







- Channel:消息通道,在客户端的每个连接里,可建立多个channel。
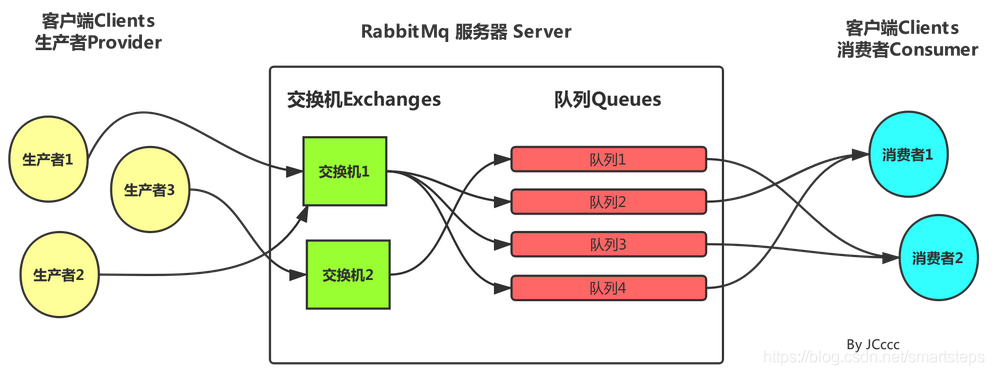
一.如何发送消息
-
生产者和Broker建立TCP连接;
-
生产者和Broker建立通道;
-
生产者通过通道消息发送给Broker,由Exchange将消息进行转发;
-
Exchange将消息转发到止跌那个的Queue(队列)。
二.如何接收消息
-
消费者和Broker建立TCP连接;
-
消费者和Broker建立通道;
-
消费者监听制定的Queue(队列);
-
当有消息到达Queue时Broker默认将消息推送给消费者;
-
消费者接受到消息。
1. Direct 广播模式
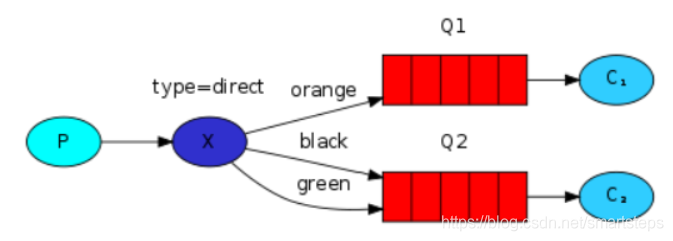
是最简单的模式.即创建消息队列的时候,指定一个路由键(RoutingKey)。当发送者发送消息的时候,指定对应的Key。当Key和消息队列的RoutingKey一致的时候,消息将会被发送到该消息队列中。推荐:Java进阶学习资料。
2.Topic 主题交换区模式
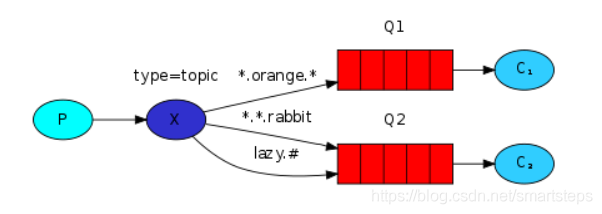
topic转发信息主要是依据通配符,队列和交换机的绑定主要是依据一种模式(通配符+字符串),而当发送消息的时候,只有指定的Key和该模式相匹配的时候,消息才会被发送到该消息队列中.通配符:* 表示一个词,# 表示零个或多个词
3.fanout是路由广播的形式
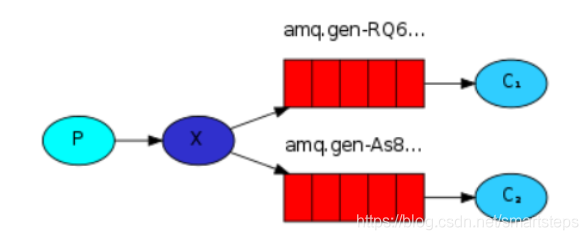
fanout是路由广播的形式,将会把消息发给绑定它的全部队列,即便设置了key,也会被忽略。因此我们发送到交换机的消息会使得绑定到该交换机的每一个Queue接收到消息,这个时候就算指定了路由键(routingKey),或者规则(即上文中convertAndSend方法的参数2),也会被忽略!
1、加大服务器带宽
访问量大时,较长的数据容易将带宽占满。如服务器上传带宽为10M,则实际上传带宽可认为1M,每秒上传量为1M/1K=1K。如果把带宽加到100M,则每秒上传量为10K。一般情况下,RabbitMq服务器能够接受的每秒写入量为20K-50K(8G内存),因此在带宽在不足200M的时候,加大带宽会产生很明显的提升作用,再往上效果就可能不那么明显了。推荐:Java进阶学习资料。
2、加大内存
RabbitMq的机制是先将消息放在内存中,然后分批写入硬盘。小批量数据的写入基本上都放在内存中,内存数据量过大时会一边把客户端的数据往内存里写,一边将内存里的陈旧数据往硬盘里写,这样会对速度造成较严重的损耗。适度的增加内存,队列将会更多的消息放在内存中,增加系统的处理速度。
3、使用固态硬盘
机械硬盘的写入速度较慢,处理大量数据时机械硬盘对性能的损耗十分严重。如果要存放1亿条数据,所需要的硬盘大小为100G,建议采用100-500G固态硬盘。再加上消费端在不断的处理数据,一般待处理的消息能够达到千万级别已经相当不容易了
4、增加生产者
服务器可以建立多个连接,单个生产者往往不能充分利用服务器的潜能,建立多个生产者之后,服务器处理能力将会得到充分利用。一般情况下,一个生产者每秒可以传入1000-5000条消息,在1-10这个范围内,每增加一个生产者,处理速度就会相对单生产者增加一倍
5、增加消费者
消费者增多时,出队速度有明显改善。该方案对于出队速度的影响有限,1-10个进程范围内,相对于单进程只有一倍左右的提升,建议线程开2-5个即可,再多可能影响不大。出现该现象的原因可能是服务器带宽或硬件处理能力有限,消费者增加了也没什么用处。因为没有实际环境测试,此条只列为建议,采用前可以多做实验
6、改网络访问为本地访问
该方案在消费端/生产端与RabbitMq服务器部署在同一台电脑时有用,因为省略了网络传输,大大节省了处理时间。如果消费端/生产端与RabbitMq服务器分开部署,该方案就不能使用了。在代码中将IP地址127.0.0.1改为localhost即可。
作者:精诚所至金石为开
blog.csdn.net/smartsteps/article/details/107002567
写在最后
可能有人会问我为什么愿意去花时间帮助大家实现求职梦想,因为我一直坚信时间是可以复制的。我牺牲了自己的大概十个小时写了这片文章,换来的是成千上万的求职者节约几天甚至几周时间浪费在无用的资源上。


上面的这些(算法与数据结构)+(Java多线程学习手册)+(计算机网络顶级教程)等学习资源
片文章,换来的是成千上万的求职者节约几天甚至几周时间浪费在无用的资源上。
[外链图片转存中…(img-Z49PkbZL-1716305710290)]
[外链图片转存中…(img-ebQWHEYo-1716305710290)]
上面的这些(算法与数据结构)+(Java多线程学习手册)+(计算机网络顶级教程)等学习资源















 8560
8560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









