






故障的演进
软件系统异常并不是一蹴而就的,毕竟在系统上线前要经过严格的单元测试、集成测试、回归测试等环节,至少会把很多显性的、容易暴露的问题发现并fix掉,没有达到测试标准的系统也不会上线。那么故障到底来自于哪里呢?

说来也简单,就是一个fault(缺陷)到error(错误)到failure(故障)的转换过程,系统缺陷在某种特定环境下被激活,然后系统产生错误,紧接着系统错误运行使得系统发生某种故障。
要注意的是,错误并不一定导致系统故障,可以理解错误是故障的充分条件。一个最简单的例子是发生了网络错误,但这个网络错误可能只是暂时的不可访问状态,并不一定会升级为故障。
故障的由来
在我们日常开发工作中,最常见的故障来自于系统单点故障,单点故障迟迟得不到处理后便升级为系统性故障甚至全面瘫痪。
单一故障点是指没有备用的冗余组件的硬件或软件组件,而这些组件是系统重要的组成部分。该组件出现故障会使系统无法继续提供服务。设计容错系统时,必须确定并消除潜在的单一故障点。
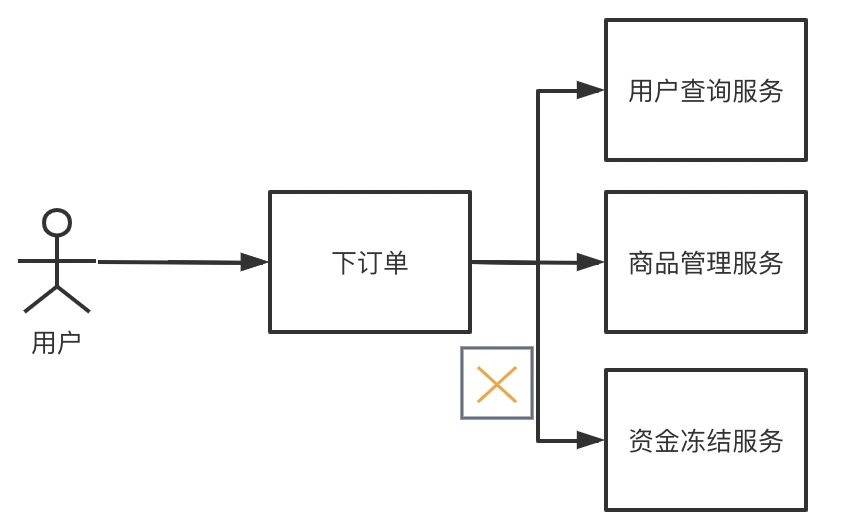
一个典型的故障升级可能是这样的:系统中资金冻结服务存在严重的缺陷,所有部署该服务的机器平均响应速度逐渐慢下来,当大量下单请求进来时,慢慢消耗掉系统所有资源,进而导致整个系统不可用。
故障的常用容错方法
软件故障的容错方法如果用一句话来简单概况的话也简单:通过定义规则来容忍系统缺陷。但这样的定义未免过于大而空,我们需要切实有效可落地的方式。下面介绍9种常用的处理方式。
▐ Process Pairs
也就是最简单的backup方案,保证系统在某一个时刻总能有一个进程来处理客户的输入请求,能处理短暂的软件错误。
▐ Graceful Degradation
就是我们常说的降级,在系统遭遇某个错误之后不提供完整功能,只给用户开放部分基础能力,此解决方案通常是上面的backup方案持续性不work的时候采取的保护措施。
▐ Selective Retry
选择性重试也是可选的方案之一,它主要适用于是突发式高负载资源短缺的场景,例如,网络瞬时打满峰值不可访问或者内存资源短缺,重试能够增加资源分配成功的可能性。
▐ State Handling
在系统不能提供服务后,又要保证client的无状态属性。服务端需要持续保存当前的状态,用于故障后的重试。
▐ Linking Process
有些程序进程是相互依赖的,如果某个进程出错,其他依赖的进程需要侦测到错误,明确做相应的处理,通常是结束全部依赖进程。
▐ Checkpoint
周期性的保存进程的状态。如果需要保证数据正确,回滚到最近保存的状态即可,只是会有部分的数据丢失。
▐ Update Lost
上面方案的补充版,在两个checkpoint之间系统故障,需要保存客户请求,在rollback前一个版本之后重新处理这些请求。
▐ Process Pools
使用资源预分配技术,按照经验设定好某些请求资源的需求量,为程序分配合适的资源。就像我们为某个任务分配线程池大小一样。
▐ Micro reboot
通过解耦系统组件,使得系统在遭遇故障时,只需要重启需要的组件,而不必重启整个系统。核心是组件和数据分离,数据的处理通过持久化存储的方式保证一致。
容错、熔断、隔离?
“隔离”是一种异常检测机制,常用的检测方法是请求超时、流量过大等。一般的设置参数包括超时时间、同时并发请求个数等。
“熔断”是一种异常反应机制,“熔断”依赖于“隔离”。熔断通常基于错误率来实现。一般的设置参数包括统计请求的个数、错误率等。
“容错”是一种异常处理机制,“容错”依赖于“熔断”。熔断以后,会调用“容错”的方法。一般的设置参数包括调用容错方法的次数等。
总结
技术学习总结
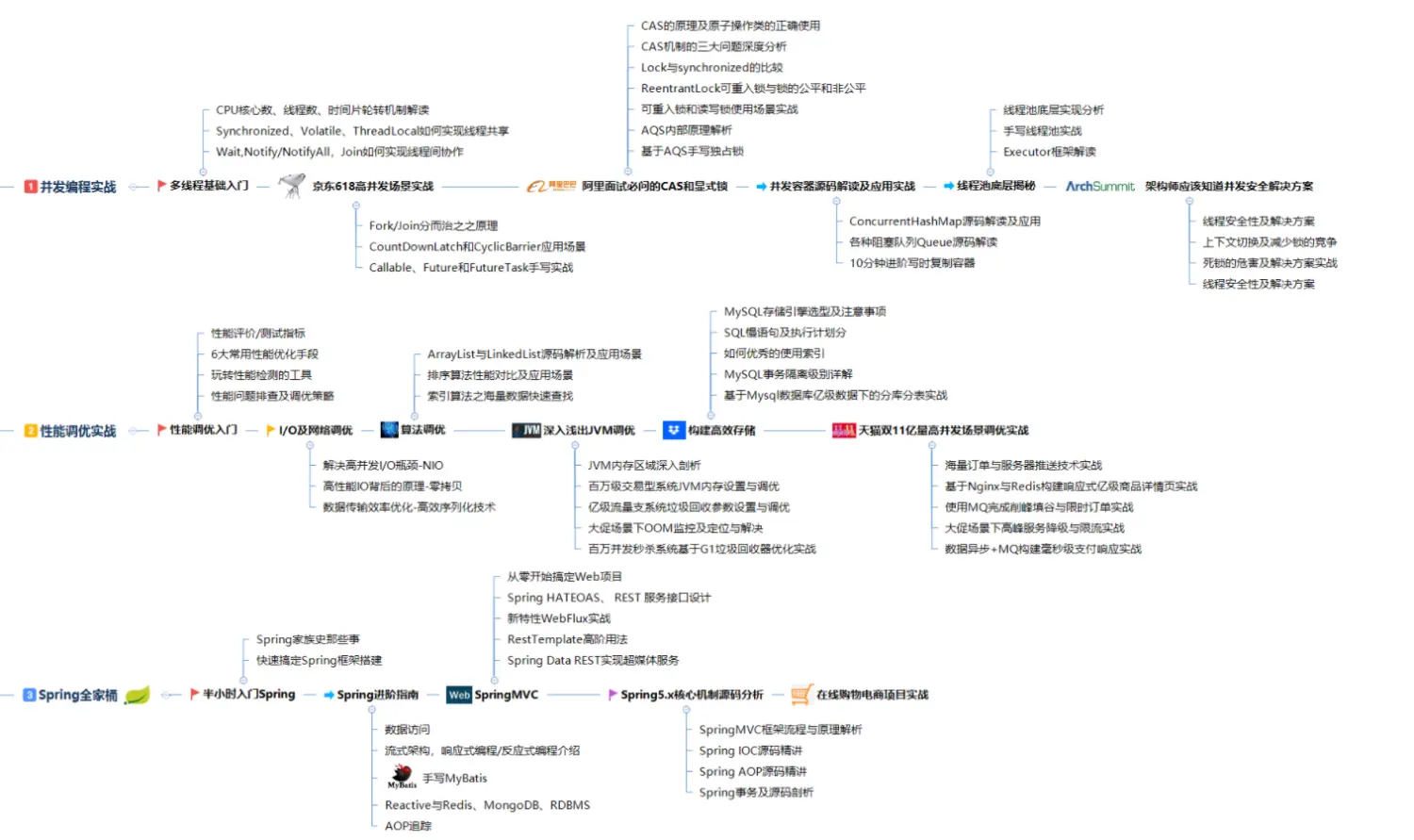
学习技术一定要制定一个明确的学习路线,这样才能高效的学习,不必要做无效功,既浪费时间又得不到什么效率,大家不妨按照我这份路线来学习。


最后面试分享
大家不妨直接在牛客和力扣上多刷题,同时,我也拿了一些面试题跟大家分享,也是从一些大佬那里获得的,大家不妨多刷刷题,为金九银十冲一波!

享
大家不妨直接在牛客和力扣上多刷题,同时,我也拿了一些面试题跟大家分享,也是从一些大佬那里获得的,大家不妨多刷刷题,为金九银十冲一波!
[外链图片转存中…(img-eiGg52rN-1721130537290)]
[外链图片转存中…(img-qMUZRnXj-1721130537290)]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









