






本文档详细介绍了使用ChatGLM3-6b大模型、m3e向量模型、one-
api接口管理以及Fastgpt的知识库,成功的在本地搭建了一个大模型。此外,还利用LLaMA-Factory进行了大模型的微调。
1.ChatGLM3-6b
2.m3e
3.One-API
4.Fastgpt
5.LLaMA-Factory
1.部署ChatGLM3-6b大模型
1.1创建腾讯云服务器
注意:
ChatGLM3-6b的大模型40多个G,购买腾讯云服务器的时候一定要扩容硬盘,否则会出现克隆失败的情况.
后面微调大模型的时候微调好的模型需要导出,所以最好扩容>=200
腾讯云服务器官网>产品>计算>高性能应用服务
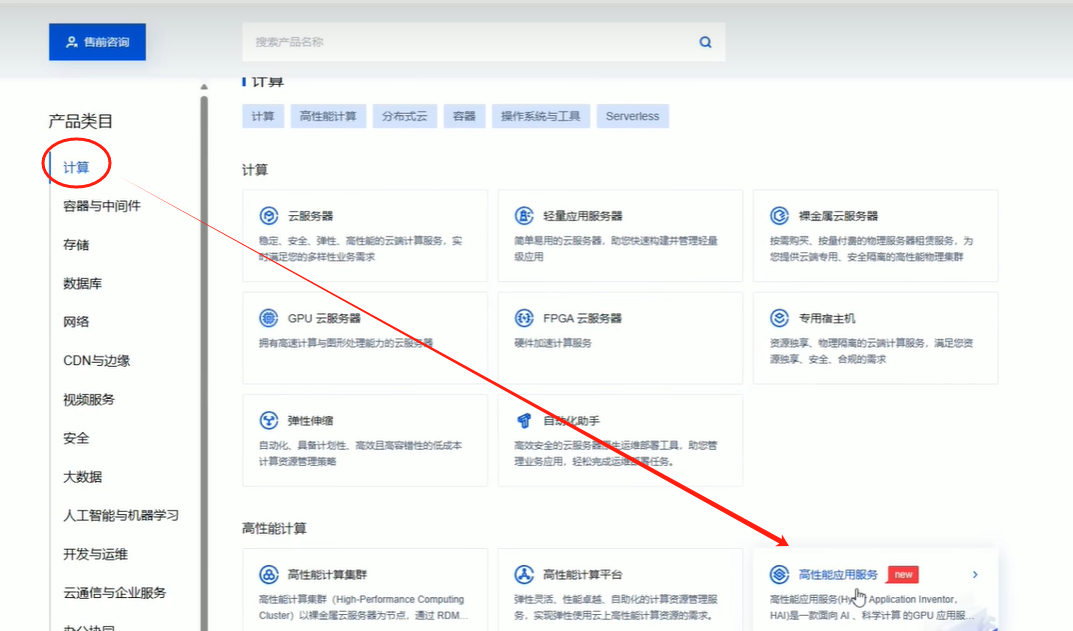
选择AI框架>Pytorch2.0.0
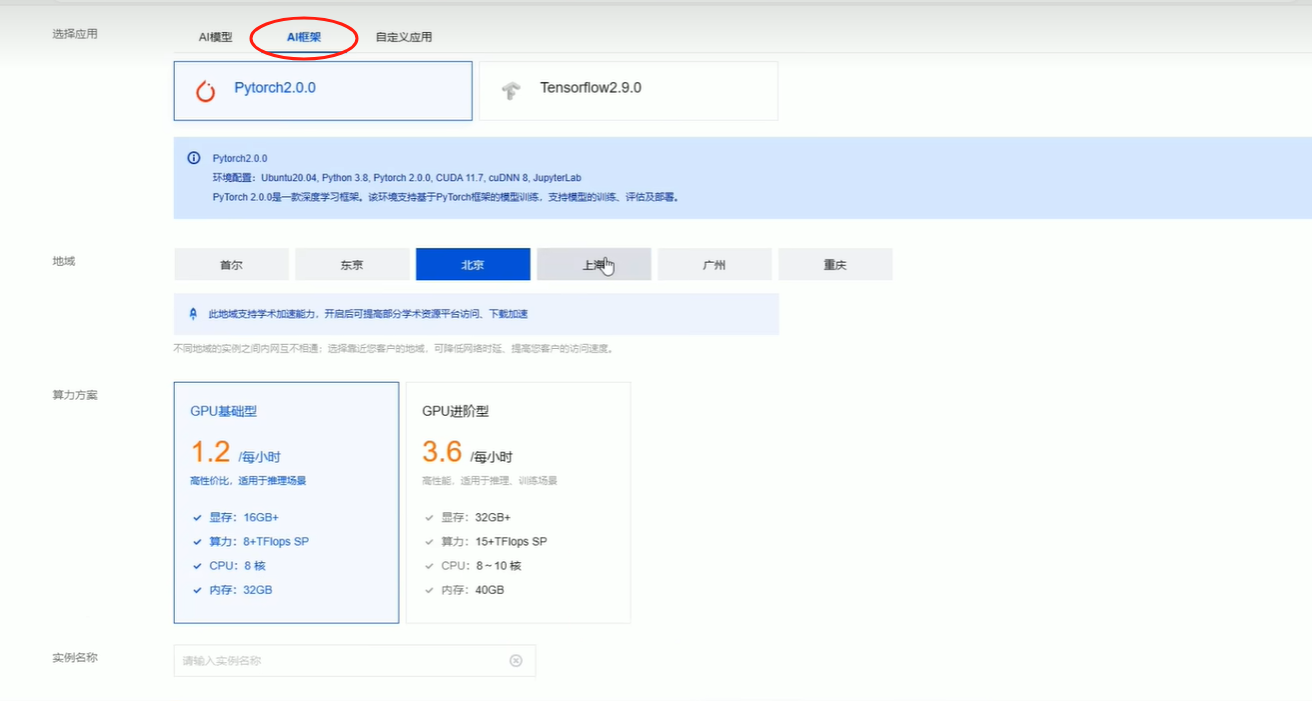
等待创建成功之后使用JupyterLab进入
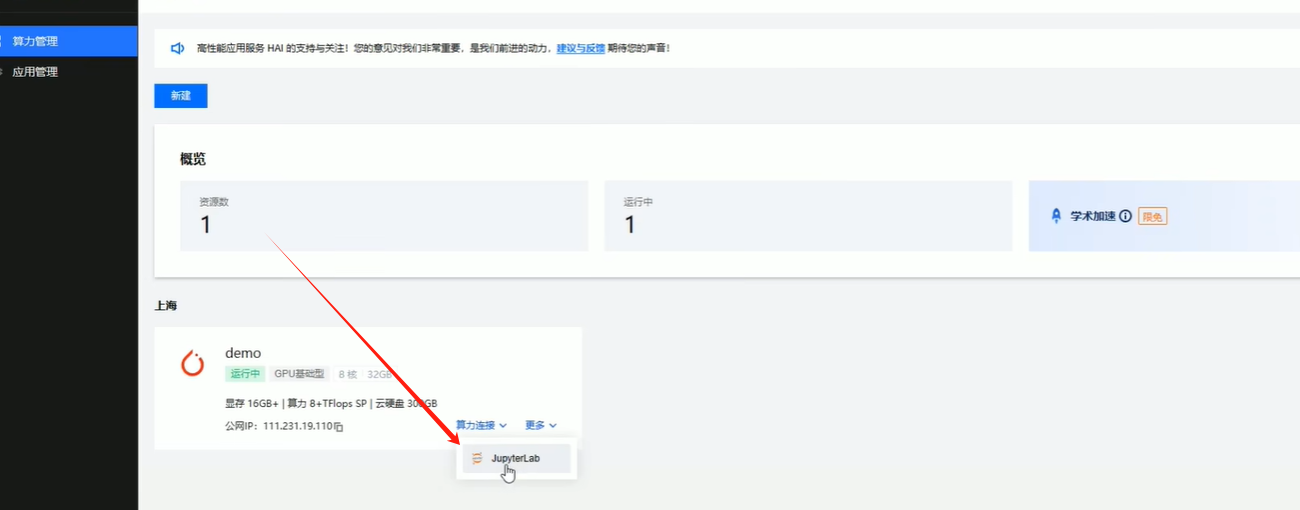
点击Terminal(终端)
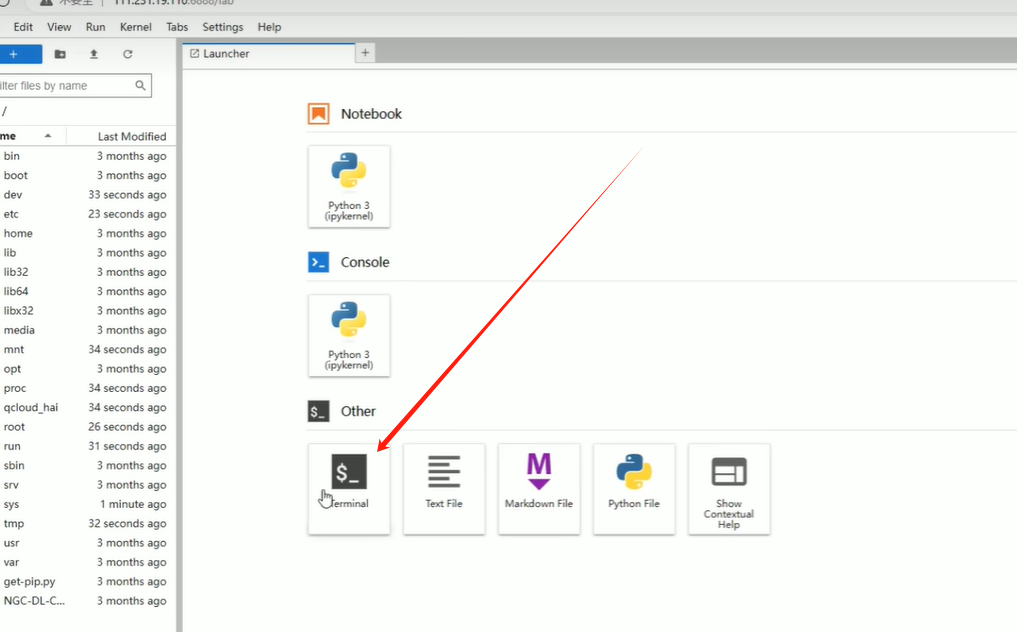
1.2 下载大模型和向量模型
mkdir models
cd models
apt update
apt install git-lfs
# 克隆chatGLM3-6b大模型
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
# 克隆m3e向量模型
git clone https://www.modelscope.cn/xrunda/m3e-base.git
1.3 下载chatglm3-demo项目
mkdir webcodes
cd webcodes
# 下载chatglm3-6b web_demo项目
git clone https://github.com/THUDM/ChatGLM3.git
pip install -r requirements.txt
1.4 修改model路径
打开basic_demo/web_demo_streamlit.py文件,修改MODEL_PATH的路径为本地大模型的路径
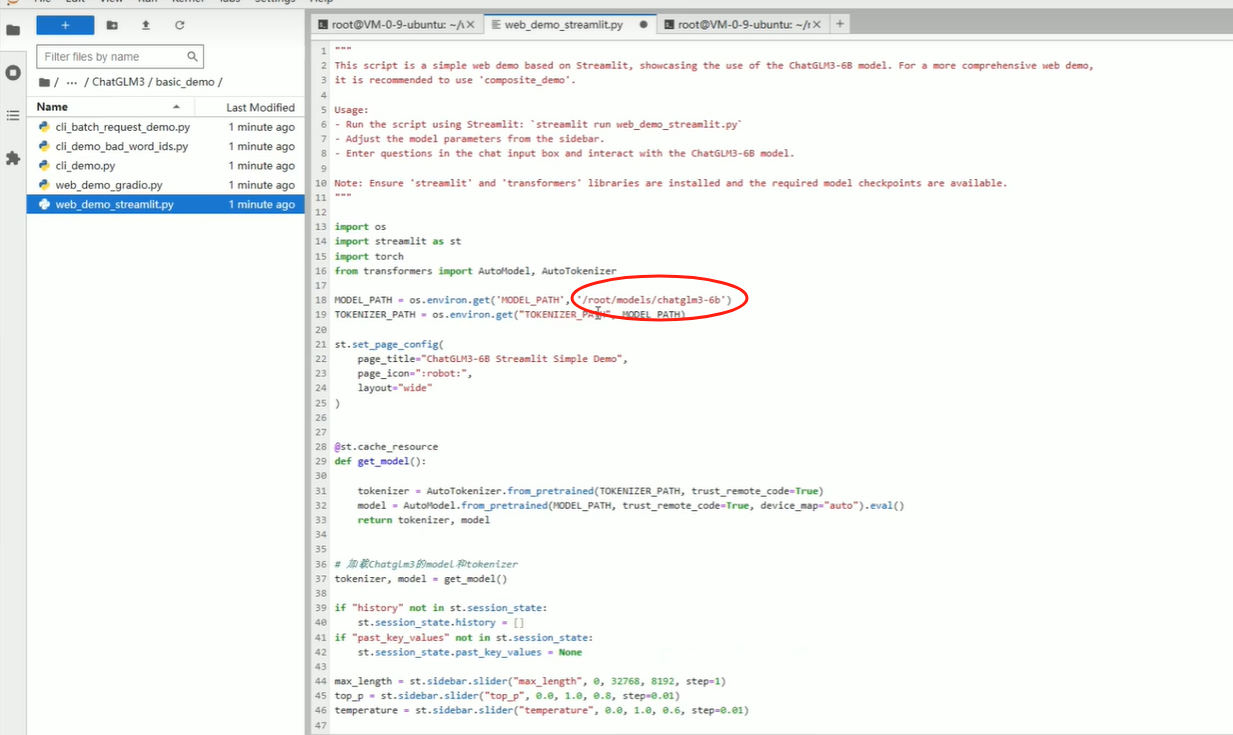
1.4 运行web_demo项目
cd basic_demo
streamlit run web_demo_streamlit.py
首次运行的话到1.4这停止,目的是为了测试大模型是否跑通.
下面的1.5 后面会有使用的时机
1.5 修改api_server.py文件
cd ChatGLM3/openai_api_demo
# 然后找到api_server.py文件夹
# 修改里面的MODEL_PATH 和 EMBEDDING_PATH 为本地的大模型地址和向量模型地址
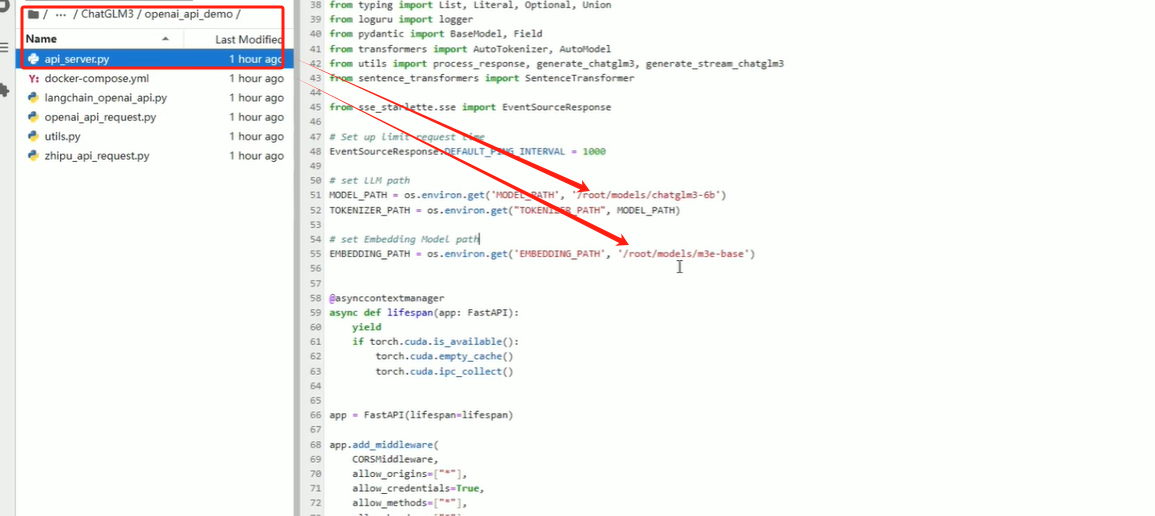
修改文件最下面的device_map="cuda"
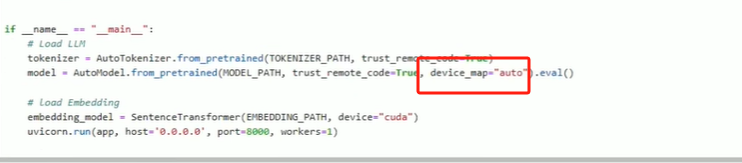
model = AutoModel.from_pretrained(MODEL_PATH,trust_remote_code=True,device_map="cuda").eval()
2.下载docker和docker compose
# 安装 Docker
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
systemctl enable --now docker
# 安装 docker-compose
curl -L https://github.com/docker/compose/releases/download/v2.20.3/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
# 验证安装
docker -v
docker-compose -v
# 如失效,自行百度~
3.使用docker部署one-api项目
docker run --name one-api -d --restart always -p 3080:3000 -e TZ=Asia/Shanghai -v /home/ubuntu/data/one-api:/data justsong/one-api
3.1 修改大模型运行端口
把1.4运行的项目停止
而后查看1.5的运行方式
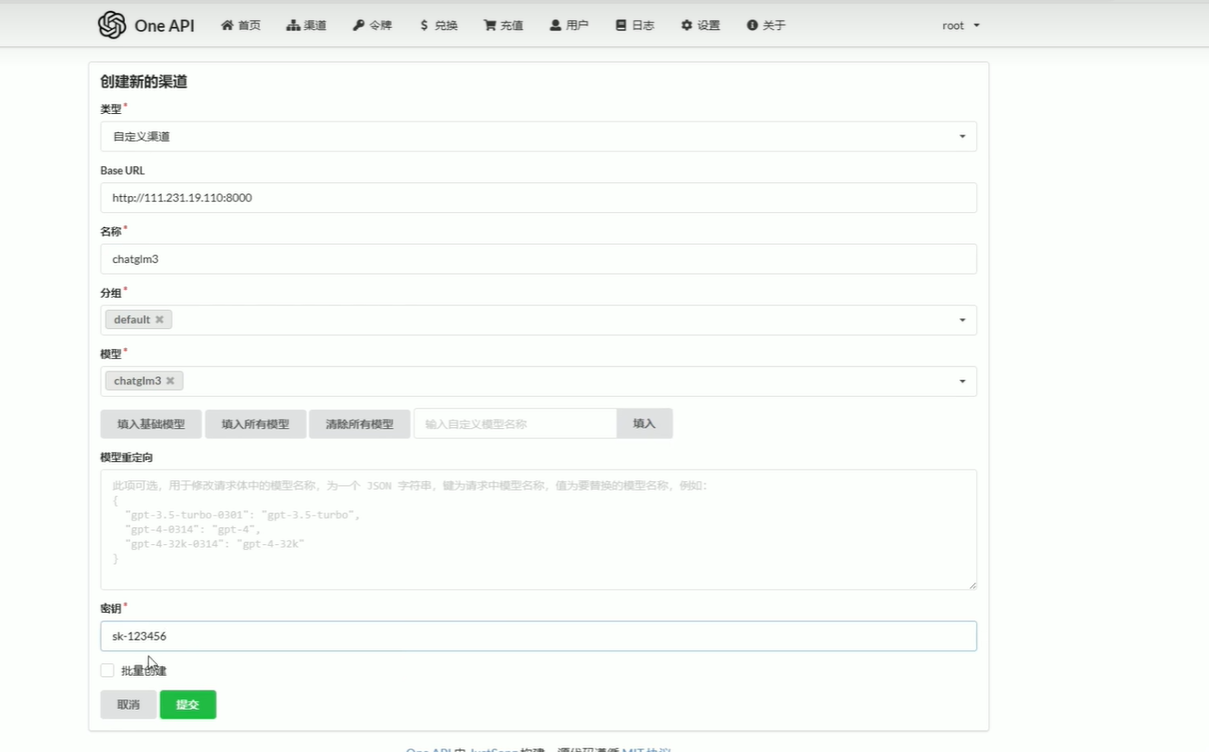
3.2添加chatglm3的渠道
Base_URL是部署大模型的服务器的ip地址,端口号为启动大模型的端口号.
秘钥随便填
3.3添加m3e渠道
同上
3.4测试渠道是否跑通
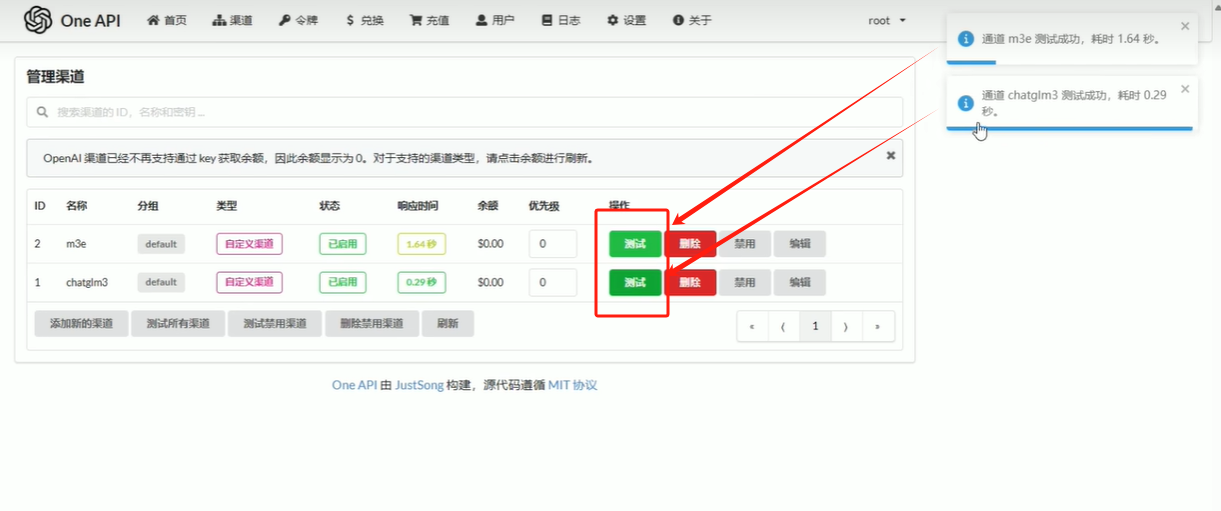
3.5添加令牌
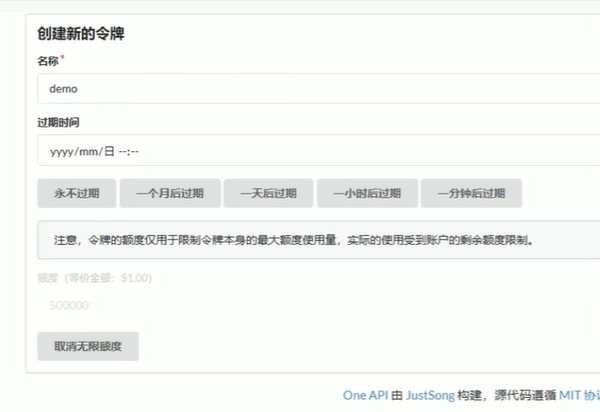
4.部署fastgpt
mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/files/deploy/fastgpt/docker-compose.yml
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
4.1修改docker-compose.yml
修改docker-compose.yml中的OPENAI_BASE_URL(API 接口的地址,需要加/v1)和CHAT_API_KEY(API
接口的凭证)。
使用 OneAPI 的话,OPENAI_BASE_URL=OneAPI访问地址/v1;CHAT_API_KEY=令牌
# 非 host 版本, 不使用本机代理
# (不懂 Docker 的,只需要关心 OPENAI_BASE_URL 和 CHAT_API_KEY 即可!)
version: '3.3'
services:
pg:
image: ankane/pgvector:v0.5.0 # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.5.0 # 阿里云
container_name: pg
restart: always
ports: # 生产环境建议不要暴露
- 5432:5432
networks:
- fastgpt
environment:
# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果
- POSTGRES_USER=username
- POSTGRES_PASSWORD=password
- POSTGRES_DB=postgres
volumes:
- ./pg/data:/var/lib/postgresql/data
mongo:
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18
container_name: mongo
restart: always
ports:
- 27017:27017
networks:
- fastgpt
command: mongod --keyFile /data/mongodb.key --replSet rs0
environment:
- MONGO_INITDB_ROOT_USERNAME=myusername
- MONGO_INITDB_ROOT_PASSWORD=mypassword
volumes:
- ./mongo/data:/data/db
entrypoint:
- bash
- -c
- |
openssl rand -base64 128 > /data/mongodb.key
chmod 400 /data/mongodb.key
chown 999:999 /data/mongodb.key
exec docker-entrypoint.sh $$@
fastgpt:
container_name: fastgpt
image: ghcr.io/labring/fastgpt:latest # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:latest # 阿里云
ports:
- 3000:3000
networks:
- fastgpt
depends_on:
- mongo
- pg
restart: always
environment:
# root 密码,用户名为: root
- DEFAULT_ROOT_PSW=1234
# 中转地址,如果是用官方号,不需要管。务必加 /v1
- OPENAI_BASE_URL=https://api.openai.com/v1
- CHAT_API_KEY=sk-xxxx
- DB_MAX_LINK=5 # database max link
- TOKEN_KEY=any
- ROOT_KEY=root_key
- FILE_TOKEN_KEY=filetoken
# mongo 配置,不需要改. 用户名myusername,密码mypassword。
- MONGODB_URI=mongodb://myusername:mypassword@mongo:27017/fastgpt?authSource=admin
# pg配置. 不需要改
- PG_URL=postgresql://username:password@pg:5432/postgres
volumes:
- ./config.json:/app/data/config.json
networks:
fastgpt:
4.2 修改config.json
需要注意的是llmModels中datasetProcess必须设置为true知识库才会生效,否则知识库会出问题
{
"systemEnv": {
"vectorMaxProcess": 15,
"qaMaxProcess": 15,
"pgHNSWEfSearch": 100 // 向量搜索参数。越大,搜索越精确,但是速度越慢。设置为100,有99%+精度。
},
"llmModels": [
{
"model": "chatglm3", // 模型名
"name": "chatglm3", // 别名
"maxContext": 16000, // 最大上下文
"maxResponse": 4000, // 最大回复
"quoteMaxToken": 13000, // 最大引用内容
"maxTemperature": 1.2, // 最大温度
"charsPointsPrice": 0,
"censor": false,
"vision": false, // 是否支持图片输入
"datasetProcess": true, // 是否设置为知识库处理模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig":{} // LLM默认配置,可以针对不同模型设置特殊值(比如 GLM4 的 top_p
},
],
"vectorModels": [
{
"model": "m3e",
"name": "m3e",
"charsPointsPrice": 0,
"defaultToken": 700,
"maxToken": 3000,
"weight": 100,
"defaultConfig":{} // 默认配置。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)
}
],
"reRankModels": [],
"audioSpeechModels": [
{
"model": "tts-1",
"name": "OpenAI TTS1",
"charsPointsPrice": 0,
"voices": [
{ "label": "Alloy", "value": "alloy", "bufferId": "openai-Alloy" },
{ "label": "Echo", "value": "echo", "bufferId": "openai-Echo" },
{ "label": "Fable", "value": "fable", "bufferId": "openai-Fable" },
{ "label": "Onyx", "value": "onyx", "bufferId": "openai-Onyx" },
{ "label": "Nova", "value": "nova", "bufferId": "openai-Nova" },
{ "label": "Shimmer", "value": "shimmer", "bufferId": "openai-Shimmer" }
]
}
],
"whisperModel": {
"model": "whisper-1",
"name": "Whisper1",
"charsPointsPrice": 0
}
}
4.3 启动容器
# 进入项目目录
cd 项目目录
# 启动容器
docker-compose pull
docker-compose up -d
4.4 初始化Mongo副本集(4.6.8以前可忽略)
# 查看 mongo 容器是否正常运行
docker ps
# 进入容器
docker exec -it mongo bash
# 连接数据库(这里要填Mongo的用户名和密码)
mongo -u myusername -p mypassword --authenticationDatabase admin
# 初始化副本集。如果需要外网访问,mongo:27017 可以改成 ip:27017。但是需要同时修改 FastGPT 连接的参数(MONGODB_URI=mongodb://myname:mypassword@mongo:27017/fastgpt?authSource=admin => MONGODB_URI=mongodb://myname:mypassword@ip:27017/fastgpt?authSource=admin)
rs.initiate({
_id: "rs0",
members: [
{ _id: 0, host: "mongo:27017" }
]
})
# 检查状态。如果提示 rs0 状态,则代表运行成功
rs.status()
4.5 访问fastGPT
目前可以通过 ip:3000 直接访问(注意防火墙)。登录用户名为 root,密码为docker-compose.yml环境变量里设置的
DEFAULT_ROOT_PSW。
如果需要域名访问,请自行安装并配置 Nginx。
5.微调大模型
微调大模型的时候,需要把运行中的大模型服务停止,否则会出现运行显存不足的错误.
5.1环境搭建(可跳过)
git clone https://github.com/hiyouga/LLaMA-Factory.git
conda create -n llama_factory python=3.10
conda activate llama_factory
cd LLaMA-Factory
pip install -r requirements.txt
5.2取sha1值
import hashlib
def calculate_sha1(file_path):
sha1 = hashlib.sha1()
try:
with open(file_path, 'rb') as file:
while True:
data = file.read(8192) # Read in chunks to handle large files
if not data:
break
sha1.update(data)
return sha1.hexdigest()
except FileNotFoundError:
return "File not found."
# 使用示例
file_path = './data/self_cognition_modified.json' # 替换为您的文件路径
sha1_hash = calculate_sha1(file_path)
print("SHA-1 Hash:", sha1_hash)
5.3 修改数据集
训练的数据集放在LLaMA-Factory/data目录下
可以根据自己的情况上传训练数据集
# 自定义数据集
[
{
"instruction": "用户指令(必填)",
"input": "用户输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
5.4 修改data/dataset_info.json文件(重要!!!)
当你把自定义的数据集上传到data目录下之后,需要在dataset_info.json文件中配置
// 在数据集后面新增你添加的自定义数据集的名称和sha1值
// 例如:
{
"self_cogition":{
"file_name":"self_cogition.json" //文件名,
"file_sha1":"使用本文档5.2生成的sha1值"
}
}
5.5 运行
python src/train_web.py
5.6 训练
配置好训练内容后点击网页的开始训练
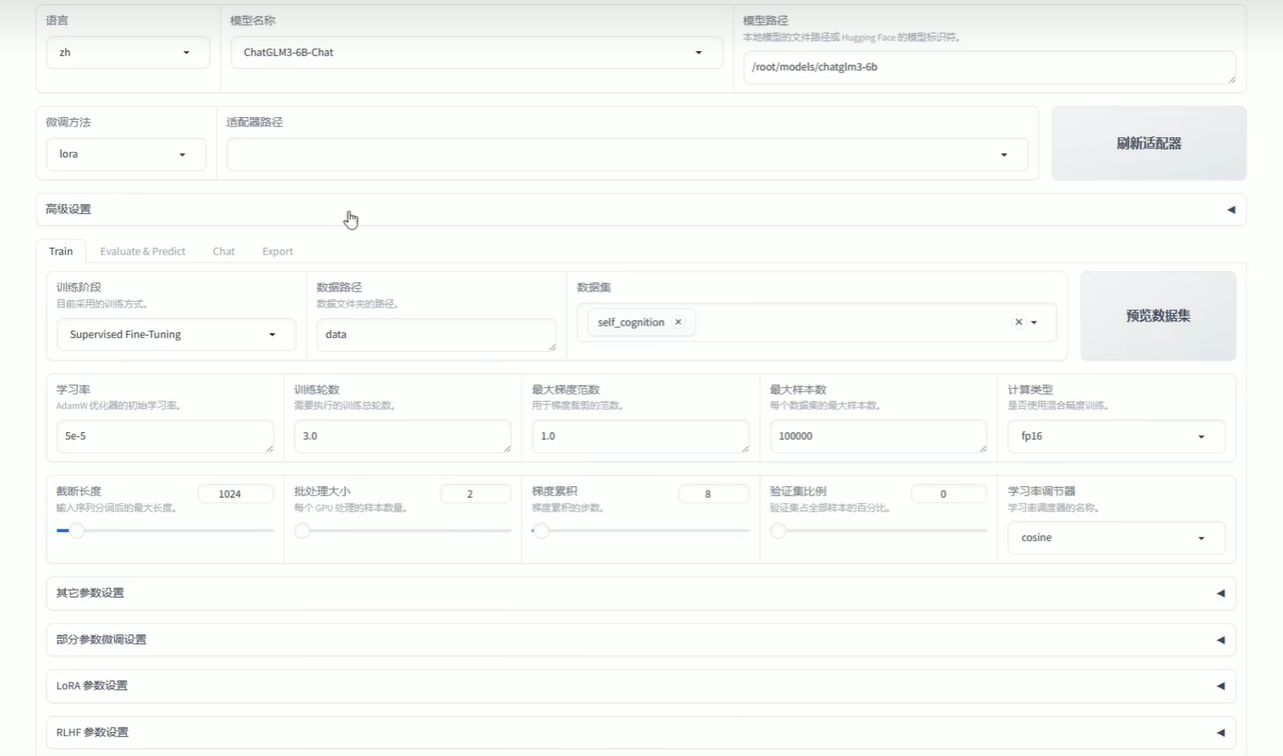
5.7 训练后测试
找到Chat,然后加载模型,测试训练结果
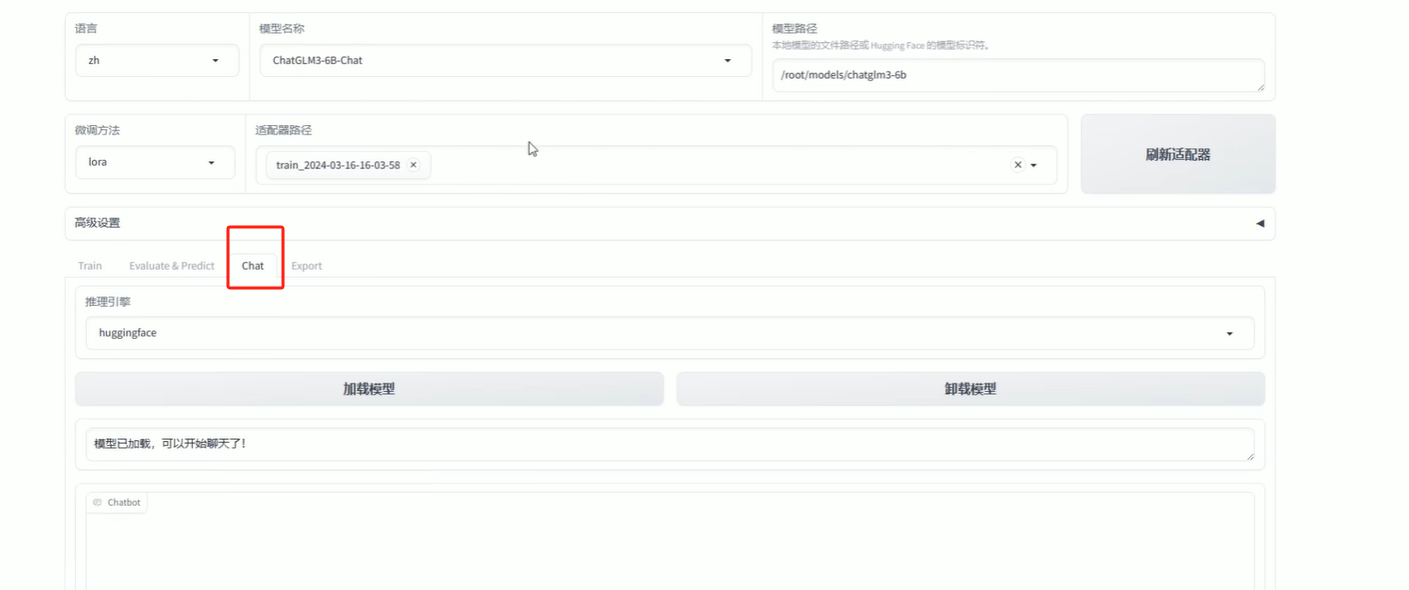
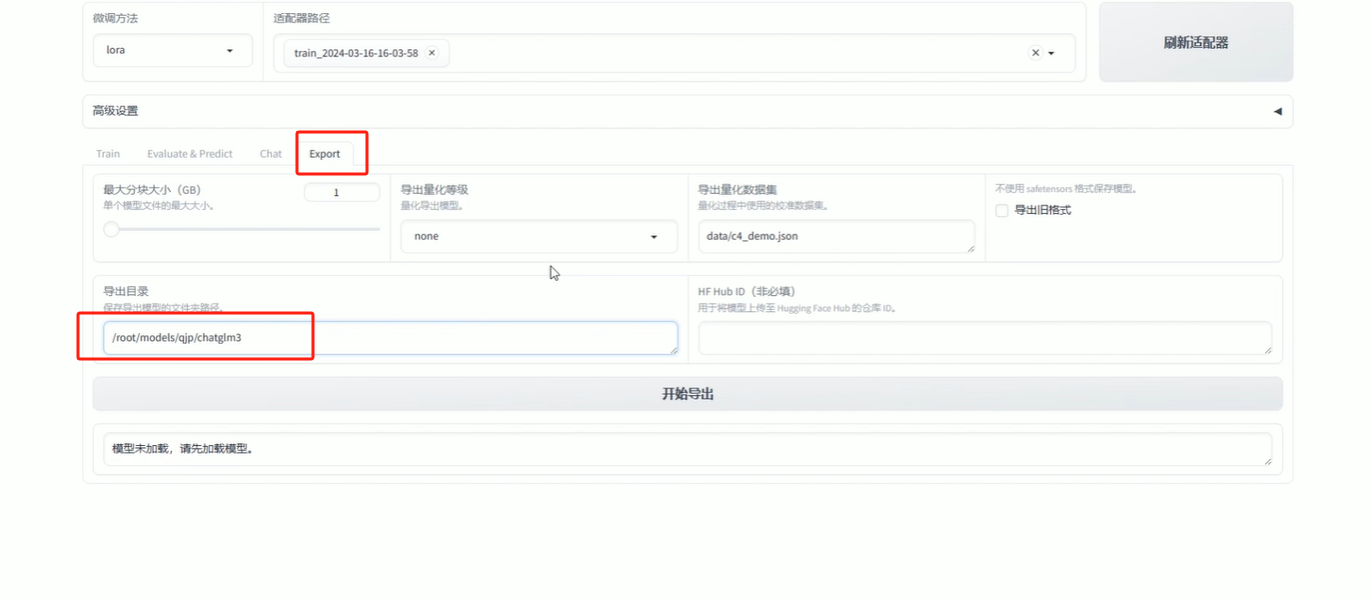
5.8 导出
导出之后,就可以修改大模型路径了(本文档1.5修改api_server.py文件),修改完之后重新运行api_server.py就可以了
AI时代的职场新潮流
听说AI要来抢工作了?别担心,新岗位可比旧岗位有趣多了!想象一下,你从搬砖工升级成了机器人操作员,从算盘小能手变成了大数据分析师,这不是美滋滋吗?所以,社会生产效率提升了,我们也能更轻松地工作。不过,想成为AI界的佼佼者?那就得赶紧学起来,不然就会被同行们甩得连AI的尾巴都摸不着了!
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享!

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享!















 1160
1160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









