






Pandas入门
进入已创建环境中的jupyter notebook
首先载入数据
任务一:导入numpy和pandas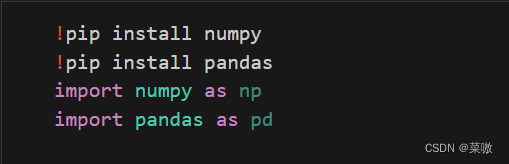
任务二:载入数据 (1)相对路径载入数据 (2)绝对路径载入数据
 任务三:每1000行为一个数据模块,逐块读取
任务三:每1000行为一个数据模块,逐块读取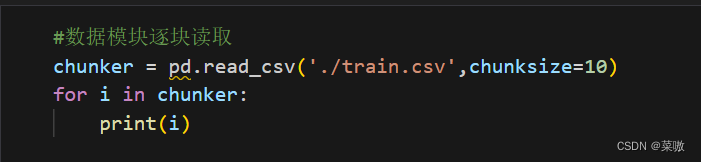
任务四:将表头改为中文,索引改为乘客ID

df=pd.read_csv('train.csv',names=['乘客ID','是否幸存'……],index_col='乘客ID',header=0)
任务五:展示部分数据
前十行:df.head(10)
后15行:df.tail(15)
判断数据是否为空,为空返回true,其余地方返回false
df.isnull().head(5)
任务六:保存数据
将加载并做出改变的数据,在工作目录下保存一个新文件train_Chinese.csv
注意:不同的操作系统保存下来可能会有乱码,可以加入encording='GBK'或者'encording='utf-8''
df.to_csv('train_chinese.csv')
pandas基础
查看DateFrame数据的每列的名称:df.columns
查看“Cabin"这列的所有值:df['Name'].head(3)或df.Name.head(3)
删除多余列:del test1['a']
隐藏列元素:df.drop(['PassengerId','Name','Age','Ticket'],axis=1).head(3)
筛选年龄在10岁以下的:df[df['Age']<10]
将midage的数据中第100行的"Pclass"和"Sex"的数据显示出来:midage.loc[[100],['Pclass','Sex']](loc定位方式)(iloc索引方式)
根据c列升序排列:frame.sort_values(by='c',ascending=True)
行索引升序:frame.sort_index()
列索引升序:frame.sort_index(axis=1)
列索引降序:frame.sort_index(axis=1,ascending=False)
两列同时降序:frame.sort_values(by=['a','c'],ascending=False)
调用describe函数,观察frame2的数据基本信息:
frame2.describe()
"'count(样本数据大小),mean(样本数据的平均值),std(样本数据的标准差),min(样本数据的最小值),25%(样本数据25%时候的值),50%(样本数据50%时候的值),75%(样本数据75%时候的值),max(样本数据的最大值)"'
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









