







逻辑回归
7.1 Motivations
在第一周中,我们了解到监督学习主要用于处理回归问题与分类问题。
二者的区别在于:
- 回归问题的输出是连续实数。
- 分类问题的输出是离散的类别标签或类别概率。
在之前的章节中我们学会了使用线性回归模型来解决简单的回归问题,而对于分类问题,线性回归的效果并不好。
在这里,我们提出广义线性回归模型:
,即
,其中
单调可微。
对数线性回归为例:,
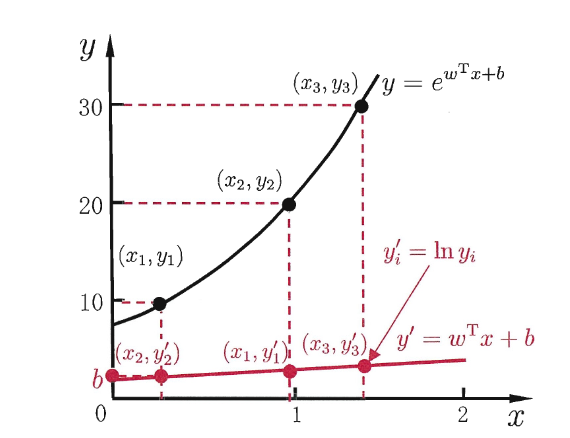
通过对数函数的映射,我们把线性回归模型与非线性的输出联系到了一起。
解决分类问题的思想就蕴藏在这种广义模型中:只需找到一个单调可微的函数 将分类任务的类别标签
与线性回归模型的预测值建立联系。
在下一节中,我们来学习一下一种常用的激活函数:sigmoid函数。
7.2 逻辑回归
上一节我们说到,要找到某个合适的联系函数处理分类问题。假设我们分类问题的类别标签是0和1的话,最理想的分类函数应该是这样的“单位跃迁函数”:
,其中
可惜的是,这个函数的数学性质很差,不可微的缺点使梯度下降无法顺利进行。
所以我们一般退而求其次,使用 sigmoid 函数:
,其曲线如图2:
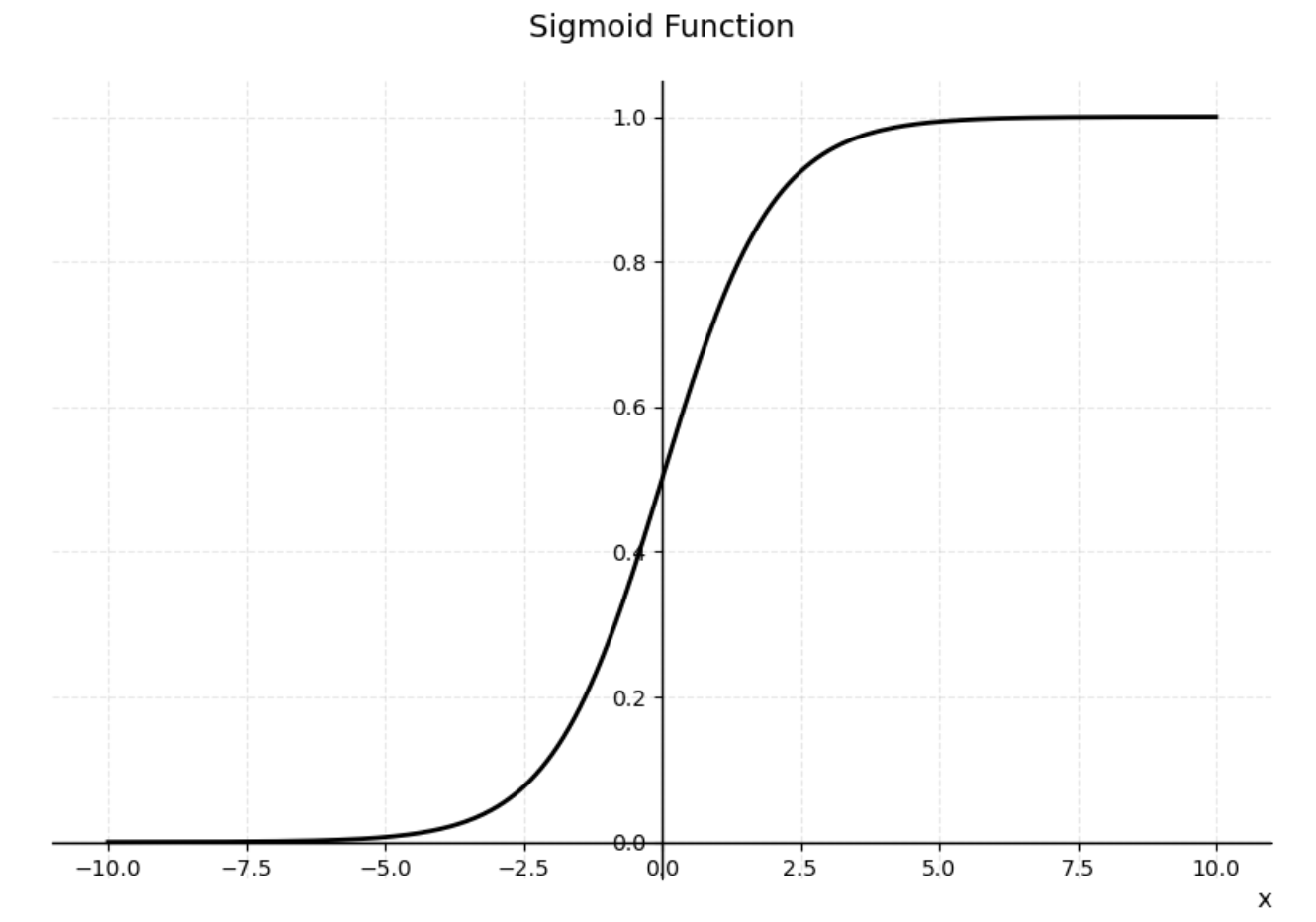
该函数n阶可导,而且在 0 附近斜率陡峭,可以较好地模拟单位跃迁函数。
这样,我们的分类模型就变成了:
,
我们可以将函数 理解为标记为正类的概率。比如,在恶性肿瘤肿瘤分类案例中(记恶性为正例)
取值为 0.9 ,那么我们就认为这个肿瘤有百分之九十的可能性为恶性。
我们可以再往下总结一步:
,
。
小结一下,这种算法虽然叫逻辑“回归”,但是实际上是在用回归问题的预测值逼近分类结果的概率。这种方法有很多优点,他不仅预测类别,还能求出分类的概率,这在许多需要利用概率的决策问题中有很大的便利;同时,sigmoid函数有很好的数学性质,许多已有的优化算法可以直接套用。
7.3 决策边界
决策边界是分类问题中区分不同类别的超曲面,是特征空间中不同结果或分类的区域的分界。决策边界可以是线性的,也可以是非线性的,取决于数据的分布和所使用的分类算法。
-
在二维特征空间中,决策边界是一条直线或曲线。
-
在三维特征空间中,决策边界是一个平面或曲面。
-
在高维特征空间中,决策边界是一个超平面或超曲面。
通过可视化的手段,决策边界直观地展示了模型的分类能力,有助于理解模型是如何进行预测的。
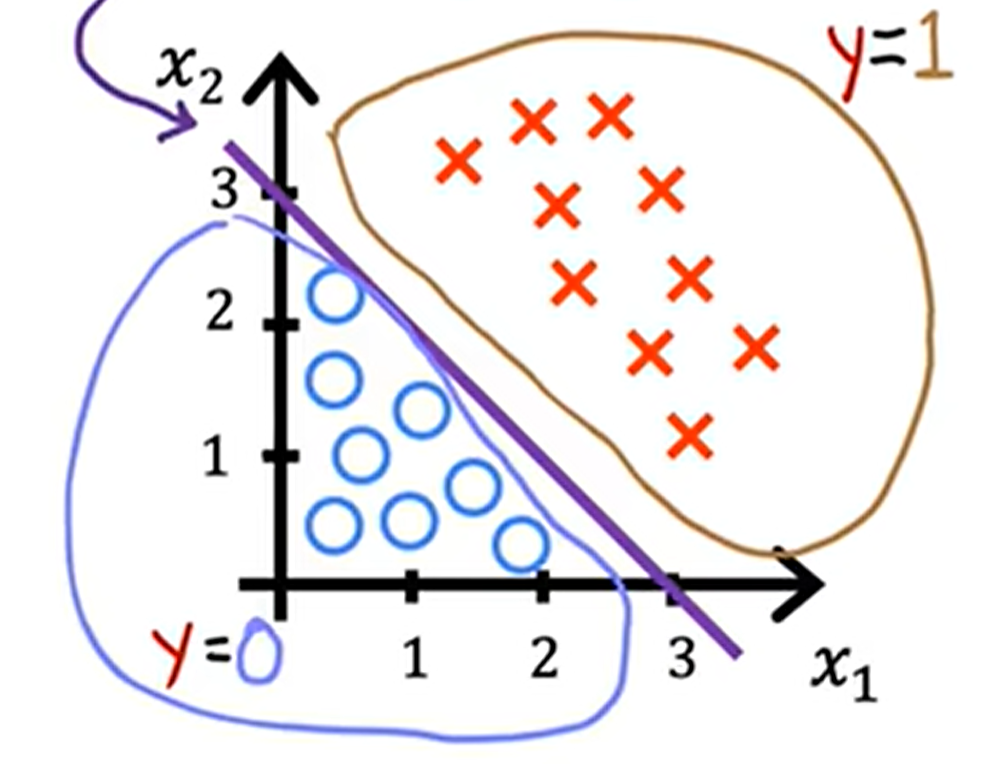
以逻辑回归为例:
对于 ,当
大于零时,分类结果为正例(1),小于零时则为负例(0),那么我们就得到
这一超平面作为我们的决策边界。
对于这个例子的二维特征空间情况,我们的决策边界就是一条直线(如图3):
在多项式回归或者随机森林等算法中,决策边界是非线性的。
8.1 逻辑回归的代价函数
在理解了逻辑回归之后,我们需要进一步为其确定一个代价函数。
在线性回归模型中,我们使用了均方误差函数作为代价函数。然而,在逻辑回归算法中,均方误差函数就会出现问题了:
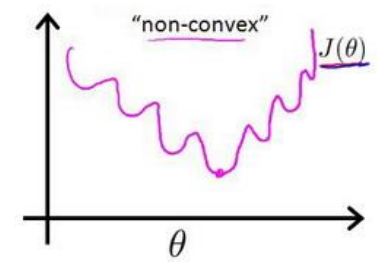
如图4,在逻辑回归中代入均方误差函数以后的代价函数是非凸函数,这意味着我们的有许多个局部最小值,这不利于我们的梯度下降过程。
这里,我们重新定义逻辑回归的代价函数为,其中
这个函数的特点是:当 y=1 时, 若不为 1 ,误差变大;当 y=0 时,
若不为 0 ,误差变大。
为了方便计算,我们可以把这个函数给简化成 :
将其代入代价函数得:
8.2 梯度下降的实现
明确了以上这些以后就很简单了,我们还是把问题概括成:
把 代为
,
这个代价函数关于参数的梯度很简洁:
。
梯度下降的过程可以用python代码简单表示为:
for i in range(iterations):
# 计算预测值
h = np.dot(X, theta)
# 计算梯度
gradient = (1/m) * np.dot(X.T, (h - y))
# 更新参数
theta = theta - alpha * gradient9.1 多元分类:一对多
在这节中,我们会学习如何使用逻辑回归解决多分类问题。
我们介绍一个叫“一对多”(one-vs-all)的思路:
- 对于每个类别,我们训练一个逻辑回归模型,将该类别作为正类,其他所有类别作为负类。对于每个样本,我们计算它属于每个类别的概率,然后选择概率最高的类别作为预测结果。
用课程中的例子作说明,假设我们有这样的一组数据:
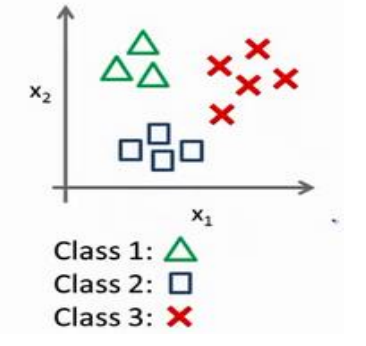
我们就可以分别为三个类别分别训练逻辑回归模型:
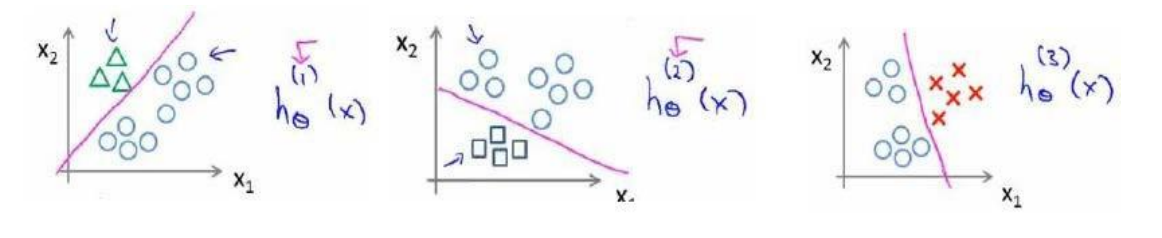
这样我们得到了一系列训练好的模型。
最后,在我们进行预测的时候,只要对于每个样本把每个模型都运行一遍,最后取正确概率最大的一个即可。
正则化原理
10.1 过拟合与欠拟合
通俗来讲,过拟合就是学得太细致,把很多不必要的细节也给学进去了,欠拟合则是学得太草率,很多细节没能学进去。
打个比方,比如你要学习一个数据集来学会鉴定某物体否是棵树。当你过拟合了,可能学成“必须要有2039片边缘成锯齿状的叶子才是一棵树”;当你欠拟合了,可能就会学成“只要是绿色的都是树”。
在拟合曲线中,欠拟合一般体现为曲线过于简单,而过拟合一般体现为曲线过于复杂,不具备泛化能力(如图5)。
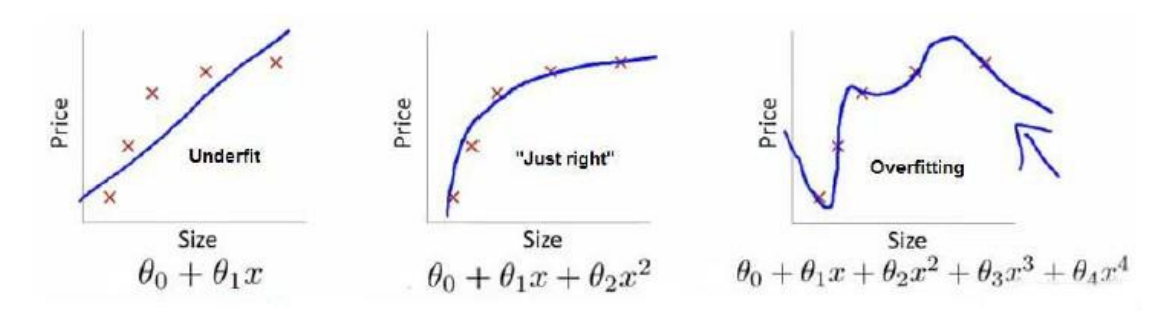
10.2 正则化
正则化是解决过拟合的有力手段。从图5第三个曲线中可见,导致过拟合的主要原因在与某些高次项特征,如果我们可以对其权重 进行限制,就可以很好地解决这个问题。这就是正则化的主要思想。
接下来,我们将学习正则化实现的手段:
就以上面的多项式回归为例,假设三次项与四次项导致了过拟合我们可以对原本代价函数——均方误差函数进行一些修改,加入惩罚项:
显然,这样的一个代价函数确定的的最佳、
会比原来小很多,过拟合的问题得到改善。
然而在实战中,我们往往不知道什么样的特征应该被惩罚,所以一般会构造如此的代价函数:
为解决过拟合的问题,我们会对所有项进行惩罚(除),并依赖代价函数最优化的软件来找到最佳的正则化参数
。
正则化的思路在大部分模型中都常见,只需在原有的代价函数中加入正则项,然后正常进行梯度下降,就可以很好地解决过拟合的问题。
实战——鸢尾花数据集逻辑回归
我们使用sklearn库中的鸢尾花数据集。输入如下语句可以从库中导入:
from sklearn import datasets
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data # 使用所有特征
y = iris.target包含4个特征(萼片长度、萼片宽度、花瓣长度、花瓣宽度)和3个类别(Setosa、Versicolor、Virginica),适合用于多分类问题。
具体训练这里直接使用了已有的逻辑回归库,同样可以从sklearn中导入。以下是完整的代码:
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 特征压缩
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
model = LogisticRegression(multi_class='multinomial', solver='lbfgs', max_iter=1000)
model.fit(X_train, y_train)
如果想要看一下模型的效果,可以加入以下的可视化部分,为了便于画图,这里选择了决策边界在某二维特征空间上的投影:
import matplotlib.pyplot as plt
def plot_decision_boundary(X, y, model, feature1, feature2):
X_reduced = X[:, [feature1, feature2]]
scaler_2d = StandardScaler()
X_reduced_scaled = scaler_2d.fit_transform(X_reduced)
x_min, x_max = X_reduced_scaled[:, 0].min() - 1, X_reduced_scaled[:, 0].max() + 1
y_min, y_max = X_reduced_scaled[:, 1].min() - 1, X_reduced_scaled[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
np.arange(y_min, y_max, 0.01))
grid_points = np.c_[xx.ravel(), yy.ravel()]
grid_points_scaled = scaler_2d.transform(grid_points)
grid_points_full = np.zeros((grid_points_scaled.shape[0], X.shape[1]))
grid_points_full[:, [feature1, feature2]] = grid_points_scaled
Z = model.predict(grid_points_full)
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3)
plt.scatter(X_reduced_scaled[:, 0], X_reduced_scaled[:, 1], c=y, edgecolors='k', marker='o')
plt.xlabel(iris.feature_names[feature1])
plt.ylabel(iris.feature_names[feature2])
plt.title('Decision Boundary')
plt.show()
# 绘制决策边界
plot_decision_boundary(X_train, y_train, model, 2, 3) # 使用花瓣长度和花瓣宽度可视化决策边界如下:
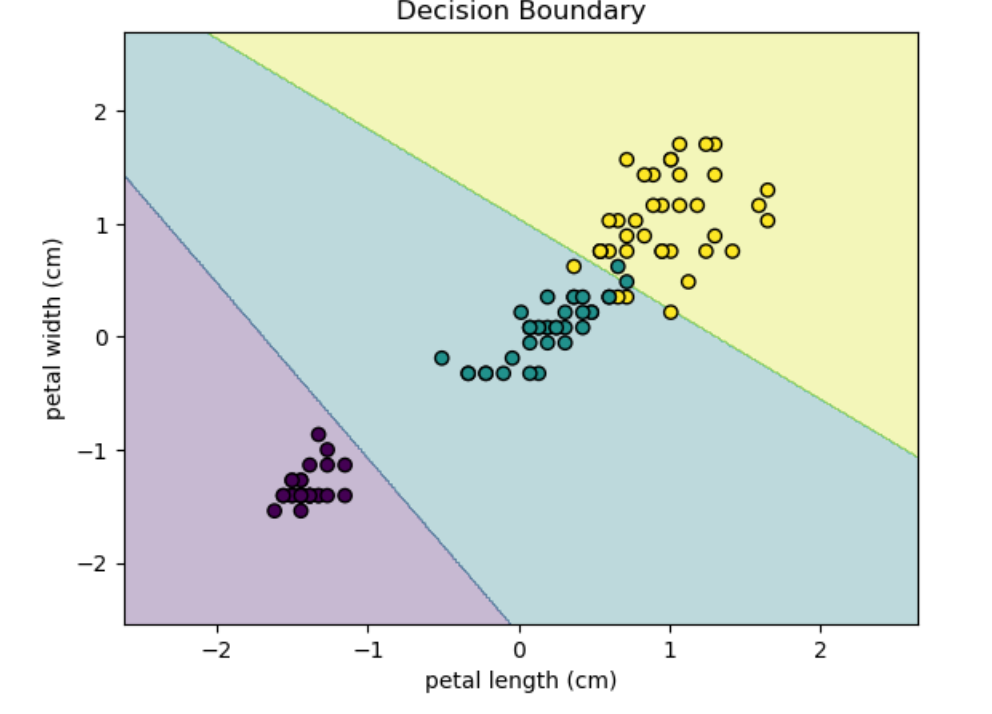
这样,我们就在鸢尾花数据集上使用逻辑回归完成了一个多分类。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









