






文章目录
计算机网络基础
一、计算机网络章节介绍
1.网络与生活密不可分
2.IT行业的网络
3.如何学习网络技术
重在理解。理解原理,理解概念(能够复述)
4.网络基础概念
- 网络基础概念–网络模型
- 各种网络协议–报文结构
- 网络技术
二、单机设备实现上网的必备条件
1.网卡
-
数据信号传输过程。
-
信号的转换过程——调制与解调过程
- 调制过程:二进制信号转换为电信号的过程
- 解调过程:电信号转换为数据信号的过程
2.传输媒介
1.网线
双绞线
线序:
568a:白绿,绿,白橙,蓝,白蓝,橙,白棕,棕
568b:橙白,橙,白绿,蓝,白蓝,绿,白棕,棕。目前最为常见
制作材质区分
五类线 网线外侧有 CAT.5 的标记,最高的传输频率为 100MHz,传输速率为 100Mbps,适用于百兆以下的网络
超五类 网线外侧有 CAT.5e 的标记 传输频率与五类相同,但最高传输速率是 1000Mbps,适用于千兆网络上
六类线 网线外侧有 CAT.6 的标记,传输频率是 250MHz,最高传输速率为 1Gbps,适用于千兆网络中
超六类 网线外侧有 CAT.6e 的标记,最大传输频率为 500 MHz,传输速度为 10Gbps,适合用于万兆的网络中
七类线 七类的线芯是 0.57mm 左右的铜线,是高纯度的无氧铜,这能保证超低电阻,从而能传输更远,更稳定
八类线 40Gbps
光纤:一定不可以折死角
网线长度越长带宽速率损耗越大
| 最高的传输频率 | 传输速率 | 适用于 | ||
|---|---|---|---|---|
| 五类线 | CAT.5 | 100MHz | 100Mbps | 百兆以下的网络 |
| 超五类 | CAT.5e | 100MHz | 100Mbps | 千兆网络 |
| 六类线 | CAT.6 | 250MHz | 1Gbps | 千兆网络 |
| 超六类 | CAT.6e | 500 MHz | 10Gbps | 万兆网络 |
2.wifi
版本:
wifi4
wifi5
wifi6
wifi7
3.接口需要具备速率协商
由高频率一方向下兼容
三、多人网络是如何构成的
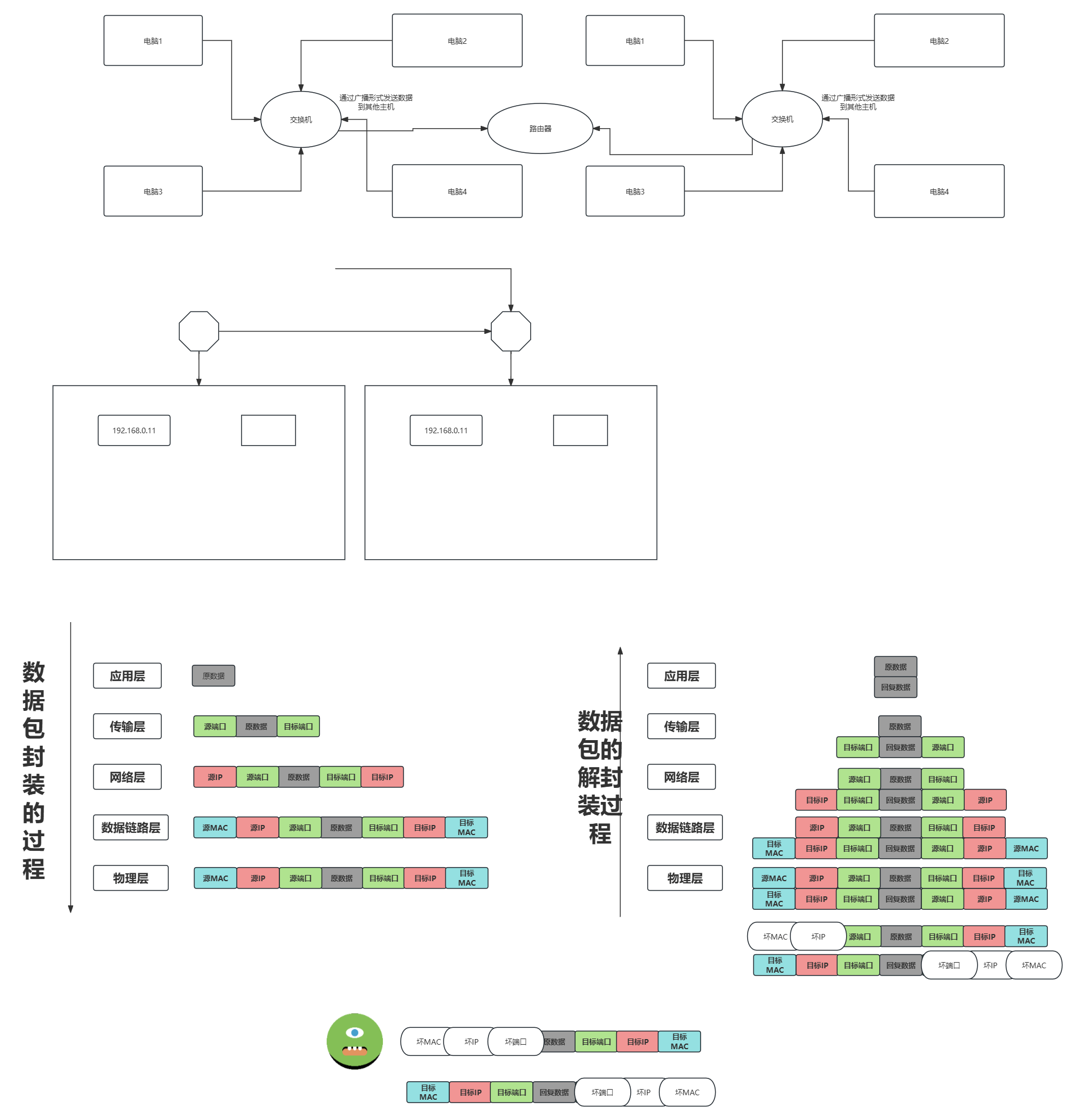
1.交换机
通过广播构建多人同网段的局域网
容易产生广播风暴问题:vlan技术
2.路由器
通过路由规则,打通不同的网络通信
四、网络模型标准——osi七层模型
1.介绍
七层模型,亦称OSI(Open System Interconnection)。参考模型是国际标准化组织制定的一个用于计算机或通信系统间互联的标准体系,一般称为OSI参考模型或七层模型。
2.七层结构
物理层
建立、维护、断开物理连接。(由底层网络定义协议)
数据链路层
建立逻辑连接、进行硬件地址寻址、差错校验等功能。(由底层网络定义协议)
将比特组合成字节进而组合成帧,用MAC地址访问介质,错误发现但不能纠正。
协议:ARP协议 实现MAC地址的寻址
网络层
进行逻辑地址寻址,实现不同网络之间的路径选择。ip地址
协议有:ICMP(ping命令) IGMP IP(IPV4 IPV6)
传输层
定义传输数据的协议端口号,以及流控和差错校验。
协议有:TCP UDP,数据包一旦离开网卡即进入网络传输层
会话层:负责通信会话的连接与断开
表示层:数据包进行进一步处理,数据格式加密,数据包压缩
应用层:协议有:HTTP HTTPS FTP TFTP SMTP POP3 SNMP DNS TELNET DHCP
HTTP超文本传输协议
HTTPS安全的超文本传输协议
FTP文件传输协议
TFTp特殊的文件传输协议
SMTP,POP3邮件协议
SNMP传输系统性能指标的协议,一般用于监控
DNS域名解析
TELNET连接接口默认23端口
DHCP
| 七层结构 | 功能 | 协议 |
|---|---|---|
| 物理层 | 建立、维护、断开物理连接 | |
| 数据链路层 | 建立逻辑链接,进行硬件地址寻址、差错校验等功能 | arp |
| 网络层 | 进行逻辑地址寻址。实现不同网络间的路径选择 | icmp,igmp,ip |
| 传输层 | 定义传输数据的协议端口号,以及流控和差错校验 | tcp,udp |
| 会话层 | 负责通信会话的连接与断开 | |
| 表示层 | 对数据包进一步处理,数据格式加密,数据包压缩 | |
| 应用层 | http,https,dhcp,telnet,dns,ftp |
3.OSI七层模型规划出来的数据包的封装与解封装的流程















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









