






目录
七、语义分割Seg
八、重绘Inpaint
九、线稿检测Lineart
十、动漫线稿检测Lineart anime
十一、人物姿势检测Openpose
十二、涂鸦Scribble
十三、软边缘检测Softedge
十四、随机洗牌Shuffle
十五、自适应Ip2p
十六、分块重采样Tile
十七、仅参考Reference only
7
语义分割
“Seg” 是 “Semantic Segmentation”(语义分割)的简称,它是计算机视觉领域的一项任务。其目标是将图像中的每个像素标记为不同的语义类别区域。与传统的图像分割任务不同,语义分割不仅仅是将图像划分为不同的区域,还会为每个像素赋予语义标签,即指定像素所属的类别,例如人、车、树等。

简单来说,语义分割模型能够识别图像中的各种物体,并用已经定义的不同颜色来表示它们。这样可以更详细地理解和分析图像中的场景。如上图,参考图经过语义分割预处理器处理后生成了一个包含了许多色块的图片,其中紫色表示伞,蓝色表示车辆,诸如此类。所以很容易理解,语义分割其实就是将图片中的物品进行分类,比如哪一类是车子,哪一类是建筑,又或者哪一类是人,每一类不同的物体都用不同的颜色表示出来。
通过了解这些信息,就可以向SD模型提供有关图像中人、车、建筑等物体位置的信息,从而帮助SD模型生成与之相似的图片。
1)预处理器选择
语义分割有三种预处理器可供选择:OneFormer ADE20k (ofade20k)、OneFormer COCO (ofcoco)、UniFormer ADE20k (ufade20k)。
ADE20k和COCO协议指的是该模型训练使用的图片数据库为ADE20k或COCO。
OneFormer 和 UniFormer 是两种不同的算法。
其中第一种预处理器ofade20k生成的图片最为干净而且也最准确。第二种预处理器ofcoco会把建筑物的窗户也单独识别出来,细节更丰富。第三种预处理器ufade20k识别的结果就没那么好了,当然也可能仅仅是因为这种类型的图片不是它所擅长的。
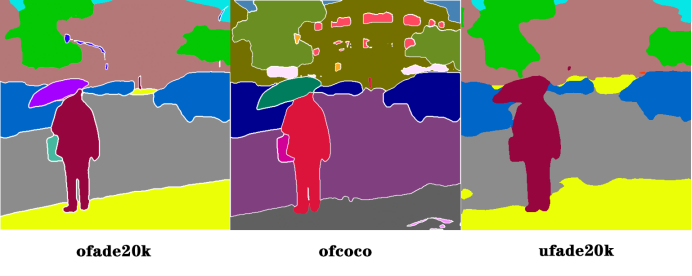
实际操作过程中可以分别使用是三种预处理器处理,对比后再选择最理想的分割结果。如果实在不想选择,那么使用默认的第一种预处理器即可,其效果非常稳定。
2)生成效果示例
提示词:sports car, blue sky, highway, highly detailed(跑车,蓝天,高速公路,高度细节)
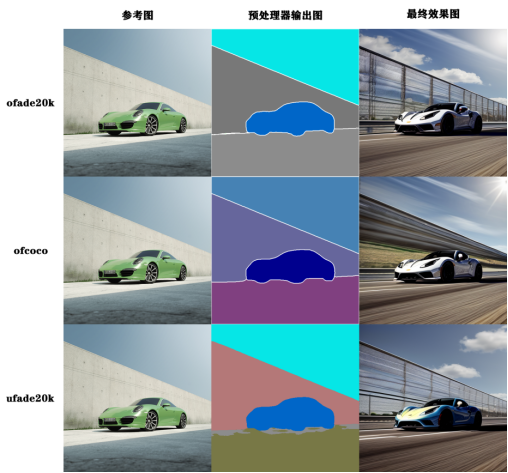
8
重绘inpaint
ControlNet的局部重绘与图生图的局部重绘有一定区别,最显著的区别在于使用图生图的局部重绘时,重绘幅度设置过高会导致蒙版区域生成的内容与整体的图片内容不匹配,而ControlNet的局部重绘则不会有这个问题。

重绘ControlNet的使用方法与其他ControlNet有些差异。
第一步:将图片上传到图生图页面的重绘(inpaint)标签页下,提示词使用生成该图的提示词即可。
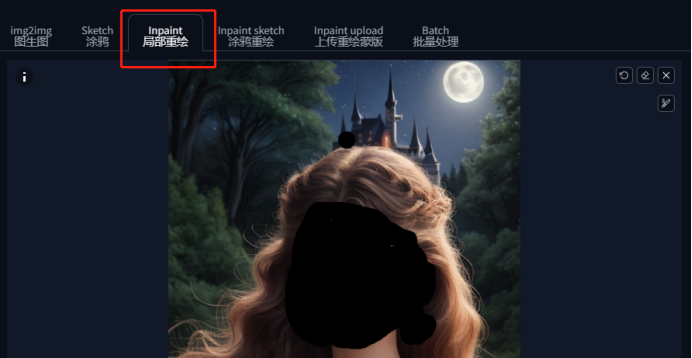
第二步:使用画笔将需要修改的地方涂抹覆盖,比如这里我想换一个人脸,那么我就将人脸涂抹完全
第三步:关键设置如下图
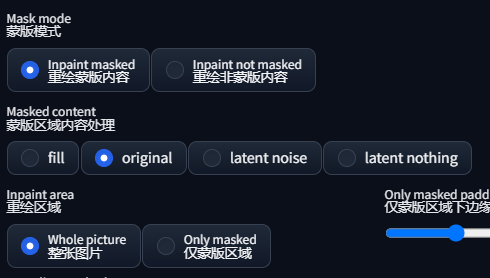
第四步:重绘幅度设置为1,种子随机

第五步:设置ControlNet,不需要上传图片到controlnet,其它参数如下
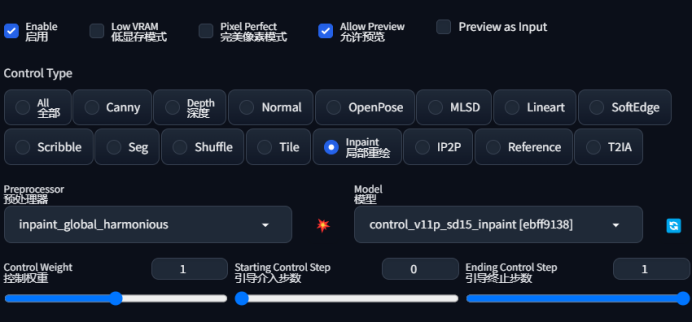
第六步:点击生成

9
线稿检测Lineart
Lineart检测旨在呈现图像的轮廓,并试图将其转换为简洁的线条。它通过提取图像中的边缘信息,将图像转化为仅包含轮廓线条的黑白图像。
Lineart检测的目标是捕捉和突出显示物体的形状和结构,去除图像中的细节和颜色,从而产生一种类似手绘或插画的效果。它可以将复杂的图像简化为线条的形式,使后续的处理过程更加专注于物体的轮廓和整体构图。

简而言之,线稿检测指的是将参考图处理成一张类似手绘线稿图的过程。
将提取的线稿通过ControlNet模型引导stable diffusion即可生成相似的图片。
1)预处理器选择
根据命名可以知道,线稿检测的预处理器可以分为两类:一类是针对真实风格的图像,另一类则针对动漫风格。然而,并不意味着对于真人照片只能使用真实风格的预处理器。实际上,你可以自行测试并选择适合的选项,因为图像千变万化,各种参数设置也不是固定的。
可能是动漫线稿检测的预处理内置的阈值比较高,对于真人照片,其处理效果并不理想,因此要尽量避免使用动漫线稿检测处理真实图片。
而对于动漫图片,由于其主要由电脑绘制,线条比较平滑,因此,动漫线稿检测和真人线稿检测的结果都还不错。


单从预处理器的生成结果来看,写实线稿检测是最还原的,对参考图的细节也保留得最好,当需要获得与参考图更相似的图片时使用此预处理器。与此相反,动漫降噪线稿检测保留的线条最少,因此能最终的图片也可以有更大的随机性。标准线稿检测得到的结果比较杂乱,噪声明显较多,最终的生成结果也是如此,会造成画面的一些扭曲,这将在第二节的示例中得到应证。
2)生成效果示例
写实线稿和动漫线稿能比较好还原人物本来的面貌,而粗略线稿和动漫线稿去噪则有稍微大点的变化空间。

10
动漫线稿检测Lineart anime
动漫线稿检测与线稿检测基本类似,可以使用线稿检测所使用的全部预处理器。除了动漫去噪线稿生成的图片细节丢失比较多之外,其它预处理的结果差别都不是很大。
生成效果示例:

11
人物姿势检测openpose
Openpose是一个用于检测人物姿势的关键点的模型,例如头部、肩膀、膝盖等。它通过分析图像中人体的相对位置来获取姿势信息。而ControlNet模型则可以利用预处理获得的人物姿势信息应用于其他图像中。
与其他模型不同,Openpose并不保留人物的长相、服装和背景等其他信息。相反,它专注于捕捉人体姿势的结构。这意味着在使用Openpose时,我们可以更自由地选择图像的其他元素,如服饰、构图和背景等。这为我们提供了更大的创作空间,也更能发挥不同SD模型的创造力。
需要注意的是,尽管Openpose可以用于引导生成姿势,但生成的姿势并不总是非常精准。Openpose是基于图像中人体关键点的检测模型,它通过分析相对位置来识别人物的姿势。然而,由于图像的复杂性和噪声等因素,Openpose可能无法完全捕捉到人物的细微动作和姿势变化。
1)预处理其选择
Openpose预处理器的种类比较多。下面简单介绍各种预处理器检测的内容并配有实例图。
Openpose:眼睛、鼻子、脖子、肩膀、肘部、臀部、手腕、膝盖、脚踝
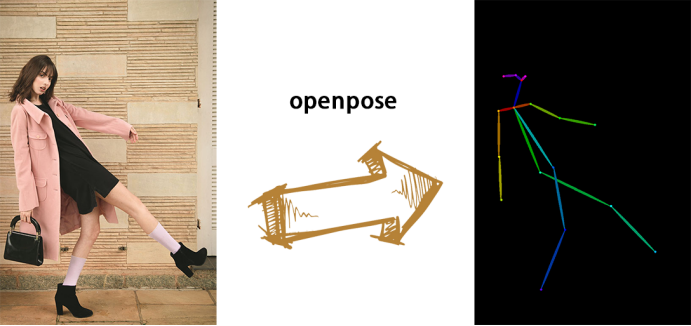
Openpose + face:openpose检测内容、脸部轮廓、眼睛、嘴巴、鼻子

Openpose + faceonly:脸部轮廓、眼睛、嘴巴、鼻子

Openpose + hands:openpose检测内容、手掌、手指

Openpose + full:检测所有能检测的内容,包括openpose、脸部和手部关键点
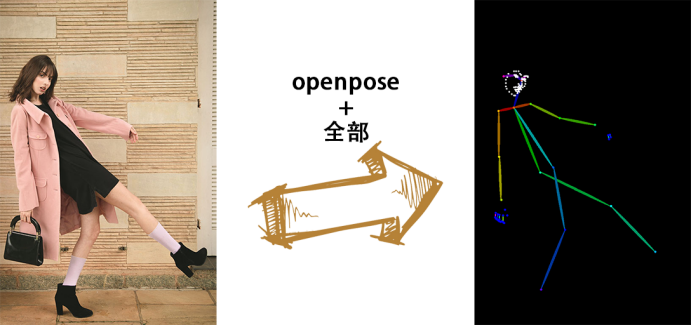
2)生成效果示例
目前在使用SD模型生成全身图时,即使使用ControlNet进行辅助,仍然容易导致生成的结果产生扭曲。因此,建议在输出图像时避免直接生成全身图片,而是使用人物的中景、近景甚至特写图片做为参考图,这样取得效果往往是较好的。
Openpose:
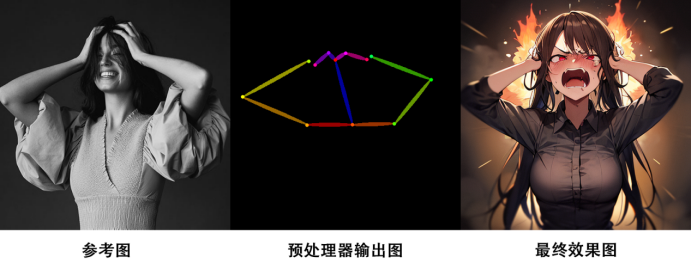
Openpose + face:

Openpose + face only:

Openpose + hands:
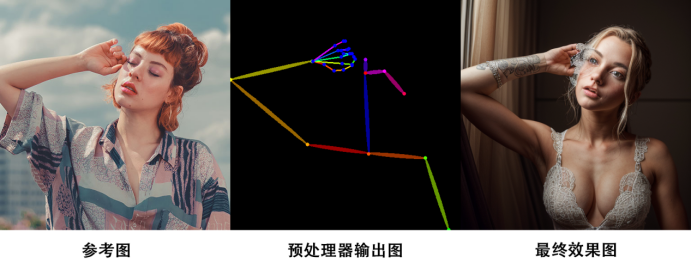
Openpose + full:

12
涂鸦scribble
涂鸦预处理器能够将一张图片转化为类似手绘效果的涂鸦。生成的涂鸦效果进一步通过scribble ControlNet模型引导SD模型填充更加丰富的细节。
scribble ControlNet无论是对人物图片还是建筑图片进行处理都能引导SD模型获得很不错的效果。
1)预处理器选择
涂鸦的预处理器有三种可供选择:HED、PiDiNet、XDoG。
其中HED和PiDiNet都是神经网络算法, 而XDoG为经典算法。由于神经网络算法在处理图像时具有更强的学习能力,因此HED和PiDiNet在涂鸦风格转换方面具有一定的优势。
通过观察下方的图示,你可以更直观地了解HED、PiDiNet和XDoG这三种预处理器的效果差异。根据自己的需求和偏好,选择合适的预处理器能够更好地实现涂鸦效果的转换。
默认设置,效果对比如下:

2)生成效果示例
从生成效果来看,使用三种预处理器,最终生成的图片效果都很不错。不过可以注意到,这个ControlNet模型引导生成的图片与参考图的结构是有区别的,并不是那么的忠实。只要稍微仔细看一下下面图片中建筑的结构就不难发现这一点。
输入的参考图:

HED:

PiDiNet:

XDog:

13
软边缘检测softedge
不同于边缘检测和线稿检测,软边缘检测往往还可以提取图片中具有渐变效果的边缘线条。而且提取的边缘线还具有一定的渐变效果,因此使用这种方法生成的图片画面会更加柔和。
从下图中可以看到,边缘检测对于比较柔和的边缘完全提取不出来,而线稿检测则只能提取一部分,只有软边缘检测才可以将柔和的边缘线条很好地提取出来。

1)预处理器选择
软边缘检测的预处理器有四种:HED、保守HED、PiDiNet和保守PiDiNet
在官方文档中,对这四种预处理器根据不同条件进行评估并排名
鲁棒性(可以理解为容错率或者对陌生图片的适应能力):保守PIDI > 保守HED > PIDI > HED
生成质量上限:HED > PIDI > 保守HED > 保守PIDI
综合考虑之下,官方将默认选项设定为PiDi,原因是该方法在大多数情况下都表现良好。
不同预处理器的效果如下:
HED:

保守HED:

PiDi:

保守PiDi:

2)生成效果示例
总的来说,HED和PiDi预处理得到的结果更加柔和,最终输出的图片中对比度不会太高,光线也比较柔和,而保守HED和保守PiDi则相反。但总体上看,差别不是很大。
输入参考图:

HED:

保守HED:

PiDi:

保守PiDi:

14
随机洗牌Shuffle
随机洗牌能够将输入的参考图随机打乱,然后模型再试图将其还原为一张有序的图片。这样可以生成许多风格相似但内容不同的图片。
可以把这个过程想象成理牌的过程。斗地主相信很多人都玩过。当牌刚刚发下来时,显然牌序是乱的,那么我们需要重新将其理成有序的样子。怎么理?方法很多,可以将牌从小到大的顺序排列起来,也可以将对子、顺子或炸弹归为一类排列,其顺序可以不同,比如对子可以放前面,也可以放后面,这完全看个人喜好。但是无论怎么排列,你都会排列为一种有序的状态。
洗牌的人就充当了预处理器的作用,而你则是起到了shuffle controlnet模型的作用。预处理器将输入的图片打乱,shuffle controlnet模型则试图从混乱的内容中生成有序的结果。这就是随机洗牌ControlNet的作用。
与其他的ControlNet不同,随机洗牌预处理器的输出结果会受到种子的影响,不同的种子值会生成不同的预处理图。另外还有一点是,既使不经过预处理,随机洗牌也可以正常输出最终效果图。
随机洗牌可以用来复制参考图的风格、色彩、亮度和对比度等信息,效果相当显著。
生成效果示例:



15
自适应ip2p
Ip2p,全称Instruct Pix2Pix,即指导图片生成图片,与图生图的功能很类似。通过这个功能,可以复制参考图的构图,同时生成图片的内容也会根据提示词作出一些改变。
例如:当我输入提示词:Make her old(使她变老),就可以将参考图中的年轻女子变成老年人。

需要注意的是,这个ControlNet是没有预处理器的,所以如果发现你的预处理器是空的也不必担心。
另外这是一个处于试验阶段的ControlNet模型,有时候你会发现它并不是那么好用,这很正常,它还有很多需要改进的地方。
通常情况下,这个模型是只能接受指令性的提示词的,但是在重新训练的时候使用了50%的指令性和50%的描述性提示词,因此一般的提示词几乎都可以被识别。
怎么区分这两种类型的提示词呢?很简单,比如,“a cute girl(一个可爱的女孩)”是一个描述性的提示词,而“make the girl cute(把那个女孩变可爱)”就是一个指令性的提示词。
更多使用示例:
提示词:Make it cartoon(卡通化)

提示词:make it oil painting by monet(使之变成莫奈风格油画)

16
分块重采样tile
这个controlnet可能是最让人难以理解的模型,分块重采样?听着就很玄乎。你可能只是知道它可以配合脚本如Ultimate SD upscaler一起使用来讲图片高清放大,但它的作用远不止于此。
分块重采样主要起两个作用:
1、忽略图片的部分细节,并给图片添加新的细节,同时还不会影响图片的整体构图。
2、会根据分块的语义内容添加细节,如果分块内容与提示词不匹配,则不使用提示词指导该分块的生成。
通常情况下,如果我们要改变图片的细节,则主要通过图生图的功能进行。可是也发现一个问题,一旦重绘幅度(denoising)设置过高,整个图片的构图就会产生显著的变化。而分块重采样则不会出现这样的问题。
比如,在下图中,我使用了两个模型生成图片:Dreamshaper和realistic vision。参考图由Dreamshaper生成,而其他图片则是通过realistic vision生成。当重绘幅度设置为1时,启用tile功能,则可以保持整体构图的一致性,此时尽管整体构图没有变化,但细节却发生了显著的改变。同样的条件下,当我关闭tile,生成的图片则与参考图完全不同。因此,tile功能在于可以更新图片的细节而不对整体构图产生影响,即使重绘幅度为1。
预处理器和模型如下图:


既然,tile可以给图片添加新的细节,那么我们是不是可以使用tile来给模糊的图片添加更多细节,使之变得清晰呢?
答案是可以的。
比如下图的参考图即是一张相当模糊的图片,但狗狗的形状依稀可辨,我们使用tile尝试生成狗狗的更多细节。
提示词:a dog on grassland(一只在草地上的狗狗)
重绘幅度:1

可以发现,开启tile后确实可以将模糊的图片变得清晰。
除此之外,Tile功能甚至可以将低分辨率的图片超分放大,生成清晰度极高的图片。下图的参考图分辨率为64x64,重绘生成的图片为512x512。
提示词:a girl, jewery, stunningly beautiful(1个女孩,珠宝,很美丽)
重绘幅度:1

可以发现,当启用Tile功能后,生成的图片与参考图非常相近,但清晰度显著提升,因此Tile也可用于超分放大图片。
实际上,超分放大图片是Tile最频繁的应用之一。例如,如果我输入一张512x512的图片,并希望将其放大四倍以获得2048x2048的高分辨率图片。虽然理论上这是可行的,但直接生成如此高分辨率的图片需要极大的显存占用,因此往往需要借助其他插件的帮助。
Tile Diffusion和Ultimate SD Upscale是两个广泛使用的高分放大插件,通常与Tile配合使用。它们的主要功能是将一次性生成一张大图的过程拆分为多次生成小图,然后再将这些小图拼接成大图的过程,从而极大地降低了对显存的需求。这使得即使显存较低的情况下,也能够轻松生成4K甚至8K的高分辨率图片。
如下图所示,通过对比可以明显看出,启用tile + 插件后,图片分辨率显著提升,同时画面细节也更加丰富和自然。然而,放大前后的图片并不完全相同。这是因为Tile会生成许多新的细节来取代原有的细节,因此Tile并非严格意义上的高分放大方法。然而,它能够产生与高分放大相似的效果,且通常比传统的高分放大方法获得更好的效果。
放大前(768x512):

Tile + tile diffusion 放大后(2048x1356):

需要特别注意的是,与其他ControlNet不同,Tile的效果可以受重绘幅度的影响。因此重绘幅度也是Tile的参数之一,更高的重绘幅度,图片被替换的细节就越多,与参考图的差异就越大,但即使重绘幅度设置为1也不会影响整体的构图。以下是使用不同重绘幅度的对比图。

参考图由dreamshaper生成,重绘使用的模型是realistic vision,前者为2.5D模型,生成的人物介于真实和虚拟之间,而后者则是真实模型,生成的人物与现实中的人的形象更接近。从上图可以看出,随着重绘幅度增高,人物样貌逐渐向真实过度。
那么就可以衍生出很多新的使用方法,比如风格化图片,将真人动漫化或者动漫真人化等等。

更多的使用方法,可以根据具体的使用场景去尝试这个功能,看看是否有用武之地。
17
仅参考reference only
使用此功能需要将ControlNet升级到1.1.153版本以上。
Reference only是controlnet模型中出现最晚的一个选项,能够输出与参考图非常类似的图片,与此同时还受到SD模型和提示词的影响。
此controlnet没有模型选项,只有3个不同预处理器,因此你只需要选择一个预处理器类型即可。
包括三个预处理器:
Reference only:仅参考输入图片。使用的是attention链接技术,将参考图与SD模型的自注意力层链接。
Reference adain:自适应实例规范,使用的是一种称为“Adaptive Instance Normalization”的技术。
Reference adain + attn:以上两种技术的组合
Reference有多种使用方法。
1)生成相似图片
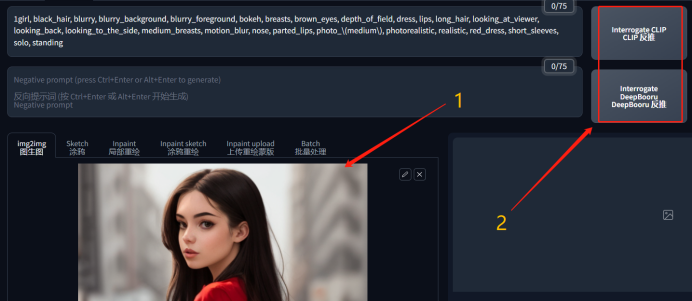
① 选择一张参考图

② 上传到图生图界面,点击反推提示词,Clip和deepbooru都可
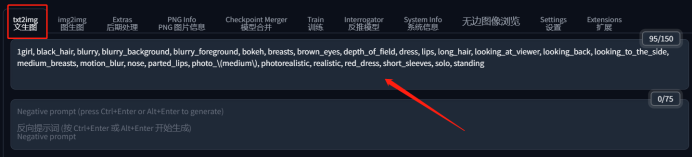
③ 将提示词复制到文生图的提示词框内
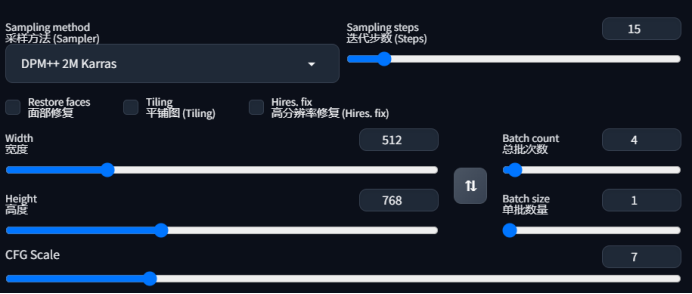
④ 设置其它参数
⑤ 将参考图上传到controlnet,点击启用,控制类型选择reference(参考),预处理器选择仅参考输入图(reference only)
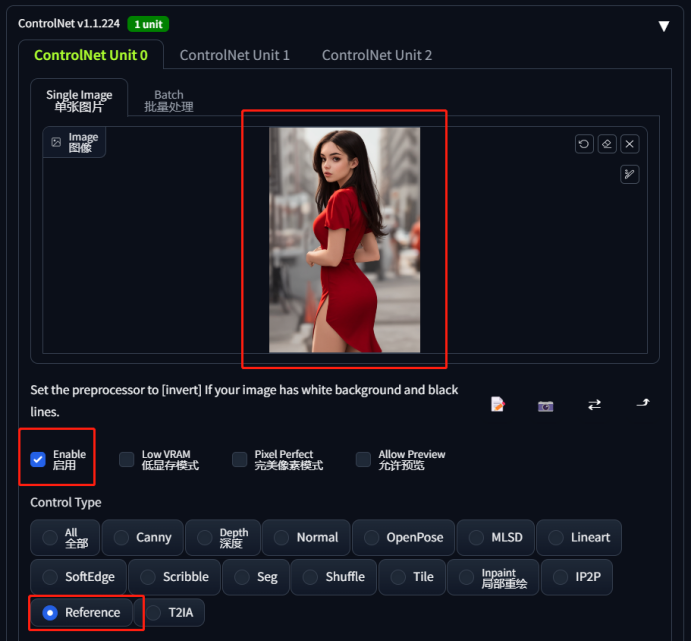
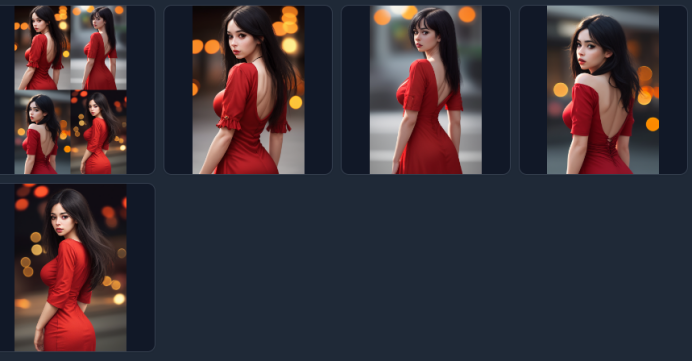
⑥ 点击生成,你就可以获得许多相似的图片

作为对比,以下是关闭controlnet生成的图片:
2)给人物穿上特定衣服

(打错字,上图右边为开启reference的情况)
可以尝试用这个功能换衣,但并不稳定,不能保证每种类型的衣服都100%成功。更好的方法还是得通过LoRA来实现。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 43
43

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









