







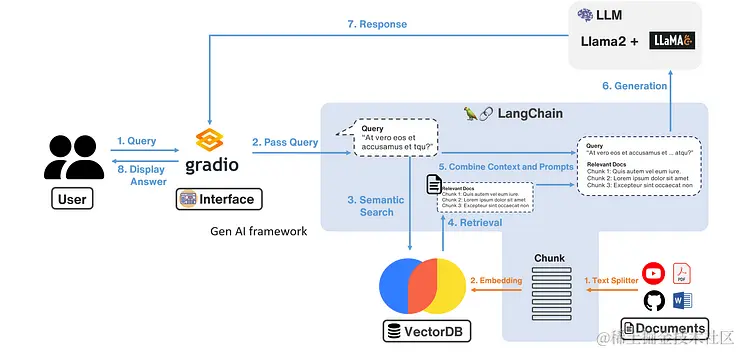
 本文将逐步指导您创建自己的RAG(检索增强生成)系统,使您能够上传自己的PDF文件并向LLM询问有关PDF的信息。本教程侧重于图中蓝色部分,即暂时不涉及Gradio(想了解已接入
本文将逐步指导您创建自己的RAG(检索增强生成)系统,使您能够上传自己的PDF文件并向LLM询问有关PDF的信息。本教程侧重于图中蓝色部分,即暂时不涉及Gradio(想了解已接入Gradio的,请参考官网)。相关技术栈包括以下内容:
- LLM:
Llama2 - LLM API:
llama.cpp service - Langchain:
- Vector DB:
ChromaDB - Embeding:
sentence-Tranformers
核心在于 Langchain,它是用于开发由语言模型支持的应用程序的框架。LangChain 就像胶水一样,有各种接口可以连接LLM模型与其他工具和数据源,不过现在 LangChain 正在蓬勃发展中,许多文件或API改版很多。以下我使用最简单的方式示范。
步骤1. 环境设置
首先设置 Python 环境,我使用 conda 创建环境,并安装以下库,我在 Jupyter 环境完成示例。
arduino复制代码 # python=3.9
ipykernel
ipywidgets
langchain
PyMuPDF
chromadb
sentence-transformers
llama-cpp-python
步骤2. 读入文件处理并导入数据库。
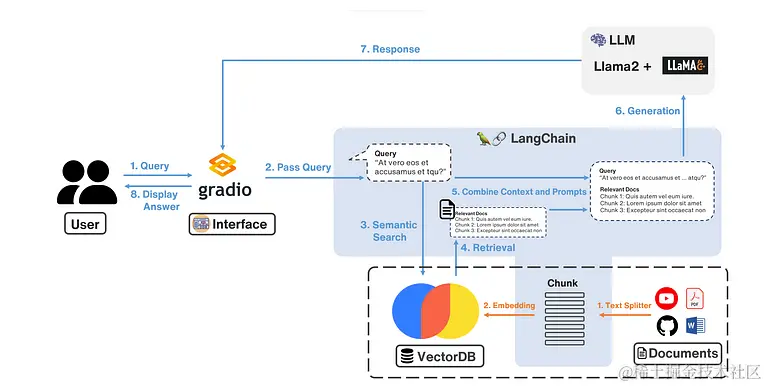
首先我们要将外部信息处理后,放到 DB 中,以供之后查询相关知识,这边的步骤对应到上图框起来的部分,也就是橘色的 1. 文本拆分器 和 2. embedding。
a). 使用文件加载器
Langchain 提供了很多文件加载器,总共大约有55种,包括word、csv、PDF、GoogleDrive、Youtube等,使用方法也很简单。这里我创建了一个虚拟人物 Alison Hawk 的 PDF 信息,并使用read in,Alison Hawk 的 PDF 信息。请注意需要安装 PyMuPDFLoader 才能使用。PyMuPDFLoader PyMuPDF
py复制代码 from langchain.document_loaders import PyMuPDFLoader
loader = PyMuPDFLoader("LangChain/Virtual_characters.pdf")
PDF_data = loader.load()
文本分割器会将文档或文字分割成一个个 chunk,用以预防文档的信息超过 LLM 的 tokens,有一些研究在探讨如何将 chunk 优化。我们后续文章中讨论。
这两种常用的工具之间的区别在于,如果块大小超过指定阈值,它们会递归地将文本分割为更小的块。LangChain提供这两种方式,并且主要参数如下:
py复制代码 - RecursiveCharacterTextSplitter
- CharacterTextSplitter
- chunk size:决定分割文字时每个内存块中的最大字元数。它指定每个内存块的大小或长度。
- chunk_overlap:决定分割文字时连续内存块之间重叠的字元数。它指定前一个内存块的多少应包含在下一个内存块中。
py复制代码 from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=5)
all_splits = text_splitter.split_documents(PDF_data)
在上面的代码中我们指定chunk_size=100, chunk_overlap=5, 这样的意思就是我们每块的文档中是 100 个字符,chunk_overlap 表示字符重复的个数,这样可以避免语义被拆分后不完整。
c) 加载嵌入模型
然后使用嵌入将步骤(b)分割的块文本转换为向量,LangChain提供了许多嵌入模型的接口,例如OpenAI、Cohere、Hugging Face、Weaviate等,请参考LangChain官网。
这边我使用Hugging Face的Sentence Transformers,它提供了许多种pretrain模型,可以根据你的需求或应用情境选择,我选择,其他model细节可以看到HuggingFace。注意要先安装才能使用。all-MiniLM-L6-v2sentence-Tranformers
py复制代码 from langchain.embeddings import HuggingFaceEmbeddings
model_name = "sentence-transformers/all-MiniLM-L6-v2"
model_kwargs = {
'device': 'cpu'}
embedding = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs
)
d) 将Embedding结果汇入VectorDB
我们会将嵌入后的结果存储在VectorDB中,常见的VectorDB包括Chroma、Pinecone和FAISS等,这里我使用Chroma来实现。Chroma与LangChain整合得很好,可以直接使用 LangChain的接口进行操作。
py复制代码 # embed 并存储文本
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









