






};
t.start();
}
}
通过Runnable 匿名内部类来实现
public class Demo {
//创建多线程
public static void main(String[] args) {
//通过匿名内部类来实现
Thread t=new Thread(new Runnable() {
@Override
public void run() {
//重写run方法
}
});
t.start();
}
}
public class Demo {
//创建多线程
public static void main(String[] args) {
Thread t=new Thread(()->{
//编写线程代码
}
);
t.start();
}
}
()->{ }这个就是lambda表达式
===============================================================================
| Thread() | 创建线程对象 |
| — | — |
| Thread(Runnable target) | 使用Runnable对象创建线程对象 |
| Thread(String name) | 创建线程对象并命名 |
| Thread(Runnable target,String name) | 使用Runnable对象来创建线程,并命名 |
| ID | .getId() |
| — | — |
| 名称 | .getName() |
| 优先级 | .getPriority() |
| 状态 | .getState() |
| 是否后台线程 | .isDaemon() |
| 是否存活 | .isAlive() |
| 是否被中断 | .isInterrupted |
| 获取当前线程的实例 | currentThread() |
优先级和线程调度有关,由操作系统来完成。
后台线程,不影响整个进程的结束
前台线程,会影响到整个进程的结束
是否存活就是run()方法是否运行结束了
===========================================================================
start
start 是Thread类的一个关键方法
功能:让操作系统内核真正创建一个线程来执行
start 和run 的区别
start 是创建线程(有新的执行流)
调用run只是一个普通的方法调用,不涉及创建新线程(仍然在原来的线程中,没有涉及到新的执行流)
调用strat 方法
public class Demo {
//start 和 run 的区别
public static void main(String[] args) {
MyThread2 myThread2=new MyThread2();
myThread2.start();
while(true){
System.out.println(“hehe”);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class MyThread2 extends Thread{
@Override
public void run() {
while(true){
System.out.println(“haha”);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}

可以看到两个线程并发执行,
而如果是调用run()方法,就是普通的调用,没有创建新线程,一直在循环里出不来
===========================================================================
线程执行完毕,运行5S 线程执行完毕
public class Demo {
//中断一个线程
static boolean isRunning=true;
public static void main(String[] args) {
Thread t1=new Thread(){
@Override
public void run() {
while(isRunning){
System.out.println(“hello”);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
t1.start();
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
isRunning=false;
System.out.println(“线程运行5S结束”);
}
}
针对上面的方式进行修改
1,把上面的while()中判断条件进行修改
2,把catch里面的代码,加一个break
调用 interrupt()是通知线程结束,具体还是看内部代码的实现
public class Demo {
//使用Thread 方法来中断线程
public static void main(String[] args) {
Thread t1=new Thread(){
@Override
public void run() {
while(!Thread.currentThread().isInterrupted()){
System.out.println(“hello”);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// e.printStackTrace();
break;
}
}
}
};
t1.start();
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(“线程结束”);
t1.interrupt();
}
}
=========================================================================
我们在创建多个线程之后,每个线程都是一个独立的执行流~
这些线程每个线程的执行顺序都是不确定的,完全取决于操作系统的调度,这里的等待线程机制就是一种确定线程先后顺序方式,确定线程的结束顺序,无法确定谁先开始,可以确定谁先结束 使用join()
join 起到的效果就是等待某个线程结束,谁调用join就等待谁结束
通过代码来解释:
public class Demo {
//使用Thread 方法来中断线程
public static void main(String[] args) {
Thread t1=new Thread(){
@Override
public void run() {
for(int i=0;i<5;i++){
System.out.println(“hello”);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
t1.start();
try {
t1.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
这里在main 方法中调用了join,相当于在主线程中,等待t1线程结束
main方法在执行的时候,遇到join就会堵塞等待,一直等t1线程执行完毕,这个时候join才会继续往下执行
也就是说谁调用join 谁先结束
=========================================================================
当执行sleep时就是让线程休眠,所谓的休眠就是把线程的task struct放入等待队列
CPU在执行的时候是挑等待队列中的线程来执行的,而sleep的线程在等待队列不在就绪队列,所以不会被执行
也可以在sleep中加上时间,等时间过去后,等待队列的线程才有机会到就绪队列,至于什么时候到就绪队列还是要看调度器执行
等待队列可能有好多了,具体谁先出队列,先回到就绪队列和设定的时间相关,如果时间一样就看系统的调度
==========================================================================
在我们调试多线程程序有帮助
| NEW | Thread 对象刚创建,还没有在系统中创建线程,相当于任务交给了线程,但是线程还没有开始执行 |
| — | — |
| Runnable | 线程是一个准备就绪的状态,随时可能调度到CPU上执行,或者正在CPU上执行(线程的task struct在就绪队列中) |
| Blocked | 线程堵塞(线程在等待队列里)没有竞争到锁 |
| Waiting | 线程堵塞(线程在等待队列里)调用waiting 方法 |
| Timed_Waiting | 线程堵塞(线程在等待队列里)调用sleep方法 |
| Terminated | 线程结束了(Thread对象还没销毁) |
================================================================================
多线程虽然是更轻量的并发编程(相比于进程),但是线程是访问同一份内存资源,由于线程是一个抢占式执行的过程中谁先执行,谁后执行,不确定,完全却决于系统的调度。由于这里不确定性太多就可能导致多个线程访问同一个资源的时候,出现BUG所以引出了线程安全问题。 访问分为读和写操作,读操作不会涉及到线程安全问题,只有写操作涉及线程安全工作
多线程修改同一变量
public class Demo {
//线程安全问题
static class Counter{
//创建一个自增类,通过线程调度来展示线程安全问题
public int count=0;
public void increase(){
count++;
}
}
public static void main(String[] args) {
//通过两个线程同时对count进行自增
Counter counter=new Counter();
Thread t1=new Thread(){
@Override
public void run() {
for(int i=0;i<50000;i++){
counter.increase();
}
}
};
Thread t2=new Thread(){
@Override
public void run() {
for(int i=0;i<50000;i++){
counter.increase();
}
}
};
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(counter.count);
}
}
此处代码就是t1,t2 两个线程修改同一变量,存在线程安全问题,正常情况下count值应该是100000,但是运行下来,count值是在50000~100000之间,每次都在变化,这是为什么呢? 这里就是触发了线程安全的问题
这里我们先看count ++ 具体做了什么事情,这里我们就要引入JMM了
JMM(JVM 实现方式的抽象,Java 程序和内存之间是如何交互的)
1)先把内存数据读取到CPU的寄存器中
2)针对寄存器中的内容,通过类似于ADD这样的指令进行+1,操作的结果仍然是放在寄存器中里
3)把寄存器中的数据,写回到内存中
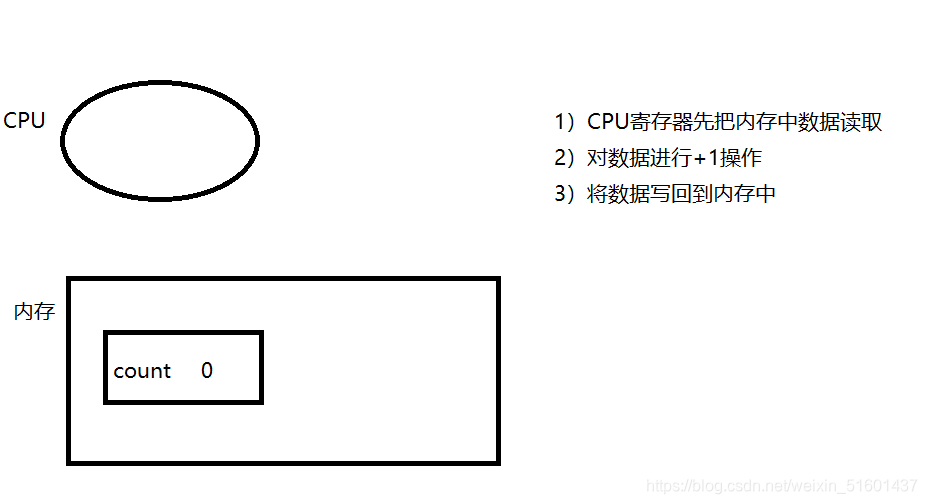
由于多线程之间是抢占式执行的,可能第一个线程执行自增一半时,就可能被调度出CPU,由第二个线程再次自增

LOAD就是从内存中读取数据到寄存器 ADD就是进行自增效果 SAVE就是将寄存器中数据写回内存中
如果出现第一个线程读取到数据为0时,在进行自增操作时,线程二也进行读取数据,两个线程都读到的是0,相当于两次自增操作只增加了一次,只要是线程二的读取不是在线程一SAVE操作后,就会发生自增异常的情况!所以两个线程分别自增50000次,数据最后的数值是在50000~100000之间的。这就是抢占式执行同一个资源所带来的异常!
如果这里是两个CPU也是同样的情况,这样的不确定性,不符合预期的要求,就认为是BUG,因为我们执行代码就是追求的是确定性
由于多线程是抢占式执行,可能会出现第一个线程自增执行到一半就被调度出去,就会执行第二个线程。
1)线程的抢占式执行过程(无法修改)操作系统内核实现的
2)多个线程修改同一变量
3)修改操作不是原子性 (原子性:不可拆分)如果三个操作(读取,自增,写回)打包成一个整体,这就能解决了线程不安全问题,保证操作原子性,是保证线程安全的主要手段
4)内存可见性
两个线程同时操作一个内存,比如一个读一个写,写操作的线程进行修改时,读线程读取到的可能是修改之前的结果,也可能是读取到修改之后的结果,也会带来线程安全问题
内存可见性也可能是编译器优化,假设执行一个循环自增,这样的操作就涉及到大量的读写操作,读写内存的操作比访问CPU寄存器要慢几千倍,所以JVM往往对指令进行优化,把它等价转换成另外一种情况 保证逻辑不变的情况下,读取一次内存,之后进行自增,自增结束后在写回内存,节省了很多的 读写内存的开销,但是这样会触发线程不安全。
解决可见性,方案就是直接禁止这样的编译器的优化,让程序跑慢点,关键是要对,不能在多线程情况下出错
5)指令重排序
和线程不安全直接相关,也是和编译器优化直接相关,为了让程序跑的更快,调整了执行顺序~(调整的前提逻辑不改变,但是效率提高),如果是多线程的情况下可能重排会改变逻辑,会导致线程不安全问题。
1)多线程不修改同一变量
synchronized
synchronized(关键字) 监视器锁 ,我们通过加锁来保证操作原子性,同时禁止指令重排序和保证内存可见性
用法:
1.修饰一个方法 (方法前加上,就是针对代码进行加锁工作,调用方法就加锁,出了代码块就解锁)

2.修饰一个代码块(包裹起来) 针对哪个对象加锁,括号内就填哪个对象

分析synchroized 工作过程
使用synchronized 就是 相当于增加于给操作增加了两个指令 LOCK UNLOCK
LOCK 操作的特性,只有一个线程能执行成功,直到另一个线程释放UNLOCK 另一个线程才能执行
就比如上面演示的自增操作,加锁就相当于把LOAD ADD SAVE 三个操作打包为一个操作,这样就解决了线程的原子性,并且synchronized也能禁止编译器的进行内存可见性和指令重排序,所以使用synchronized就解决了线程安全问题,但是synchronized也付出了代价,程序运行的效率大大降低了。
最后
面试题文档来啦,内容很多,485页!
由于笔记的内容太多,没办法全部展示出来,下面只截取部分内容展示。
1111道Java工程师必问面试题

MyBatis 27题 + ZooKeeper 25题 + Dubbo 30题:

Elasticsearch 24 题 +Memcached + Redis 40题:

Spring 26 题+ 微服务 27题+ Linux 45题:

Java面试题合集:

使用synchronized 就是 相当于增加于给操作增加了两个指令 LOCK UNLOCK
LOCK 操作的特性,只有一个线程能执行成功,直到另一个线程释放UNLOCK 另一个线程才能执行
就比如上面演示的自增操作,加锁就相当于把LOAD ADD SAVE 三个操作打包为一个操作,这样就解决了线程的原子性,并且synchronized也能禁止编译器的进行内存可见性和指令重排序,所以使用synchronized就解决了线程安全问题,但是synchronized也付出了代价,程序运行的效率大大降低了。
最后
面试题文档来啦,内容很多,485页!
由于笔记的内容太多,没办法全部展示出来,下面只截取部分内容展示。
1111道Java工程师必问面试题
[外链图片转存中…(img-WMCFGkli-1719268810420)]
MyBatis 27题 + ZooKeeper 25题 + Dubbo 30题:
[外链图片转存中…(img-Kkc9WLh9-1719268810420)]
Elasticsearch 24 题 +Memcached + Redis 40题:
[外链图片转存中…(img-eMjSgl4A-1719268810421)]
Spring 26 题+ 微服务 27题+ Linux 45题:
[外链图片转存中…(img-5qlcn7Vn-1719268810421)]
Java面试题合集:
[外链图片转存中…(img-JTy8UMMq-1719268810422)]
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









