






在之前的笔记中有简单了解了一下职业插画师们是如何将一张草稿转变为一小段CG的,就是通过ControlNet+Gen2的方式。
这种方式其实非常简单且好上手,需要的也只是一双会画草稿的手和在Gen2买个订阅不然只能生成25秒。
在那会我就提到了另一个东西-ComfyUI,经常用ControlNet的小伙伴估摸着会想起来了,WebUI里面的这个ComfyUI是不是今天要学的那一个。
在这里是也可以不是,ComfyUI可以看作是和WebUI一样的AI绘画工具。
虽然都是基于Stable Diffusion,但是ComfyUI是一个基于节点流程式的Stable Diffusion绘画工具。
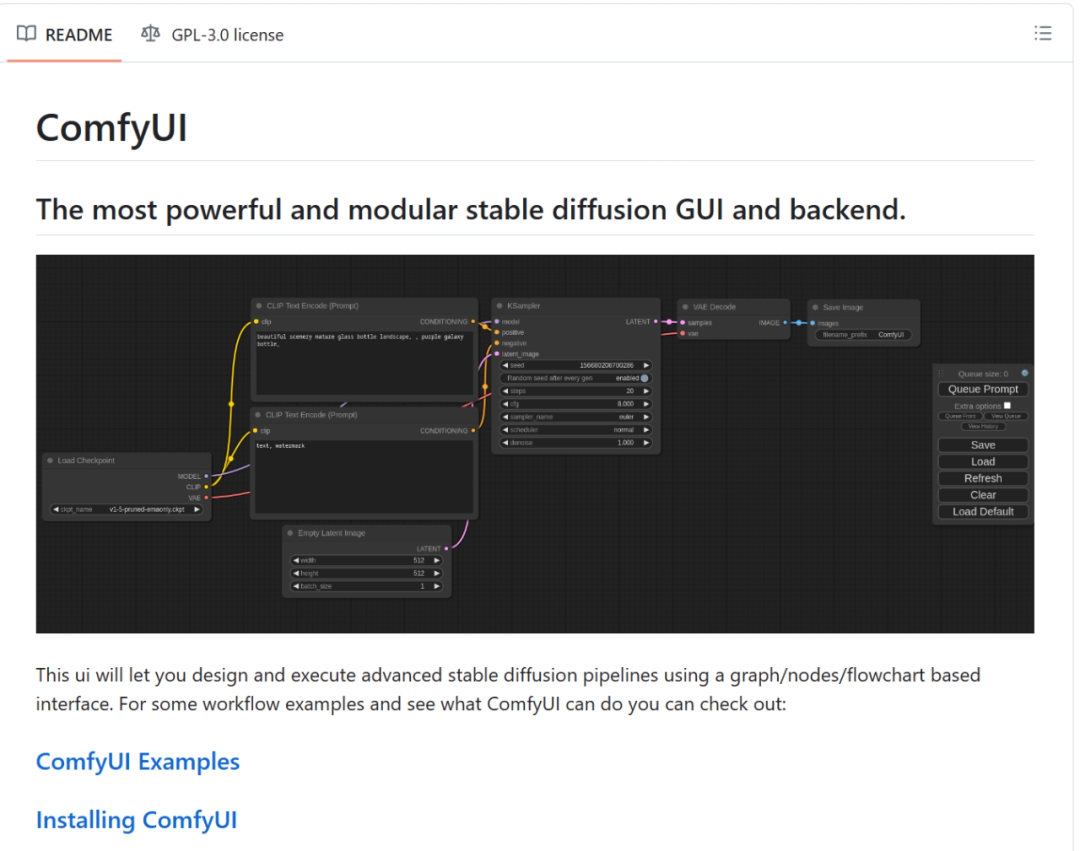
这个节点流程式光说可能不好理解,我放一张图就好懂了:
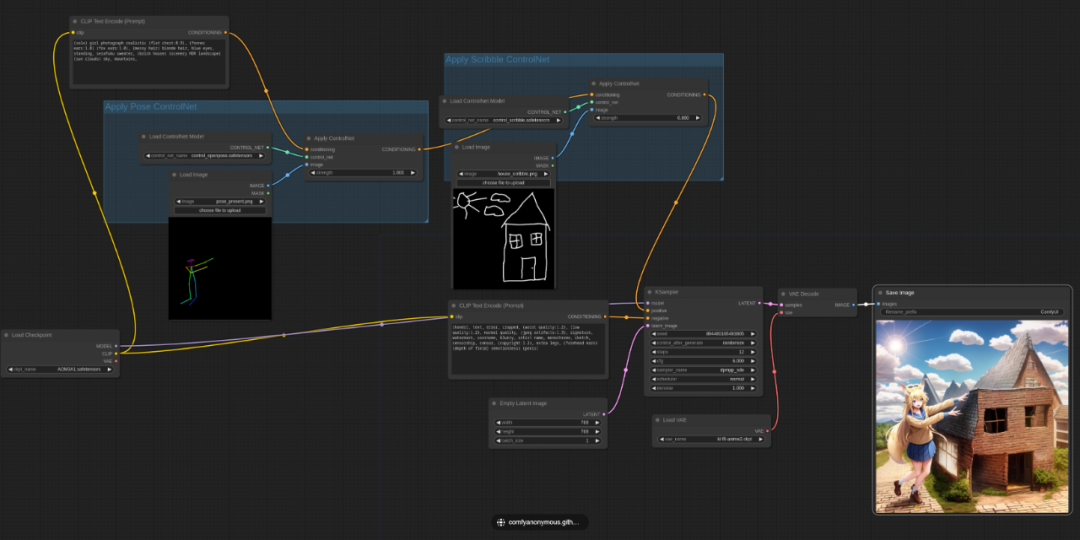
ControlNet and T2I-Adapter Examples | ComfyUI_examples (comfyanonymous.github.io)
像是之前学习过Blender或者了解过UE等节点式软件的同学可能会熟悉一些,不了解也没关系,看着复杂其实也不难上手。
ComfyUI本质上是通过将stable diffusion的流程拆分成一个个模块,一个方框里的功能对应WebUI中的一个功能。
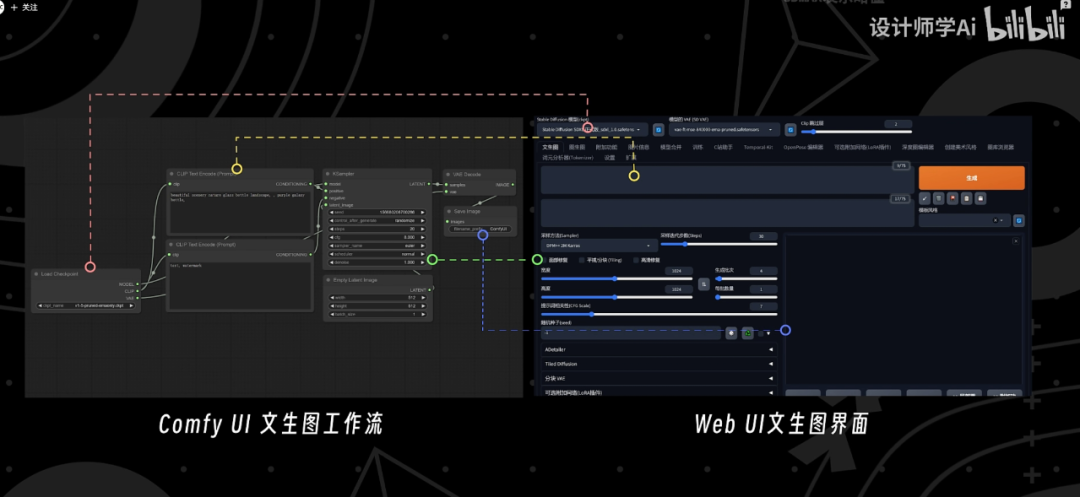
这样做的好处是可以实现更加精准的工作流定制和完善的可复现性。
像是图生图工作流、lora工作流、controlnet-depth工作流、impaint工作流等都是在WebUI中学习过的。
而ComfyUI的特别之处是在于处理长线复杂的大型工作中可以搭建定制工作流程,系统会排队处理任务,这样就不需要坐在电脑前等待漫长的渲染。
ComfyUI在SDXL模型方面只需要4G的显存就能有更快的加载速度,而WebUI则需要8G的显存,并且在生成大型图片的时候不会爆显存。
就SDXL这个官方大模型上看,ComfyUI有着越来越大的优势。

ComfyUI的下载和安装
下载:
进入到ComfyUI的官方Github链接:
https://github.com/comfyanonymous/ComfyUI
在下方的README中有一个Installing ComfyUI的选项,点击那个链接。
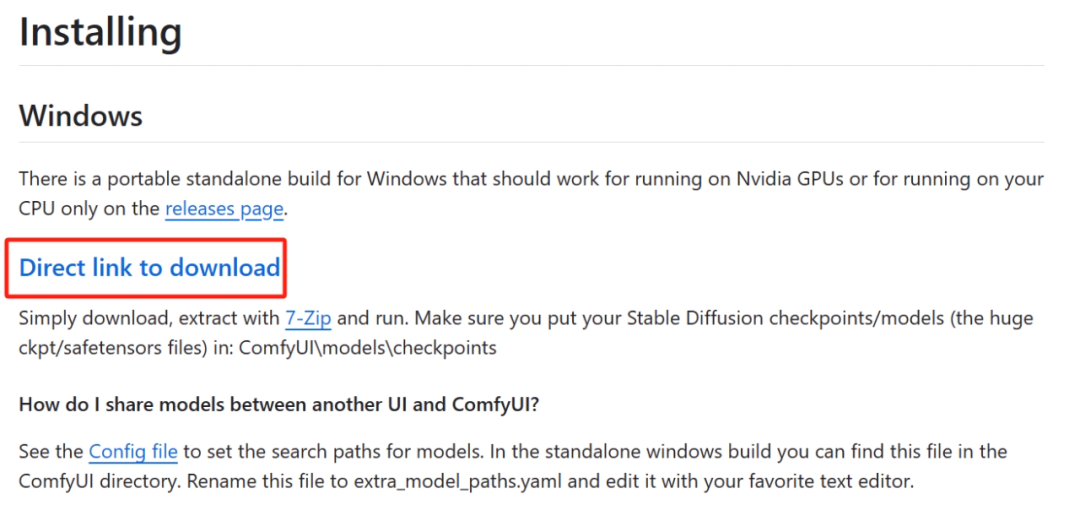
然后选择Direct link to download,这样浏览器就会自动下载压缩包。
安装:
在下载完成之后会得到一个压缩包,这个包解压之后大概有4.72GB左右,所以需要准备好足够的空间。
但目前这个解压出来的包只适用于Windows电脑,如果是英伟达的显卡也就是N卡的话就点击run_nvidia_gpu,如果不是就点run_cpu(A卡I卡或者无显卡)。
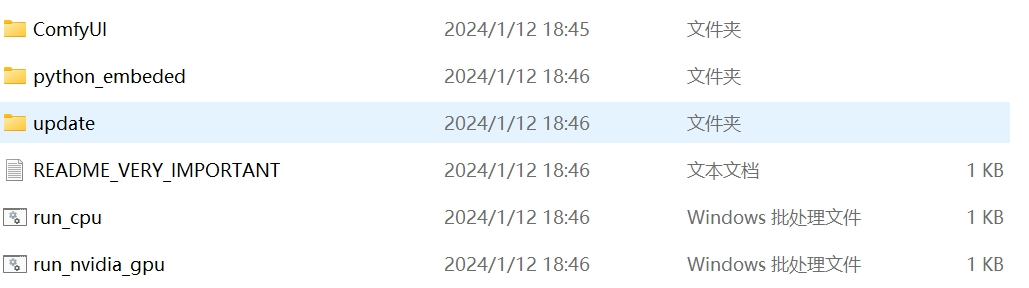
在短暂的加载之后就会出现ComfyUI的界面:
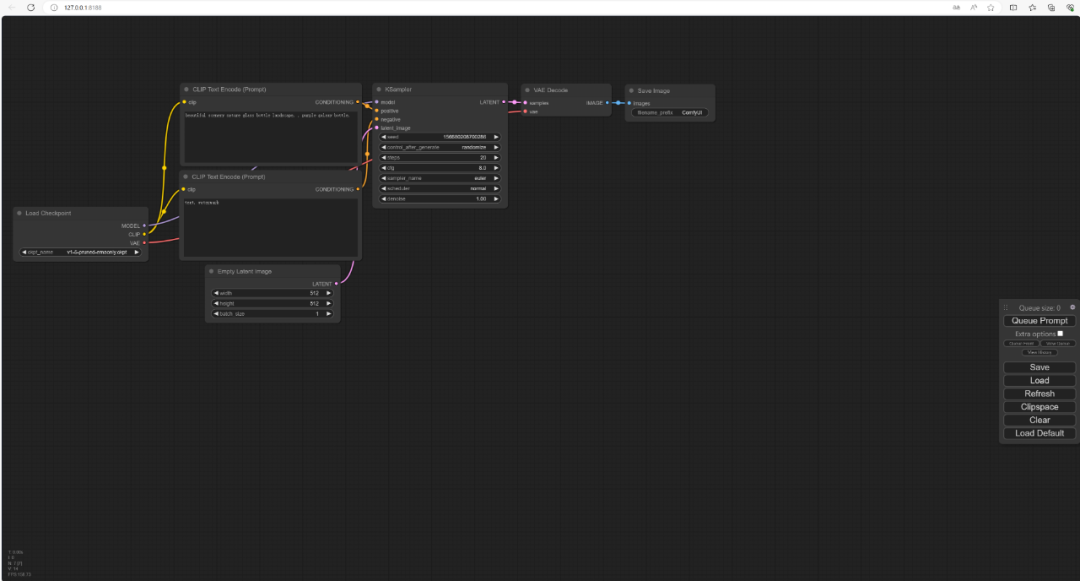
不会自动跳转也没关系,在命令行中可以看到这个地址,复制之后粘贴到网页即可。

在一切都安装好之还没有结束,因为现在的ComfyUI中并没有任何模型,这里需要将在网上下载下来的模型复制粘贴进ComfyUI的models文件夹中。
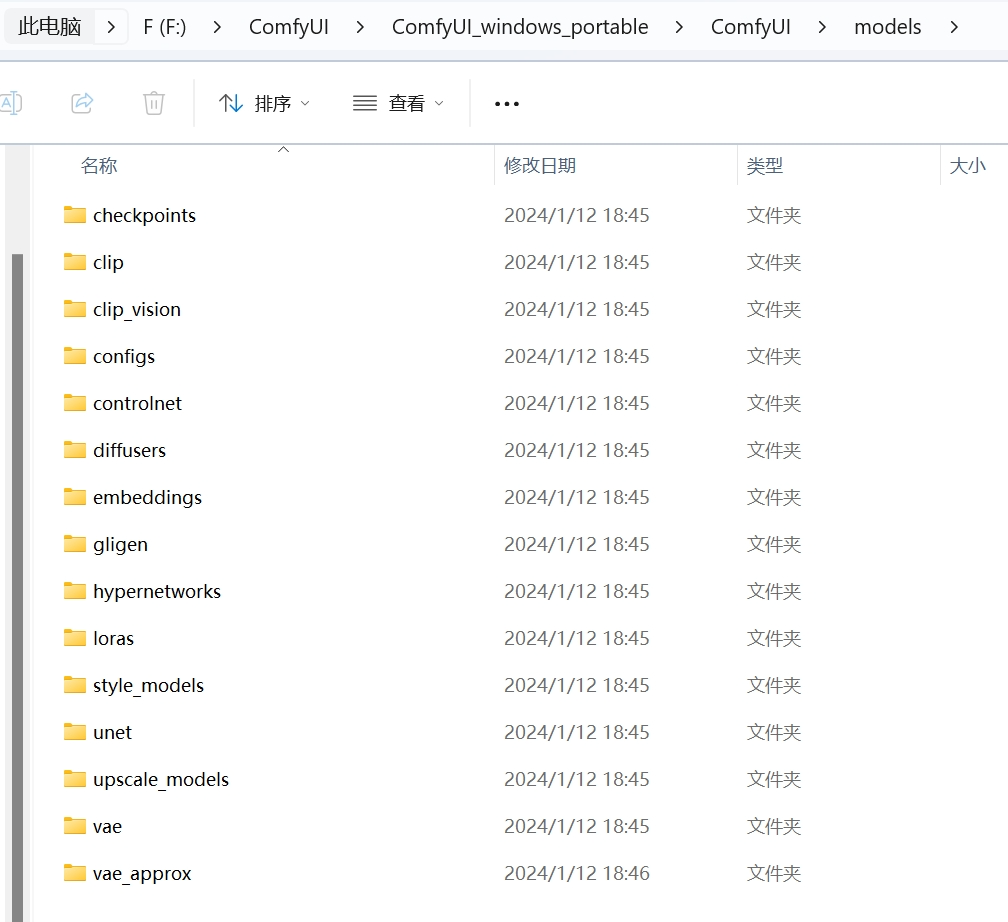
当然如果已经使用过WebUI像我这样已经有不少模型在本地的话,直接复制到ComfyUI的文件夹中会比较占硬盘空间,这里ComfyUI的作者提供了一个可以将WebUI的模型链接到ComfyUI的方法。
这里需要根据步骤进行:
**第一步:**找到一个名为extra_models_path.yaml.example的路径
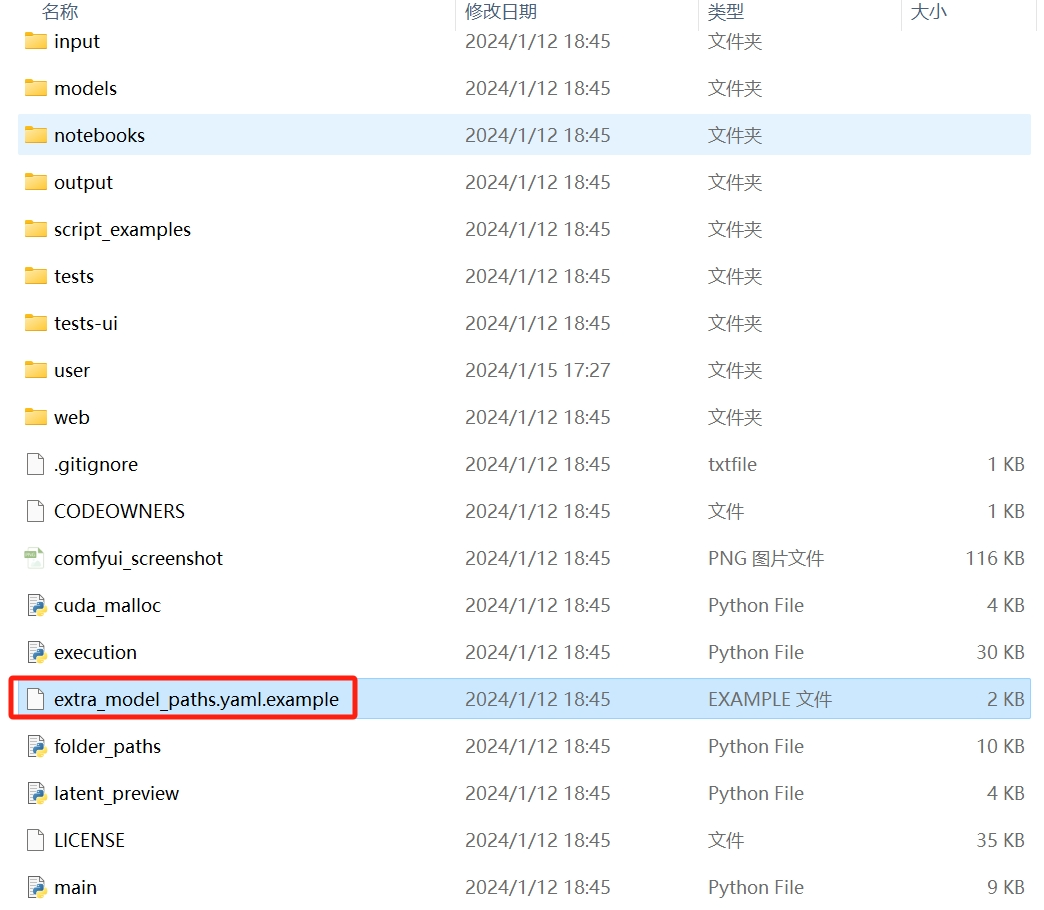
点击重命名将后缀的**.example**删除掉,变成这样(会弹出是否确认更改,直接点确定):

**第二步:**鼠标右键点击打开方式,选择以记事本的方式打开。
找到Base Path这一行,将其后面改为WebUI根目录地址(注意:到WebUI文件夹即可)
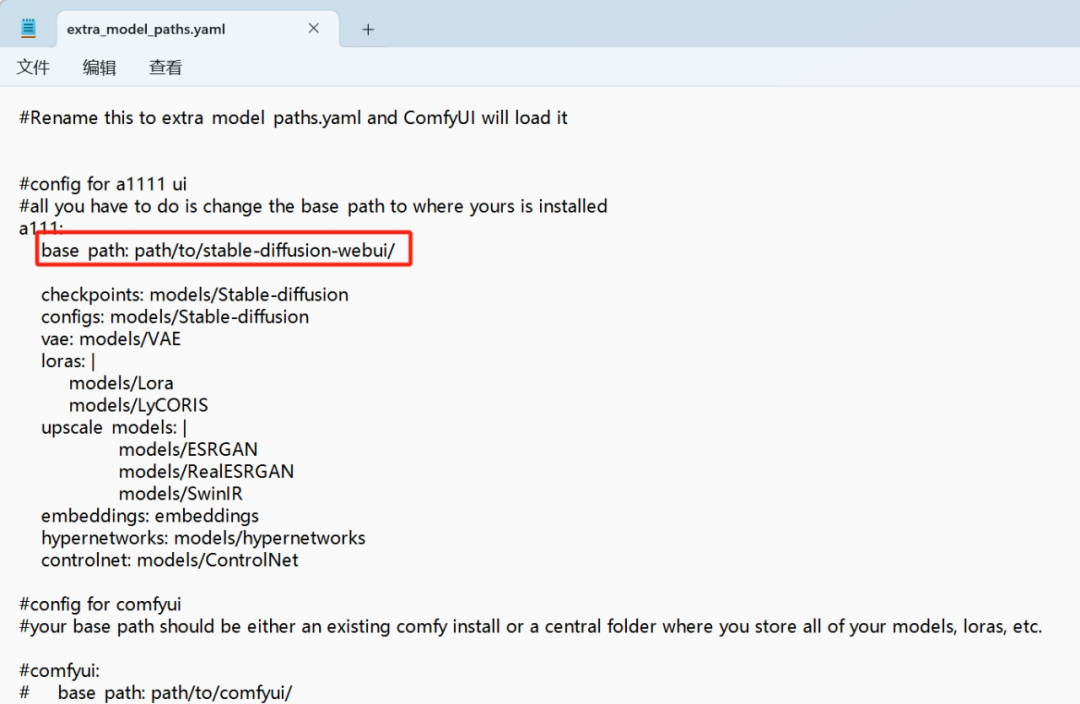
更改后:
然后点击右上角的文件-保存即可,关闭页面后重新启动ComfyUI。
这样在选择模型的地方就可以看到WebUI中所放置的所有模型了。
如果后续要更新ComfyUI版本(不会自动更新),就进入到ComfyUI文件夹选择运行Update脚本即可。

ComfyUI的基本模块
打开ComfyUI的界面后所看到的就是一个文生图的工作流程。
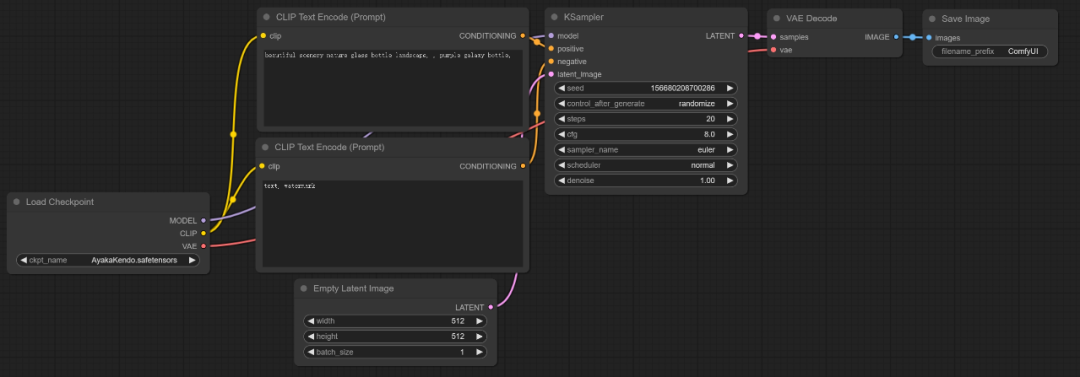
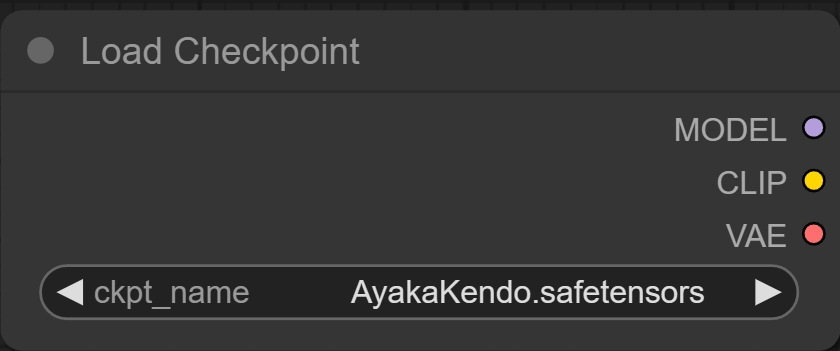
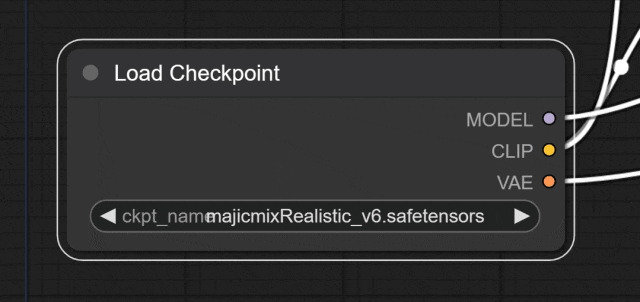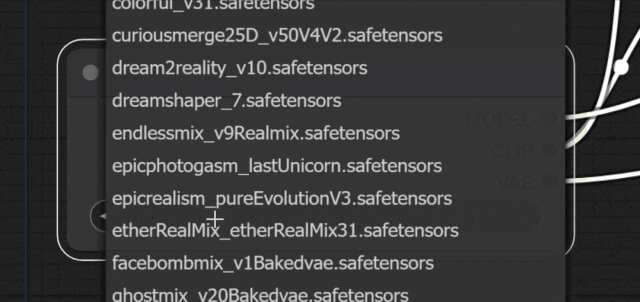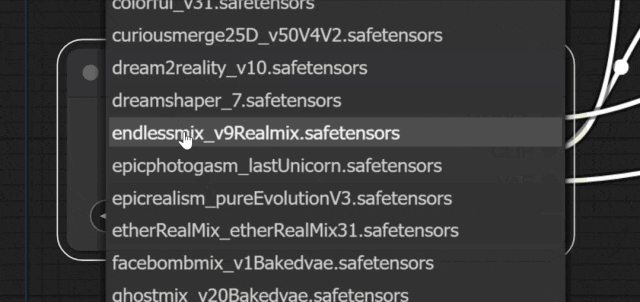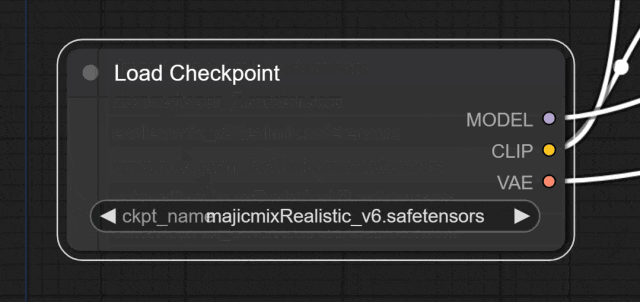
Load Checkpoint模块就是加载模型的地方。
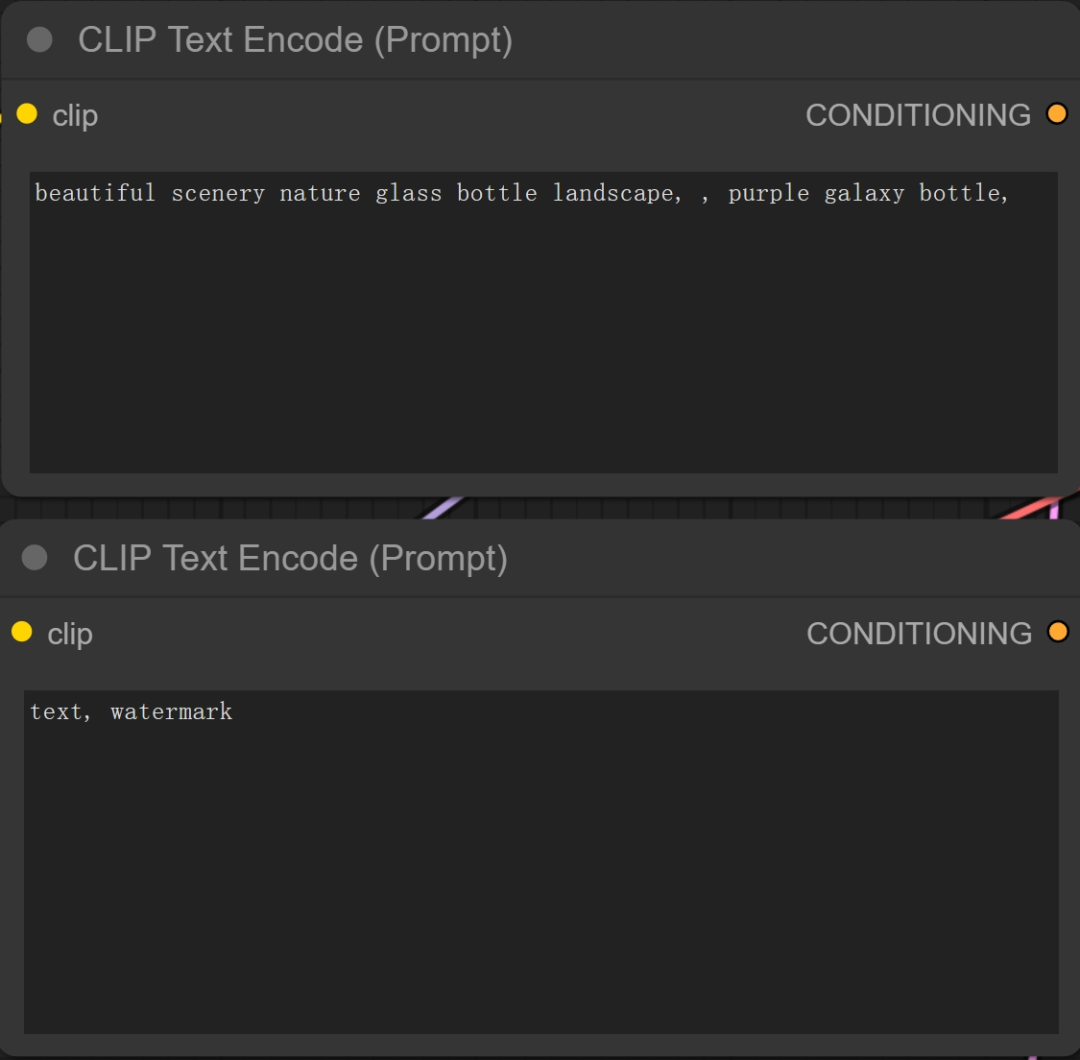
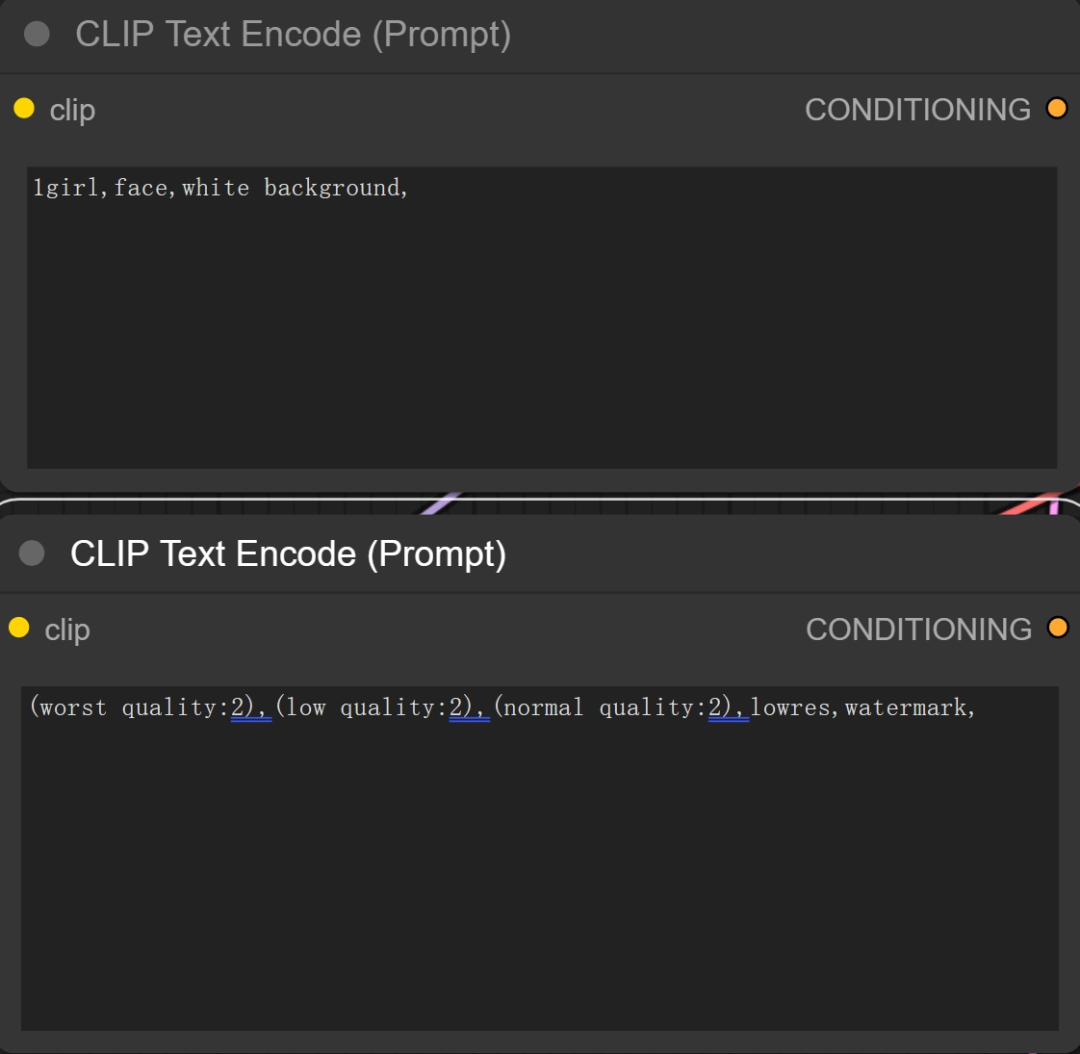
其中右侧的Clip分别链接到了正负两个提示词模块
Ksampler模块就是WebUI里的采样器,了解过WebUI的看这些就非常熟悉了。
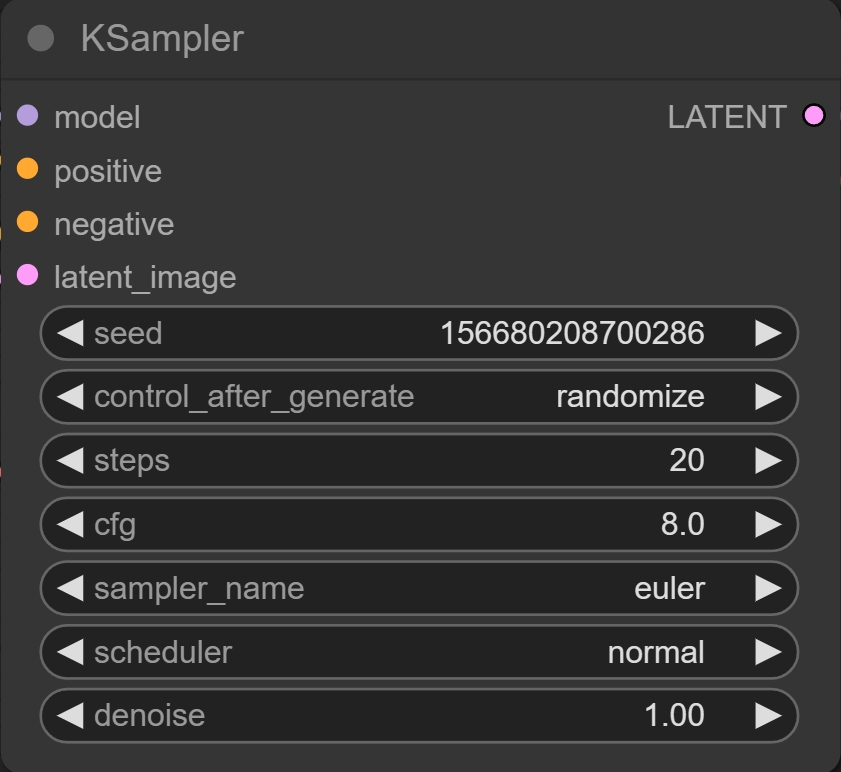
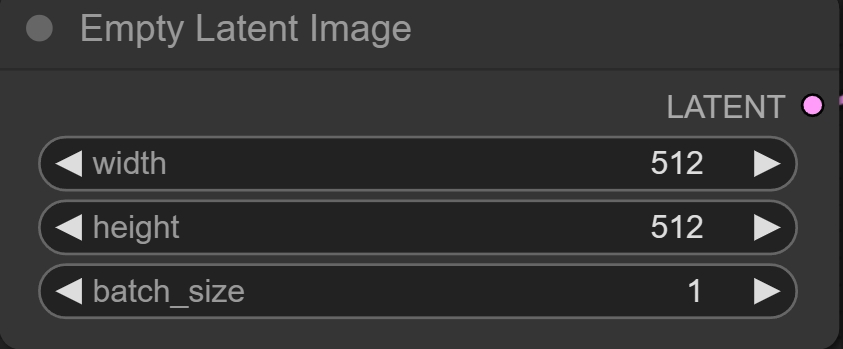
Empty latent image模块可以设置图像的宽高和生成图像数量
VAE Decode模块这个没学过之前的Stable Diffusion可能不太好理解。
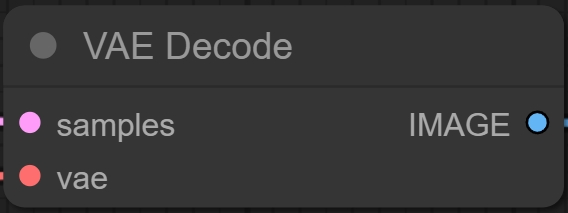
在此前的所有步骤都是图像的生成过程,AI会生成一个潜空间图像,这个图像经过VAE Decode解码之后还原到像素空间,之后才会得到我们所常见的AI绘图结果。
这里简单操作一下大伙就大概知道是怎么回事了:
选择一个想要用的模型:
然后输入正负提示词:
选择图片的大小:
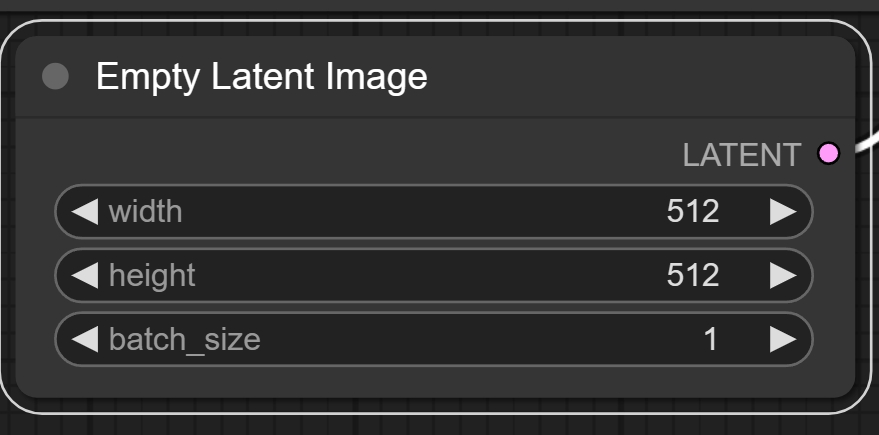
选择好其他参数:
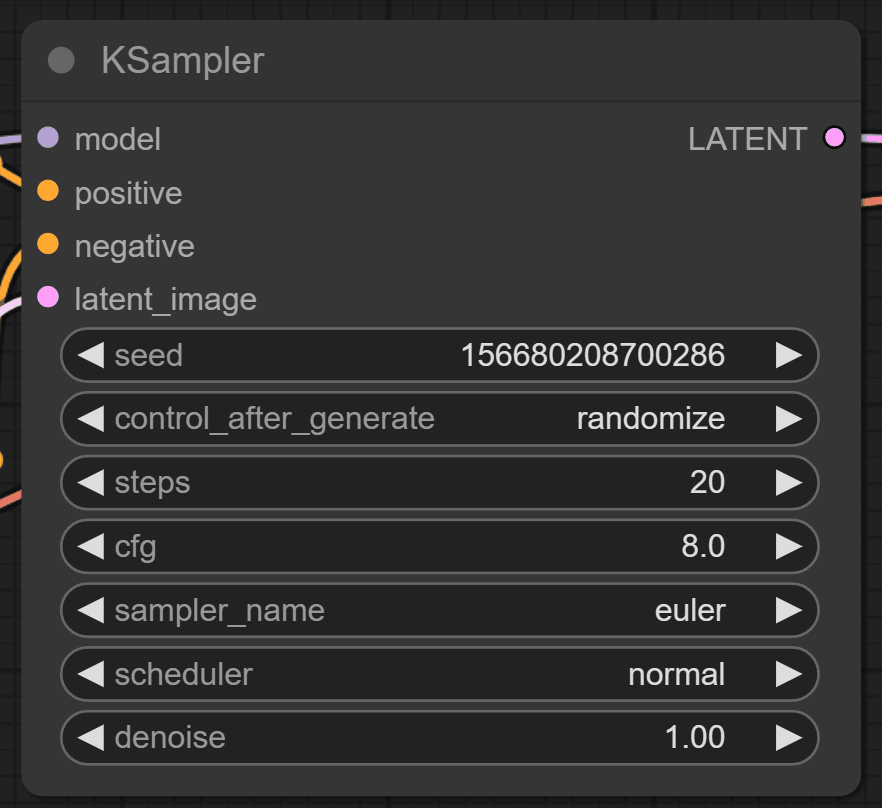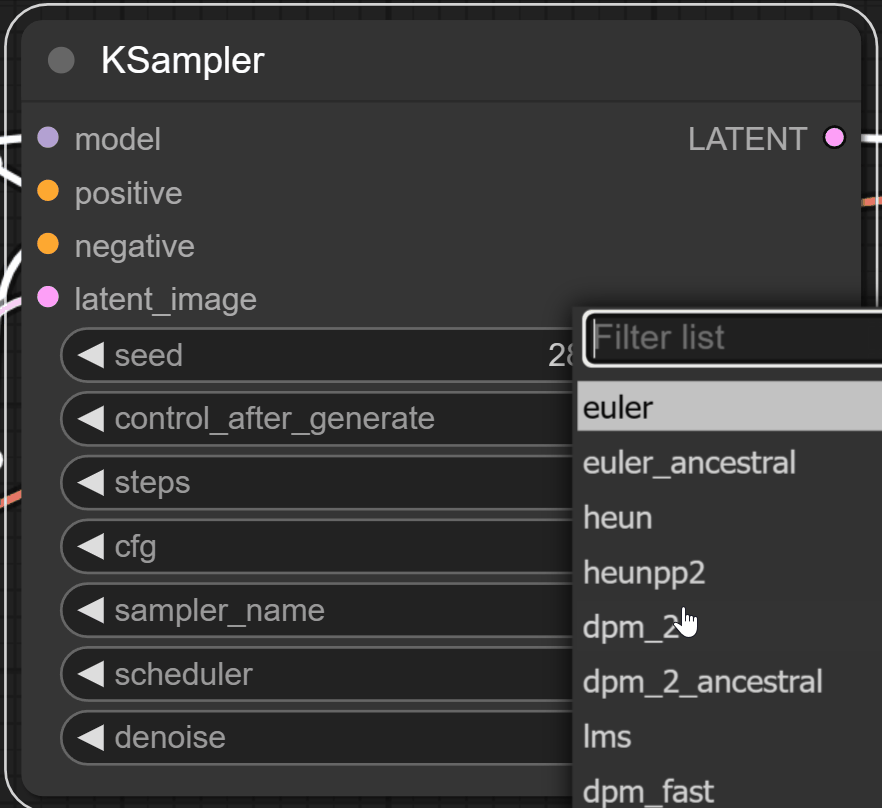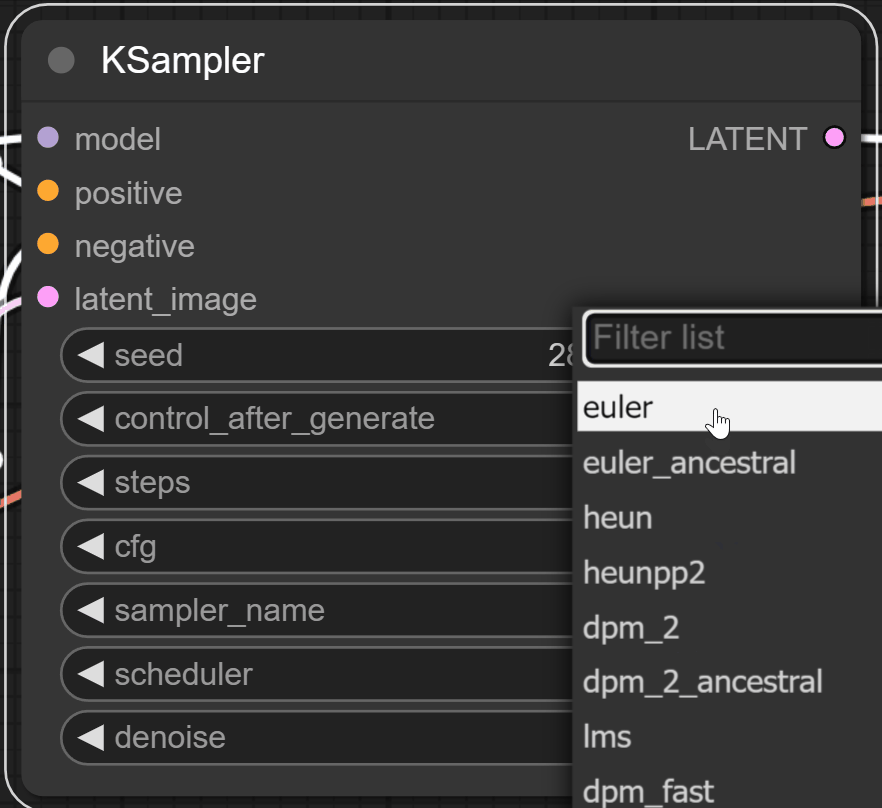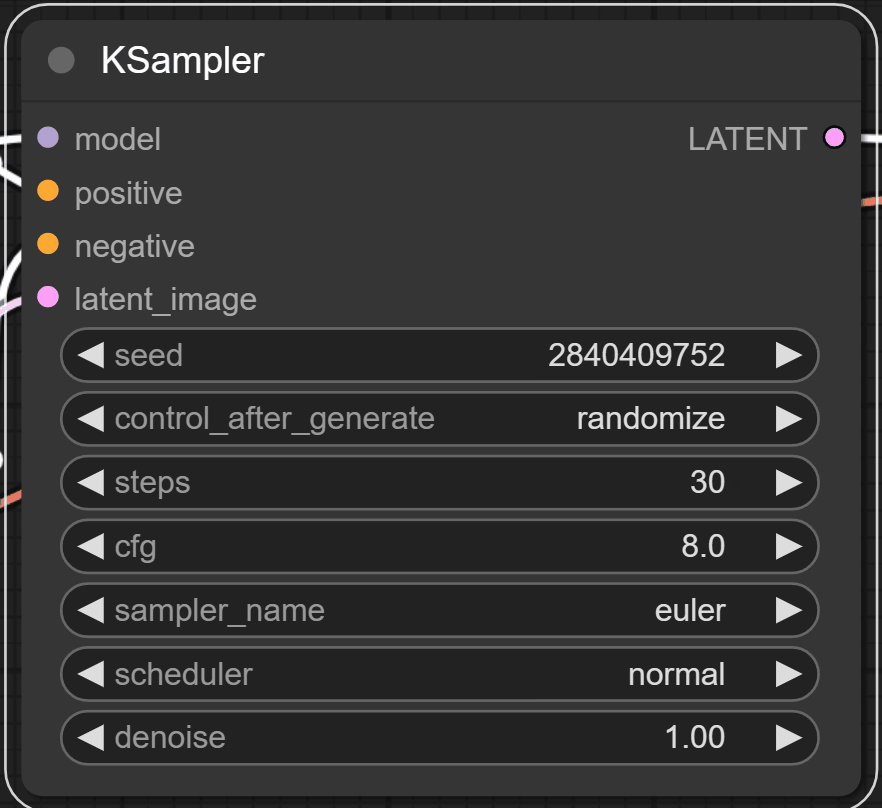
点击最右侧的Queue prompt就可以生成图片了!
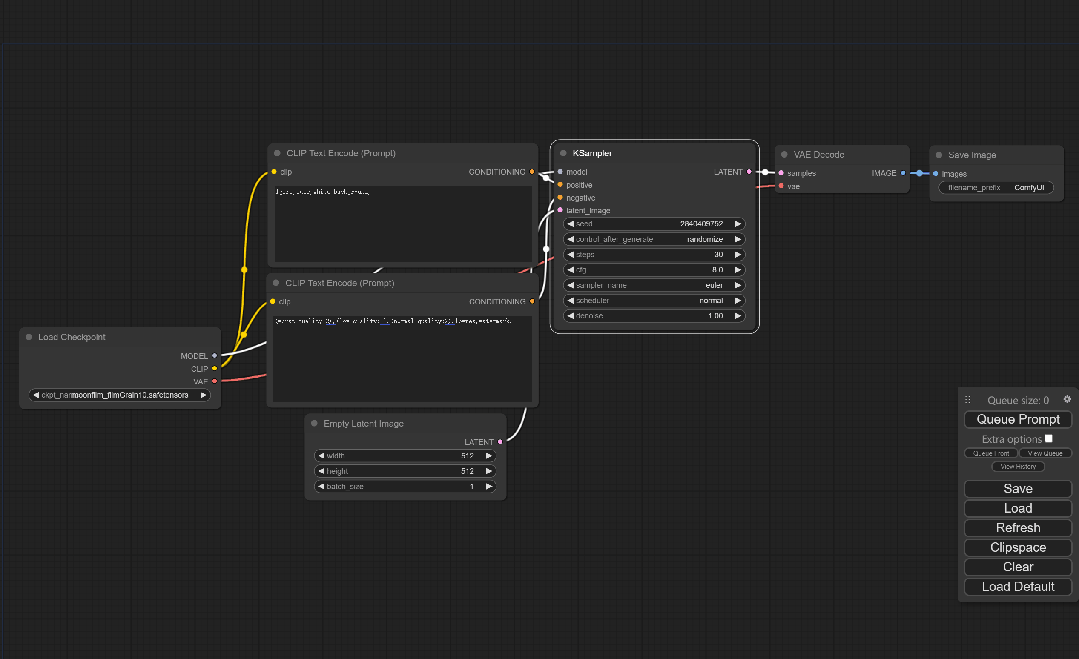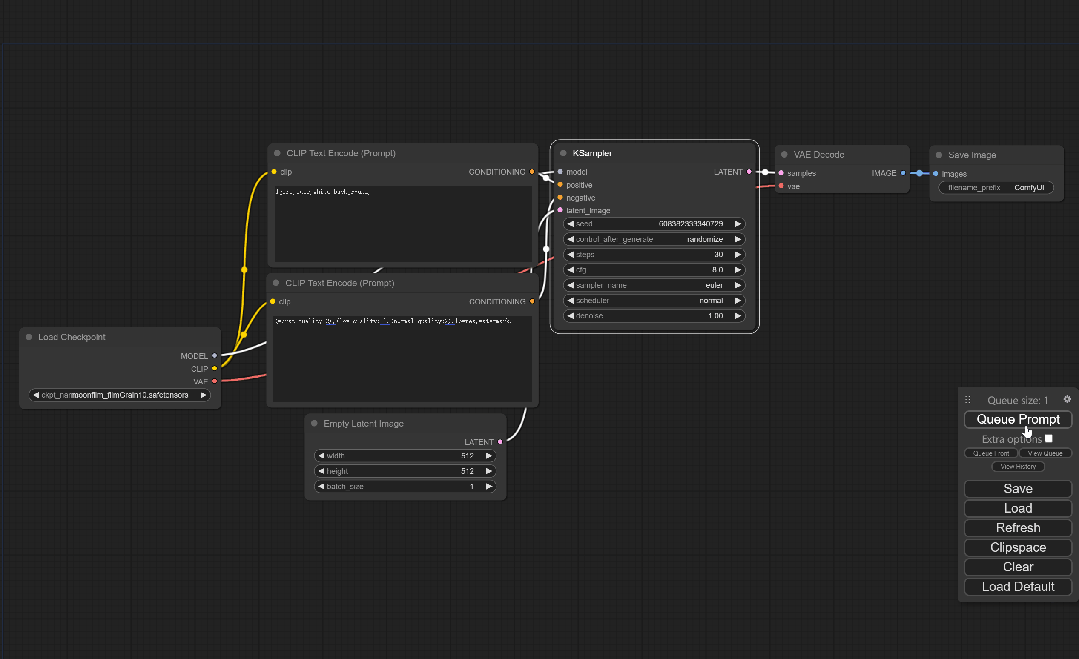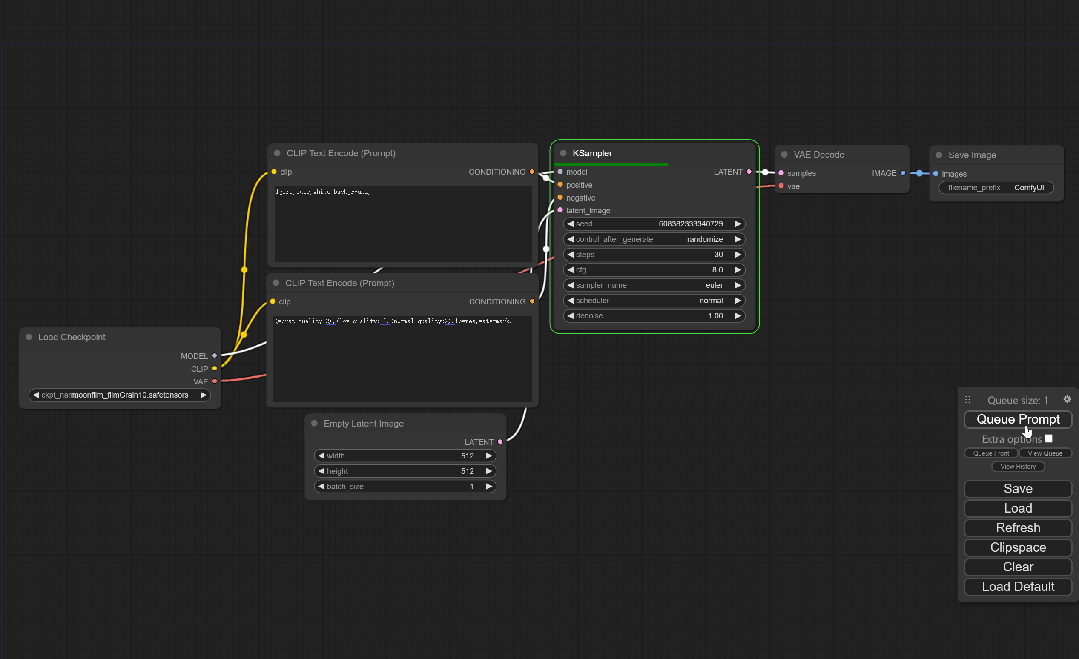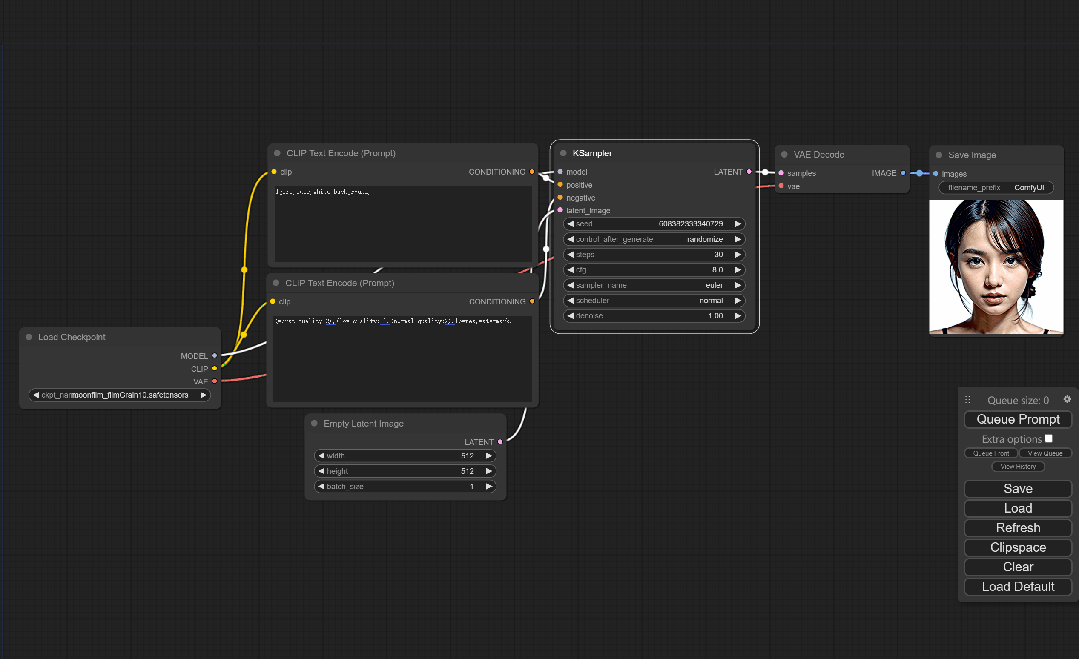
这样看整个流程是不是非常的简单明了。
今天的内容就到这里啦!
主要是为了学习后续视频的制作我才决定学习一下ComfyUI,虽然绝大多数的操作参数什么的和WebUI是一样的,但是我个人更喜欢WebUI的使用。
当然,多学一点也没什么坏处不是。
那今天的内容就水到这里了,大伙下篇笔记见,拜了个拜!

Light pink hair, pink eyes, pink and white, sakura leafs, vivid colors, white dress, paint splash, simple background, ray tracing, wavy hair
Negative prompt: (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, watermark
-
Steps: 30
-
Sampler: Euler a
-
CFG scale: 7
-
Seed: 3159822199
-
Size: 512x512
-
Model hash: e4a30e4607
-
Model: majicmixRealistic_v6
-
Denoising strength: 0.7
-
Clip skip: 2
-
ENSD: 31337
-
Hires upscale: 2
-
Hires upscaler: R-ESRGAN 4x+
-
Version: v1.6.0-2-g4afaaf8a0
为了帮助大家更好地掌握 ComfyUI,我在去年花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









