






1.删除排序链表中的重复元素II
给定一个已排序的链表的头
head, 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。示例 1:
输入:head = [1,2,3,3,4,4,5] 输出:[1,2,5]示例 2:
输入:head = [1,1,1,2,3] 输出:[2,3]提示:
- 链表中节点数目在范围
[0, 300]内-100 <= Node.val <= 100- 题目数据保证链表已经按升序 排列
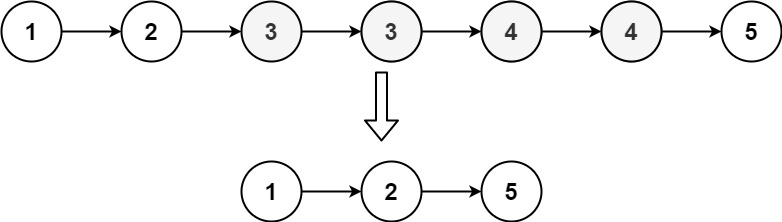
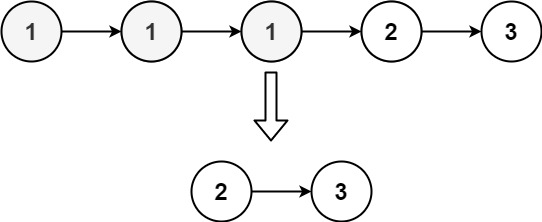
由于给定的链表是排好序的,因此重复元素在链表中出现的位置是连续的 ,我们只需要一次遍历就可以删除重复元素,由于链表头结点也可能被删所以需要引入虚拟头结点。注意链表为空需要特判。如果当前 cur->next 与 cur->next->next 对应的元素相同(不过前提是它俩不能为空结点),那么我们就需要将 cur->next 以及所有后面拥有相同元素值的链表结点全部删除。我们记下这个元素值 x,随后不断将 cur->next 从链表中移除,直到 cur->next 为空结点或者其元素值不等于 x 为止。此时,我们将链表中所有元素值为 x 的节点全部删除。如果当前 cur->next 与 cur->next->next 对应的元素不相同,继续向后遍历就好
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* deleteDuplicates(struct ListNode* head) {
if(head==NULL) return head;
struct ListNode* dummyhead=(struct ListNode*)malloc(sizeof(struct ListNode));
dummyhead->next=head;
struct ListNode* cur;
cur=dummyhead;
while(cur->next!=NULL&&cur->next->next!=NULL)
{
if(cur->next->val==cur->next->next->val)
{
int x=cur->next->val;
while(cur->next!=NULL&&cur->next->val==x)
//只要当前结点存在,并且它的值还等于 x我们就继续删除它
{
cur->next=cur->next->next;
}
}else{
cur=cur->next;
}
}
return dummyhead->next;
}2.两两交换链表中的结点
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
示例 1:
输入:head = [1,2,3,4] 输出:[2,1,4,3]示例 2:
输入:head = [] 输出:[]示例 3:
输入:head = [1] 输出:[1]提示:
- 链表中节点的数目在范围
[0, 100]内0 <= Node.val <= 100
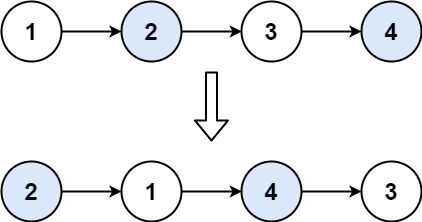
二话不说虚拟头节点是基础操作,要对两个结点进行交换操作那么就一定要让cur指针指向这两个结点的前一个结点
while循环的条件旨在确保当前还有两个结点可以交换(注意顺序,避免空指针异常),在交换过程中我们一定要预先保存链表第1个和第3个结点的地址,否则在交换过程中就无法对这些结点进行定位,更无法交换了。在操作完之后将cur指针向前移动两位再进行下一次操作
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* swapPairs(struct ListNode* head) {
struct ListNode* dummyhead=(struct ListNode*)malloc(sizeof(struct ListNode));
dummyhead->next=head;
struct ListNode *cur,*temp,*temp1;
cur=dummyhead;
while(cur->next!=NULL&&cur->next->next!=NULL)//注意顺序
{
temp=cur->next;
temp1=cur->next->next->next;
cur->next=cur->next->next;
cur->next->next=temp;
temp->next=temp1;
cur=cur->next->next;
}
return dummyhead->next;
}3.有效的括号
给定一个只包括
'(',')','{','}','[',']'的字符串s,判断字符串是否有效。有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 每个右括号都有一个对应的相同类型的左括号。
“栈” +哈希表
首先需要创建一个空栈,从左往右遍历,左括号都需要入栈,右括号必须和栈顶的左括号组成一对(消除),然后弹出栈顶。换句话说,由于括号两两一对,所以数组长度必须是偶数。在遍历结束的时候,如果栈为空,说明所有括号均已匹配完毕返回true。反之,如果在遍历的过程中,发现栈为空,或者括号类型不匹配的情况,返回false。此外,如果遍历结束栈不为空,说明还有没匹配的左括号,返回false
bool isValid(char* s) {
char mp[128] = {};
mp[')'] = '(';
mp[']'] = '[';
mp['}'] = '{';
int top = 0; // 直接把 s 当作栈
for (int i = 0; s[i]; i++) {
char c = s[i];
if (mp[c] == 0) { // c 是左括号
s[top++] = c; // 入栈
} else if (top == 0 || s[--top] != mp[c]) { // c 是右括号
return false; // 没有左括号,或者左括号类型不对
}
}
return top == 0; // 所有左括号必须匹配完毕
}4.买卖股票的最佳时机
给定一个数组
prices,它的第i个元素prices[i]表示一支给定股票第i天的价格。你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回
0。示例 1:
输入:[7,1,5,3,6,4] 输出:5 解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。 注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。示例 2:
输入:prices = [7,6,4,3,1] 输出:0 解释:在这种情况下, 没有交易完成, 所以最大利润为 0。提示:
1 <= prices.length <= 1050 <= prices[i] <= 104
这道题是典型的贪心算法应用题,贪心算法是一种在求解问题时,每一步都选择当前最优解,以期望最终得到全局最优解的算法思想。贪心算法的基本思想可以总结为“每一步都做出一个局部最优的选择,最终就能得到全局最优解”。
那么在这道题中我们只需要做两件事情,记录“到目前为止的最低价格”和“当前价格卖出时能获得的利润”,不过一定要注意顺序,只有先更新最低价格,才能保证满足题目中先买后卖的要求
int maxProfit(int* prices, int pricesSize) {
int min=10001;
int max=0;
for(int i=0;i<pricesSize;i++)
{
if(prices[i]<min) min=prices[i];
else if(prices[i]-min>max) max=prices[i]-min;
}
return max;
}5.合并k个升序链表
给定一个链表数组,每个链表都已经按升序排列。
请将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]] 输出:[1,1,2,3,4,4,5,6] 解释:链表数组如下: [ 1->4->5, 1->3->4, 2->6 ] 将它们合并到一个有序链表中得到。 1->1->2->3->4->4->5->6示例 2:
输入:lists = [] 输出:[]示例 3:
输入:lists = [[]] 输出:[]提示:
k == lists.length0 <= k <= 10^40 <= lists[i].length <= 500-10^4 <= lists[i][j] <= 10^4lists[i]按 升序 排列lists[i].length的总和不超过10^4
之前做过两个链表的合并,那么合并k个链表其实就是循环进行,也就是说,只要定义出一个头结点,然后让每次的list[i]都与之合并就好。这里用了递归,先确定好怎么结束,当一方为空的时候,返回另一方,最后比较两个元素的值,确定接的顺序,最后返回ans(递归结束之后,它会回溯,所以ans是头结点,最后将每次合成新的再合成)
注意这里不是mergeTwoLists(head, lists[i]),而是 head = mergeTwoLists(head, lists[i]),要更新每次合并好的值
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
if (list1 == NULL) {
return list2;
}
if (list2 == NULL) {
return list1;
}
struct ListNode* ans;
if (list1->val <= list2->val) {
ans = list1;
ans->next = mergeTwoLists(list1->next, list2);
} else {
ans = list2;
ans->next = mergeTwoLists(list1, list2->next);
}
return ans;
}
struct ListNode* mergeKLists(struct ListNode** lists, int listsSize) {
if (!listsSize)
return NULL;
struct ListNode* head = NULL;
for (int i = 0; i < listsSize; i++) {
head = mergeTwoLists(head, lists[i]);
}
return head;
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









