






1. 引言
GraphRAG,微软开源的一个新的基于知识图谱构建的检索增强生成(RAG)系统,该框架旨在利用大型语言模型(LLMs)从非结构化文本中提取结构化数据, 构建具有标签的知识图谱,以支持数据集问题生成、摘要问答等多种应用场景。
GraphRAG 的一大特色是利用图机器学习算法针对数据集进行语义聚合和层次化分析,因而可以回答一些相对高层级的抽象或总结性问题, 这一点恰好是常规 RAG 系统的短板。
本文主要对 GraphRAG 源码方面进行解读, 也希望借此进一步理解其系统架构、关键概念以及核心工作流等。
本次拉取的 GraphRAG 项目源码对应 commit id 为 a22003c302bf4ffeefec76a09533acaf114ae7bb,更新日期为 2024.07.05。
2. 框架概述
2.1 解决了什么问题(What & Why)?
讨论代码前, 我们先简单了解下 GraphRAG 项目的目标与定位. 在论文中, 作者很明确地提出了一个常规 RAG 无法处理的应用场景:
However, RAG fails on global questions directed at an entire text corpus, such as “What are the main themes in the dataset?”, since this is inherently a queryfocused summarization (QFS) task, rather than an explicit retrieval task.
也就是类似该数据集的主题是什么这种 high level 的总结性问题。作者认为, 这种应用场景本质上是一种聚焦于查询的总结性(QueryFocused Summarization, QFS)任务, 单纯只做数据检索是无法解决的.。相应地, 其解决思路也在论文中清楚地描述出来了:
In contrast with related work that exploits the structured retrieval and traversal affordances of graph indexes (subsection 4.2), we focus on a previously unexplored quality of graphs in this context: their inherent modularity (Newman, 2006) and the ability of community detection algorithms to partition graphs into modular communities of closely-related nodes (e.g., Louvain, Blondel et al., 2008; Leiden, Traag et al., 2019). LLM-generated summaries of these community descriptions provide complete coverage of the underlying graph index and the input documents it represents. Query-focused summarization of an entire corpus is then made possible using a map-reduce approach: first using each community summary to answer the query independently and in parallel, then summarizing all relevant partial answers into a final global answer.
利用社区检测算法(如 Leiden 算法)将整个知识图谱划分模块化的社区(包含相关性较高的节点),然后大模型自下而上对社区进行摘要, 最终再采取 map-reduce 方式实现 QFS:每个社区先并行执行 Query,最终汇总成全局性的完整答案。
2.2 实现方式是什么(How)?
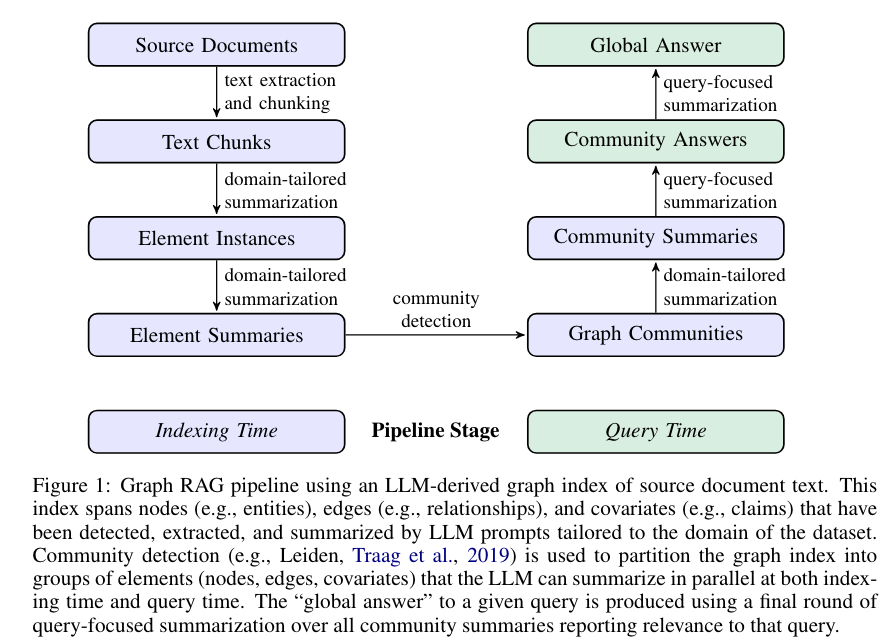
论文中给出了解决问题的基本思路,与其他 RAG 系统类似, GraphRAG 整 个Pipeline 也可划分为索引(Indexing)与查询(Query)两个阶段。索引过程利用 LLM 提取出节点(如实体)、边(如关系)和协变量(如 claim),然后利用社区检测技术对整个知识图谱进行划分,再利用 LLM 进一步总结。最终针对特定的查询,可以汇总所有与之相关的社区摘要生成一个全局性的答案。
3. 源码解析
官方文档说实话写得已经很清楚了,不过想要理解一些实现上的细节,还得深入到源码当中。接下来, 一块看下代码的具体实现。
项目源码结构树如下:


针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

3.1 Demo
研究具体功能前,先简单跑下官方 demo,上手也很简单, 直接参考 https://microsoft.github.io/graphrag/posts/get_started/ 即可。
高能预警:虽然只是一个简单 demo,但是 Token 消耗可是一点都不含糊,尽管早有预期, 并且提前删除了原始文档超过一半的内容,不过我这边完整跑下来还是花了差不多 3刀 费用,官方完整 demo 文档跑一遍,预计得消耗 5~10刀。
这里实际运行时间还是比较慢的,大模型实际上是来来回回地在过整个文档,其中一些比较重要的事项如下:
目录结构


这个文件中的很多文档都值得仔细研究,后续将结合代码详细说明。
Workflows
此外,console 中会打印很多运行日志,其中比较重要的一条就是完整的 workflows,会涉及到完整 pipeline 的编排:

3.2 Index
索引阶段整体看下来应该算是整个项目的核心,整体流程还是比较复杂的。
执行 indexing 的语句如下:

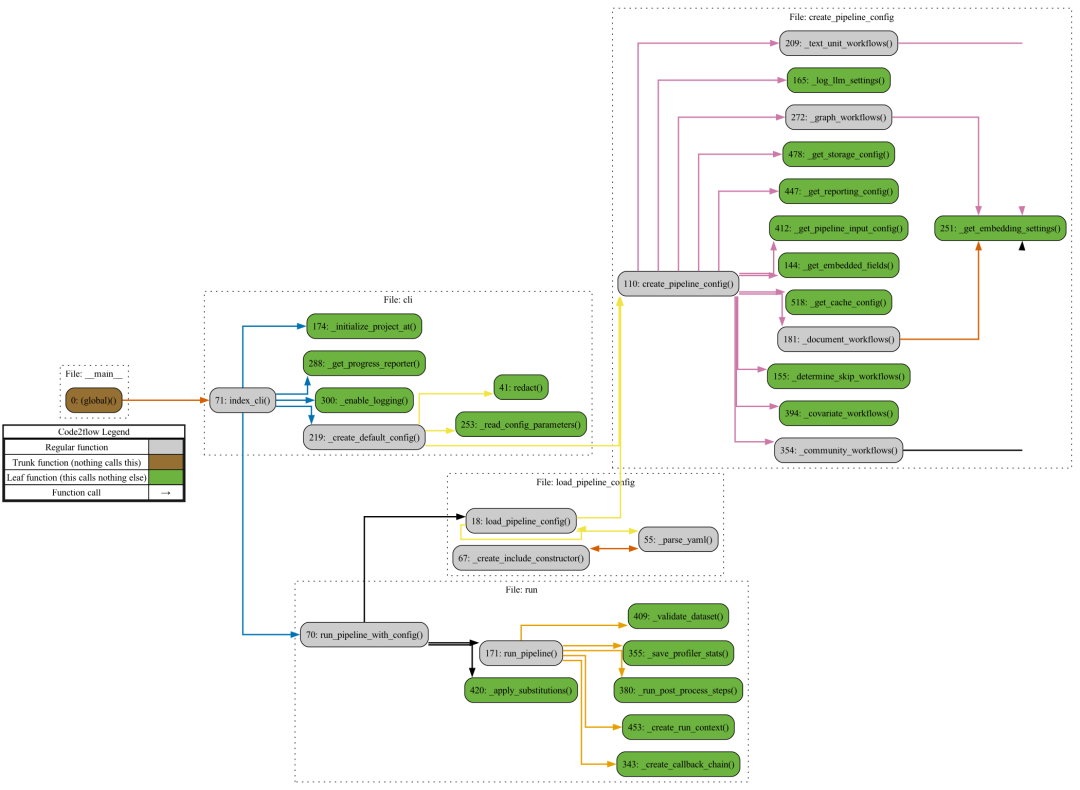
简单跟一下,发现实际调用的是 graphrag/index/__main__.py 文件中的主函数, 使用 argparse 解析输入参数,实际调用的是 graphrag/index/cli.py 中的 index_cli 函数。
继续解读源码前,先简单看下相关函数的调用链路,如上图所示,其中灰色标记的函数是我们需要重点关注的。
-
cli.py::index_cli() 函数首先根据用户输入参数, 如 --init,确定是否需要初始化当前文件夹,这部分具体由 cli.py::index_cli() 执行,其具体实现逻辑比较简单,检查目录下的一些配置、prompt、.env等文件是否存在,没有则创建,具体文件内容,就是上一节目录中展示的 settings.yaml, prompts 等。
-
真正执行 indexing 操作时,实际上会执行一个内部函数 cli.py::index_cli()._run_workflow_async(),主要会涉及到 cli.py::_create_default_config() 与 run.py::run_pipeline_with_config() 两个函数。
限于篇幅, 我们在此只讨论默认配置运行流程,大致梳理清楚相关逻辑后,可自行修改相关配置。
-
默认配置生成逻辑:cli.py::_create_default_config() 首先检查根目录以及配置文件 settings.yaml,然后执行 cli.py::_read_config_parameters() 读取系统配置,如 llm、chunks、cache、storage 等,接下来的操作比较关键,后续会根据当前参数创建一个 pipeline 的配置,具体代码位于 create_pipeline_config.py::create_pipeline_config(), 这块绕了蛮久,可以说是整个项目中逻辑比较复杂的模块了。
-
如果深入 create_pipeline_config.py::create_pipeline_config() 的代码,可以发现其核心逻辑如下:

这段代码的基本逻辑就是根据不同的功能生成完整的 workflow 序列,此处需要注意的是这里并不考虑 workflow 之间的依赖关系,单纯基于 workflows/v1 目录下的各 workflow 的模板生成一系列的 workflow。
- Pipeline 执行逻辑:run.py::run_pipeline_with_config() 首先根据 load_pipeline_config.py::load_pipeline_config() 加载现有 pipeline 的配置(由上一步中 cli.py::_create_default_config() 生成), 然后创建目标文件中的其他子目录, 如 cache、storage、input、 output 等(详见上一节目录结构树),然后再利用 run.py::run_pipeline() 依次执行每一个工作流,并返回相应结果。
这里有必要再单独说明一下 run.py::run_pipeline(),该函数用于真正地执行所有 pipeline, 其核心逻辑包含以下两部分:
-
加载 workflows:workflows/load.py::load_workflows(),除了常规工作流的创建外,还会涉及到拓扑排序问题。
- workflows/load.py::create_workflow():利用已有模板,创建不同的工作流
- graphlib::topological_sort():根据 workflow 之间的依赖关系,,计算 DAG 的拓扑排序。
-
进一步执行 inject_workflow_data_dependencies()、write_workflow_stats()、emit_workflow_output 等操作,分别用于依赖注入,数据写入以及保存,真正的 workflow.run 操作会在 write_workflow_stats() 之前执行,此处的核心逻辑可参考以下代码:

根据以上信息,我们可以大致梳理出索引环节的完整工作流。
-
初始化:生成必要的配置文件、缓存,、input/output 目录等
-
索引:根据配置文件,利用 workflow 模板创建一系列的 pipeline,并依据依赖关系,,调整实际执行顺序,再依次执行
Workflow
截至目前, 我们实际上还没有真正分析 index 阶段的业务逻辑,只是搞清楚了 GraphRAG 内置的这套 pipeline 编排系统该如何工作。
这里以 index/workflows/v1/create_final_entities.py 为例,一起看下具体的一个 workflow 是如何运行的。
DataShaper
-
讨论 workflow 之前,先简单了解下项目使用的另一个框架 datashaper 。datashaper 是微软开源的一款用于执行工作流处理的库,内置了很多组件(专业名词叫做Verb)。
-
通俗来讲,datashaper 就像一条流水线,每一步定义了作用于 input 数据的一种操作,类似 pytorch 图像变换中 clip、otate、scale等操作,如果还是不能理解,建议直接跑一下官方文档中的 demo 程序examples/single_verb, 应该就大致清楚怎么回事了。
-
从功能上来讲,个人感觉有点像Prefect。
知识图谱构建
- 对应的工作流是 create_final_entities.py,翻阅源码可以发现,该 workflow 会依赖于 workflow:create_base_extracted_entities,同时定义了 cluster_graph、embed_graph 等操作,其中 cluster_graph 采用了 leiden 策略,具体代码位于 index/verbs/graph/clustering/cluster_graph.py。

- 可以看出,实际上就是加了一个 verb 装饰器而已,进一步跟进 strategy 的实现可以发现,这里的 leiden 算法实际上也是源自另一个图算法库 https://github.com/graspologic-org/graspologic
Pipeline
-
搞清楚了上述 workflow 的执行逻辑,再根据上节最后提到的编排日志,或者 artifacts/stats.json 文件,就可以整理出完整工作流了。
-
官方文档也放出了非常详细的说明,参见 https://microsoft.github.io/graphrag/posts/index/1-default_dataflow/
-
不过我这边依据源码提取出来的 pipeline 好像还是有些差异的,有做过相关工作的可以留言探讨下。
3.3 Query
查询阶段的 pipeline 相对而言要简单些,执行 query 的语句如下:

这里需要注意的是有 Global/Local search 两种模式,还是首先生成函数调用关系图,对整体结构能有个大致了解。
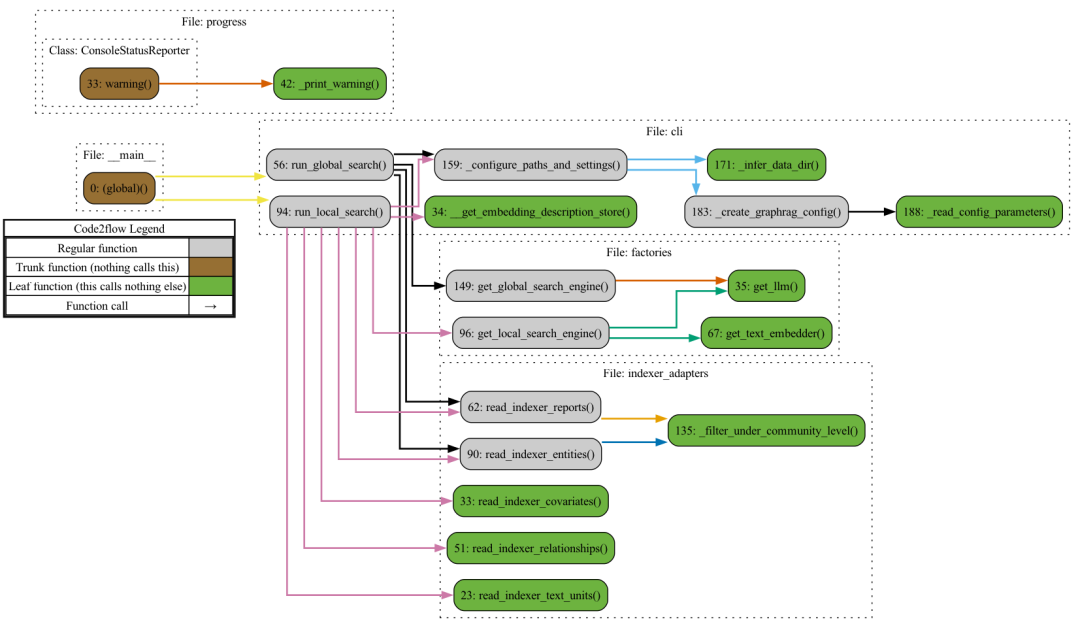
graphrag/query/__main__.py 中的主函数会依据参数不同,,分别路由至 cli::run_local_search() 以及cli::run_global_search()。
Global Search
cli::run_global_search() 主要调用了 factories.py::get_global_search_engine() 函数,返回一个详细定义的 GlobalSearch 类,进一步跟进去,发现该类跟 LocalSearch 类相似,都是基于工厂模式创建,其核心方法为 structured_search/global_search/search.py::GlobalSearch.asearch(),具体使用了 map-reduce 方法,首先使用大模型并行地为每个社区的 summary 生成答案,然后再汇总所有答案生成最终结果,此处建议参考 map/reduce 的相关 prompts,作者给出了非常详细的说明。
也正是因为这种 map-reduce 的机制,导致 global search 对 token 的消耗量极大。
Local Search
与全局搜索类似,cli::run_local_search() 函数主要也是调用了 factories.py::get_local_search_engine(),返回一个 LocalSearch 类,这里的 asearch() 相对比较简单,会直接根据上下文给出回复,这种模式更接近于常规的 RAG 语义检索策略,所消耗的 Token 也比较少。
与全局搜索不同的地方在于, Local 模式综合了 nodes、community_reports、text_units、relationships、 entities、covariates 等多种源数据,这一点在官方文档中也给出了非常详细的说明,,不再赘述。
4. 一些思考
GraphRAG 最核心的卖点就在于一定程度上解决了聚焦于查询的总结性(QueryFocused Summarization, QFS)任务, 这一点就个人了解到的应该还是首创。在此之前,,思路上最接近的应该就是 https://github.com/parthsarthi03/raptor,不过后者并非针对知识图谱。
QFS 与 Multi-Hop Q&A 应该是现阶段 RAG 系统都暂时无法解决的难点,但是对于很多场景,尤其是数据分析领域,却有着广泛的应用。虽然当下 GraphRAG 的使用成本还很高,不过至少提供了一种可能性。
此外,个人感觉相较于一般的知识图谱 RAG 项目,GraphRAG 给我印象更为深刻的:是内置了一套相对完整的工作流编排系统,这一点在其他 RAG 框架中还不多见。这可能也是后续一个值得深挖的方向,基于模板定义好大部分工作流,提供少部分的配置灵活性,每一个环节都可控可追溯,而不是一味地让大模型执行所有操作。
与之相对地,常规 RAG 部分,比如 embedding、retrieval 等环节反而没有太多需要讨论的地方,尽管加了个社区检测算法。
当然,本项目在知识图谱的处理颗粒度上也做得很细,比如社区检测的 leiden 算法,综合多源数据的 local search 等。一个有意思的点在于:项目中实体抽取相较于常规的一些基于 Pydantic 的思路,目前已经是完全采用大模型实现了,并且在三元组的 schema 方面也未设置任何约束。作者还简单解释了下:因为总是要做相似性聚类的,所以每次大模型抽取即使有些差异,最终社区的生成也不会有很大影响。这一点说实话在鲁棒性方面确实是很大的提升👍。
我个人觉得目前的 GraphRAG 也仍旧还有很多值得改进的地方,比如搞了很多让人云里雾里的名词,诸如 Emit、Claim、Verbs、Reporting 之类,同时夹带私货,用了一些微软自家的相对比较小众的库,这也进一步加大了理解上的难度,此外模块化方面应该也有待加强,尤其是 OpenAI 那块,耦合严重。
综合来看,微软本次放出的 GraphRAG 框架确实有不少干货,值得花些时间去仔细研读和思考。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 516
516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}