩](about:blank#1_348)
* [拓展:join 关键字 实现 多表查询](about:blank#join____362)
* [实战2:查询所有同学的总成绩](about:blank#2_372)
* [实战3:查询所有同学的每门成绩](about:blank#3_384)
* [内外连接(join关键字的特有的功能)- 拓展:join 多表的实现实例3](about:blank#join_join_3_391)
* [自连接](about:blank#_395)
* [子查询](about:blank#_414)
* * [单行子查询:返回一行记录的子查询](about:blank#_431)
* [多行子查询:返回多行记录的子查询](about:blank#_435)
* * [\[not\] exists关键字 - 也是针对多行子查询的情况](about:blank#not_exists___439)
* [合并查询](about:blank#_444)
======================================================================
上篇文章MySQL - 对数据表进行“增删查改”的基础操作讲到:
“增删查改” 又称 CURD操作。
C - create
U - update
R - refer
D - delete
命令格式 :
insert into 表名 values (列的值,列的值…);
【插入的列值个数,取决于你数据表的列数】
新增操作可以指定插入的列:
insert into 表名 (列名,列名…) values (列的值,列的值…);
新增操作还可以一次插入多行记录:
insert into 表名 values (列的值,列的值…),(列的值,列的值…),…;
查询 (select :关于 select 的操作,都不会影响到数据库中的原始数据)
1、全列查找 :
select * from 表名;
2、指定列查找
select 列名,列名… from 表名;
3、指定表达式
select 表达式 from 表名;
注意:这里的表达式:往往是列和列之间的运算,并且得到的结果是一个临时表,其值不会受到原始数据类型的影响,MySQL会自动适应,将其打印出来。
4、给表达式指定别名
select 表达式 as 别名 from 表名;【此处的别名就相当于查询结果的临时表的列名】
5、去重 :
select distinct 列名 from 表名;【根据指定列的值,进行去重】
6、排序
单列排序:select 列名 from 表名 order by 列名/表达式/表达式的别名 排序规则(asc / desc);
asc :升序 ; desc : 降序
多列排序:select 列名,列名… from 表名 order by 列名, 列名,列名… 排序规则(asc / desc);
以第一列为准,进行排序。
如果指定的 第一列中有两个数据相同,这这两个数据,谁在上,谁在下。由指定的第二列对应的两行的列值的大小所决定;如果第二列恰巧也是相同,则有第三列的对应的两行的列值的大小所决定,以此类推。
其目的:就是排序的顺序是可以预期的。
多列排序的效果 和 单列排序是一样的,只能保证 指定的第一个列是有序的。
7、条件查询
select 列名 from 表名 where 条件;
where 后面的条件,起着刷选数据的作用:会遍历 服务器数据库中数据表的记录/数据,依次代入条件中,如果满足条件,将这个记录保留,反之,就直接跳过。
条件 涉及到 一些运算符:> 、<、=、 <=> 、is null、is not null、like、between and 、 in(…)
还有一些逻辑符 :and(与)、or(或) 、not(非)【and 的优先级 比 or 高】
另外注意:where 后面的条件中不能包含别名
8、分页查询
select 列名 from 表名 limit N offset M;
从 第 M 条记录开始,一个返回 N个记录。【M是从0开始,也就是说 第一条记录对应的就是零】
update 表名 set 列名 = 值,列名 = 值… where 条件;
此处的修改是针对“满足where条件”的记录进行的。
【update的修改是会作用硬盘上的原始数据(原始数据改变了),条件千万一定要仔细写!!!!(避免误改)】
如果 没有 where 条件的限制,update 操作会将 指定的列,每一行的数据都修改。
delete from 表名 where 条件;
此处的删除是针对“满足where条件”的记录进行的。
delete删除操作是会作用硬盘上的原始数据(原始数据是真的没了),条件千万一定要仔细写!!!!(避免误删)】
如果 没有 where 条件的限制,delete 操作会将数据表中的所有数据清空。
==========================================================================
约束就是我们的数据库在使用的时候,对于里面能够存储的数据所提出的要求和限制。
程序员就可以借助约束来完成更好的校验,
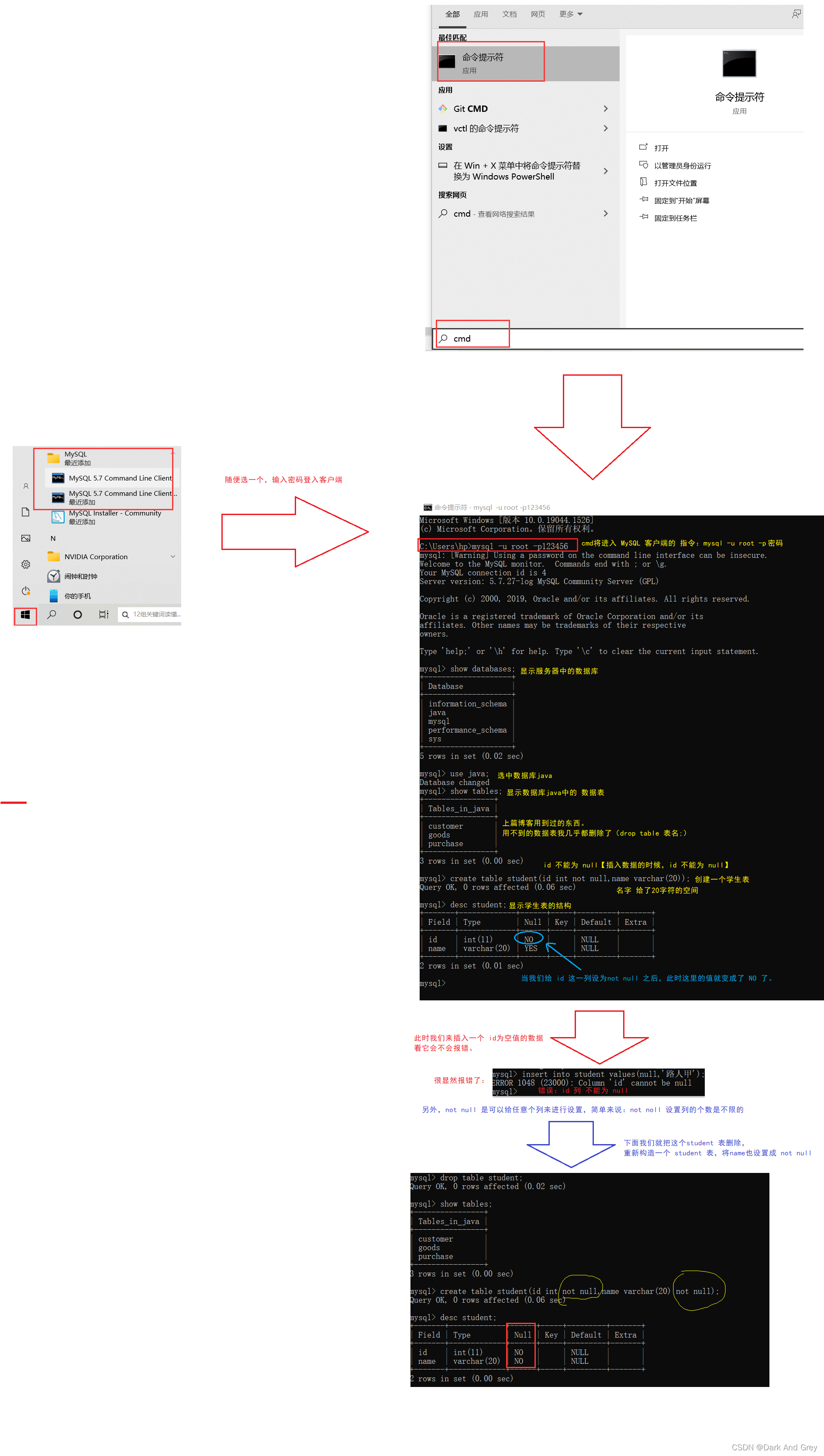
1、not null - 指示某列不能存储 NULL 值。
如果使用 not null 指示某列不能存储 NULL 值时,尝试往这里插入空值,就会直接报错。
简单来说,not null 用于创建数据表时,指定 列的插入值的情况不能为空值,必须是具体的数据。
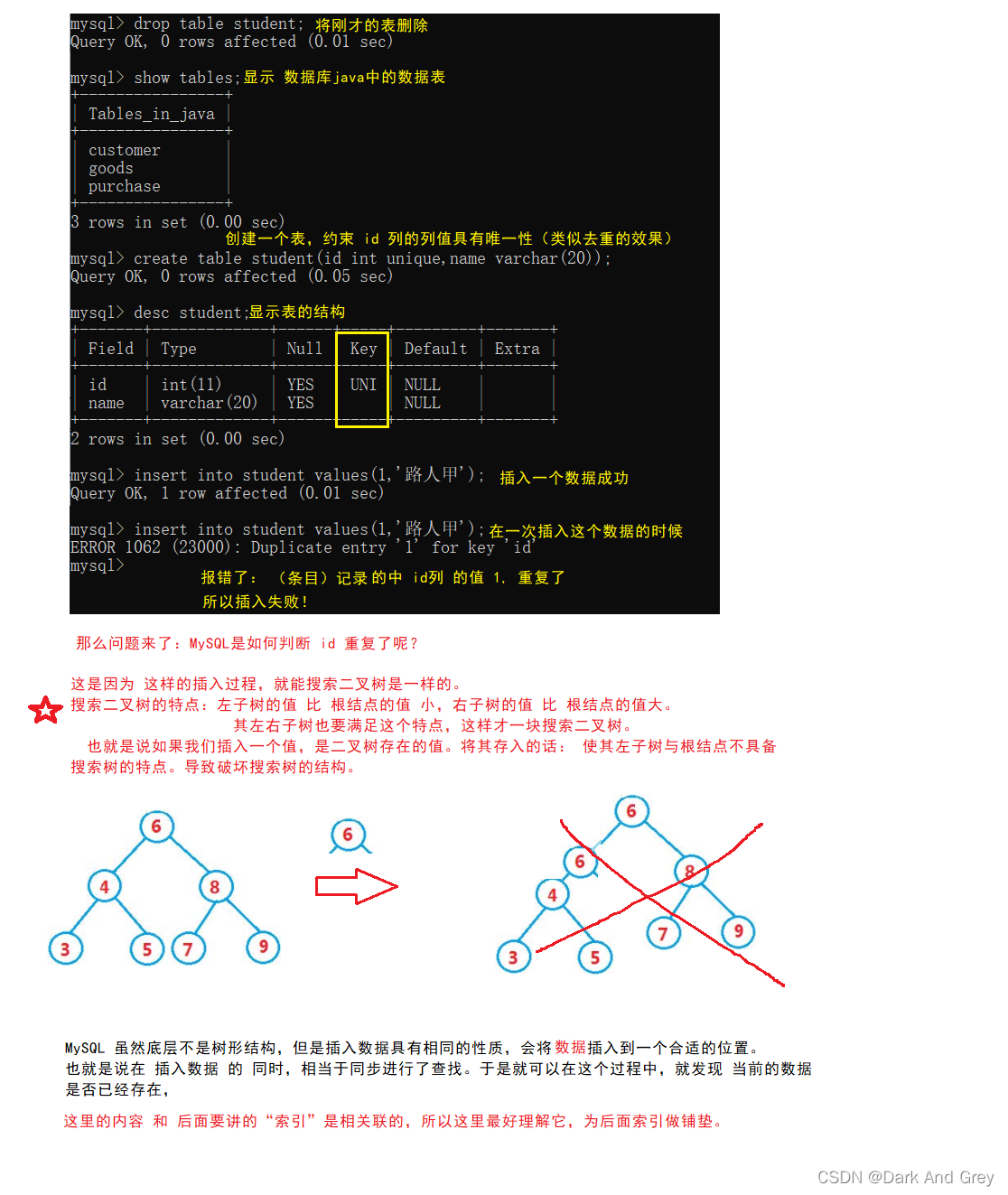
2、unique - 保证某列的每行必须有唯一的值。
数据唯一:尝试插入重复的值,也会报错,
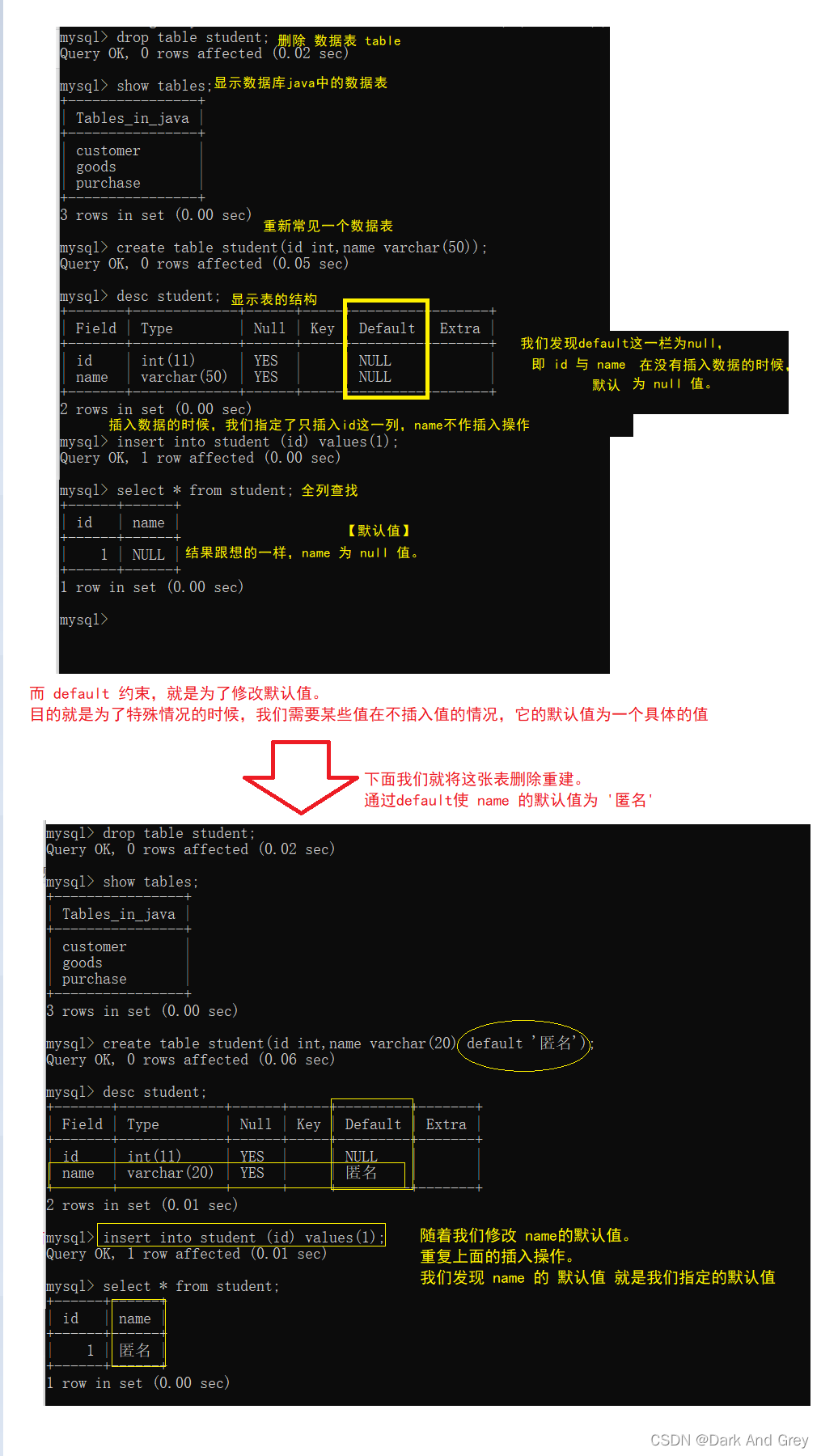
3、default - 规定没有给列赋值时的默认值。
修改 / 指定 某一列的默认值。
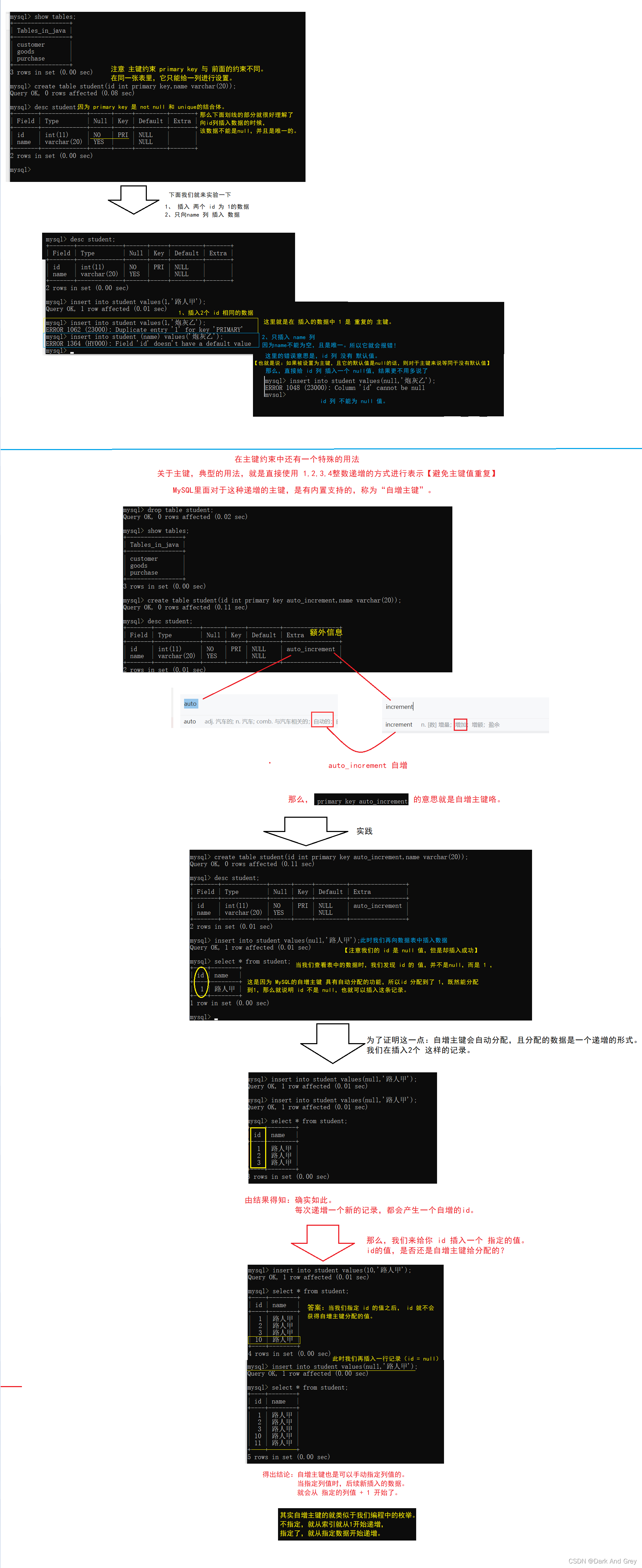
4、primary key - 主键约束 - 日常开发中最常使用的约束!也是最重要的约束
primary key 主键约束 相当于 not null 和 unique 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
主键约束,相当于数据的唯一身份标识,类似身份证号码。
创建表的时候,很多时候都需要指定的主键。
5、foreign key - 保证一个表中的数据匹配另一个表中的值的参照完整性。
外键,描述的是 两个表之间的关联关系,表1 里的数据 必须在 表2 中存在

外键约束语法:create table 子表名(列名 类型,列名 类型,… 列名 类型, foreign key (子表中置为外键的 列名) references 父表名(依赖的父表中列名));

上面所讲的都是针对子表的操作,下面我们来针对一下父表的操作。
为什么要针对父表进行操作,是因为 外键约束同样也在约束父表。
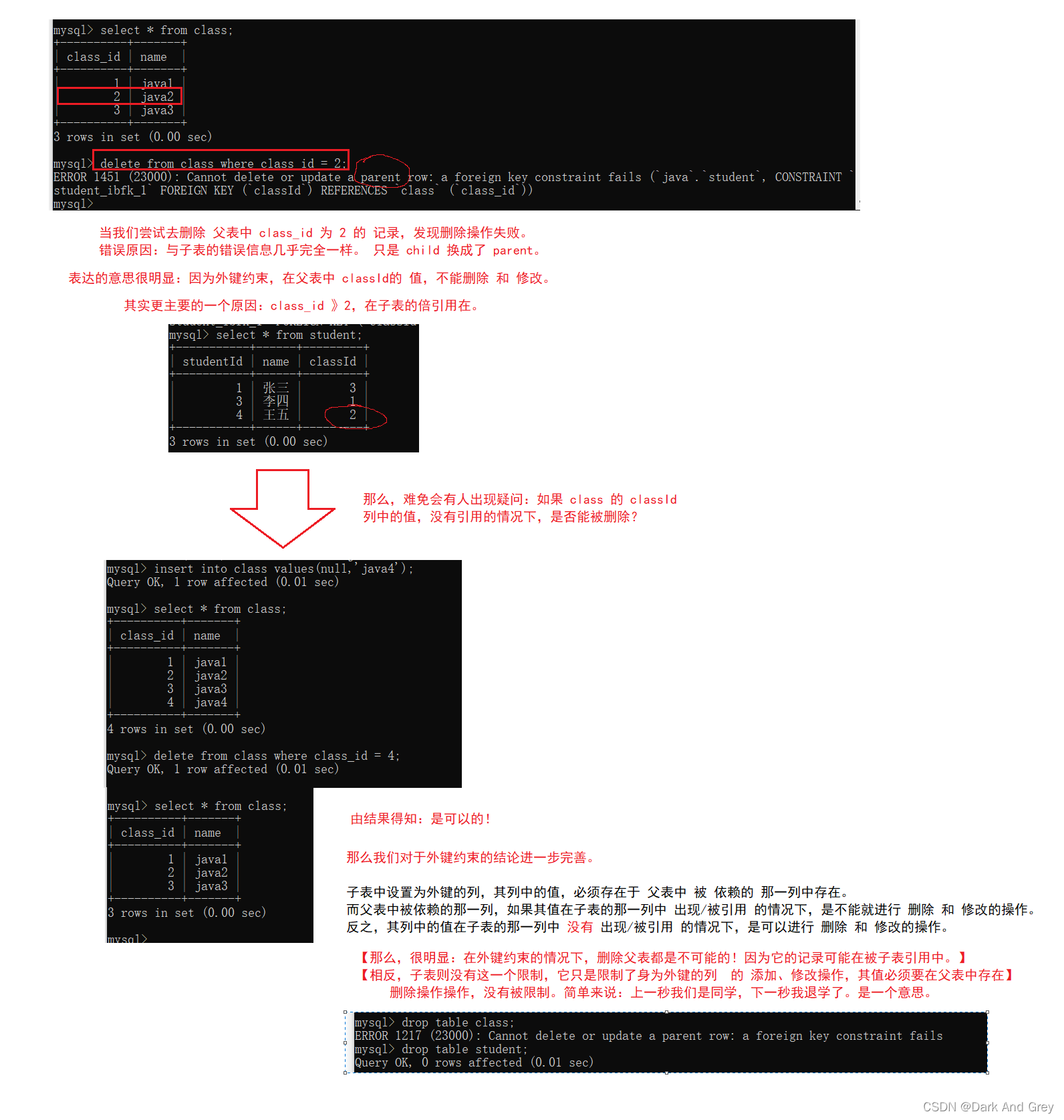
外键约束的工作原理
拓展

6、check - 保证列中的值符合指定的条件。对于MySQL数据库,对check子句进行分析,但是忽略check子句 - (了解)
指定一个条件,通过条件来对值进行判定。
但是 MySQL并不支持这个。
===================================================================
所谓的“数据库设计” 和 “表的设计”其实就是根据实际问题场景,把表给创建出来。
【我觉得这个设计问题,就和 java 的 类 和 对象,差不多。将一个现实问题抽象一个类,这个类具有我们解决问题的属性和方法,再通过实例化去使用它。来解决我们实际问题】
但凡是和“设计”鱼贯的的话题,都比较抽象,一般来说都是都需有一定的经验。
很显然对于我们这些还未踏入职场的新人来说,肯定是缺乏的。
一般是给我们一个问题场景,让我们思考如何设计数据库,如何设计表。
一个典型的通用的办法:先找出这个场景中涉及到的“实体”,然后再来分析“实体之间的关系”。
【实体 就类似 java 中 对象,一些操作,是需要对象与对象之间的相互作用】
实体就可以视为是需求中的一些关键性的名词。
下面讲一个典型的场景

实体之间的关系主要可以分为以下几种:
1、一对一的关系【一个钥匙,开一扇门】
2、一对多的关系【一个钥匙,开多扇门】
3、多对多的关系【n 个钥匙,开m扇门】
4、没有关系【就是两个互不相干的表】-
分析实体之前的关系,一个关键性技巧就是造句。
不要想太复杂,就是小学语文的造句,给你几个词,用它造一个句子。
1、一对一的关系【一个钥匙,开一扇门】
一对一的关系很好理解:就是一一对应的关系。
就以上面讲的 学生管理系统为例。
学生的基本信息简称学生表(学号,学生姓名,学生班级。。。。)
校园网,想必大家都很熟悉,每个人都有一个学生账号,那么我们就需要一个 账号管理的 user 表(账户姓名,账号,密码…)
提取关键名词: 学生 和 账户
造句:一个账户对应到一个学生,一个学生只有一个账户。
这个就是一对一的关系。
那么如何在数据库中表示这种一对一的关系呢?
方法一; 可以把这两个实体用一张表表示
【就是这个表概括 学生表 和 user 表的 所有信息】
方法二:用两张表表示:一张表包含了另一张表的 列的信息。(外键约束)
【根据这个对应的关系,就可以随时找到某个账户所对应的学生是谁,也就能找到这个学生的对应账户】
假设我们有一个学生表 (学号,姓名…);一个 班级表(班级编号,班级名称…)
这就是一个 一对多的关系
还是造句: 一个 学生 属于一个 班级,一个班级可以包括多个学生。
一对多 就可以看作 一个班级 有多名学生。
在数据库中表示一对多的关系,也有两种方法
方法一:
就跟前面的举例子是一样的:在学生表中添加一个列 classId 用来表示学生所在的班级编号。

方法二:
就跟前面的举例子是一样的:在班级表新增一列来表示 这个班级的学生id。

对于 MySQL来说, 表示一对多关系的时候,只能采用方法一。
方法二之所以不能使用,是因为MySQL中没有数组这个类型,所以无法用代码表现出方法二。
如果你用的是 Redis 这样的数据库,就有数组类型,就可以考虑使用方法二来表示。

这种多对多的关系,在数据库表示的方式只有一种:使用一个关联表 来表示两个表之间的关系。
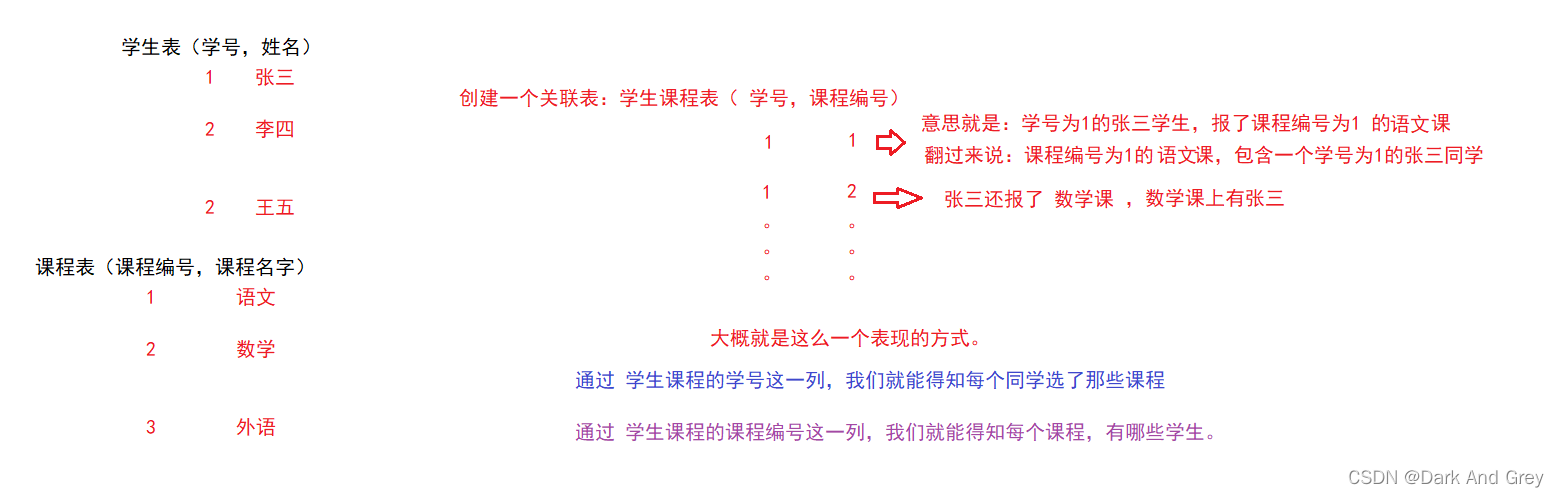
总结
这些实体之间的关系,你可以理解为一个技巧,一种思维。就像辅助外挂一样。
另外有的时候,为了耿芳变的 表示/找到实体之间的关系(尤其是针对比较复杂的场景),还可以通过画ER 图的方式来表示。【不要问我 ER ,我只是知道有这个东西】
================================================================================
和 查询操作 结合在一起的操作。
把从上一个表中的查询结果,作为下一个表要插入的数据。
语法格式:insert into 表B select * from 表 A;
将表A的遍历结果插入表B 中。

小拓展
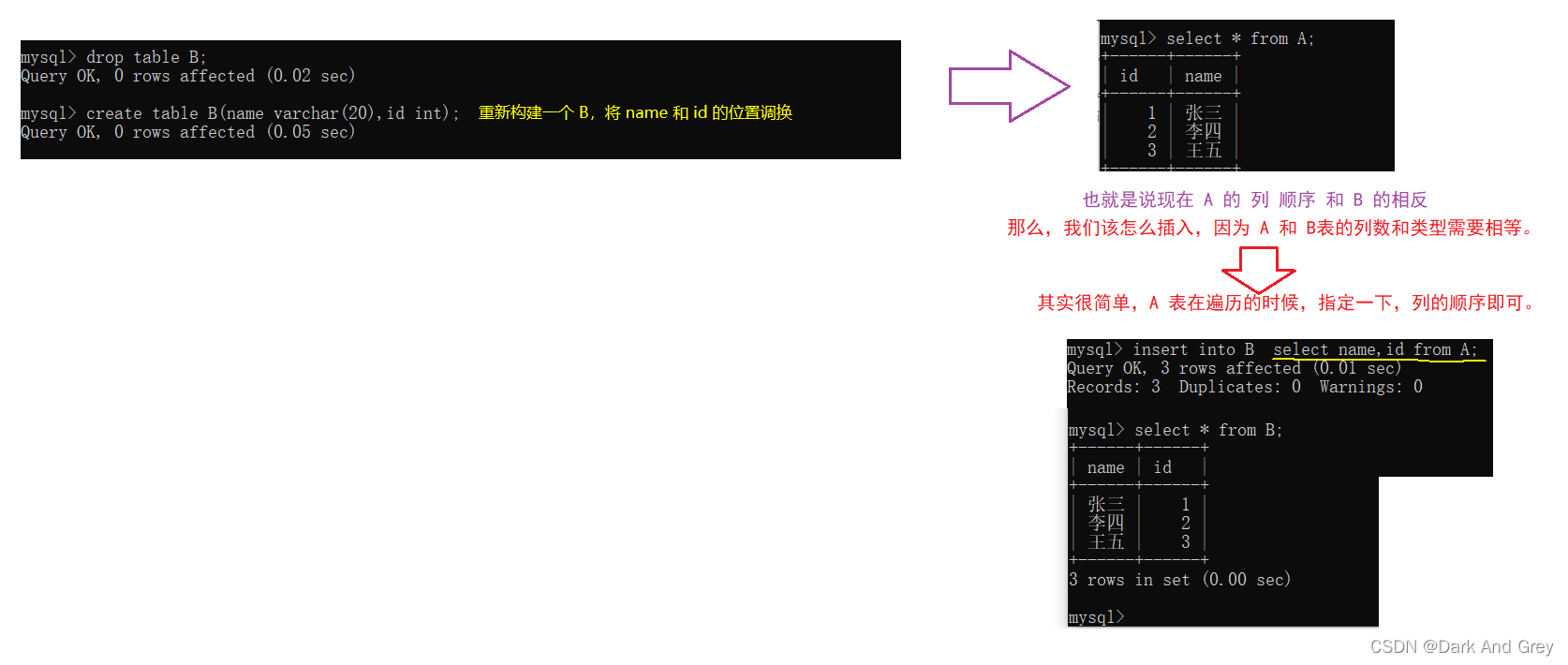
另外,还可以给后面的 select 指定一些其他的 :条件,排序,limit,去重…
插入的数据,实际就是select的执行结果的临时表。
【注意,这种操作语法上,只要类型匹配,就能插入。但是不一定有意义】
聚合查询
前面讲的基础查询带表达式的操作是针对列与列之间的关联运算。
而这里的聚合查询,是针对行与行之间的数据进行了关联操作。
聚合查询:就是把 多行的数据给进行了关联操作。
常见的聚合函数
说到聚合查询,就不得不提到聚合函数。
MySQL 内置一些聚合函数,可以让我们直接来使用。【如下图所示】
【expr - 表达式、avg -> average - 平均值、 distinct - 去重(可以添加,进去数据去重)】
| 函数 | 说明 |
| — | — |
| count ( [distinct] expr ) | 返回查询到的数据的 数量 |
| sum( [distinct] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| avg( [distinct] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| max ([distinct] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| min[distinct] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
聚合函数 :count
返回查询到的数据的 数量。换个说法 查询结果有多少行。
命令格式:select count(列名 / *) from 表名
*:表示 全列查询
列名:表示 指定列查询
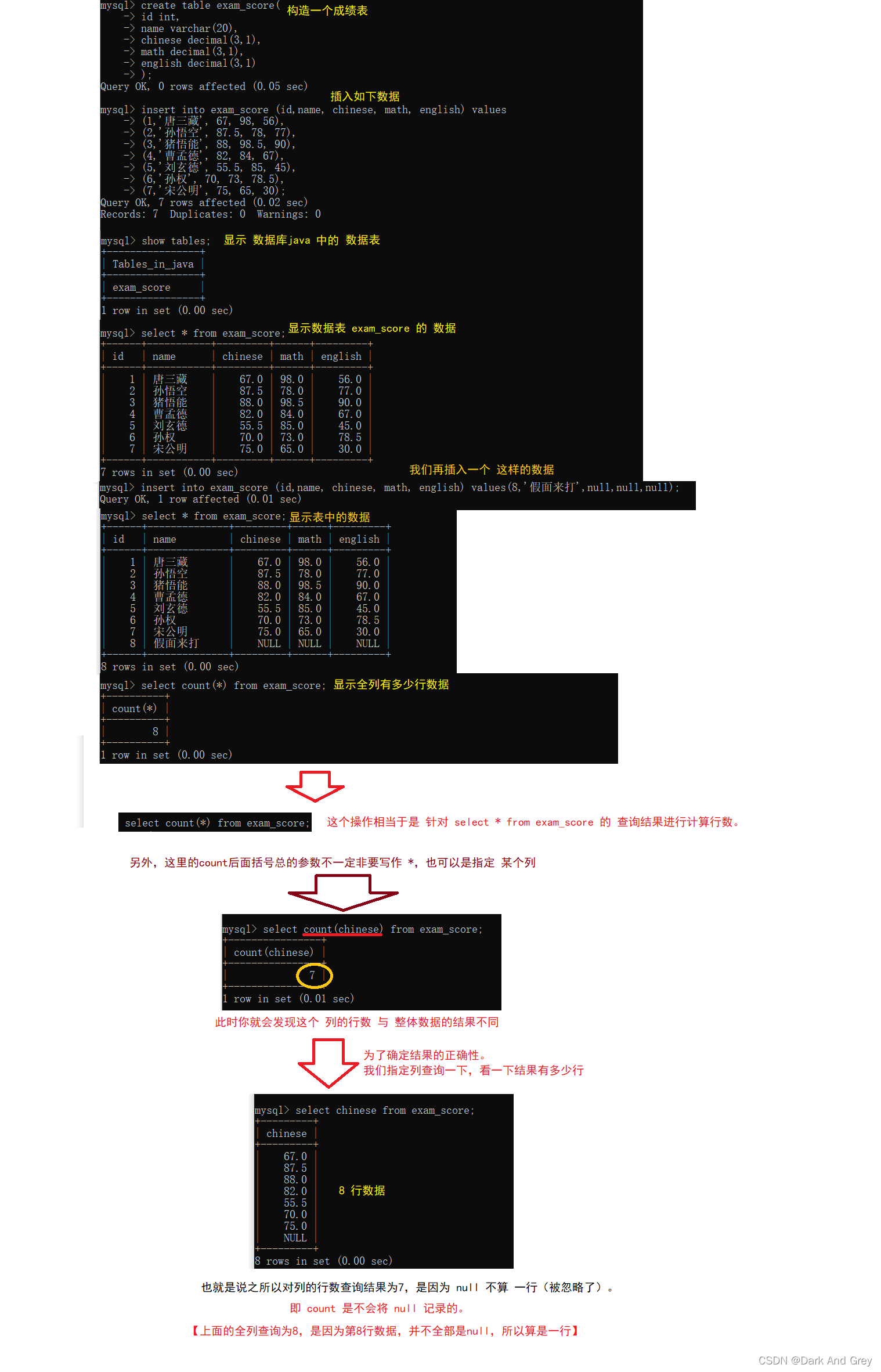
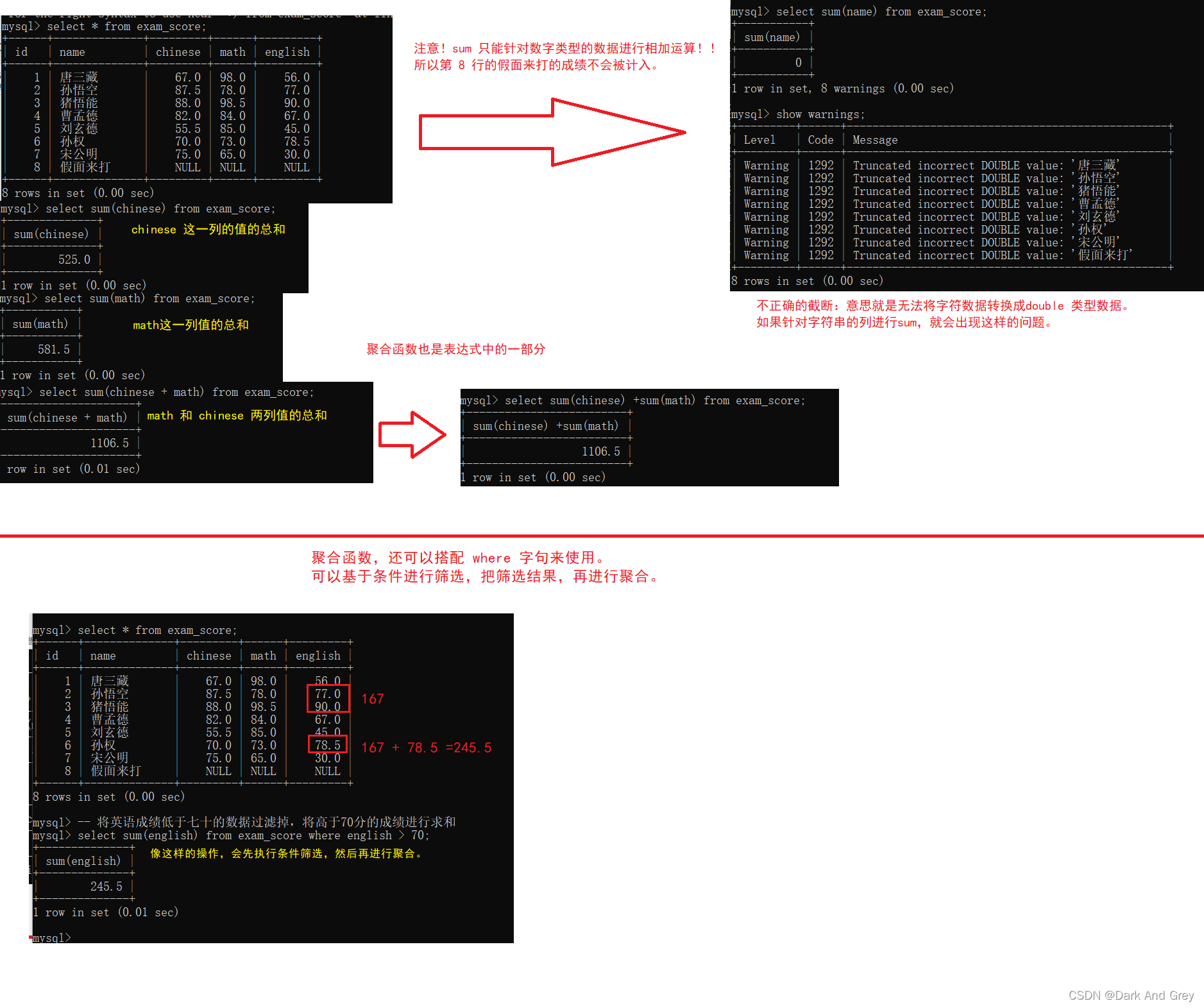
聚合函数 : sum
sum的功能就是求和,很Excel里面的求和非常像!
将某一列的若干行数据进行相加。(NULL 值 不算)
== 语法格式: select sum(列名/表达式) from 表名;
avg、max 、min 这个聚合函数的用法都是一样的。(NULL 值 不算)
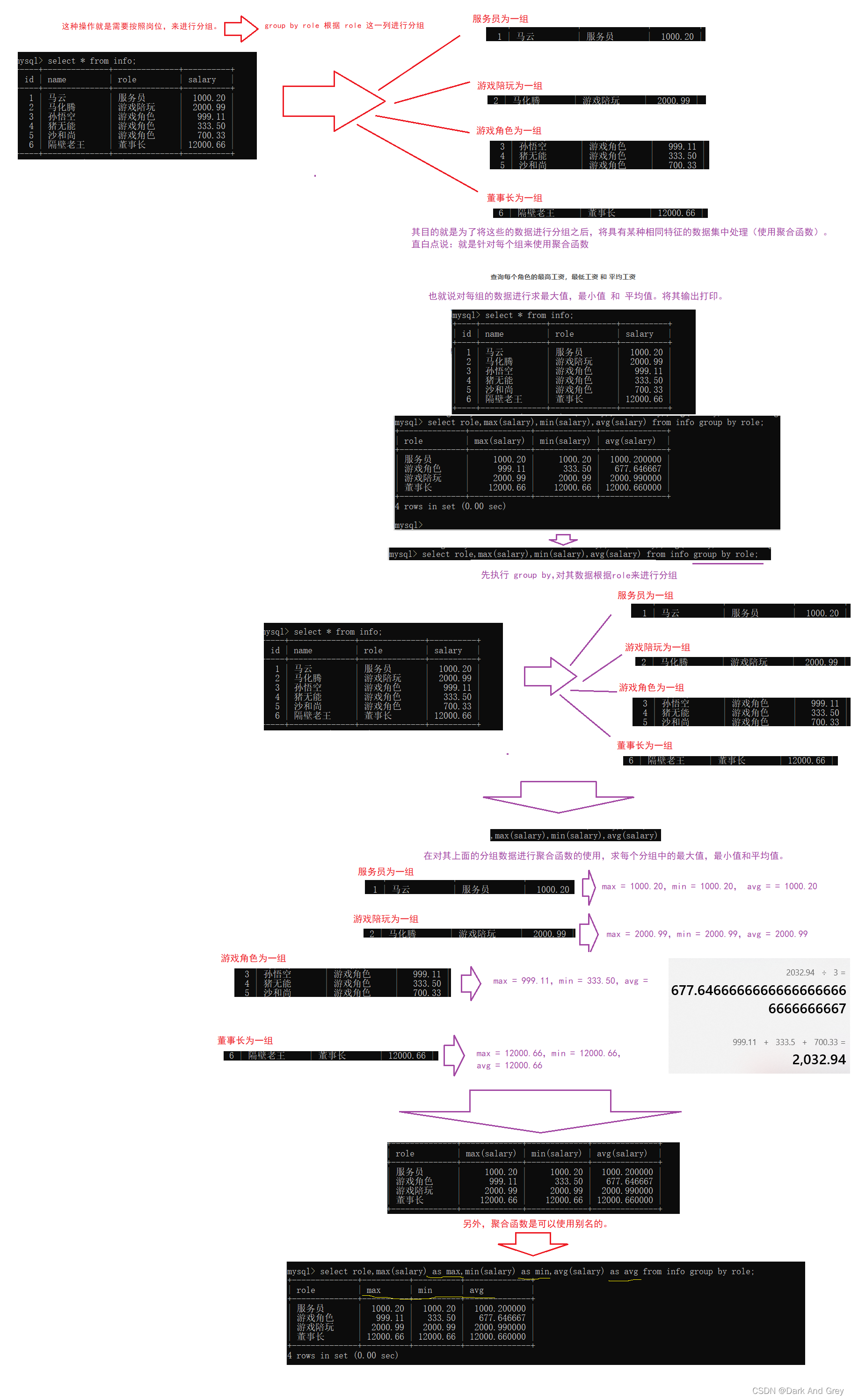
group by子句
select 中使用 group by 子句可以对指定列进行分组查询。需要满足:使用 group by 进行分组查
询时,select 指定的字段必须是“分组依据字段”(相同的字段为一组),其他字段若想出现在select 中则必须包含在聚合函数中。
准备工作
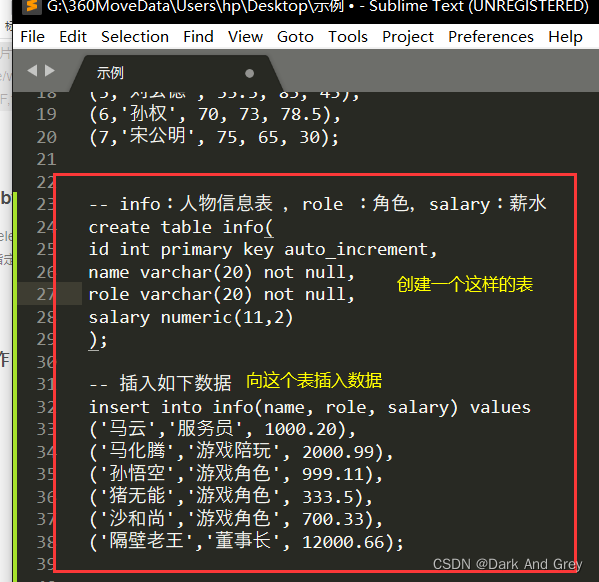
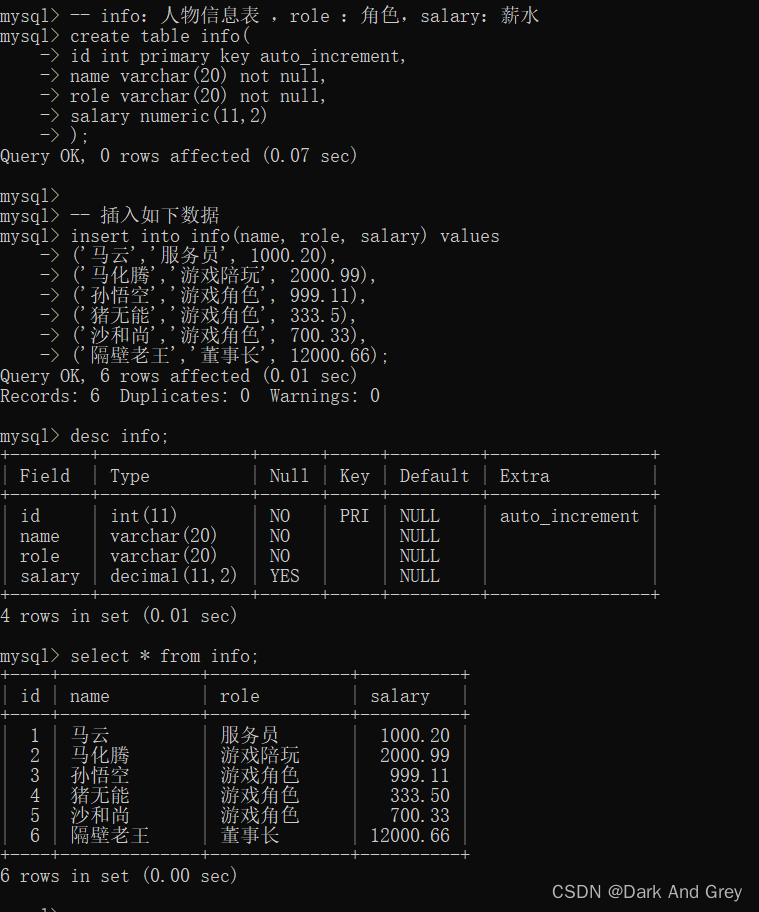
实战: 查询每个角色的最高工资,最低工资 和 平均工资
having 操作 是月 group by 配套使用的。
针对分组之后,得到的结果。可以通过having 来进行制定条件。
group by 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 where 语句,而需要用having。
注意!上面红色句子的 “group by 子句进行分组以后” 的 “以后”两个字!!!
意思是如果数据先进行了分组之后,是不能使用where来制定条件的,只能是有having 来 制定条件。
反过来理解:在对数据进行分组之前,是可以使用 where 来制定条件的。
where 和 having的区别:
where 是在数据分组之前进行制定条件,来筛选数据。
having 是根据 分组之后的数据,进行指定条件,筛选每个分组中数据。

联合查询 - 多表查询 - 重点
**联合查询:把多个表的记录 一起合并,一起进行查询。
联合查询又称 多表查询。**
多表查询是整个SQL语句中最复杂的部分,也是笔试和面试中最常考的部分。
但是在实际开发中,一般是禁止使用多表查询的。【也就是面试造绿巨人,重拳出击,工作中就是班纳,静静摸鱼】
另外,可以告诉你们的是:大厂就喜欢这种调调,靠你一些很偏的知识点。【比如:算法】
想要理解 多表查询,就得必须知道一个重要的运算:笛卡尔积(多表查询中核心操作)。
像平面坐标系,就是笛卡尔提出的。笛卡尔就是一个知名的数据家,专门研究几何的。
笛卡尔积 也就是一个数学上运算。
笛卡尔积的计算其实非常简单,就是一个类似于排列组合。
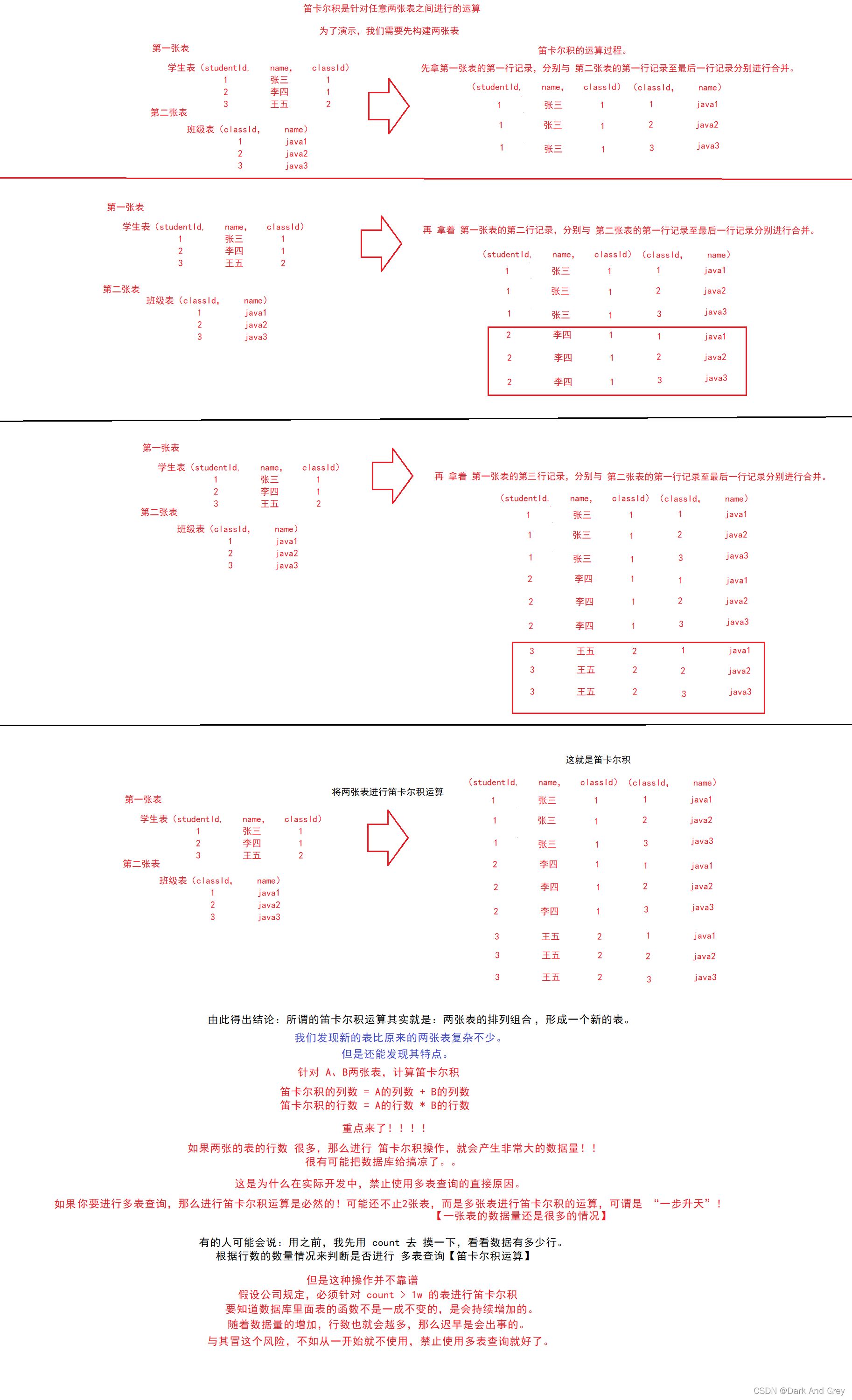
接下来要讲的 多表查询 就是基于 笛卡尔积 的 基础上 进行的。
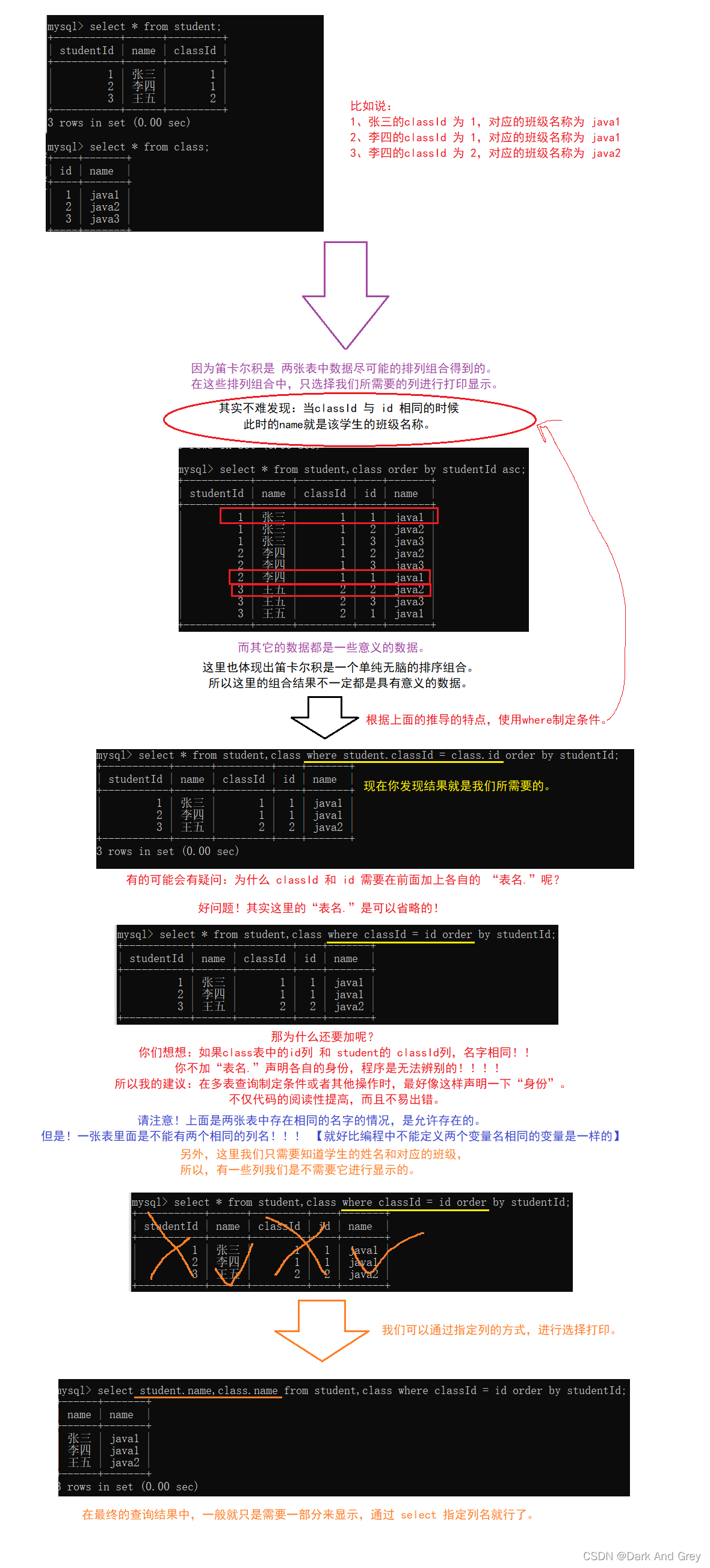
那么,如何在在SQL 中进行笛卡尔积(多表查询)操作呢?
下面我们就来执行一个最简单的多表查询(笛卡尔积运算)。
命令格式:select 列名,列名/ * from 表名,表名…

现在我们熟悉笛卡尔积运算方式【最简单的多表查询】的基础上,我们就开始着手实现更为复杂的多表查询。
多表查询的更复杂使用情况
笛卡尔积这个操作,虽然执行效率不高,但是本身确实是一个功能挺好用的操作
可以借助笛卡尔积,来完成一些复杂的操作。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









