






介绍
欢迎来到雲闪世界。互补产品推荐 (CPR) 对于电子商务平台的成功越来越重要。CPR 旨在提供最相关的产品,这些产品经常一起购买。手机和手机壳经常一起购买。购买网球拍时通常会购买网球。购买笔记本电脑后会购买鼠标。在本文中,我们将讨论亚马逊如何将 CPR 作为产品到产品推荐问题解决:
给定一个“查询”产品,目标是推荐与“查询”产品互补的相关且多样化的产品,以便可以一起购买以满足共同意图。

互补产品推荐场景
预测此类互补产品并非易事。让我们通过一个简单的示例来了解解决此问题时面临的挑战。假设网球拍作为“查询产品”,平台会显示三个相关产品列表。
-
列表 1 包括另外三款类似的网球拍。
-
列表 2 包含三个网球。
-
清单 3 包含一个网球、一个球拍套和一条头带。
通常,列表 1 提供类似的产品,不太可能一起购买。列表 2 和列表 3 提供互补商品。但是,列表 3 是更佳的选择,因为它提供多种产品,共同满足用户对网球装备的更广泛需求。此示例强调,良好的互补推荐系统应考虑相关性和多样性,以满足用户的期望。
本文试图解决以下三个挑战——
-
互补关系是不对称的,它们不是基于相似性测量的。手机壳可以是与手机一起购买的互补产品。反过来则不然。仅仅使用基于相似性的技术来解决问题并不是正确的方法。
-
互补性推荐需要考虑多样性。向用户推荐一组多样化的产品(例如网球、头带和球拍套)比推荐三种不同类型的网球更有意义。
-
冷启动商品会降低补充推荐的效果。冷启动商品是指平台上新推出且互动很少的商品。
文献综述
现有的推荐系统方法主要关注使用矩阵分解、协同过滤或神经网络的用户-商品关系,但只关注一些目标商品-商品关系。这些方法大多局限于可替代(或类似)的产品关系,而不是互补推荐。虽然最近基于行为型产品图的方法试图增强互补推荐,但它们主要区分替代品和互补品,而没有解决我们讨论的关键挑战。这些技术使用用户的共同购买和共同浏览行为交互数据进行训练。
什么是共同购买数据?
共同购买商品是指用户在平台上一起购买的一对商品。共同浏览商品是指在浏览会话中一起浏览的一对商品。先看后买是指用户先浏览了第一件商品,然后购买了第二件商品。这些行为为互补和可替代的产品关系提供了宝贵的见解。共同购买数据通常用于推荐互补产品,鼓励用户将相关商品添加到购物车中。我们将在以下部分讨论如何清理共同购买数据以识别和了解互补产品关系。
打破普遍的假设
在论文中,作者强调了传统使用共同购买和共同浏览数据来建模互补和替代产品关系的问题。他们认为,共同购买和共同浏览记录代表不同的产品关系(分别是互补和替代)的普遍假设是不准确的。共同购买模式代表互补关系,更为复杂,并且跨不同类别重叠。
本文提出了两个主要观察结果:
-
共同购买和共同浏览数据之间的重叠:作者分析了两年的数据,发现共同购买和共同浏览记录之间的重叠度超过 20%。这意味着经常共同浏览的产品也是共同购买的,模糊了互补产品和替代产品之间的区别。这种多类信号的污染使模型更难区分这些关系。例如,客户在同一笔交易中浏览并购买了两件夹克。这并不意味着这对商品是互补的。
-
不同产品类别之间的差异:共同购买和共同浏览数据之间的重叠度因产品类别而异。例如,在服装等类别中,客户更有可能共同购买他们一起浏览过的产品(例如两件不同的衬衫)。相比之下,在电子产品等类别中,重叠度较低,因为客户不太可能购买多件类似商品(例如两台不同的电视)。
问题表述
给定产品目录特征C(产品标题、描述、产品类型等详细信息)和客户行为数据B,目标是构建推荐模型M。该模型采用具有其产品类型和指定多样性程度M的查询产品,并执行两项任务:iw_iK
-
预测互补产品类型:首先根据查询产品类型M预测不同的互补产品类型。Kw_i
-
生成互补物品:从每个预测的互补产品类型M生成K物品集S_{wk}。
该模型的目标是最大化生成的互补商品与查询商品共同购买的概率,从而有效地优化基于共同购买行为的推荐。
数据准备
作者构建了基于行为的产品图 (BPG),以根据客户行为对产品关系进行建模。BPG 使用三种类型的行为关系构建:共同购买 ( B_{cp})、共同浏览 ( B_{cv})和浏览后购买 ( B_{pv})。这些行为表示为图中节点所表示的产品之间的边,有助于捕捉客户如何与各种产品互动。
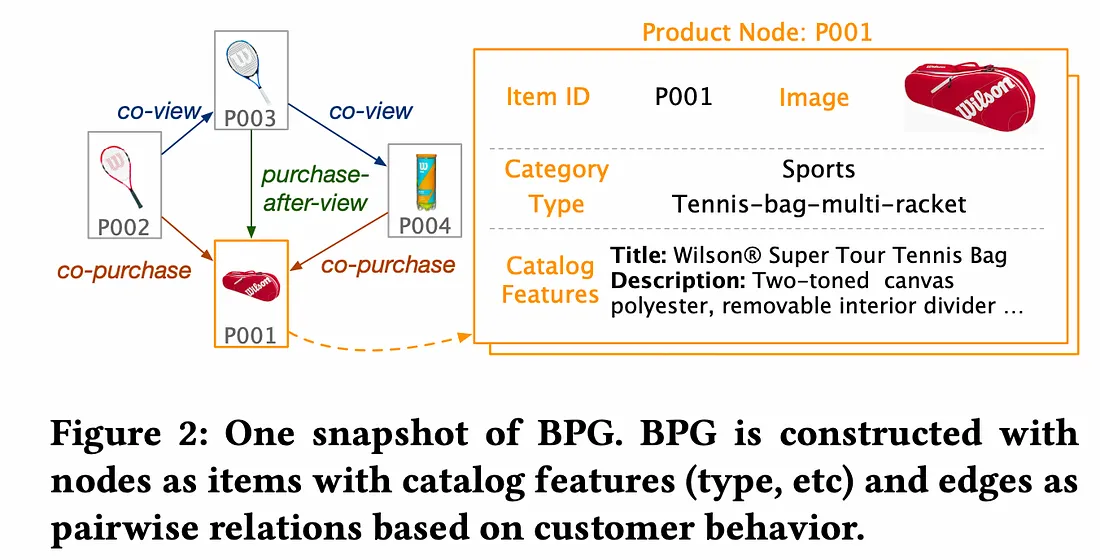
基于行为的产品图谱
目标是准备一个包含来自共同购买数据的互补商品对的稳健数据集。为了完善共同购买数据,作者使用 Amazon Mechanical Turk (MTurk) 进行了注释实验,以确定共同浏览、共同购买和浏览后购买数据中的最佳标记方案。注释者被要求将商品对分类为可替代、互补或不相关。他们发现,以下子图B_{cp} -(B_{cv} U B_{pv})包含既不是共同浏览也不是浏览后购买数据集一部分的共同购买对,它给出了最准确的互补信号。
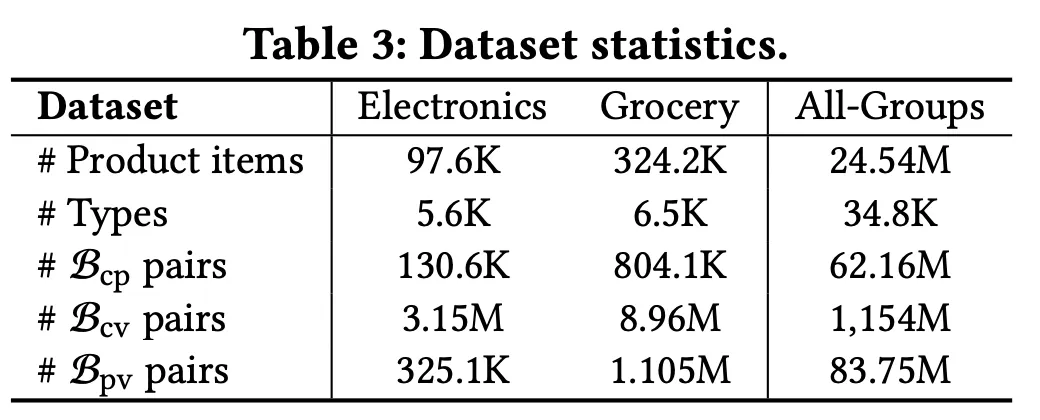
数据集统计
此外,他们还观察到互补关系通常跨越多个产品类别(例如,网球拍可能有网球衫或鞋子等互补品)。为了解决这个问题,他们删除了以前研究中使用的类别限制,并构建了一个B_{cp} -(B_{cv} U B_{pv})涵盖所有产品类型的通用数据集。他们准备了一个包含 2454 万个项目的数据集,涵盖所有产品组的 34.8K 个产品类型。他们构建的 BPG 有 6216 万个共同购买商品对、8375 万个浏览后购买商品对和超过十亿个共同浏览商品对。此外,他们还准备了两个属于电子产品和杂货类别的数据集。详细信息如上表所示。
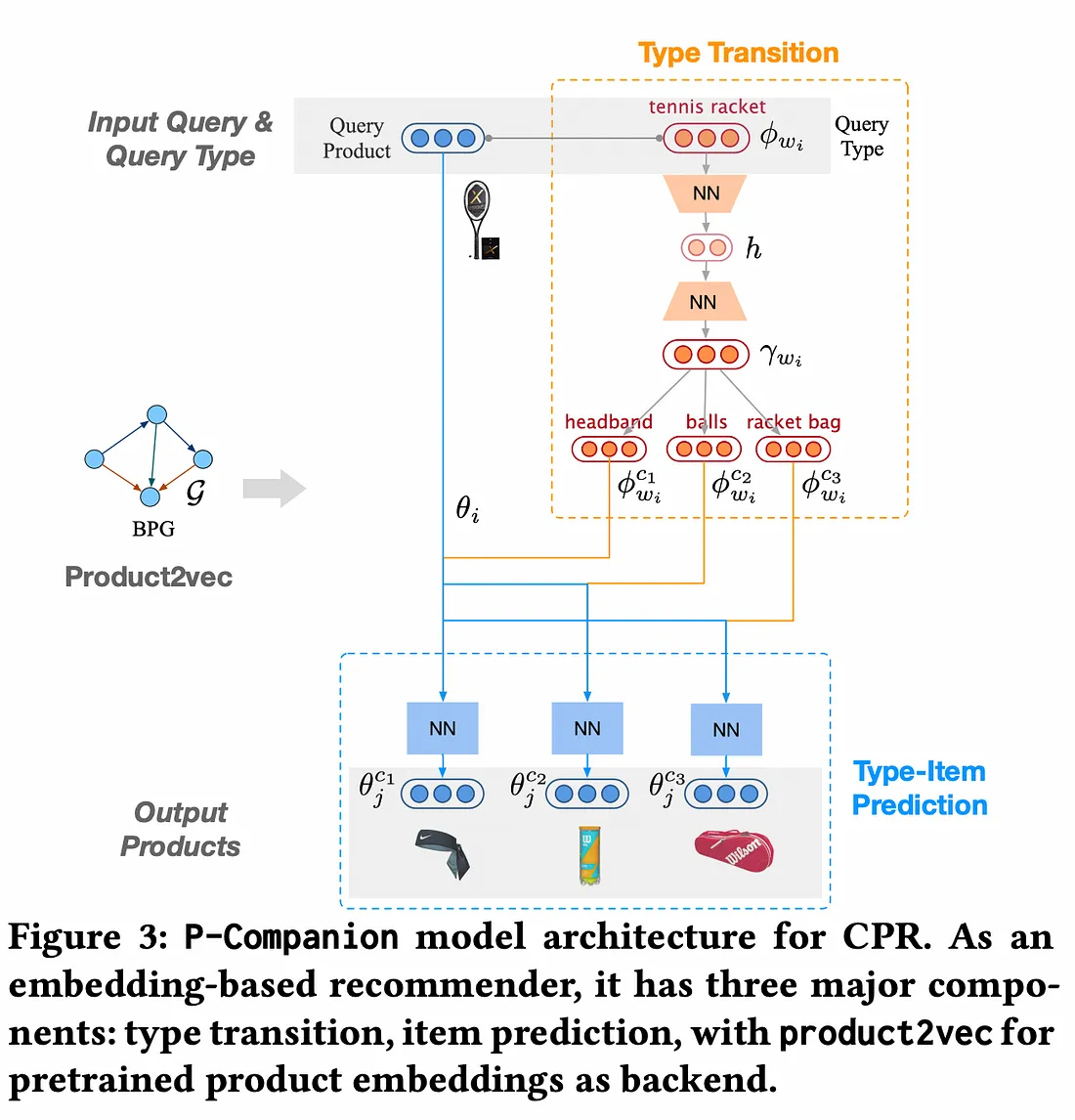
模型架构
P-Companion 是一个多任务学习框架,它联合学习与每种预测产品类型相关的互补产品类型和互补项目。该模型有三个主要组成部分。让我们详细讨论这三个部分。
Product2Vec
Product2Vec 是一种基于图注意力网络的表示学习模型。它使用 BPG 中的项目描述、历史交互数据和图结构来学习产品嵌入。假设学习到的高度相似产品的嵌入将彼此接近,而互补产品则反之亦然。BPG 子图中连接的产品(B_{cv} ∩ B_{pv}) — B_{cp}很可能相似,并用作训练模型的正对。这些产品既是共同浏览的,也是浏览后购买的,但不是共同购买的。同样,B_{cp} -(B_{cv} U B_{pv})(包含互补且因此不相似的产品的子图)被视为负对。初始嵌入通过前馈层FFN并转换为p- 维嵌入θ。
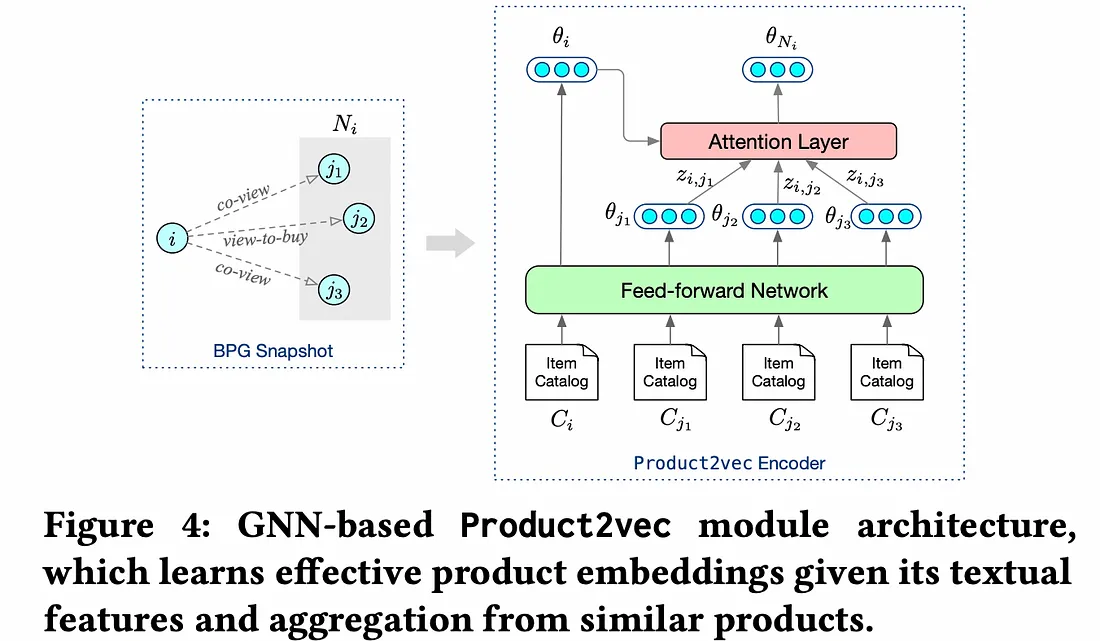
Product2Vec
对于每个项目i和嵌入θ_i,使用 BPG 中的相似子图,我们获取包含项目的(B_{cv} ∩ B_{pv}) — B_{cp}局部邻域。标签表示它们是正对。是邻近项目的嵌入。使用 softmax 激活计算注意向量以获得加权邻域聚合嵌入。N_i{j}y_{i,N_i} = 1{θ_j}z_{ij}θ_{N_i}
z_{ij} = softmax((θ_i)^T θ_j) θ_{N_i} = ∑z_{ij} θ_j
Nˆ_i类似地,我们从互补子图中提取局部邻域B_{cp} -(B_{cv} U B_{pv})。这里,y_{i, Nˆ_i} = 0。利用图注意层,我们得到一个加权邻域聚合嵌入θ_{Nˆ_i}。
该模型的目标是学习嵌入,θ使得θ_i和在嵌入空间中θ_{N_i}投影到彼此靠近,并且θ_i和θ_{Nˆ_i}在嵌入空间中投影到彼此远离。我们可以优化铰链损失来学习模型权重,FNN。
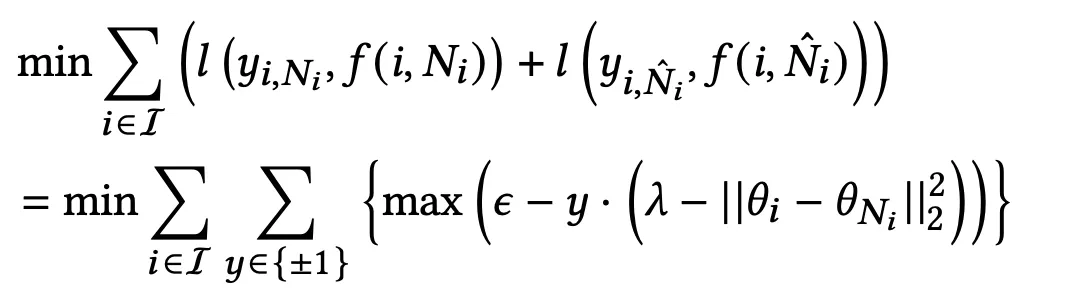
用于 Product2Vec 训练的 Hinge Loss 函数
θ_i该方程试图保持和之间的距离θ_{N_i}小于以及和λ-ε之间的距离大于。θ_iθ_{Nˆ_i}λ+ε
学习到的嵌入可以用作项目的预训练表示。这在很大程度上解决了冷启动项目的问题。我们可以仅使用文本描述来获得新项目的嵌入。
互补型转变
如前所述,我们有成对的项目,(i, j)。w_i和w_j分别是产品类型。y_{ij}=±1是根据它们是否互补而确定的标签。P-Companion 的互补类型转换组件是一个在给定查询产品类型的情况下执行互补类型预测任务的模型。该组件对查询产品类型和互补产品类型之间的不对称关系进行建模。对于产品类型w,我们根据其作为查询或互补类型的上下文位置,为其分配两个可学习的嵌入φ_w和φ^c_w。对于一对产品类型w_i和w_j,使用编码器-解码器架构将查询类型嵌入转换φ_{w_i}为其互补基向量γ_{w_i}。γ_{w_i}用于预测互补产品类型。
使用铰链损失函数来优化预测的互补产品类型γ_{w_i}和地面真实预测的互补产品类型之间的关系φ^c_{w_j}。
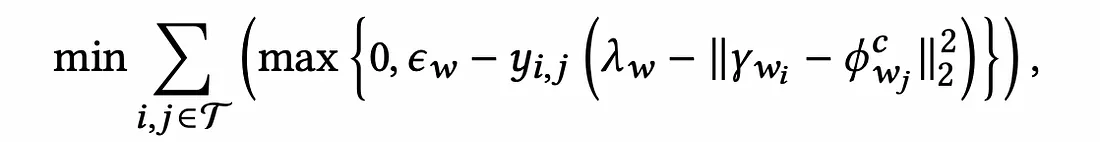
用于互补类型转换模型训练的 Hinge Loss 函数
该方程试图在时保持γ_{w_i}和之间的距离φ^c_{w_j}小于,而在时保持和之间的距离大于。λ_w-ε_wy_{i,j} = 1γ_{w_i}φ^c_{w_j}λ_w+ε_wy_{i,j} = -1
P-Companion 模型架构
互补项目预测
互补商品预测模型根据从互补类型转换模型获得的产品类型进行产品推荐。该模型将查询产品类型生成的互补产品类型嵌入γ_{w_i}和基本事实互补产品类型嵌入φ^c_{w_c}作为输入,并将商品嵌入转换θ_i为互补商品子空间嵌入θ^{w_c}_i。
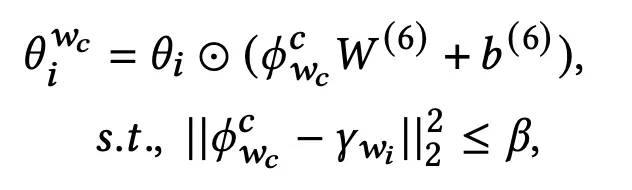
将查询项嵌入转换为不同类型的互补项嵌入
β是相似度阈值,用于确定将使用哪些互补类型来推荐互补项目。或者,我们也可以明确设置每个查询类型需要多少个互补类型。这会导致我们的推荐多样化。根据我们的设计选择,我们有多个互补类型嵌入{φ^c_{w_c}},并且原始项目嵌入θ_i转换为互补项目目标{θ^{w_c}_i}。
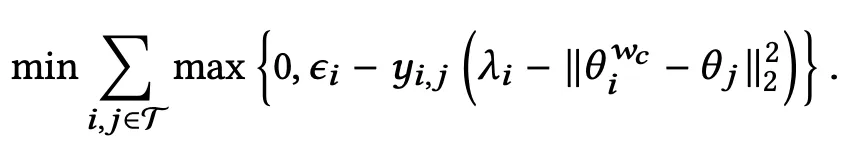
用于互补商品预测模型训练的 Hinge Loss 函数
再次,我们使用铰链损失来优化该组件的权重。该损失函数试图确保当 时θ^{w_c}_i和之间的距离θ_j小于,当 时大于。λ_i-ε_iy_{i,j} = 1λ_i_+_iy_{i,j} = -1
实现细节
Product2Vec 已作为预训练任务单独训练。我们可以使用 Product2Vec 中的嵌入来联合训练互补类型转换和互补项目预测模型。可以使用以下组合损失函数。
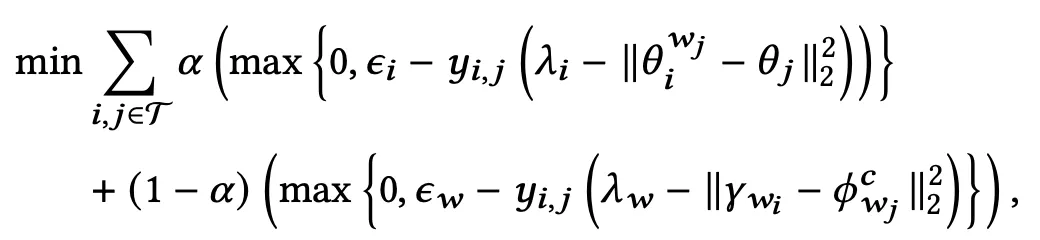
联合训练
超参数
作者将产品嵌入维度保持在 128,将产品类型嵌入维度保持在 64。距离超参数λ和ε都设置为 1。
推理
i在推理过程中,给定产品类型为 的商品w_i,我们将从 Product2Vec 中获取商品嵌入θ_i和查询产品类型嵌入φ_{w_i}。利用这些,互补类型转换可以预测前 k 个互补产品类型。互补产品预测将商品嵌入和互补产品类型嵌入{w^{c_1}_i, w^{c_2}_i, …, w^{c_k}_i}作为输入,以生成互补产品。θ_i{φ^{c_1}_{w_i}, φ^{c_2}_{w_i}, …, φ^{c_k}_{w_i}}{θ_j}
评估
离线评估
排名指标 Hit@K 用于在测试共同购买数据上评估模型。作者将 P-Companion 与 Sceptre 和 JOIE 进行了比较,发现 P-companion 在不同类别中的表现优于基线模型。它在冷启动项目上表现更好。
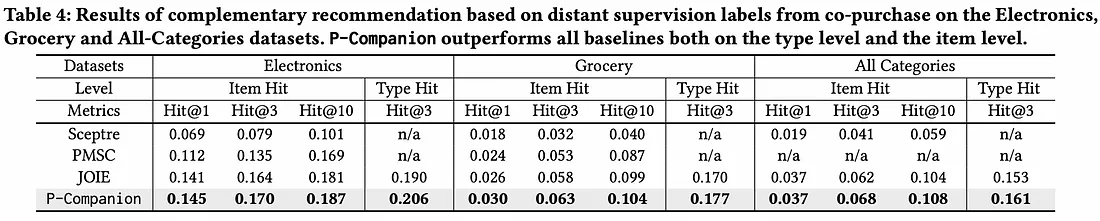
使用 Hit@K 指标进行离线评估
为了评估多样性对推荐的影响,作者通过分析一组常见查询产品的前 60 条推荐来测试 P-Companion。与基线不同,P-Companion 显示来自多个预测互补产品类型的项目以确保多样性。该模型在四种配置下进行了测试:推荐来自前 1 种类型的 60 个项目,将推荐均匀地分为前 3 种、前 5 种和前 6 种类型。这种方法使 P-Companion 能够提供比传统方法更平衡、更多样化的推荐。当模型在电子产品和杂货数据集中推荐更多产品类型时,Hit@K 会增加。
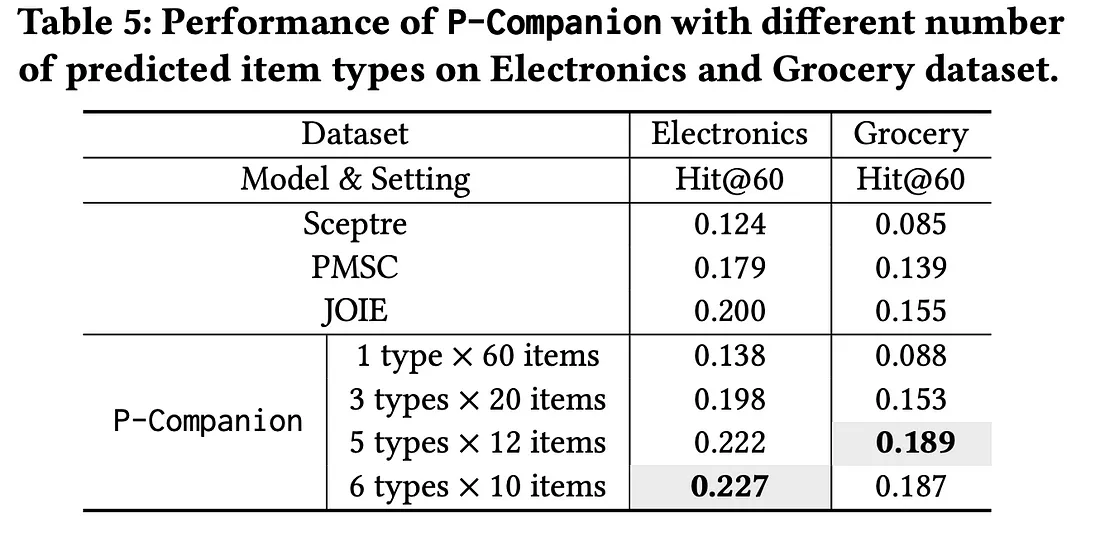
多样性的极致体现
在线评估
通过进行 A/B 测试实验,在生产环境中评估了 P-Companion 的性能。客户会话被随机拆分,对照组收到基于传统共同购买数据集的建议,实验组收到来自 P-Companion 的建议。实验进行了两周,结果显示产品销售额提高了 0.23%,利润提高了 0.18%。
这些发现表明,P-Companion 在推荐中同时考虑了相关性和多样性,通过帮助客户更有效地发现潜在需求,显著提升了客户购物体验。
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









