






swap内存
默认值60,代表 当已使用的物理内存高于60%时,开始使用交换空间
[root@node01 redis-5.0.8]# sysctl -a| grep vm.swappiness
vm.swappiness = 60
vm.swappiness = 0
最大限度使用物理内存,然后才是 swap空间,即在内存不足的情况下–当剩余空闲内存低于vm.min_free_kbytes limit时,使用交换空间。
在内存紧张时优先减少RAM里文件系统缓存的大小,而非使用swap空间,这是一种提高数据库性能的推荐做法。
vm.swappiness = 1
内核版本3.5及以上、Red Hat内核版本2.6.32-303及以上,进行最少量的交换,而不禁用交换。
vm.swappiness = 10
当系统存在足够内存时,推荐设置为该值以提高性能。
vm.swappiness = 60
默认值
vm.swappiness = 100
积极的使用交换空间。
对于内核版本为3.5及以上,Red Hat内核版本2.6.32-303及以上,多数情况下,设置为1可能比较好,0则适用于理想的情况下(it is likely better to use 1 for cases where 0 used to be optimal)
临时设置
# echo 10 > /proc/sys/vm/swappiness
OOM killer
上面说到overcommit_memory的默认值是0,在这种情况下,所有应用程序申请的内存总和是大于系统物理内存+swap,当大多数应用程序都消耗完自己的内存的时候,发现可用内存不足,这个时候就会触发OOM Killer,选择杀死一些进程来腾出空间保证系统正常运行。
参考内核源代码linux/mm/oom_kill.c。当发生oom时,调用bool out_of_memory(struct oom_control *oc),首先判断是否启用oom_killer。是否启用oom_killer是由oom_killer_disabled来决定的,先判断oom_killer_disabled的值,如果有值,则不会触发OOM机制;布尔型变量oom_killer_disabled定义在文件mm/page_alloc.c中,并没有提供外部接口更改此值,但是在内核中此值默认为0,表示打开OOM-kill。
下面是oom的源码:
bool out_of_memory(struct oom_control *oc)
{
unsigned long freed = 0;
if (oom_killer_disabled)
return false;
if (!is_memcg_oom(oc)) {
blocking_notifier_call_chain(&oom_notify_list, 0, &freed);
if (freed > 0)
/* Got some memory back in the last second. */
return true;
}
/*
* If current has a pending SIGKILL or is exiting, then automatically
* select it. The goal is to allow it to allocate so that it may
* quickly exit and free its memory.
*/
if (task_will_free_mem(current)) {
mark_oom_victim(current);
wake_oom_reaper(current);
return true;
}
/*
* The OOM killer does not compensate for IO-less reclaim.
* pagefault_out_of_memory lost its gfp context so we have to
* make sure exclude 0 mask - all other users should have at least
* ___GFP_DIRECT_RECLAIM to get here. But mem_cgroup_oom() has to
* invoke the OOM killer even if it is a GFP_NOFS allocation.
*/
if (oc->gfp_mask && !(oc->gfp_mask & __GFP_FS) && !is_memcg_oom(oc))
return true;
/*
* Check if there were limitations on the allocation (only relevant for
* NUMA and memcg) that may require different handling.
*/
oc->constraint = constrained_alloc(oc);
if (oc->constraint != CONSTRAINT_MEMORY_POLICY)
oc->nodemask = NULL;
check_panic_on_oom(oc);
if (!is_memcg_oom(oc) && sysctl_oom_kill_allocating_task &&
current->mm && !oom_unkillable_task(current) &&
oom_cpuset_eligible(current, oc) &&
current->signal->oom_score_adj != OOM_SCORE_ADJ_MIN) {
get_task_struct(current);
oc->chosen = current;
oom_kill_process(oc, "Out of memory (oom_kill_allocating_task)");
return true;
}
select_bad_process(oc);
/* Found nothing?!?! */
if (!oc->chosen) {
dump_header(oc, NULL);
pr_warn("Out of memory and no killable processes...\n");
/*
* If we got here due to an actual allocation at the
* system level, we cannot survive this and will enter
* an endless loop in the allocator. Bail out now.
*/
if (!is_sysrq_oom(oc) && !is_memcg_oom(oc))
panic("System is deadlocked on memory\n");
}
if (oc->chosen && oc->chosen != (void *)-1UL)
oom_kill_process(oc, !is_memcg_oom(oc) ? "Out of memory" :
"Memory cgroup out of memory");
return !!oc->chosen;
}
然后调用check_panic_on_oom(oc),这个函数决定采用哪种方式处理OOM。而决定哪种方式依赖于内核参数panic_on_oom。panic_on_oom的枚举值有:
默认值 0。启动OOM Killer
1 在有cpuset、memory policy、memcg的约束情况下的OOM,可以考虑不panic,而是启动OOM killer
2。无论那种情况,强制进入kernel panic(直接死机)。
/*
* Determines whether the kernel must panic because of the panic_on_oom sysctl.
*/
static void check_panic_on_oom(struct oom_control *oc)
{
//0表示启动OOM killer,因此直接return了
if (likely(!sysctl_panic_on_oom))
return;
//2是强制panic,不是2的话,还可以商量
if (sysctl_panic_on_oom != 2) {
/*
* panic_on_oom == 1 only affects CONSTRAINT_NONE, the kernel
* does not panic for cpuset, mempolicy, or memcg allocation
* failures.
*/
/*
*在有cpuset、memory policy、memcg的约束情况下的OOM,可以考虑不panic,而是启动OOM killer
*/
if (oc->constraint != CONSTRAINT_NONE)
return;
}
/* Do not panic for oom kills triggered by sysrq */
if (is_sysrq_oom(oc))
return;
dump_header(oc, NULL);
//死机
panic("Out of memory: %s panic_on_oom is enabled\n",
sysctl_panic_on_oom == 2 ? "compulsory" : "system-wide");
}
如果决定发起OOM killer,判断系统参数oom_kill_allocating_task,来决定选择哪些进程去kill。oom_kill_allocating_task的值:
1 选择kill引起oom的进
其他值 调用select_bad_process(oc),选择最bad的进程。
如果没有配置该值,则调用select_bad_process(oc),接着调用oom_evaluate_task(p, oc),接着调用oom_badness(task, oc->totalpages)来对进程打分,
从oom_kill.c 代码里可以看到 oom_badness() 给每个进程打分,根据 points 的高低来决定杀哪个进程,这个 points 可以根据 adj 调节,root 权限的进程通常被认为很重要,不应该被轻易杀掉,所以打分的时候可以得到 3% 的优惠(分数越低越不容易被杀掉)。
我们可以在用户空间通过操作每个进程的 oom_adj 内核参数来决定哪些进程不这么容易被 OOM killer 选中杀掉。比如,如果不想 MySQL 进程被轻易杀掉的话可以找到 MySQL 运行的进程号后,调整 /proc/PID/oom_score_adj 为 -15(注意 points越小越不容易被杀)防止重要的系统进程触发(OOM)机制而被杀死,内核会通过特定的算法给每个进程计算一个分数来决定杀哪个进程,每个进程的oom分数可以在/proc/PID/oom_score中找到。每个进程都有一个oom_score的属性,oom killer会杀死oom_score较大的进程,当oom_score为0时禁止内核杀死该进程。
设置/proc/PID/oom_adj可以改变oom_score,oom_adj的范围为【-17,15】,其中15最大-16最小,-17为禁止使用OOM,至于为什么用-17而不用其他数值(默认值为0),这个是由linux内核定义的,查看内核源码可知:路径为linux-xxxxx/include /uapi/linux/oom.h。
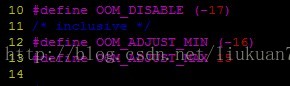
保证某个进程不被内核杀掉可以这样操作:
echo -17 > /proc/$PID/oom_adj
例如防止sshd被杀,可以这样操作:
pgrep -f "/usr/sbin/sshd" | while read PID;do echo -17 > /proc/$PID/oom_adj;done
查看所有进程的oom_score排行前十的进程
#!/bin/bash
for proc in $(find /proc -maxdepth 1 -regex '/proc/[0-9]+'); do
printf "%2d %5d %s\n" \
"$(cat $proc/oom_score)" \
"$(basename $proc)" \
"$(cat $proc/cmdline | tr '\0' ' ' | head -c 50)"
done 2>/dev/null | sort -nr | head -n 10
防止OOM Killer的方法
综上所述,知道了OOM killer的原理以及约束后,可以总结出以下几种方法来避免进程被OOM killer杀死。

















 1751
1751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









