






告诉大家一个非常残忍的答案,以后所有论文都会被查ai的。
在考虑使用AI撰写学术论文的便捷性时,你可能会问:学术界难道没有预见到这种行为吗?答案是肯定的。学术界不仅关注传统的抄袭问题,还针对AI生成内容(AIGC)增加了一项名为“AIGC检测”的指标。这一检测的目的,正是为了识别和惩处那些不假思索、完全依赖AI自动生成论文的行为。
用GPT写论文虽然重复率基本不用担心,但是AIGC疑似度是无法保证的呀!所以我们一定要做好措施来保证自己的论文通过AIGC检测,这里推荐两种方法!
第一种方法是自己使用人类语言修改论文内容来降低AI痕迹,比如删除逻辑性较强的词汇,增加富有情感色彩的词汇,比如重新组织语言复述过于规整的句子……这种方法过于耗费时间且低效,并不一定有用,所以都来试试第二种方法,保证有效!
那就是使用AI产品降低AI痕迹!!!!
很多人了解到了用AI写论文,却鲜少有人知道还可以用AI内容检测器降低论文AI痕迹,如果你知道了,那你已经打败了99%的同学。这种aigc降重技术并不仅仅是简单的降重或润色,背后的算法是完全不同的,市面上能有效执行此功能的产品寥寥无几,这里推荐一款专门降低论文AI痕迹的产品,非常适合希望提升论文原创性的学者。链接如下↓
https://ibiling.cn/paper-pass?from=csdnpss09
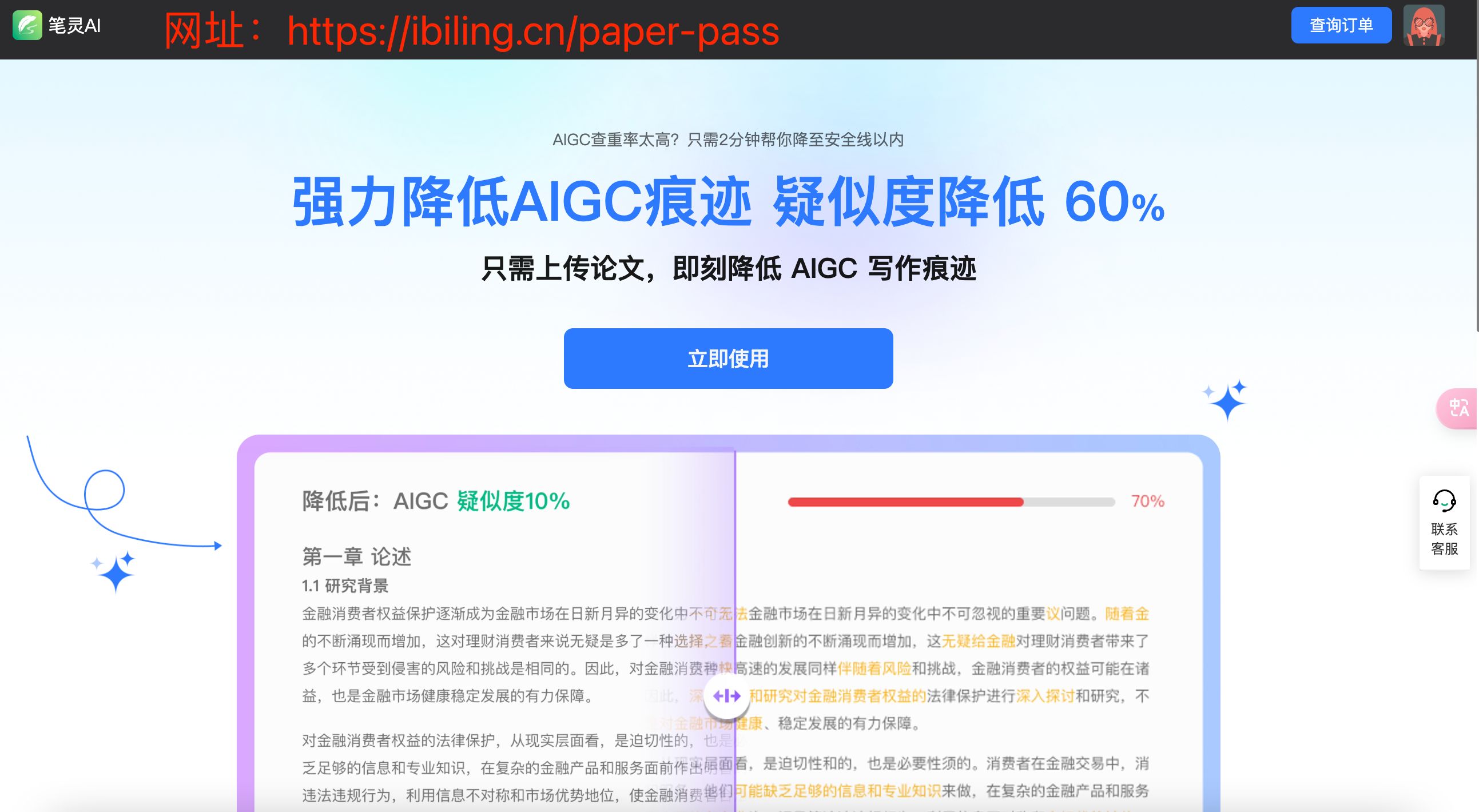
我亲自为大家进行了深度试用,效果确实令人惊艳,因此才敢放心推荐。经过试用,AIGC疑似度成功降低了约50%,也是牛牛的很安心!而且它价格巨便宜,2.5元/千字,改一整份毕业论文也才二三十块钱,这个价格还不冲等什么!!!

首先能上传word/PDF等文档就很nice,意味着不用自己一段一段复制粘贴。如果你是部分段落要进行降痕,也可以选择粘贴文本,此操作很简单,一点不复杂。
我上传了之后发现,它除了英文摘要和致谢暂时不能修改之外,其他论文内容都修改了!下面我将放出修改前后的片段进行对比!
以下是修改前一片红,简直惨不忍睹啊……

修改之前句式和风格一致性,缺乏自然语言的多样性和随机性。例如,多处出现重复的词汇和短语,如“我们将...”。细看内容,就是在泛泛而谈,没有具体的数据、实例或深入的分析来支持其论点。这种缺乏具体细节和深度的情况也符合AI生成文本的特点。
再来看看修改后的,AIGC疑似度大幅度降低。语言表达丰富了,不再拗口难读,甚至带上了一些情感色彩,虽然内容修改的还不够深入,但是AIGC疑似度就是神奇地消失了!

所以对ai检测心存顾虑的同学不妨体验一下咯~学会使用AI能帮助我们太多事情了,AI可能并不会淘汰人,但能淘汰不会使用AI的人!现在就开始,让AI成为你工作和学习的助力,保持在竞争中的优势!

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









