






这里说的是86版五笔输入法,这个版本的五笔输入法是最经典的,输入法软件多,字典资料多,万一某天拆字根时发现老是拆不对可以查字典,也可以查百度,毕竟有些汉字的编码的拆字方式是有点鬼畜的。
本教程真实可用,实际我学五笔只用了两天,第一天的时候我在摸鱼
一些基础的知识我就先省略了
简单的提一下就好
如果是五笔小白要结合其它教程才能学习
首先是键本字,这是要背的,打出键本字的方法是连敲相应的键四次,比如“金”对应键盘上的Q,连敲四次就是“金”的编码
如果想要打出字根本身,即成字字根,编码方式是:字根代码+首笔代码+次笔代码+末笔代码,笔画不足补一空格
如果想要打出横竖撇捺折(分别对应GHTYN)五个笔画本身,敲两下对应的键,再加两个LL,就可以了
“乙”这个字,是字根,但也是笔画,如果用笔画的编码方式,编码就是NNLL,如果把它当作字根处理,那编码就是NN加上空格
还有就是一级简码,也要背。
然后就是进入主题了,以上的都是小虾米,最难的是五笔字根表,复杂的一批,字根口诀也是又拗口又难记,一般来说,熟练掌握五笔字根表需要一个星期时间。
当掌握字根口诀能够熟练打字后,其实那时候人本身已经忘记口诀是什么神马样子了,完全是利用肌肉记忆来打字,如果长期不用五笔,肌肉记忆还会消失,到时候又要回来复习,(这是网上一些五笔学习者的说法,我用的是另外的学习方法,这种情况没有遇见过,下面说明这个方法)
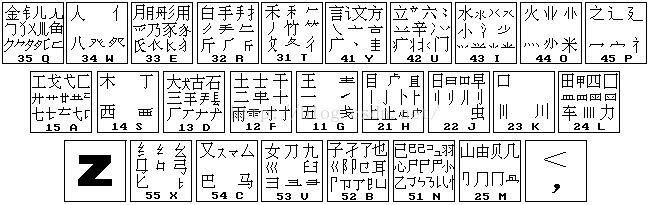
接下来是字根的速记技巧
但是有几个字根要单独记,是四个开口的方框,代码是b、m、n、a,分别朝向上、下、左、右,下面不会提到
代码Q的字根
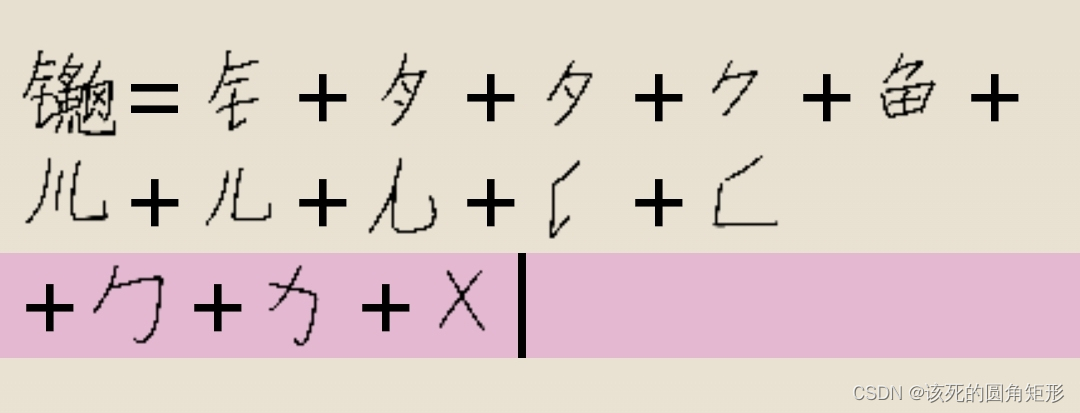
好家伙,写这个字差点把我难受死
代码W的字根:
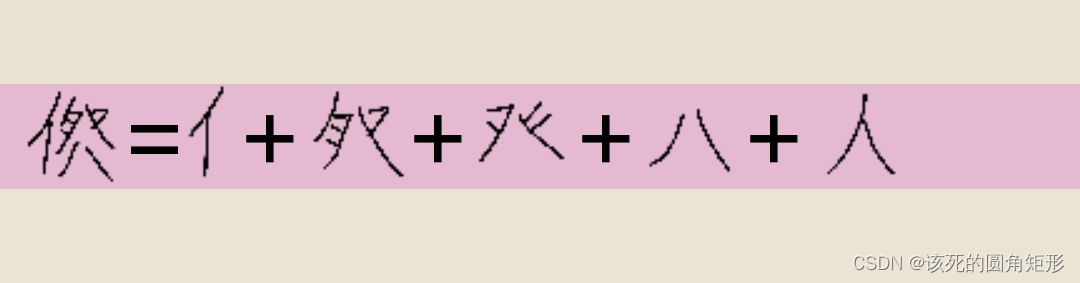
代码E的字根:
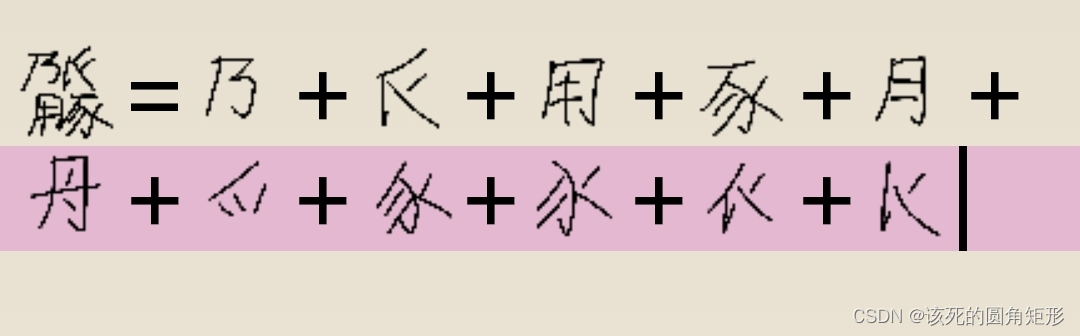
这个组合方式有点令人费解了,也比较容易记错,你需要如下图那样去理解:

当然你可以自己多加几个笔画
以前我也这样干过
后来想想凑合着用
“貌”的五笔比较鬼畜,是EERQ,所以说拆字根不要生搬硬套,要有想象力
代码R的字根:

这里没有将“白”组合进去,因为那是要单独记忆的键本字
没有组合进去字根“两撇",因为那是末笔识别码,要单独记
以下都尽量不会组合进去类似的字根
代码T的字根: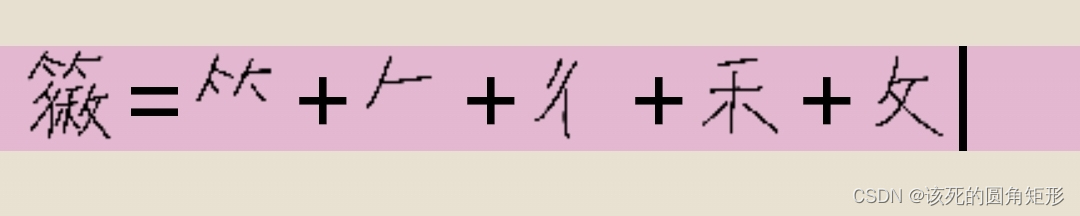
这里少了一个“竹”,还有一个笔画撇,不过,把竹字头的下面两点稍微变形不就是“竹”字了吗!
至于撇,记忆五笔字根末笔识别码时就顺手记忆了
代码Y的字根:
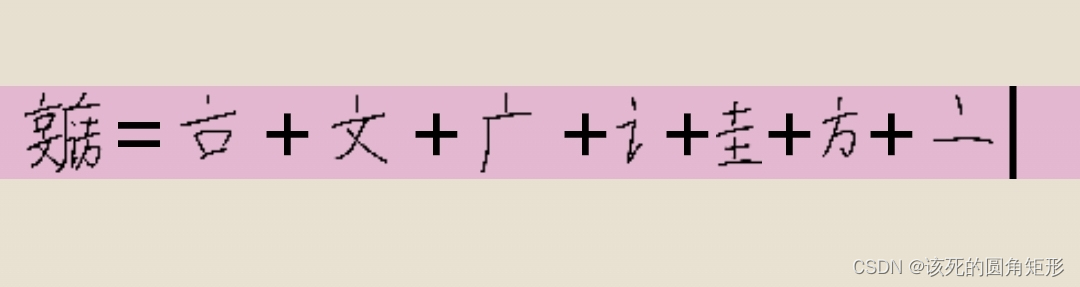
代码U的字根:
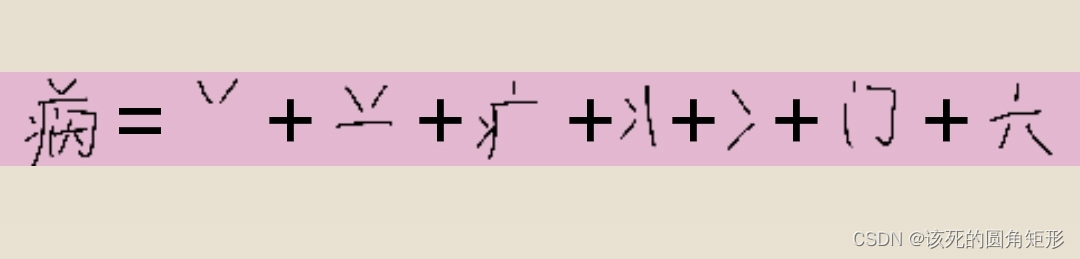
这里少了一个字根“辛”
因为空间安不下
代码i的字根:
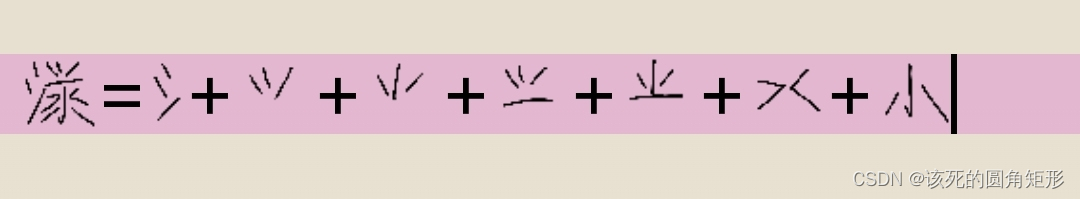
代码O的字根:
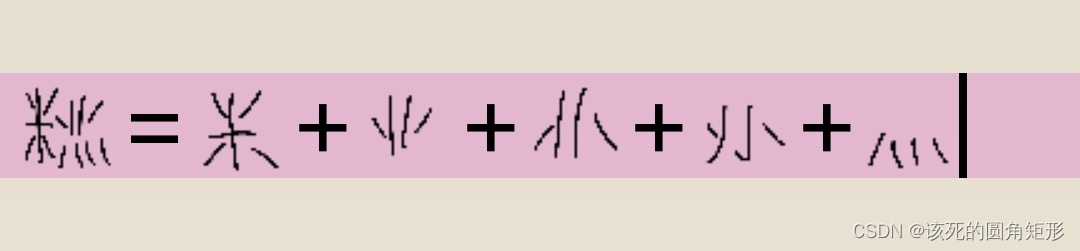
代码P的字根:
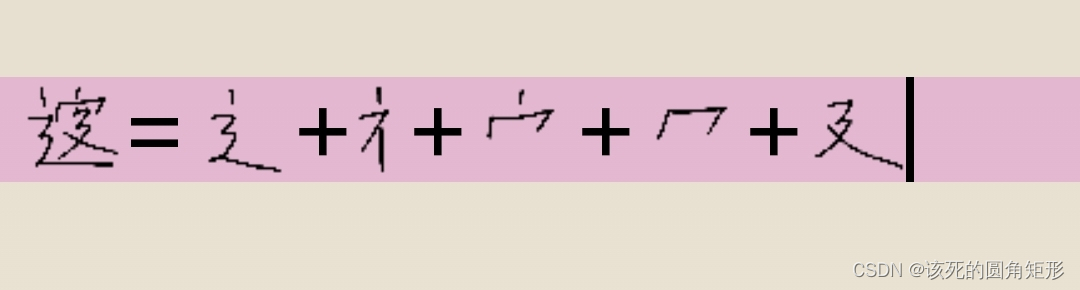
代码A的字根:
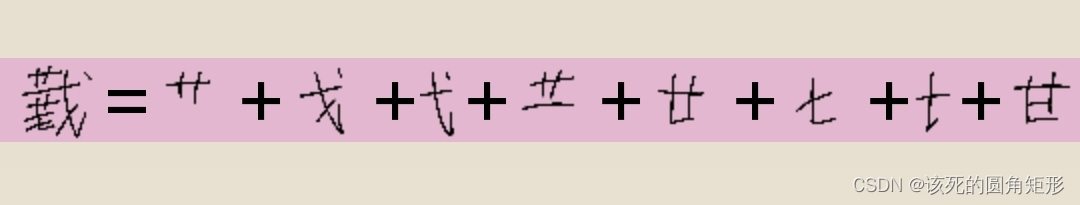
代码S的字根:
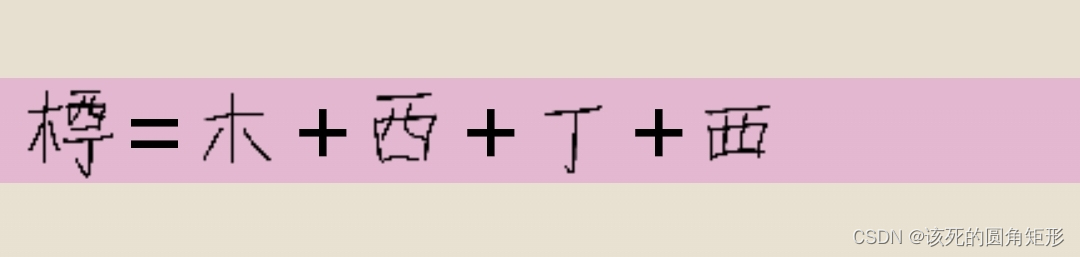
代码D的字根:

代码F的字根:
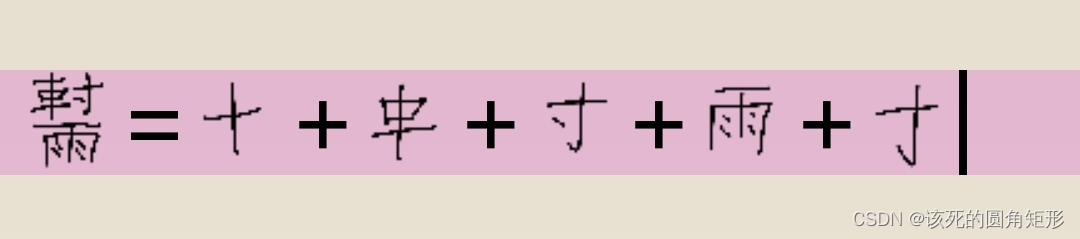
代码G的字根:
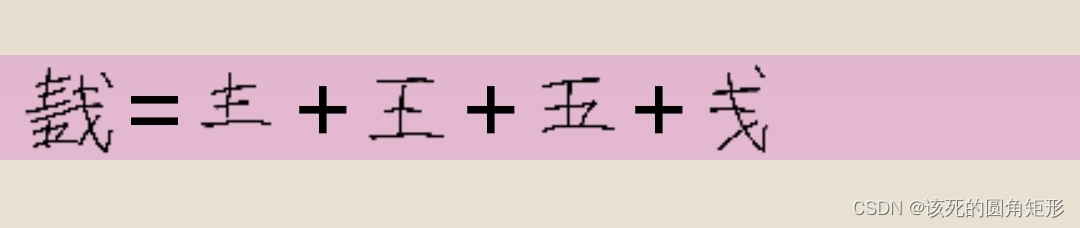
代码H的字根:
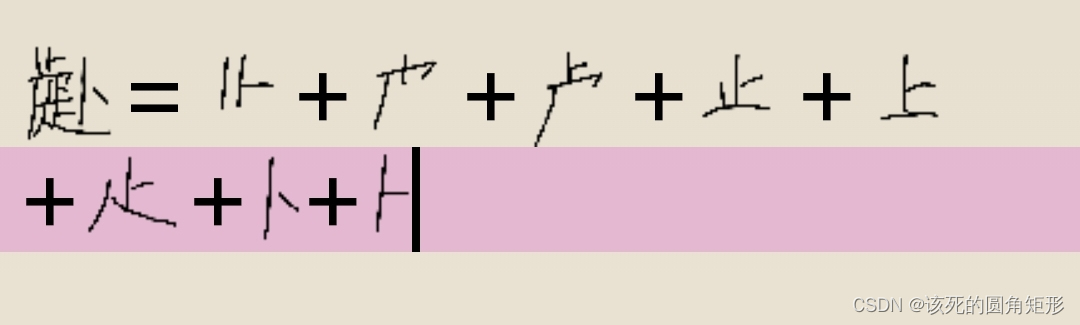
代码J的字根:
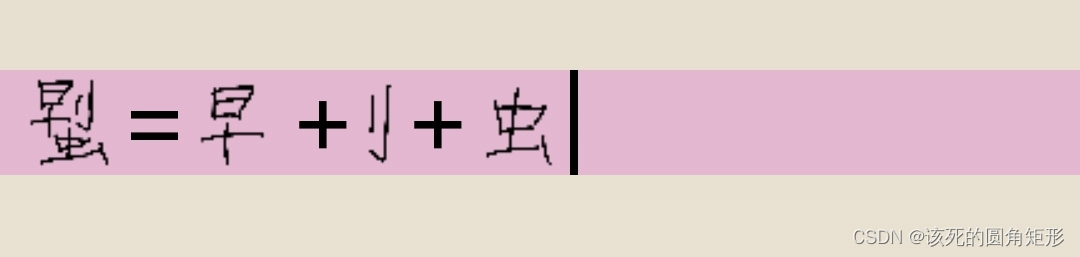
代码K的字根:
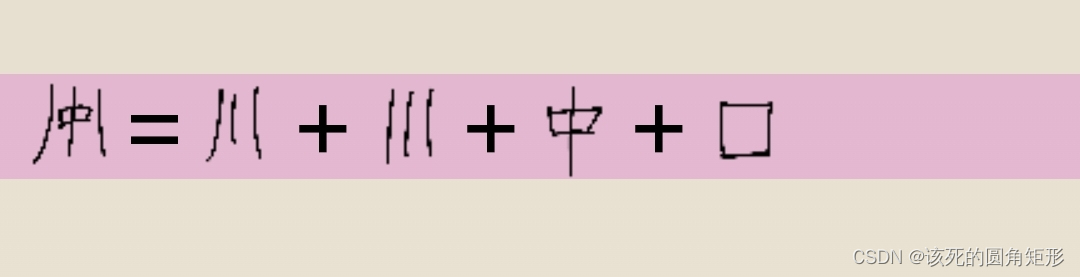
这个键的字根比较少
就把键本字凑了进去
代码L的字根:
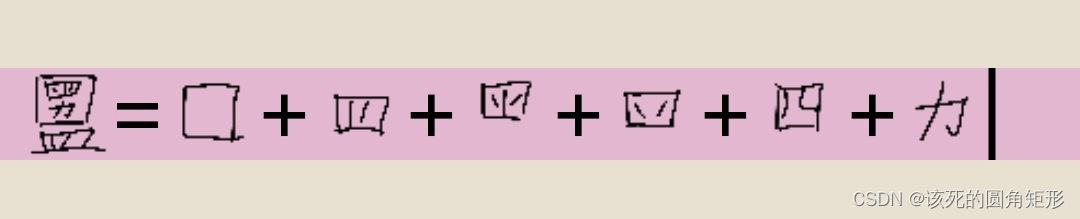
这里少了个“车”,因为空间不足
但如果你有强迫症,可以把它加上去
代码X的字根: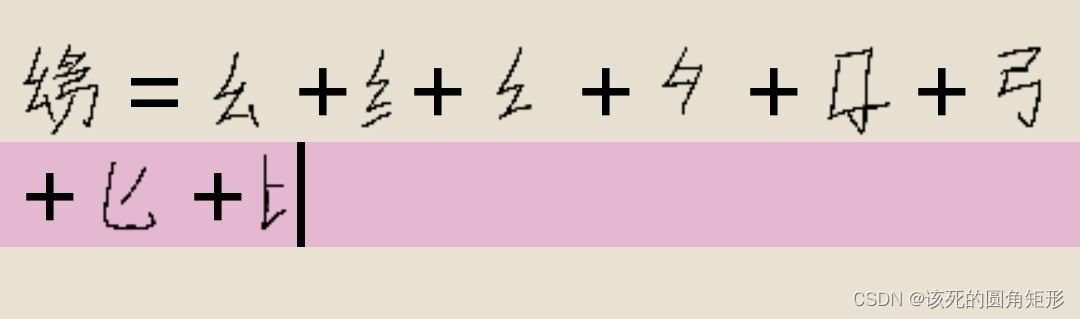
不包含“刀”这个字根,要注意
代码C的字根:
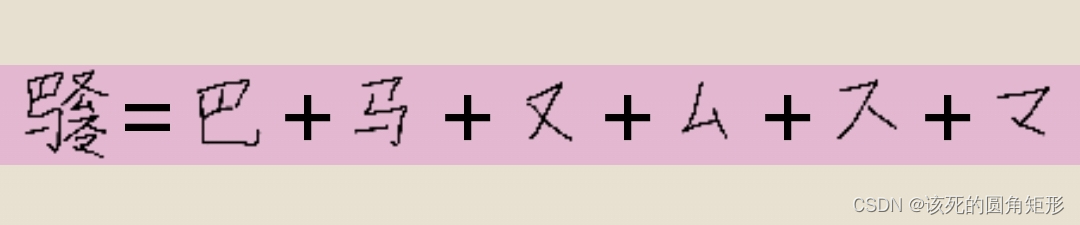
代码V的字根:
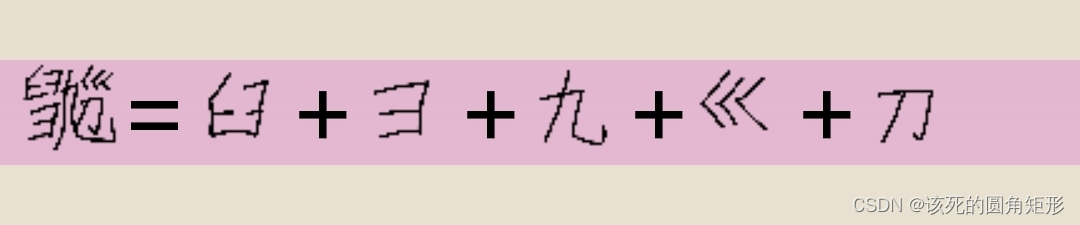
代码B的字根:
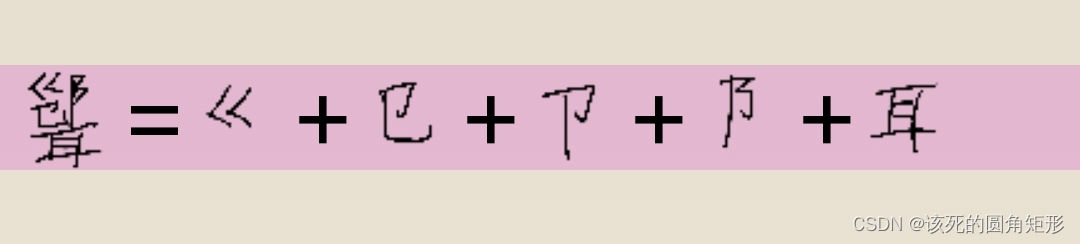
代码N的字根:
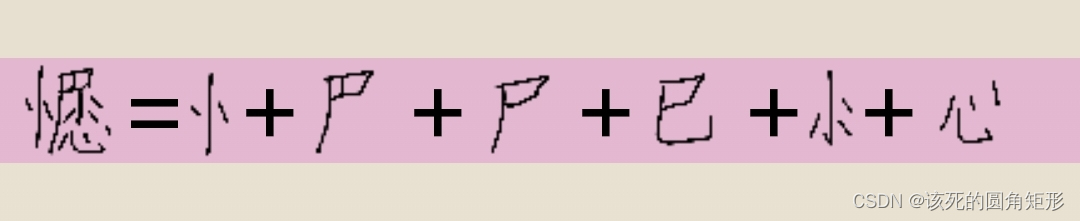
这里少了一个字根“己”,把它看成键本字的“已”就可以了
代码M的字根:
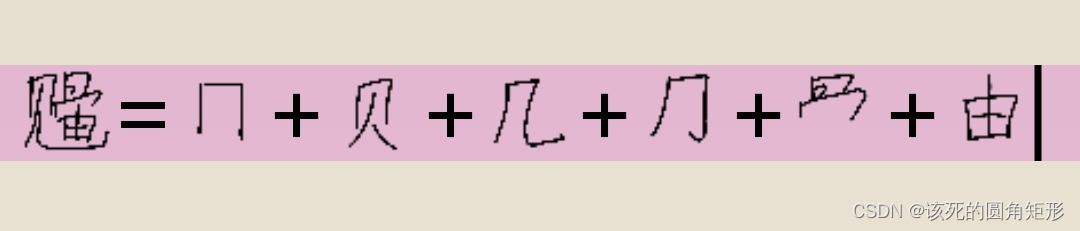















 1471
1471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









