






一、numpy
(一)、array创建数组
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
| 名称 | 描述 |
|---|---|
| object | 数组或嵌套的数列 |
| dtype | 数组元素的数据类型,可选 |
| shape | 数组维度,几行几列,可选 |
| order | 创建数组的样式,C为行方向,F为列方向,A为任意方向(默认) |
| subok | 默认返回一个与基类类型一致的数组 |
| ndmin | 指定生成数组的最小维度 |
(二)、arange创建数组
numpy.arange([start,] stop[, step,], dtype=None)
| 参数 | 描述 |
|---|---|
| start | 起始值,默认为0 |
| stop | 终止值(不包含) |
| step | 步长,默认为1 |
| dtype | 返回ndarray的数据类型,如果没有提供,则会使用输入数据的类型。 |
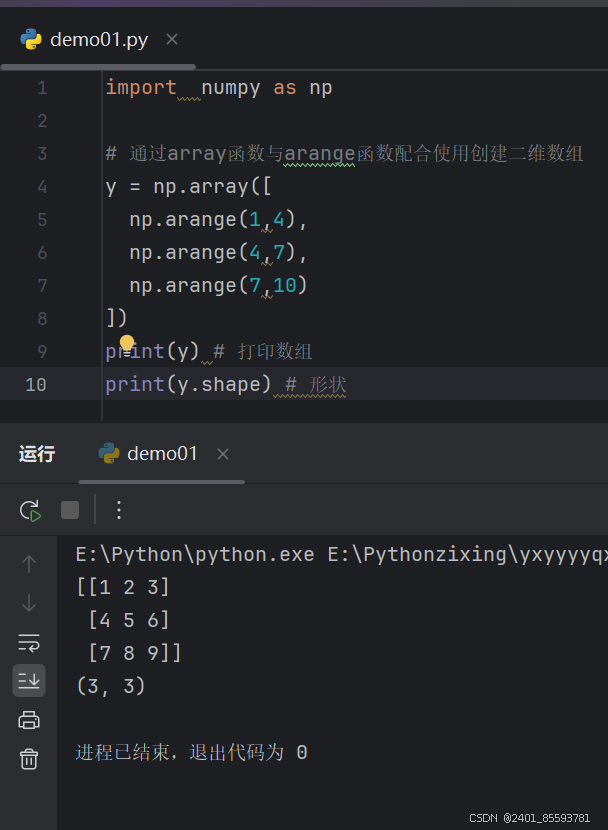
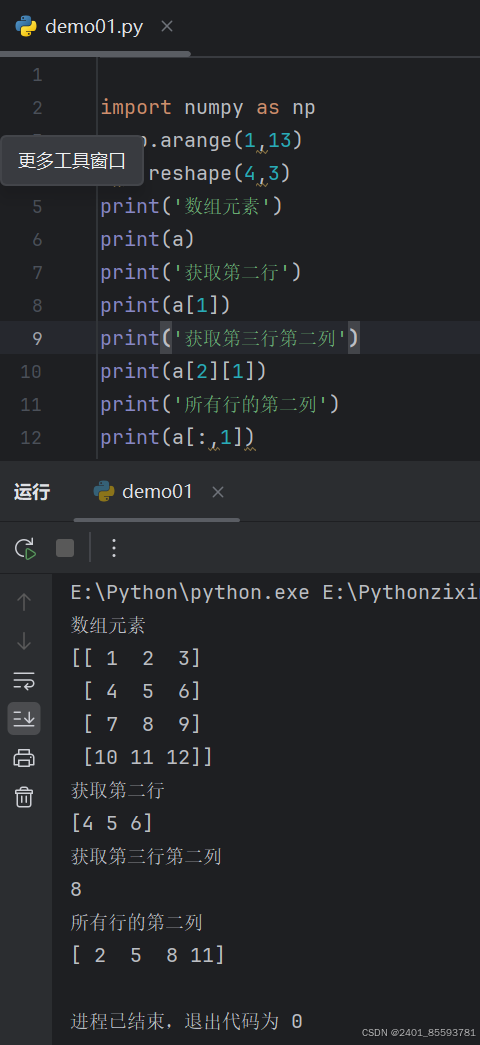
(三)、ndarray 对象
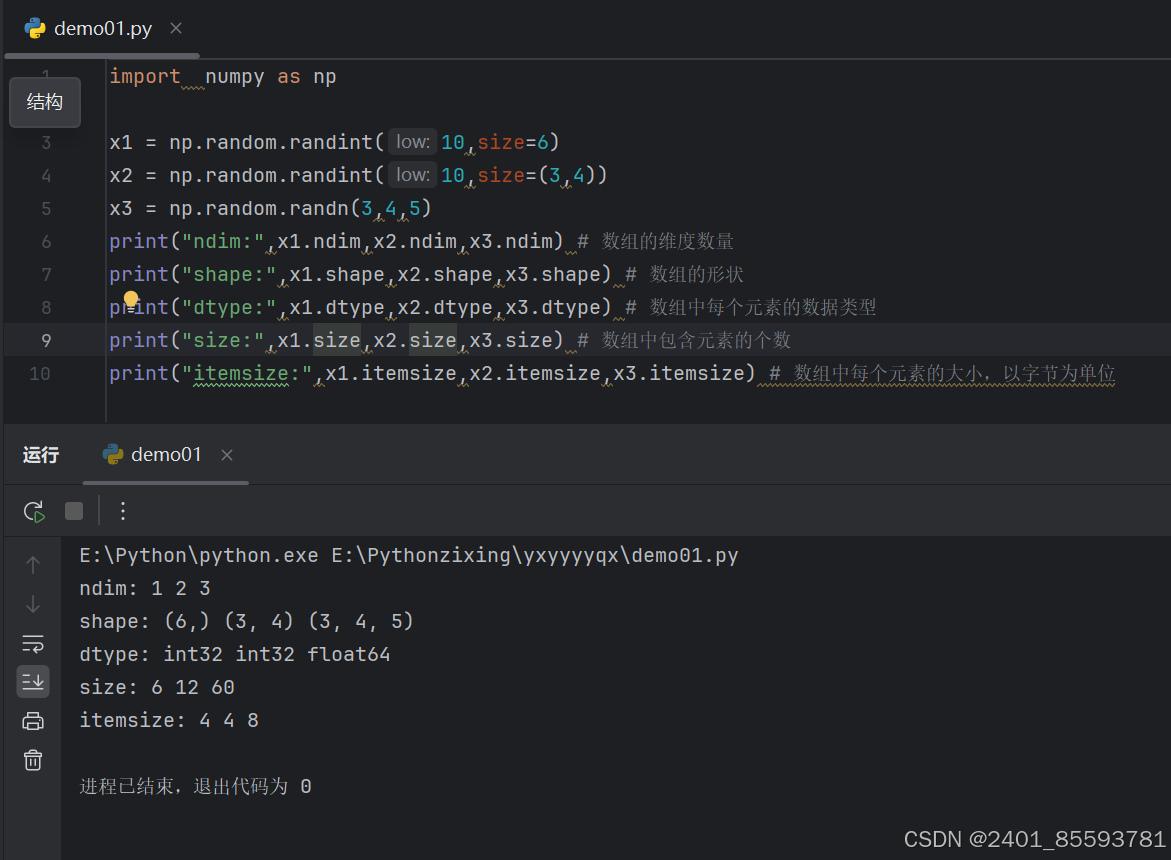
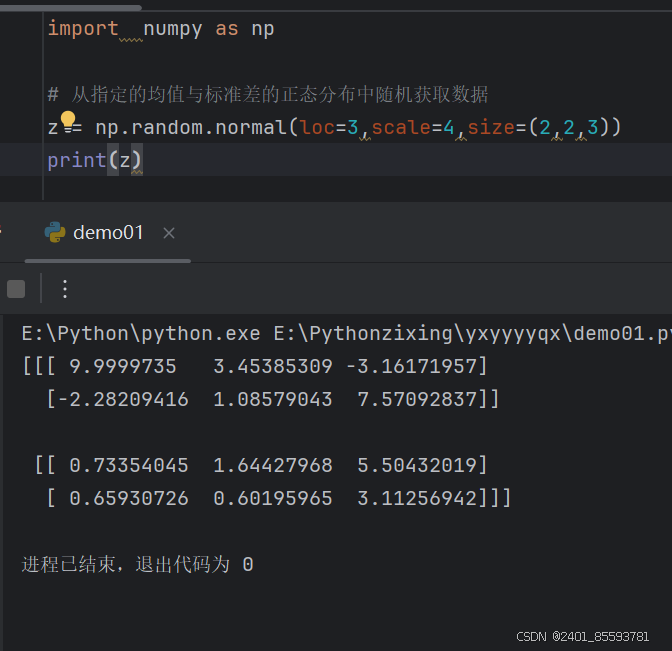
(四)、随机数创建(正态分布、期望方差)
numpy.random.random(size=None)
| 函数 | 说明 |
|---|---|
| seed | 确定随机生成器种子 |
| permutation | 返回一个序列的随机排列或返回一个随机排列的范围 |
| shuffle | 对一个序列就地随机排列 |
| rand | 产生均匀分布的样本值 |
| randint | 该方法有三个参数low、high、size三个参数。默认high是None,如果只有low,那范围就是[0,low)。如果有high,范围就是[low,high)。 |
| random(size=None) | 该方法返回size个随机数个数 |
| randn(d0,d1,…,dn) | randn函数返回一个或一组样本,具有标准正态分布(期望为0,方差为1)。dn表格每个维度,返回值为指定维度的array |
demo01.期望和方差的正态分布
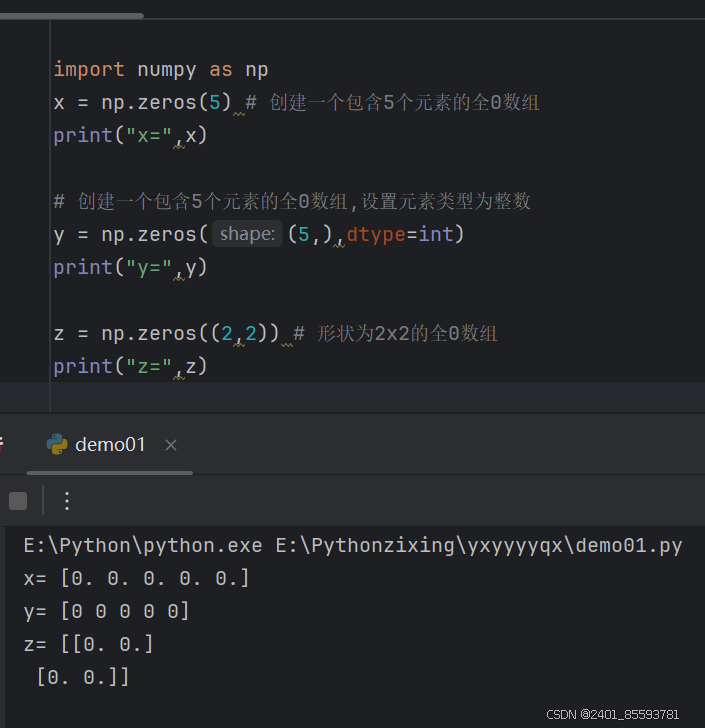
(五)、zeros函数创建数组
ones、empty函数使用方式同下
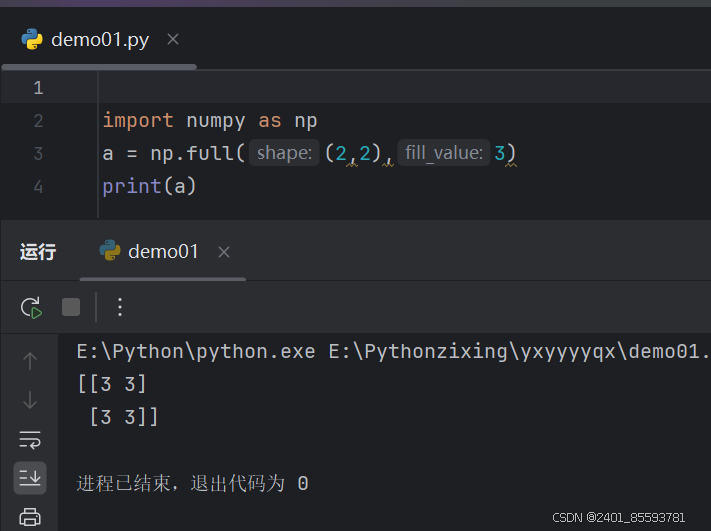
(六)、full 函数指定值创建数组
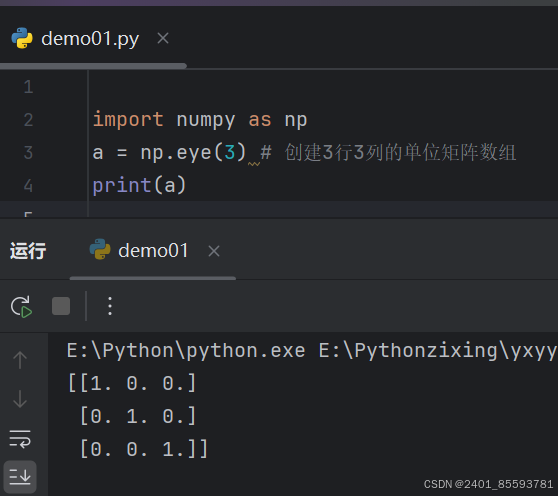
(七)、eye 函数创建单位矩阵
矩阵相乘 dot
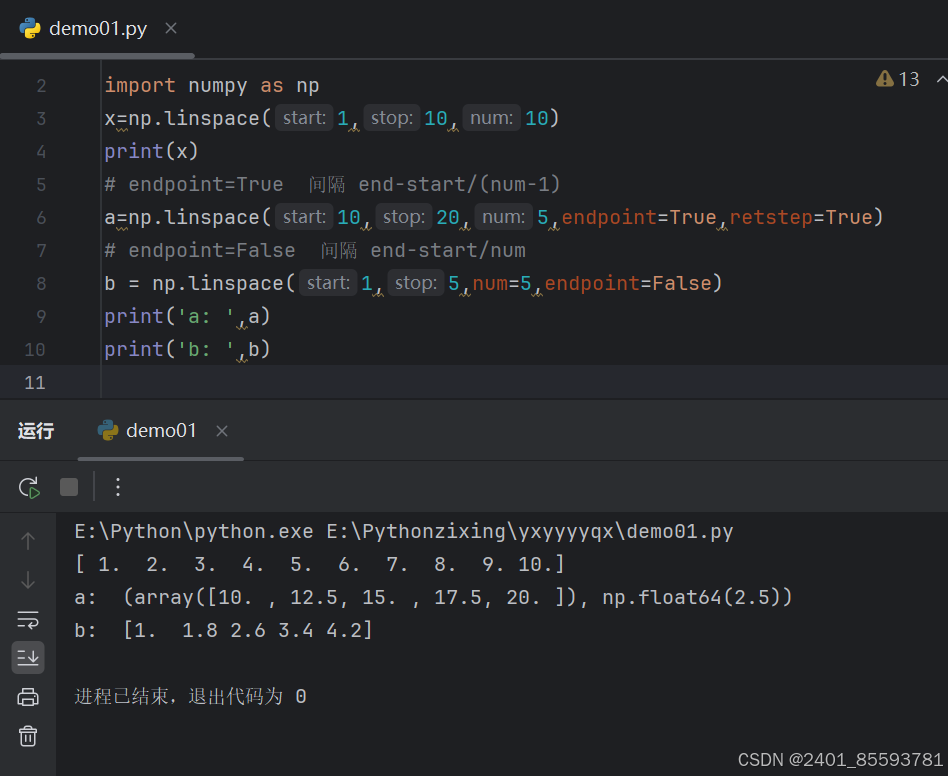
(八)、linspace 函数创建等差数列数组
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
| 参数 | 描述 |
|---|---|
| start | 序列的起始值 |
| stop | 序列的终止值,如果endpoint为true,该值包含于数列中 |
| num | 要生成的等步长的样本数量,默认为50 |
| endpoint | 该值为 Ture 时,数列中中包含stop值,反之不包含,默认是True。 |
| retstep | 如果为 True 时,生成的数组中会显示间距,反之不显示。 |
| dtype | ndarray 的数据类型 |
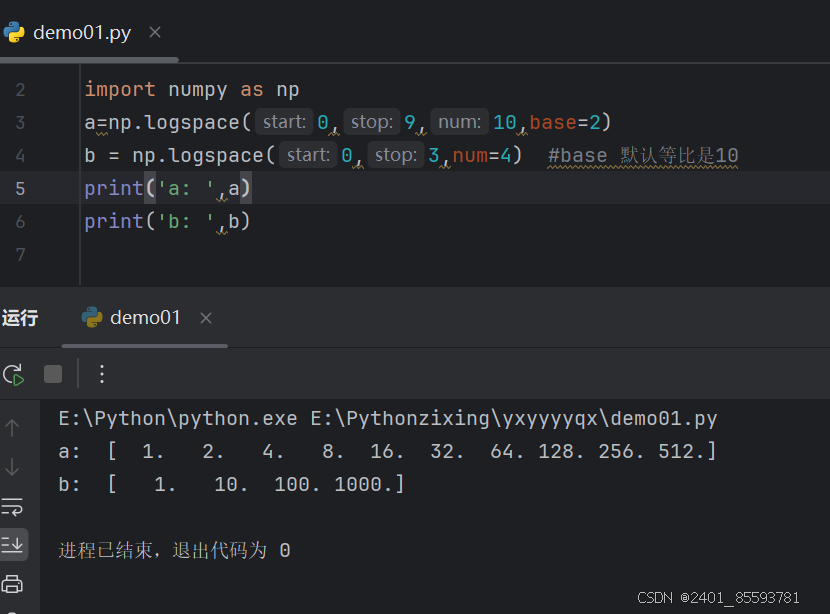
(九)、logspace创建等比数组
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
| 参数 | 描述 |
|---|---|
| start | 序列的起始值为:base ** start |
| stop | 序列的终止值为:base ** stop。如果endpoint为true,该值包含于数列中 |
| num | 要生成的等步长的样本数量,默认为50 |
| endpoint | 该值为 ture 时,数列中中包含stop值,反之不包含,默认是True。 |
| base | 对数 log 的底数。 |
| dtype | ndarray 的数据类型 |
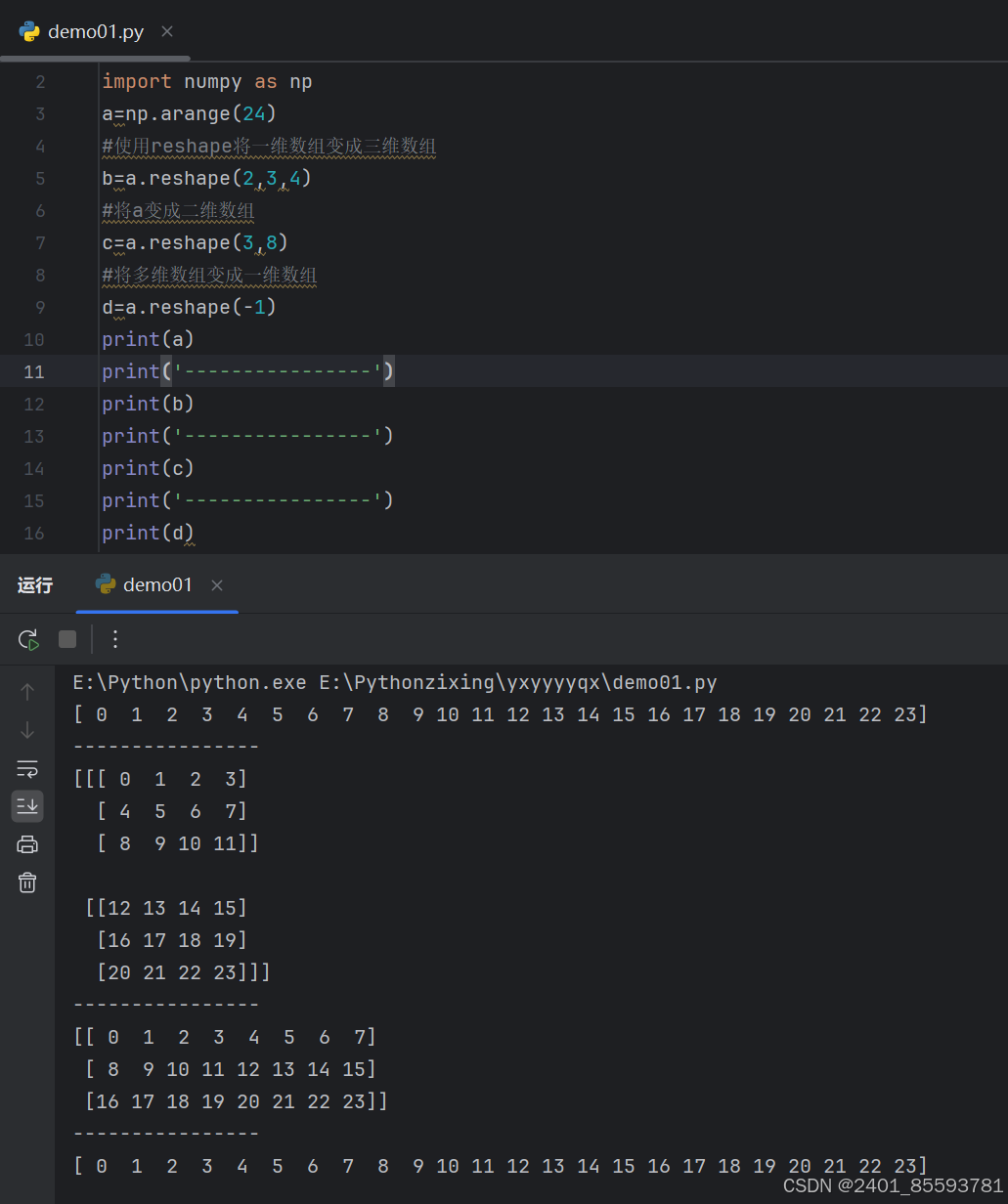
(十)、改变数组的维度
通过ravel方法或flatten方法可以将多维数组变成一维数组。
- ravel() 返回的是视图,会影响原始数组;
- flatten() 返回的是拷贝,对拷贝所做的修改不会影响原始数组。
改变数组的维度还可以直接设置numpy数组的shape属性(元组类型),通过resize方法也可以改变数组的维度。
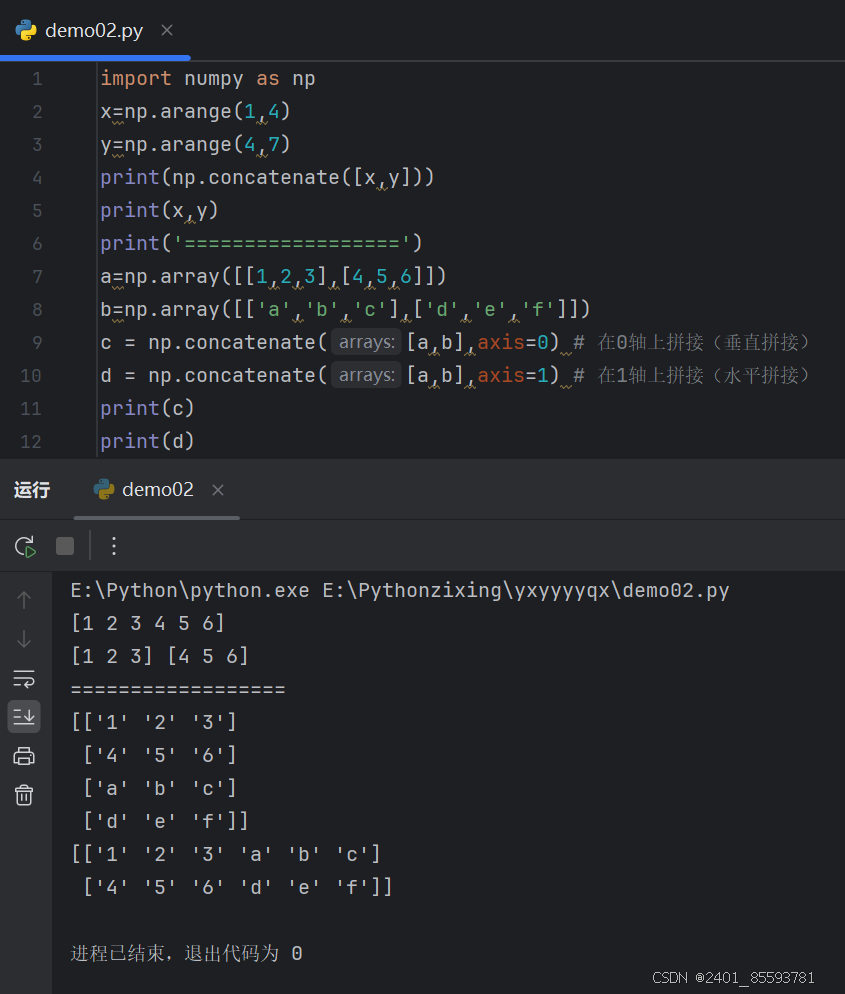
(十一)、数组的拼接
numpy.concatenate((a1, a2, ...), axis)
| 函数 | 描述 |
|---|---|
| concatenate | 连接沿现有轴的数组序列 |
| hstack | 水平堆叠序列中的数组(列方向) axis=1 |
| vstack | 竖直堆叠序列中的数组(行方向) axis=0 |
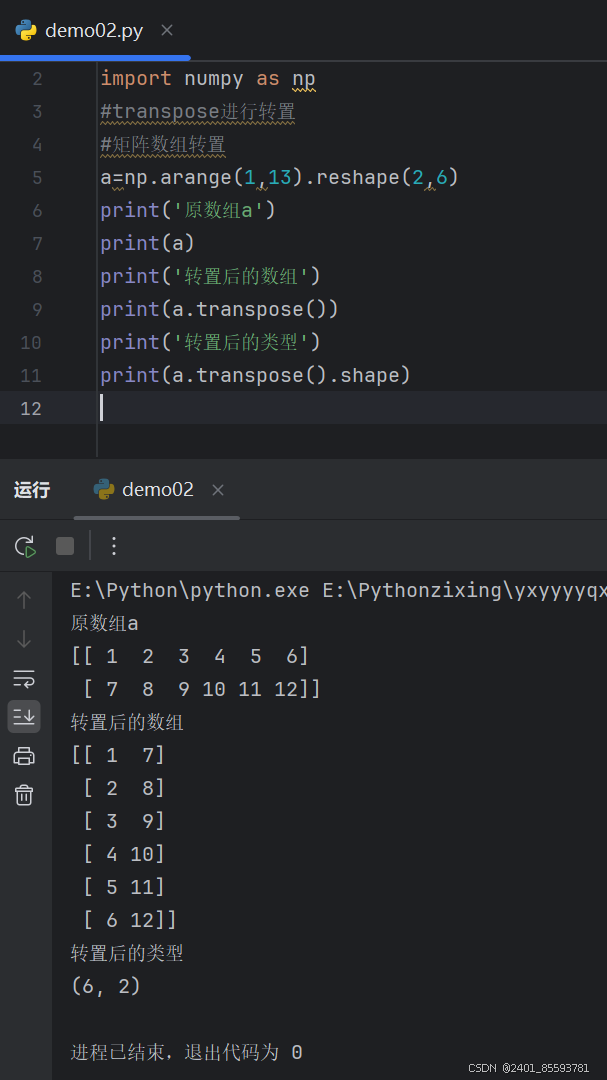
 (十二)、数组的转置
(十二)、数组的转置
(十三)、数学函数
| 方法 | 说明 |
|---|---|
| np.abs()、np.fabs() | 计算整数、浮点数的绝对值 |
| np.sqrt() | 计算各元素的平方根 |
| np.reciprocal() | 计算各元素的倒数 |
| np.square() | 计算各元素的平方 |
| np.exp() | 计算各元素的指数ex |
| np.log() np.log10() np.log2() | 计算各元素的自然对数、底数为10的对数、底数为2的对数 |
| np.sign() | 计算各元素的符号,1(正数)、0(零)、-1(负数) |
| np.ceil() np.floor() np.rint() | 对各元素分别向上取整、向下取整、四舍五入 |
| np.cos() 、np.sin()、np.tan() | 对各元素求对应的三角函数 |
| np.add()、np.subtract()、np.multiply()、np.divide() | 对两个数组的各元素执行加法、减法、乘法、除法 |
(十四)、统计函数
| 函数名 | 说明 |
|---|---|
| np.sum() | 求和 |
| np.prod() | 所有元素相乘 |
| np.mean() | 平均值 |
| np.std() | 标准差 |
| np.var() | 方差 |
| np.median() | 中数 |
| np.power() | 幂运算 |
| np.sqrt() | 开方 |
| np.min() | 最小值 |
| np.max() | 最大值 |
| np.argmin() | 最小值的下标 |
| np.argmax() | 最大值的下标 |
| np.ptp() | 计算一组数中最大值与最小值的差,可指定轴 |
| np.unique() | 删除数组中的重复数据,并对数据进行排序 |
| np.nonzero() | 返回数组中非零元素的索引 |
二、pands
(一)、DataFrame 二维数组对象创建
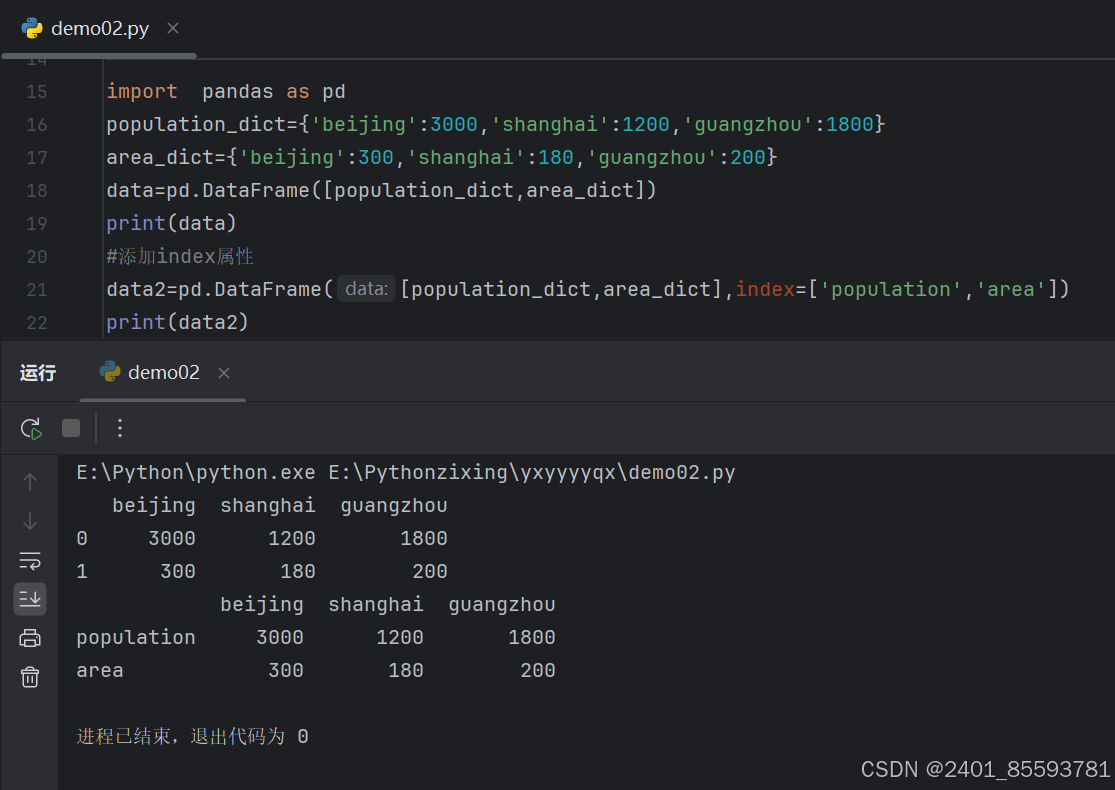
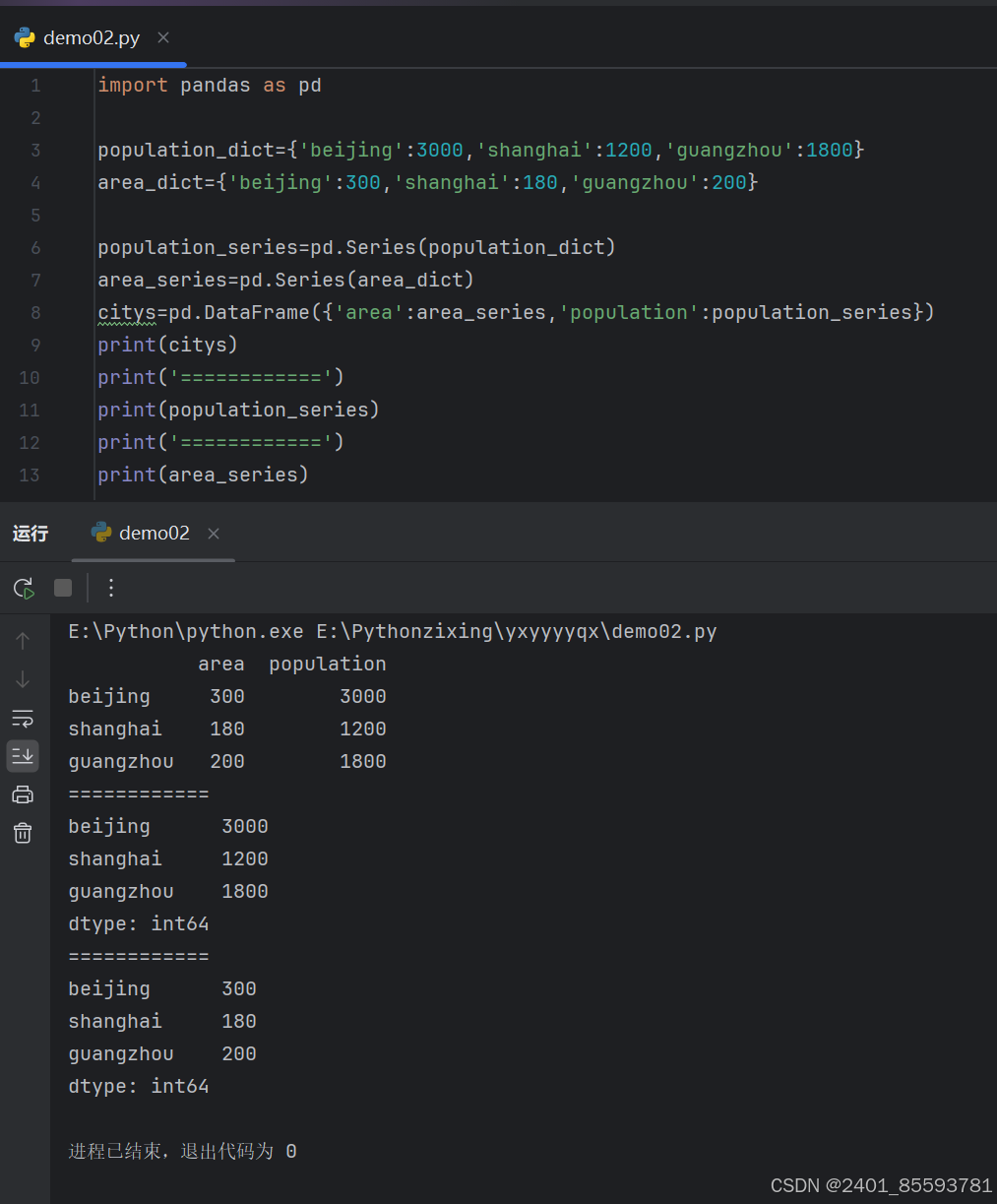
(二)、读取文件
1.读取 Excel 文件
pandas读取excel的方式介绍、行列元素访问以及读取数据后使用matplotlib画折线图-CSDN博客
2.读取 csv 文件
【数据处理】Pandas读取CSV文件示例及常用方法(入门)-CSDN博客
示例:导入.csv文件,文件编码格式是gbk
pd.read_csv('stu_data.csv',encoding='gbk')
3.读取 txt 文件
示例:导入.txt文件
pd.read_table('test_data.txt',encoding='utf-8',sep='\t')
4.读取 数据库 文件

(三)、保存文件
1.保存数据-外部文件(csv、excel)

2.保存数据-数据库
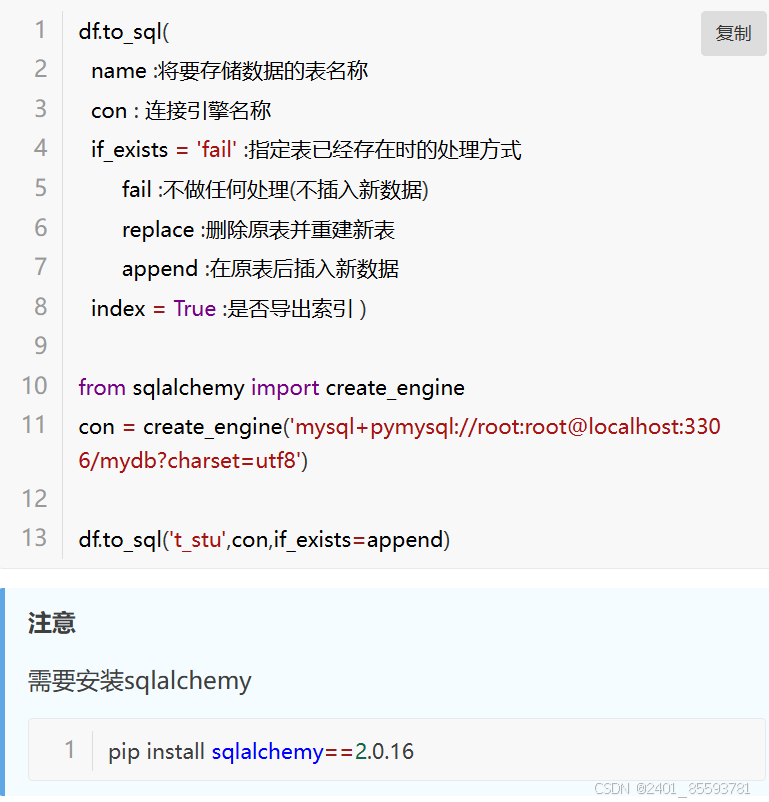
(四)、操作列
1.修改列名、删除列、获取列
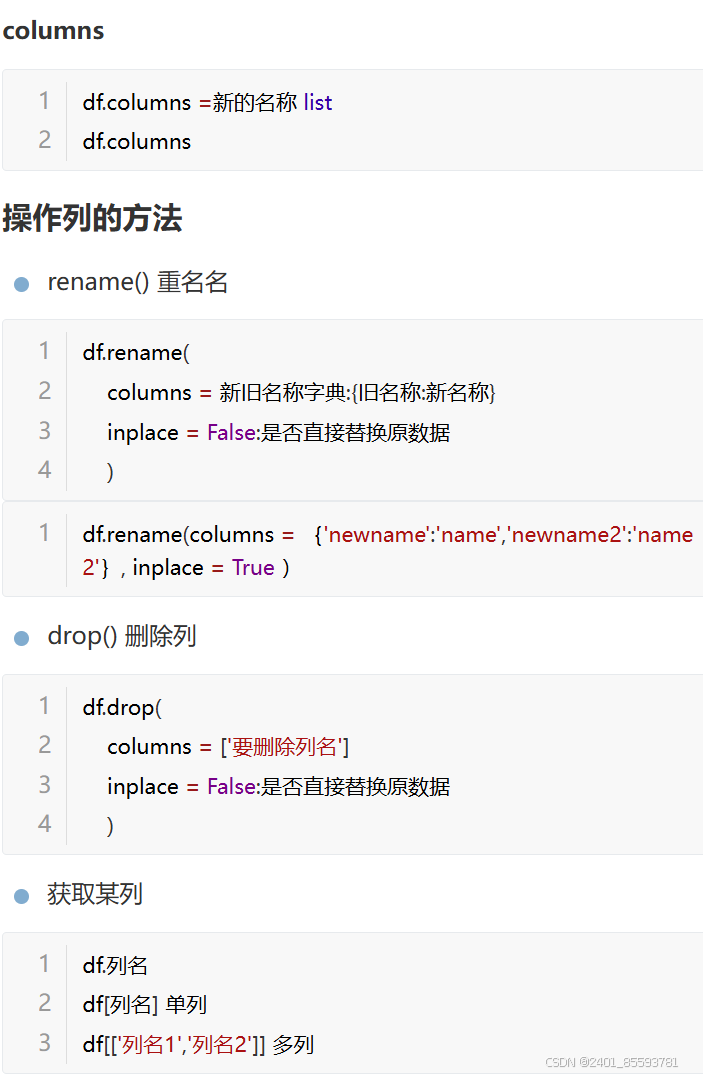
2.增加新列

3.通过函数计算变量的值
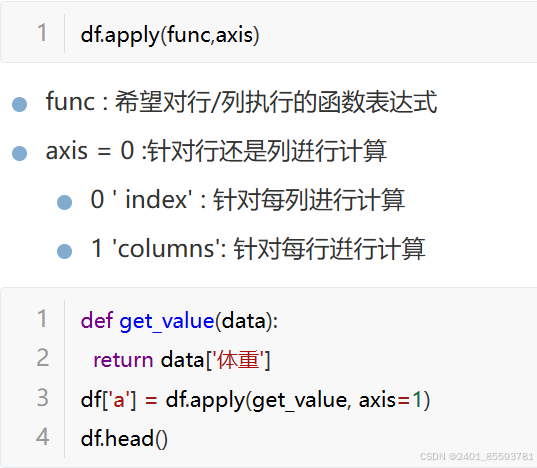
4.在指定位置插入新变量列

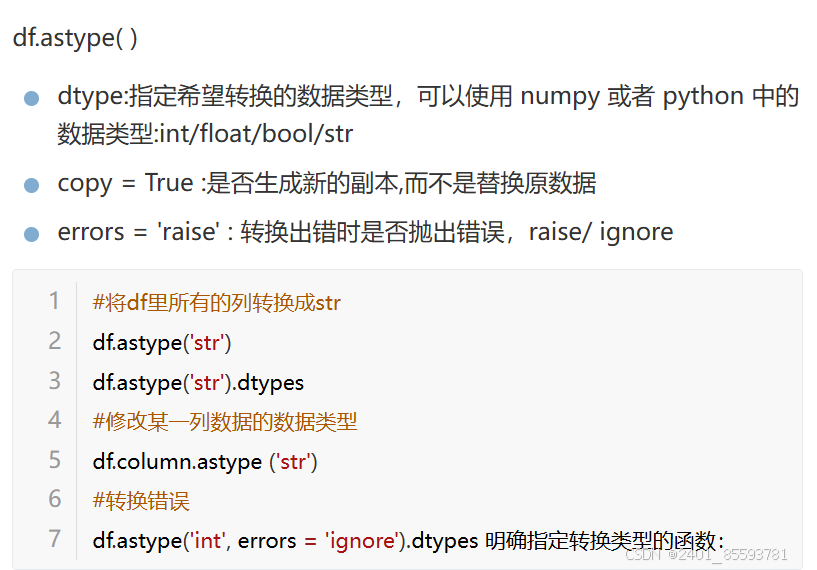
5.数据类型转换
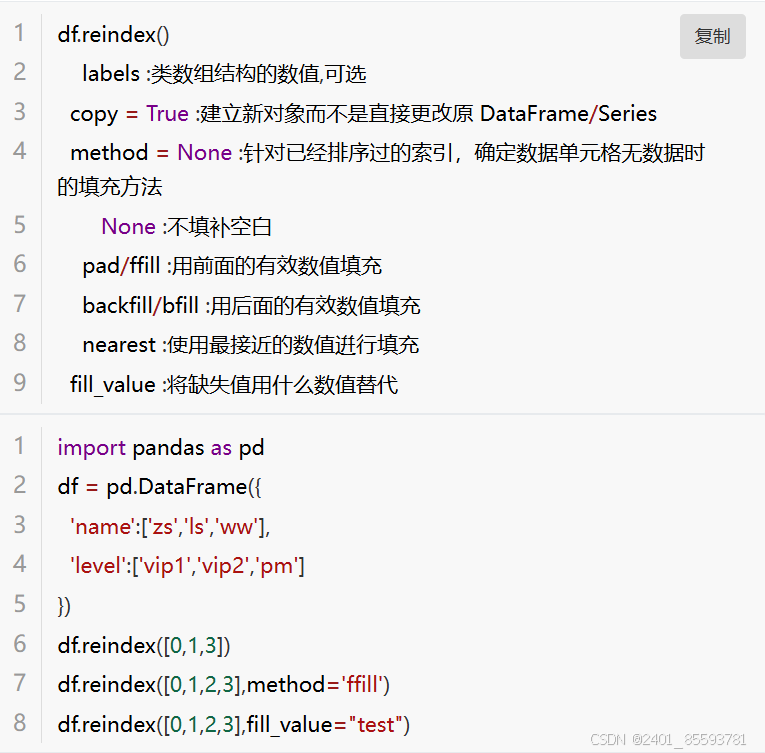
(五)、更新索引
在Pandas中,提供reindex方法,可以作用在DataFrame或Series。功能是:
- 添加索引
- 删除现在索引
- 对数据进行重新排序
- 调整DataFrame或Series的索引顺序
(六)、替换修改值
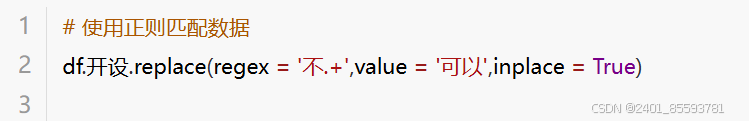
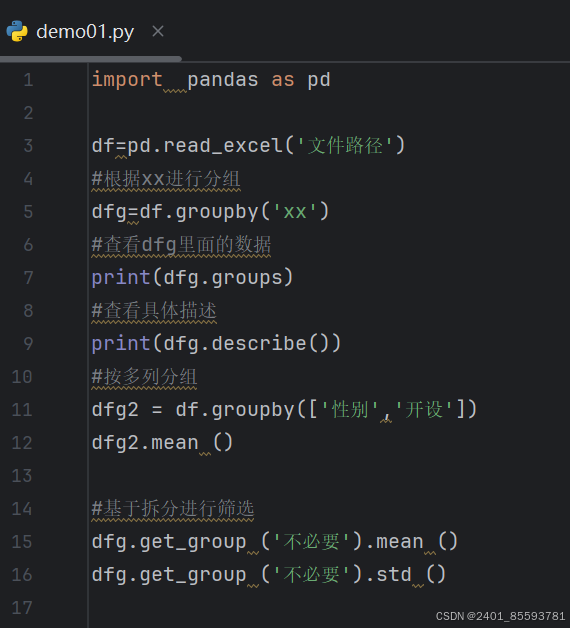
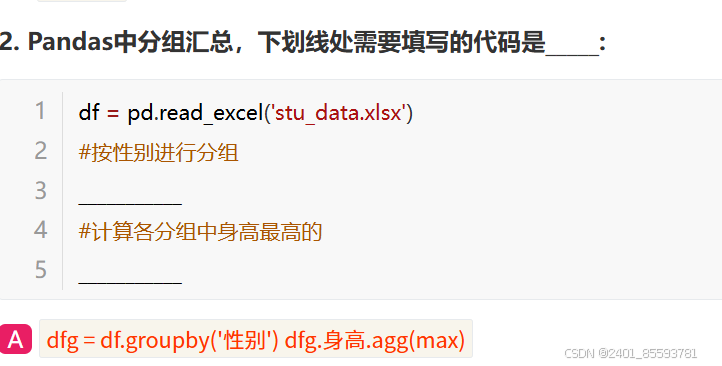
(七)、变量值的分组

(八)、变量值的分箱

(九)、长宽格式转换

(十)、数据的操作
1.merge 合并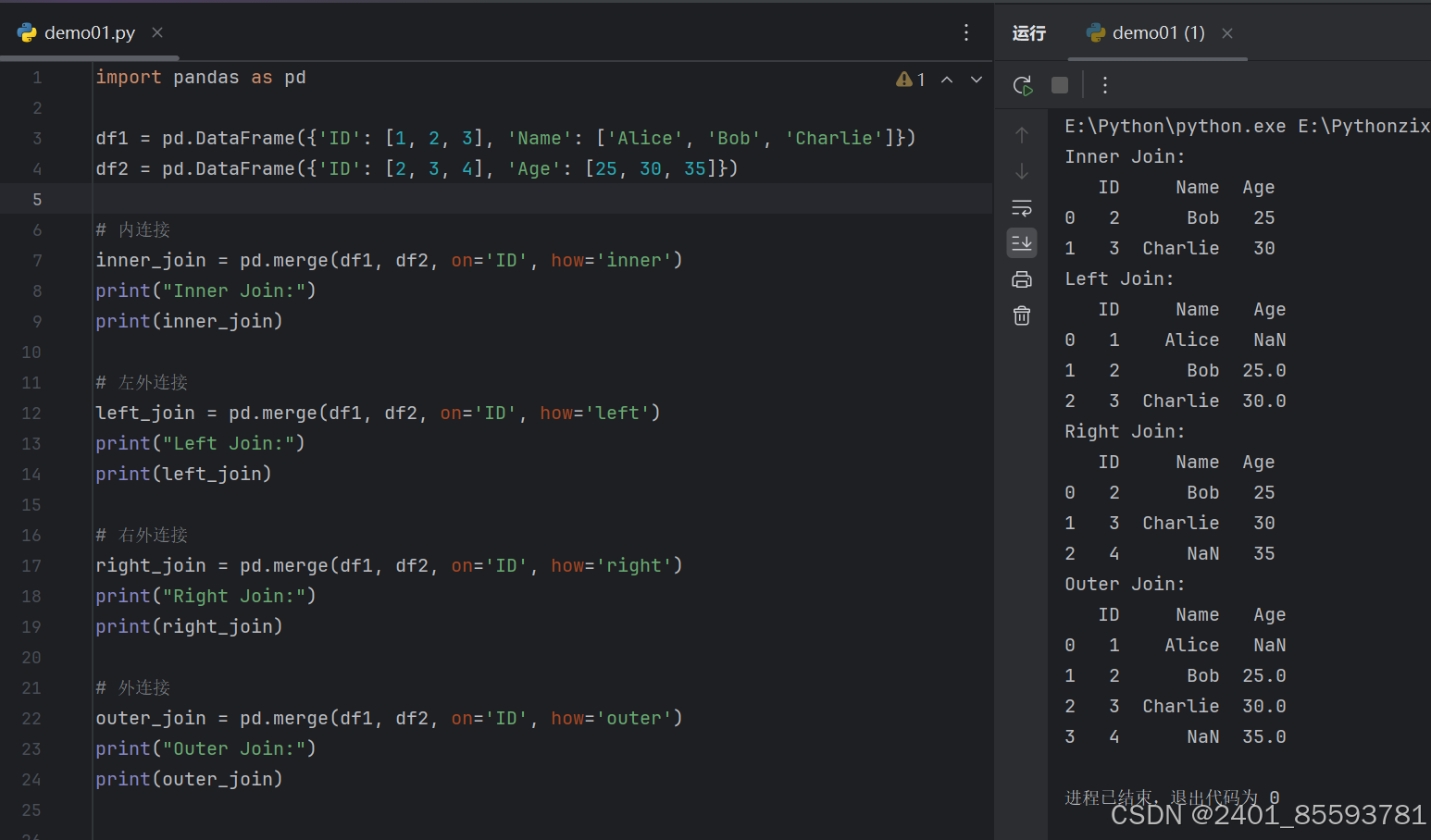
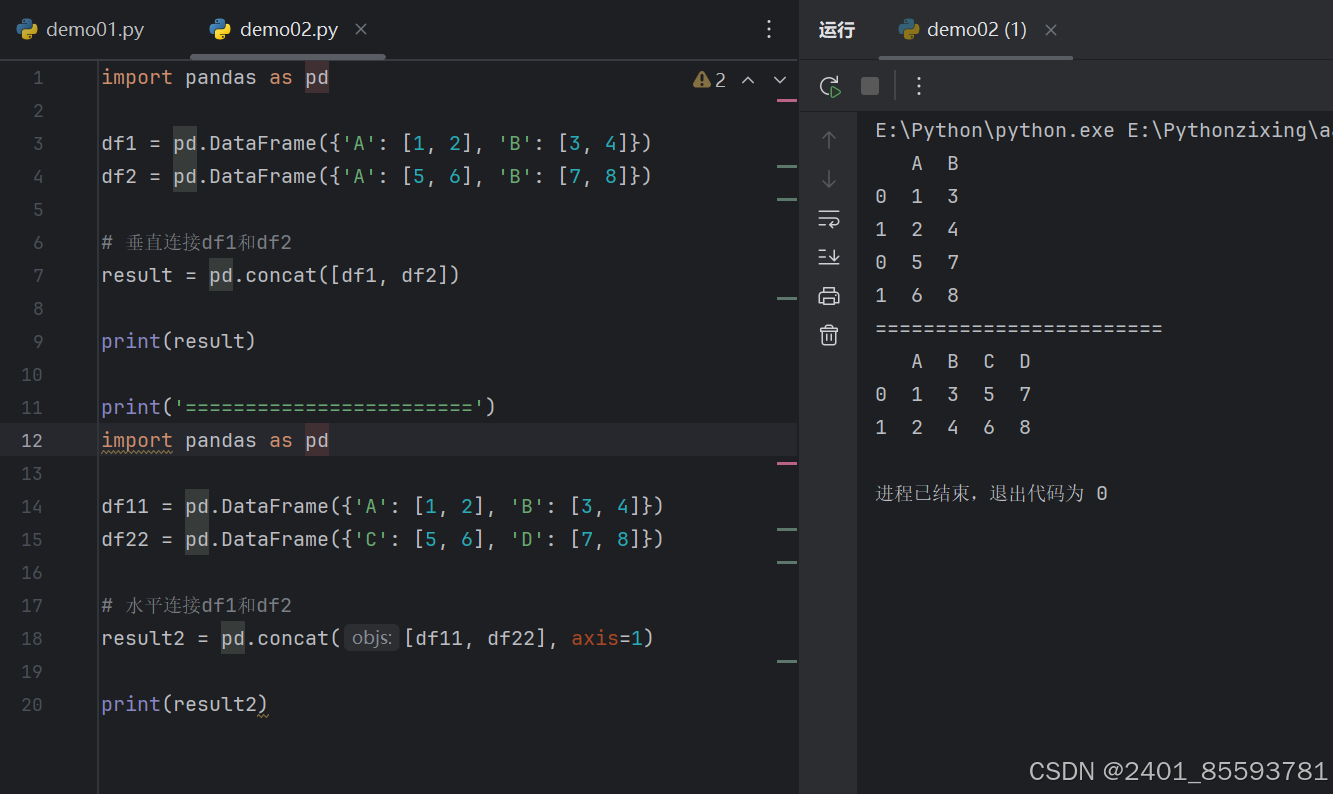
2.concat 拼接
3.查重
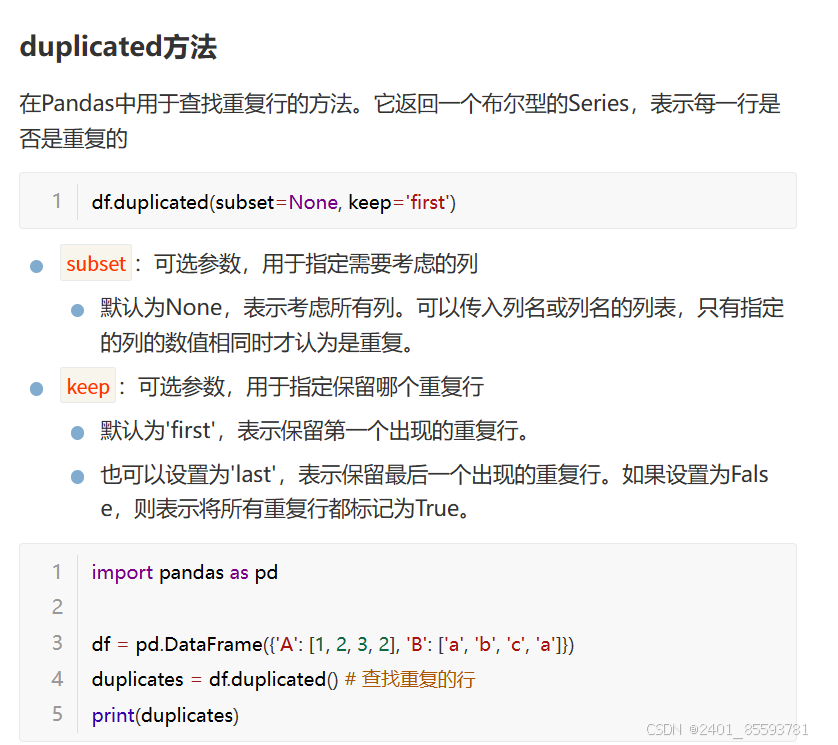
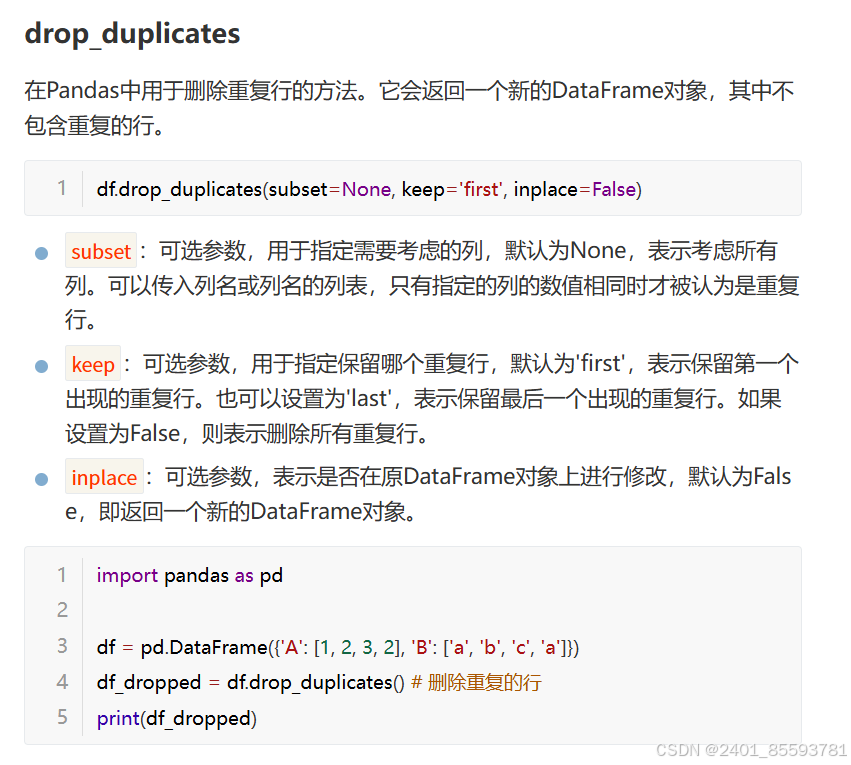
4.统计次数
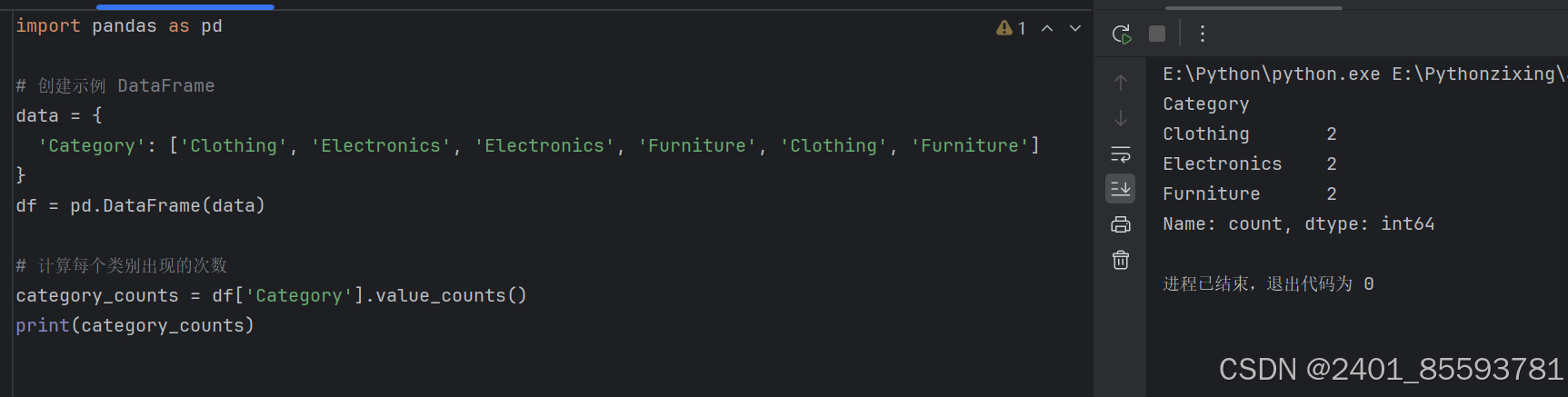
5.数据按照索引排序

6.数据按照变量值排序

(十一)、表
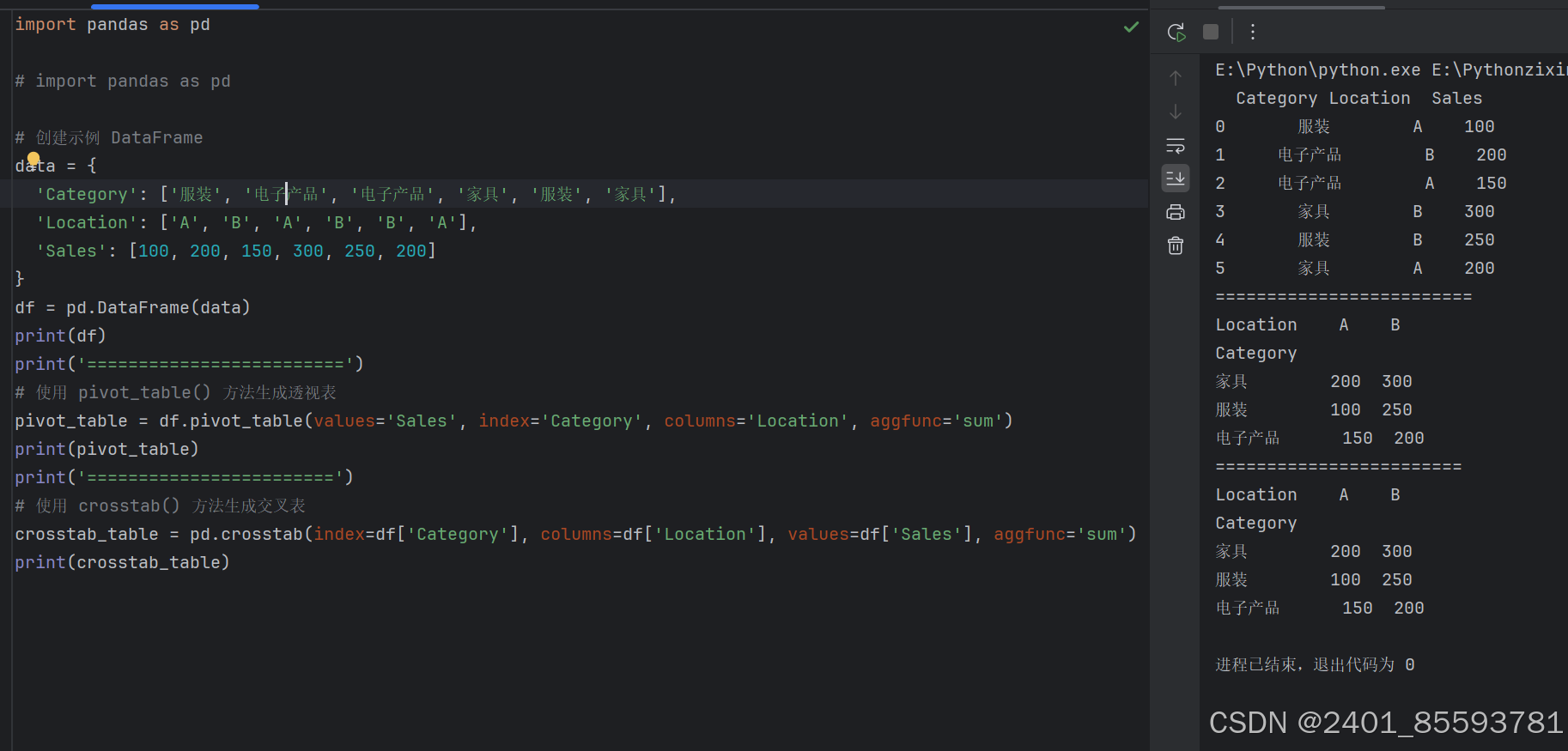
1.透视表

2.交叉表
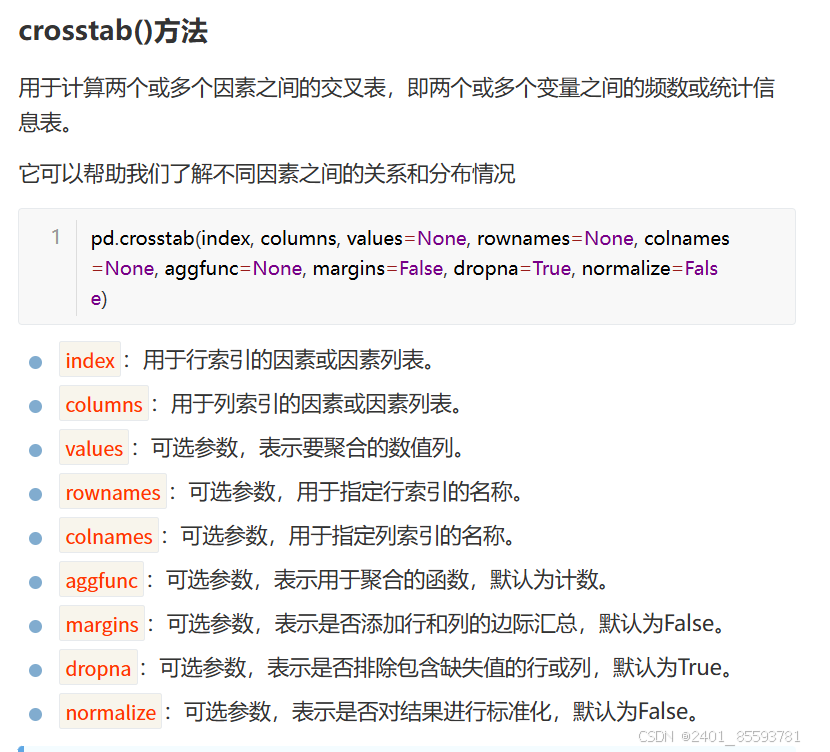
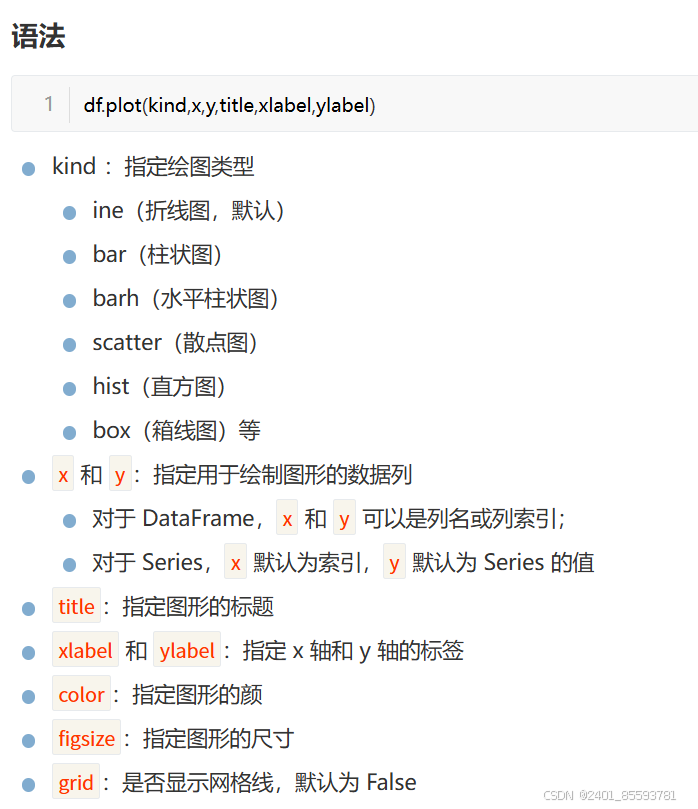
3.图表的基本使用
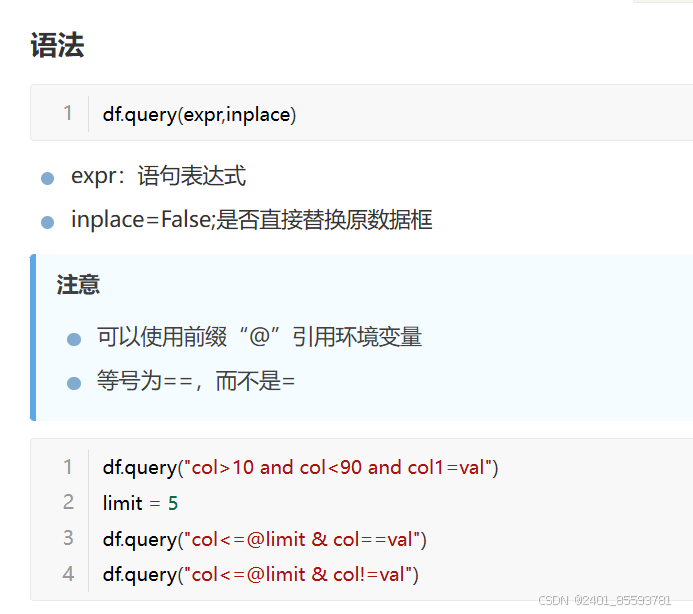
(十二)、筛选条件 query



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









