






日志文件分析
文章目录
一、需求及需求分析
1.1 介绍
本项目完成时间为2025年4月.
1.2 需求
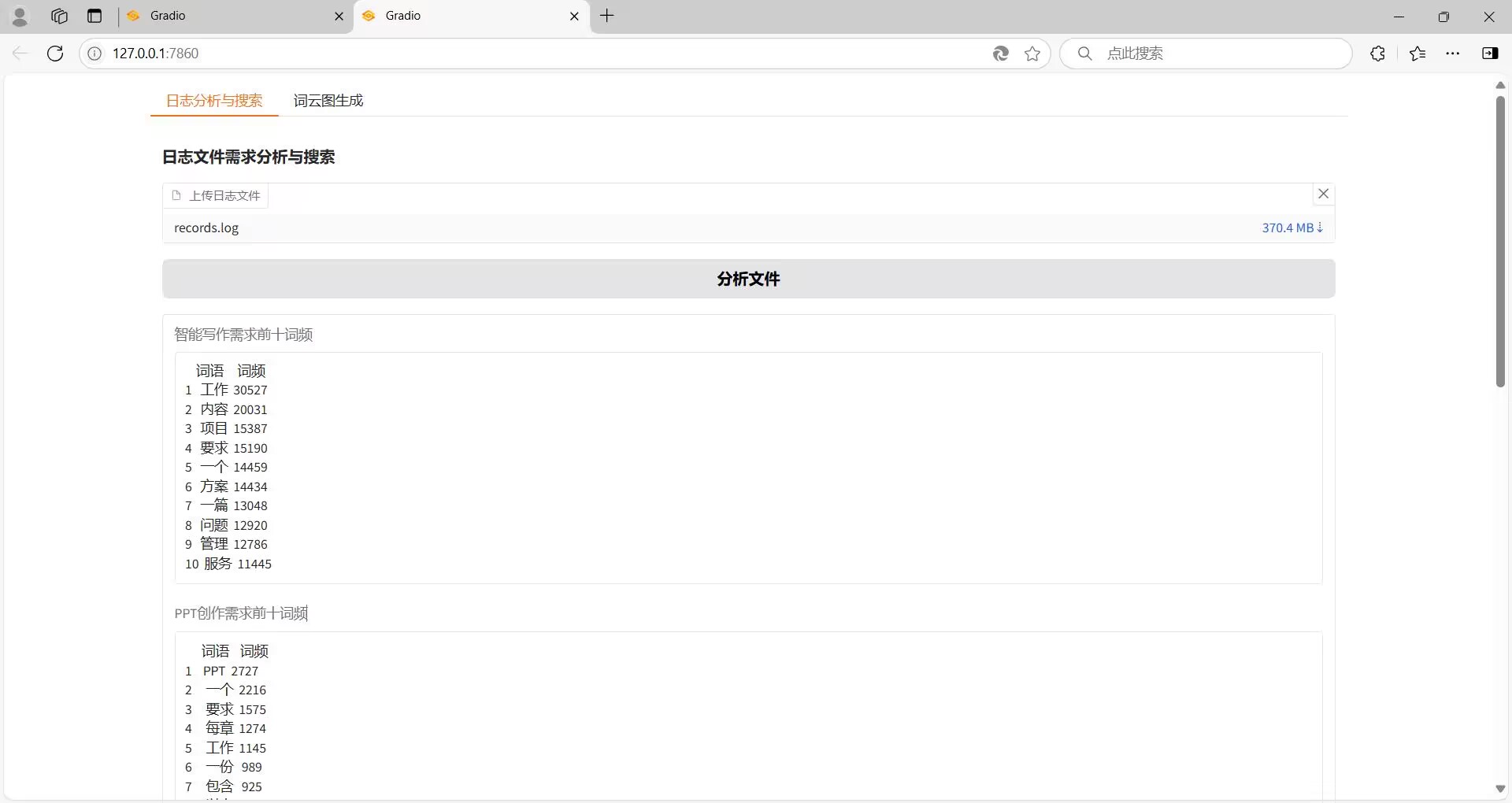
1、分析所给的日志文件,使用正则表达式提取“智能写作用户需求”和“PPT创作需求”,将提取到的需求保存到一个Excel表中,分别使用两个Sheet存储,一个Sheet名称为智能写作需求,另一个为PPT创作需求;
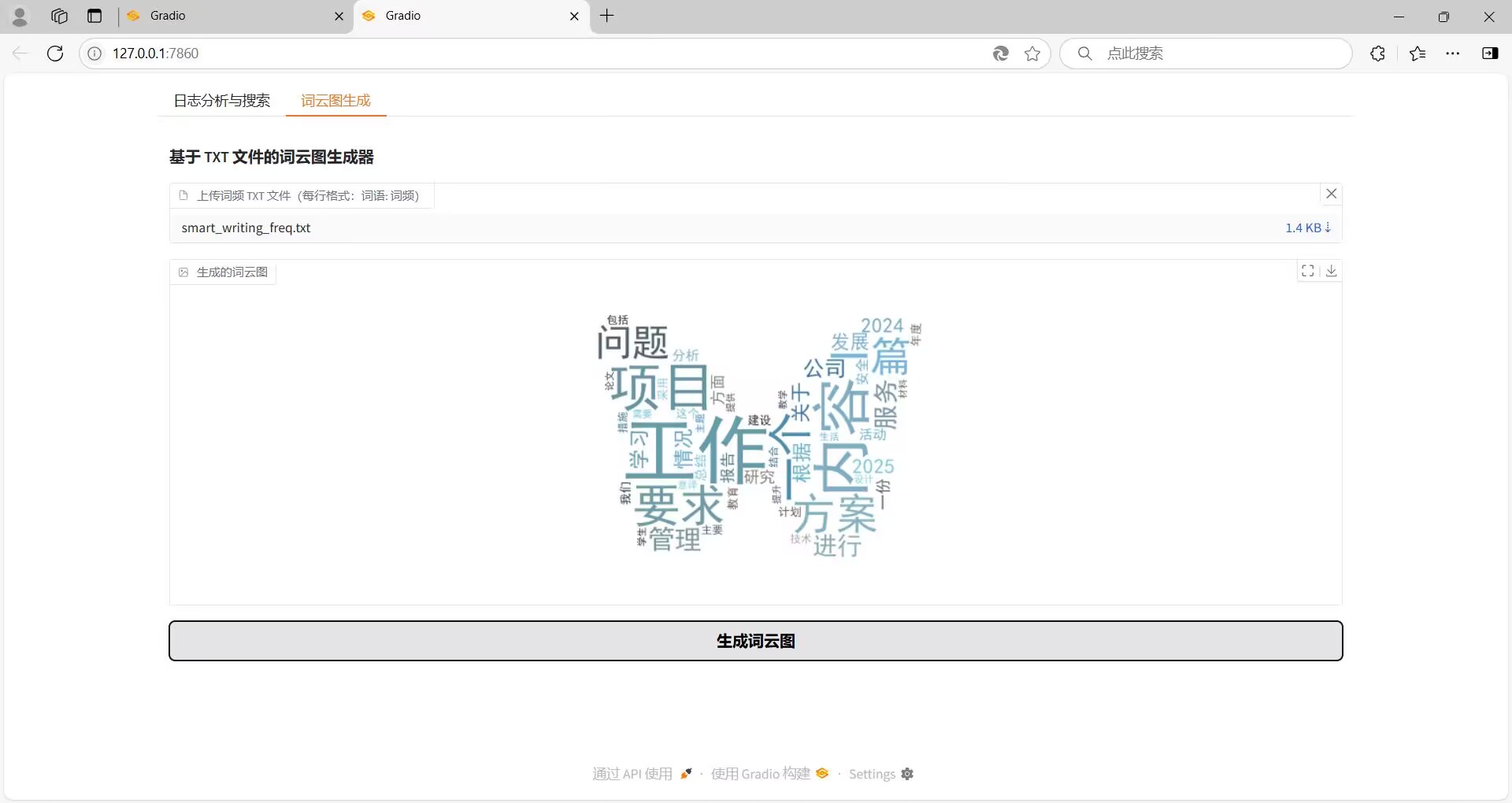
2、对获得的Excel表中的数据分别进行文本分析,如统计词频、绘制词云图,以及其他分析;
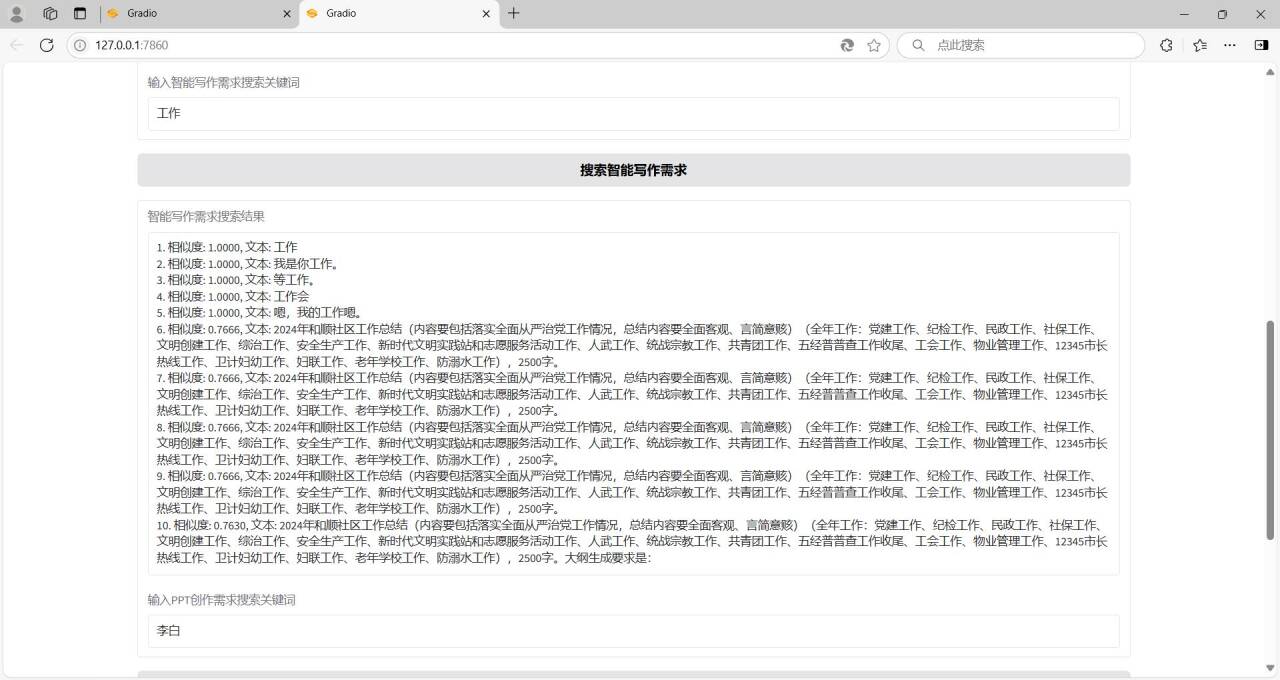
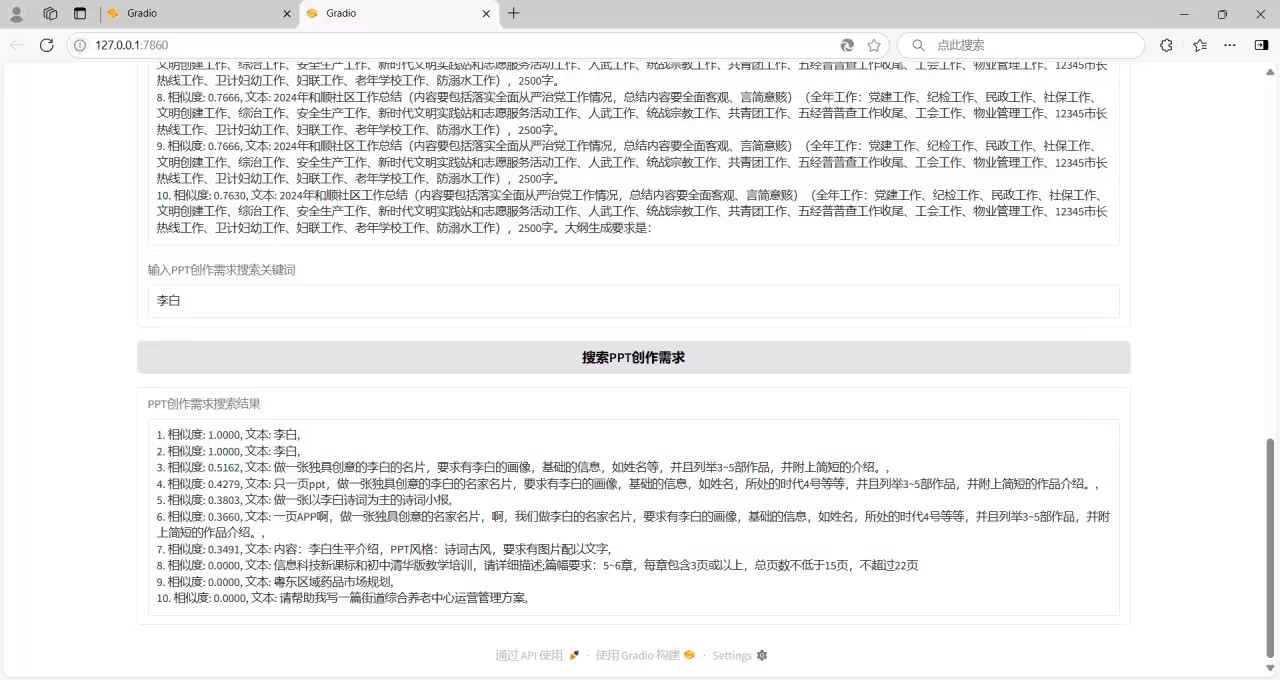
3、构建文本搜索功能,输入关键字,能够在处理好的数据中进行文本相似性搜索,返回相似性较大的前10条文本;
4、编写简单的GUI界面(建议使用streamlit或gradio)来展示分析和搜索的结果。
1.3 需求分析
1、所给日志文件中有一定规律,每一条日志的规律大致为:{时间}|{日志级别}|{具体代码行信息} - {用户需求},根据此规律可提取用户的写作需求;
2、用户需求存在两种:(1)纯明文的,这是智能写作用户需求;(2)加密的,通常以OloeBh开头,这包含了PPT创作需求。根据此规律可区分智能写作需求和PPT创作需求;
3、PPT写作需求是加密的,可以使用提供的解密脚本对其进行解密,解密后的内容大致为:[{“role”:“system”,“content”:“xxx”},{“role”:“system”,“content”:“xxx”},{“role”:“user”,“content”:“xxx”}],只需要关注该列表中最后一个字典中的content中的内容即可;
4、上述content有多种格式的字段组成:主要提取以下两种格式的用户需求即可:
(1)“我的要求是:{用户需求}。\n根据主题和参考资料完成内容分析”;
(2)“我要制作一份{用户需求}PPT的大纲,输出大纲格式严格按照以下”。
5、上述处理均依赖于正则表达式,请深入理解正则表达式,并借助python的re表达式完成匹配,也可使用AI来生成相关正则表达式;
6、获取数据后,应了解NLP领域中对文本的常用分析方法和相关工具,如分词、词频分析、词云等,常用工具有jieba、matplotlib和wordcloud等;
7、了解词向量的相关知识、欧氏距离和余弦夹角相关的东西,利用词向量计算文本相似度,完成文本搜索功能。
1.3 依赖
所需的第三方库都在requirements.txt文件里。
二、项目实现截图及gitee仓库
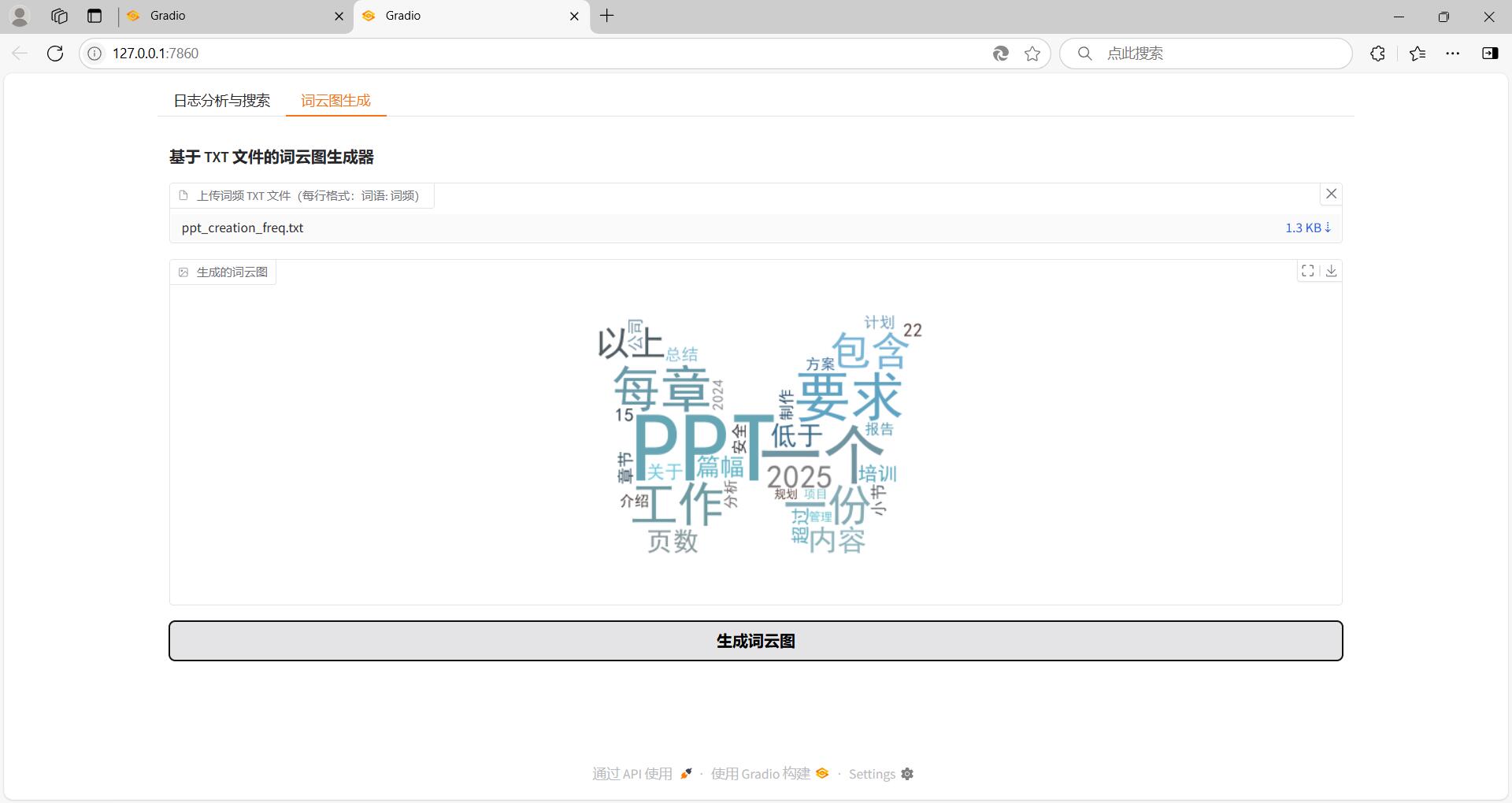
2.1 Gradio界面
界面整体分为两部分,日志文件分析与搜索和词云图模块
词云图形状可以通过更改mask图片进行修改
2.2 代码结构
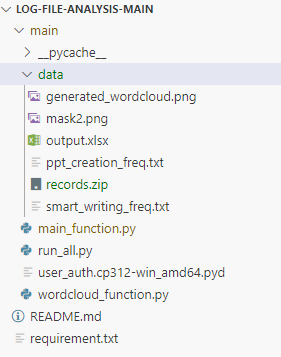
说明:user_auth.cp312-win_amd64.pyd为解密文件,对应python3.12,在record.zip文件中有日志文件和解密文件,按照代码结构放到正确位置,否则,程序可能出现路径问题。
我的本意是全部放到gitee仓库方便大家取用,但是git最大推送100M的文件,git-lfs可以推送大文件,但是收费,所以大家可以从百度网盘地址获取records.zip文件。
records.zip 链接: https://pan.baidu.com/s/1HrVIVF_olDKFIQt3Lh2jkA?pwd=2025 提取码: 2025
2.3 Gitee仓库源码
https://gitee.com/zpyszby/log-file-analysis.git
三、代码展示
3.1 main_function.py
日志分析和文本搜索部分:
import re
import user_auth
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import gradio as gr
import os
import jieba
# 从日志文件中提取需求并保存到 Excel
def extract_demands_from_log(log_path):
try:
with open(log_path, 'r', encoding='utf-8') as file:
log_content = file.read()
except FileNotFoundError:
print(f"未找到文件: {log_path}")
return None
# 修改后的正则表达式,去除多余空格,并使用 re.DOTALL 多行匹配
pattern = r"\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d{3} \| INFO +\| api.internal.dependencies.user_auth:verify_sign:\d+ - (.*?)(?=\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d{3} \| INFO|$)"
matches = re.findall(pattern, log_content, re.DOTALL)
smart_writing_demands = []
ppt_creation_demands = []
# 定义提取 PPT 需求的正则表达式
ppt_pattern_1 = r"我的要求是:(.*?)。\n根据主题和参考资料完成内容分析"
ppt_pattern_2 = r"我要制作一份(.*?)PPT的大纲,输出大纲格式严格按照以下"
for demand in matches:
if demand.startswith("OloeBh"):
auth = user_auth.UserAuth()
try:
decrypted_result = auth.get_true_messages(demand)
if decrypted_result:
last_content = decrypted_result[-1].get("content", "")
# 尝试使用正则表达式提取 PPT 需求
match_1 = re.search(ppt_pattern_1, last_content)
match_2 = re.search(ppt_pattern_2, last_content)
if match_1:
ppt_creation_demands.append(match_1.group(1))
elif match_2:
ppt_creation_demands.append(match_2.group(1))
except Exception as e:
print(f"解密PPT创作需求时出错: {e}")
else:
smart_writing_demands.append(demand)
def clean_text(text):
return re.sub(r'[\x00-\x1F\x7F]', '', text)
smart_writing_demands = [clean_text(demand) for demand in smart_writing_demands if pd.notna(demand)] # 过滤 np.nan
ppt_creation_demands = [clean_text(demand) for demand in ppt_creation_demands if pd.notna(demand)] # 过滤 np.nan
smart_writing_df = pd.DataFrame({"智能写作需求": smart_writing_demands})
ppt_creation_df = pd.DataFrame({"PPT创作需求": ppt_creation_demands})
path = os.getcwd()
data = os.path.join(path, "data")
try:
output_excel_dir = data
if not os.path.exists(output_excel_dir):
os.makedirs(output_excel_dir)
output_excel_path = os.path.join(output_excel_dir, "output.xlsx")
with pd.ExcelWriter(output_excel_path, engine='openpyxl') as writer:
smart_writing_df.to_excel(writer, sheet_name='智能写作需求', index=False)
ppt_creation_df.to_excel(writer, sheet_name='PPT创作需求', index=False)
print("Excel 文件已创建成功!")
return smart_writing_demands, ppt_creation_demands
except Exception as e:
print(f"创建Excel文件时出错: {e}")
return None
# 统计词频并保存到 txt 文件
def word_frequency_analysis(texts, output_txt_path):
all_words = []
for text in texts:
# 分词
words = jieba.lcut(text)
# 去除无关字符、标点和单字
filtered_words = [
word for word in words
if re.match(r'^[\u4e00-\u9fa5a-zA-Z0-9]+$', word) # 保留中文字符、字母和数字
and len(word) >= 2 # 只保留2字及以上词语
]
all_words.extend(filtered_words)
word_freq = pd.Series(all_words).value_counts().reset_index()
word_freq.columns = ['词语', '词频']
# 设置索引从 1 开始
word_freq.index = range(1, len(word_freq) + 1)
# 保存前 100 个高频词到 txt 文件
top_100_freq = word_freq.head(100)
output_dir = "data"
if not os.path.exists(output_dir):
os.makedirs(output_dir)
full_output_path = os.path.join(output_dir, output_txt_path)
with open(full_output_path, 'w', encoding='utf-8') as f:
for index, row in top_100_freq.iterrows():
f.write(f"{row['词语']}: {row['词频']}\n")
# 返回前 10 个高频词
top_10_freq = word_freq.head(10)
return top_10_freq
# 文本搜索
def text_search(keyword, texts, top_n=10):
texts = [text for text in texts if pd.notna(text)] # 过滤 np.nan
keyword = keyword if pd.notna(keyword) else "" # 处理关键词为 np.nan 的情况
vectorizer = TfidfVectorizer()
all_texts = texts + [keyword]
tfidf_matrix = vectorizer.fit_transform(all_texts)
keyword_vector = tfidf_matrix[-1]
text_vectors = tfidf_matrix[:-1]
similarities = cosine_similarity(keyword_vector, text_vectors).flatten()
sorted_indices = similarities.argsort()[::-1]
top_indices = sorted_indices[:top_n]
top_texts = [texts[i] for i in top_indices]
top_similarities = [similarities[i] for i in top_indices]
results = []
for i, (text, similarity) in enumerate(zip(top_texts, top_similarities), start=1):
results.append(f"{i}. 相似度: {similarity:.4f}, 文本: {text}")
return '\n'.join(results)
# Gradio 界面部分(日志分析)
with gr.Blocks() as demo:
gr.Markdown("### 日志文件需求分析与搜索")
log_file_input = gr.File(label="上传日志文件")
analyze_button = gr.Button("分析文件")
smart_writing_freq_output = gr.Textbox(label="智能写作需求前十词频", lines=10)
ppt_creation_freq_output = gr.Textbox(label="PPT创作需求前十词频", lines=10)
smart_writing_keyword_input = gr.Textbox(label="输入智能写作需求搜索关键词")
smart_writing_search_button = gr.Button("搜索智能写作需求")
smart_writing_search_output = gr.Textbox(label="智能写作需求搜索结果", lines=10)
ppt_creation_keyword_input = gr.Textbox(label="输入PPT创作需求搜索关键词")
ppt_creation_search_button = gr.Button("搜索PPT创作需求")
ppt_creation_search_output = gr.Textbox(label="PPT创作需求搜索结果", lines=10)
def analyze_log_file(file):
log_path = file.name
result = extract_demands_from_log(log_path)
if result:
smart_writing_demands, ppt_creation_demands = result
smart_freq = word_frequency_analysis(smart_writing_demands, 'smart_writing_freq.txt')
ppt_freq = word_frequency_analysis(ppt_creation_demands, 'ppt_creation_freq.txt')
return str(smart_freq), str(ppt_freq)
return "", ""
analyze_button.click(analyze_log_file, inputs=log_file_input,
outputs=[smart_writing_freq_output, ppt_creation_freq_output])
def perform_smart_writing_search(keyword):
try:
output_excel_dir = r"C:\kaohe\data"
output_excel_path = os.path.join(output_excel_dir, "output.xlsx")
excel_file = pd.ExcelFile(output_excel_path)
smart_writing_df = excel_file.parse('智能写作需求')
smart_writing_texts = smart_writing_df['智能写作需求'].tolist()
return text_search(keyword, smart_writing_texts)
except FileNotFoundError:
return "请先上传并分析日志文件。"
smart_writing_search_button.click(perform_smart_writing_search, inputs=smart_writing_keyword_input,
outputs=smart_writing_search_output)
def perform_ppt_creation_search(keyword):
try:
output_excel_dir = r"C:\kaohe\data"
output_excel_path = os.path.join(output_excel_dir, "output.xlsx")
excel_file = pd.ExcelFile(output_excel_path)
ppt_creation_df = excel_file.parse('PPT创作需求')
ppt_creation_texts = ppt_creation_df['PPT创作需求'].tolist()
return text_search(keyword, ppt_creation_texts)
except FileNotFoundError:
return "请先上传并分析日志文件。"
ppt_creation_search_button.click(perform_ppt_creation_search, inputs=ppt_creation_keyword_input,
outputs=ppt_creation_search_output)
if __name__ == "__main__":
demo.launch()
3.2 worldcloud_function.py
词云图部分:
import pandas as pd
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
import gradio as gr
from PIL import Image
import numpy as np
import os
# 读取 txt 文件并转换为 DataFrame
def read_freq_from_txt(file_path):
words = []
frequencies = []
try:
with open(file_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
word, freq = line.strip().split(': ')
words.append(word)
frequencies.append(int(freq))
return pd.DataFrame({'词语': words, '词频': frequencies})
except FileNotFoundError:
print(f"未找到文件: {file_path}")
return None
except ValueError:
print(f"文件格式有误,请确保每行格式为 '词语: 词频'。")
return None
path = os.getcwd()
x = os.path.join(path,"data\\mask2.png")
# 生成词云图并保存为图片
def generate_wordcloud(file_path, save_path):
word_freq = read_freq_from_txt(file_path)
if word_freq is None:
return None
try:
# 读取一个图片作为词云的形状
mask_image = np.array(Image.open(x))
# 定义颜色生成器
image_colors = ImageColorGenerator(mask_image)
wordcloud = WordCloud(
font_path='simhei.ttf', # 中文字体路径
background_color='white',
width=800,
height=600,
mask=mask_image, # 使用图片作为词云的形状
color_func=image_colors, # 使用颜色生成器
max_words=100, # 最大显示的词语数量
min_font_size=10, # 最小字体大小
max_font_size=100, # 最大字体大小
random_state=42 # 随机种子,保证每次生成的词云布局一致
).generate_from_frequencies(dict(zip(word_freq['词语'], word_freq['词频'])))
wordcloud.to_file(save_path) # 保存图片
return save_path # 返回文件路径
except Exception as e:
print(f"生成词云图失败: {e}")
return None
# Gradio 界面(词云图)
with gr.Blocks(title="词云图生成器") as demo:
gr.Markdown("### 基于 TXT 文件的词云图生成器")
# 文件输入组件
txt_file = gr.File(label="上传词频 TXT 文件(每行格式:词语: 词频)")
# 图片显示组件
wordcloud_img = gr.Image(label="生成的词云图", type="filepath")
# 生成按钮
generate_btn = gr.Button("生成词云图")
# 按钮点击事件逻辑
def update_image(file):
if not file:
return None
# 临时保存上传的文件
temp_path = file.name
# 生成词云图并保存到指定路径
save_path = os.path.join(path,"data\\generated_wordcloud.png")
result = generate_wordcloud(temp_path, save_path)
return result if result else None
# 绑定按钮事件
generate_btn.click(
fn=update_image,
inputs=txt_file,
outputs=wordcloud_img
)
if __name__ == "__main__":
demo.launch()
3.3 run_all.py
合并Gradio界面:
import gradio as gr
from main_function import demo as main_demo
from wordcloud_function import demo as wc_demo
# 合并两个 Gradio 界面
combined_demo = gr.TabbedInterface(
[main_demo, wc_demo],
["日志分析与搜索", "词云图生成"]
)
if __name__ == "__main__":
combined_demo.launch()
README
1、分析所给的日志文件,使用正则表达式提取智能写作用户需求和PPT创作需求,将提取到的需求保存到一个Excel表中,分别使用两个Sheet存储,一个Sheet名称为智能写作需求,另一个为PPT创作需求; 2、对获得的Excel表中的数据分别进行文本分析,如统计词频、绘制词云图,以及其他分析; 3、文件user_auth.cp312-win_amd64为解密文件,对应的python3.12版本 4、示例日志文件recods.txt下载地址: 通过百度网盘分享的文件:records.zip 链接: https://pan.baidu.com/s/1HrVIVF_olDKFIQt3Lh2jkA?pwd=2025 提取码: 2025
python解释器版本:python 3.12.7
文件夹:
data文件夹:保存日志文件、高频词文件和输出的Excel文件,这个Excel文件名字叫output,储存智能写作需求和PPT创作需求的文本。
main文件夹:代码文件 1.单独运行main_function.py或者wordcloud_function.py文件,可以正常生成GUI界面,使用一部分功能。 main_function.py 功能:日志文本分析,统计词频,文本相似度搜索; wordcloud_function.py 功能:生成词云图; 2.直接运行run_all.py可以使用完整功能;
mask.png图片是生成词云图的形状。
gradio界面: 包括文本分析和词云图生成两部分
1.文本分析:上传文本文件分析文件,会在data文件夹生成output.xlsx文件、ppt_creation_freq.txt文件和smart_writing_freq.txt文件,两个文本文件分别储存智能写作和PPT创作的高频词及词频。
2.词云图生成:将文本分析生成的ppt_creation_freq.txt文件和smart_writing_freq.txt文件分别上传,会生成两个词云图,图片储存在data目录。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









