






前言
I/O 或输入/输出通常意味着中央处理器(CPU) 与外部设备(如磁盘、鼠标、键盘等)之间的读写。在深入研究零拷贝之前,有必要指出磁盘 I/O(包括磁盘设备和其他块导向设备)和网络 I/O之间的区别。
磁盘 I/O 的常用接口是 read()、write() 和 seek()。同时,网络 I/O 的接口通常是套接字相关接口。套接字接口背后发生的事情是发送方和接收方计算机创建自己的套接字,并设置发送或接收文件的连接。如今,越来越多的 应用程序已经实现了从CPU绑定到 I/O 绑定的转变,这意味着 I/O 的性能通常是这些应用程序的瓶颈。
一般来说,用户不能直接在内核操作任何数据,包括读写。数据必须从内核复制到用户内存,而这个操作必须由 CPU 来完成,因此带来了很大的性能损失。这时零拷贝就派上用场了。零拷贝的主要原理是尽可能地消除或减少 CPU 在用户内存和内核内存之间的数据复制,从而减少相应的中断和模式切换次数,从而提高网络 I/O 的 I/O 性能。
先备知识
物理内存
物理内存,我们平时所称的内存也叫随机访问存储器( random-access memory )也叫 RAM 。而 RAM 分为两类:
-
一类是静态 RAM( SRAM ),这类 SRAM 用于 CPU 高速缓存 L1Cache,L2Cache,L3Cache。其特点是访问速度快,访问速度为 1 - 30 个时钟周期,但是容量小,造价高。
-
另一类则是动态 RAM ( DRAM ),这类 DRAM 用于我们常说的主存上,其特点的是访问速度慢(相对高速缓存),访问速度为 50 - 200 个时钟周期,但是容量大,造价便宜些(相对高速缓存)。
内存由一个一个的存储器模块(memory module)组成,它们插在主板的扩展槽上。
常见的存储器模块通常以 64 位为单位( 8 个字节)传输数据到存储控制器上或者从存储控制器传出数据。
多个存储器模块连接到存储控制器上,就聚合成了主存。
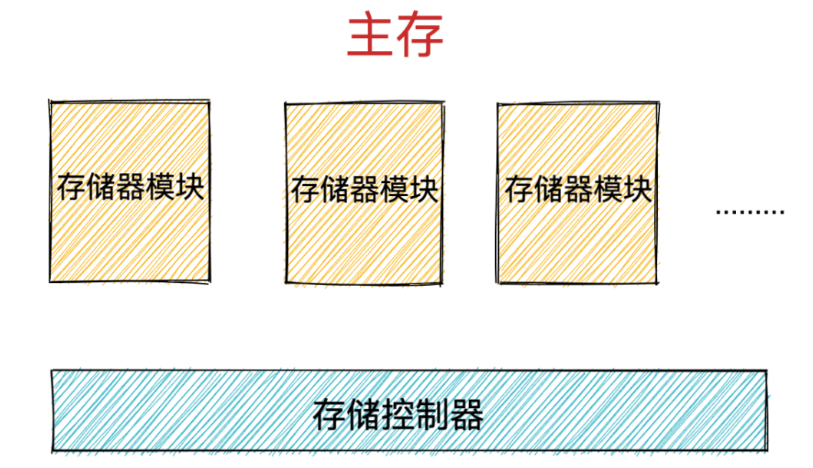
DRAM 芯片就包装在存储器模块中,每个存储器模块中包含 8 个 DRAM 芯片,依次编号为 0 - 7
虚拟内存
虚拟内存 使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。
与没有使用虚拟内存技术的系统相比,使用这种技术的系统使得大型程序的编写变得更容易,对真正的物理内存(例如 RAM)的使用也更有效率。目前,大多数操作系统都使用了虚拟内存,如Windows家族的“虚拟内存”;Linux 的“交换空间”等。
现代处理器使用的是一种称为 虚拟寻址(Virtual Addressing) 的寻址方式。使用虚拟寻址,CPU 需要将虚拟地址翻译成物理地址,这样才能访问到真实的物理内存。
实际上完成虚拟地址转换为物理地址转换的硬件是CPU 中含有一个被称为内存管理单元(Memory Management Unit, MMU) 的硬件。如下图所示:
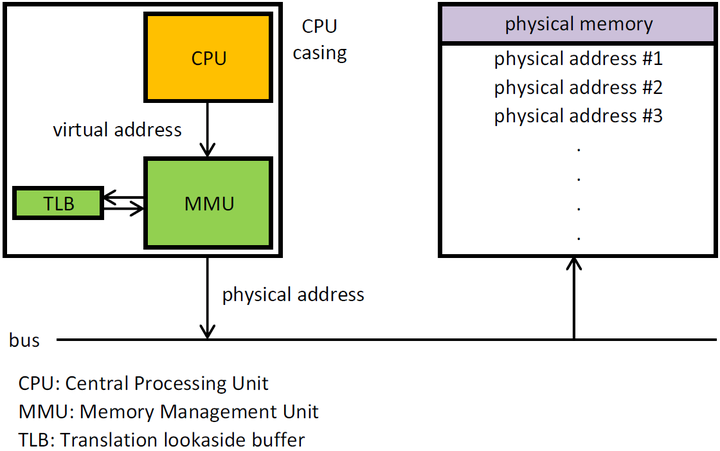
通过虚拟地址访问内存有以下优势:
-
程序可以使用一系列相邻的虚拟地址来访问物理内存中不相邻的大内存缓冲区。
-
程序可以使用一系列虚拟地址来访问大于可用物理内存的内存缓冲区。当物理内存的供应量变小时,内存管理器会将物理内存页(通常大小为 4 KB)保存到磁盘文件。数据或代码页会根据需要在物理内存与磁盘之间移动。
-
不同进程使用的虚拟地址彼此隔离。一个进程中的代码无法更改正在由另一进程或操作系统使用的物理内存。
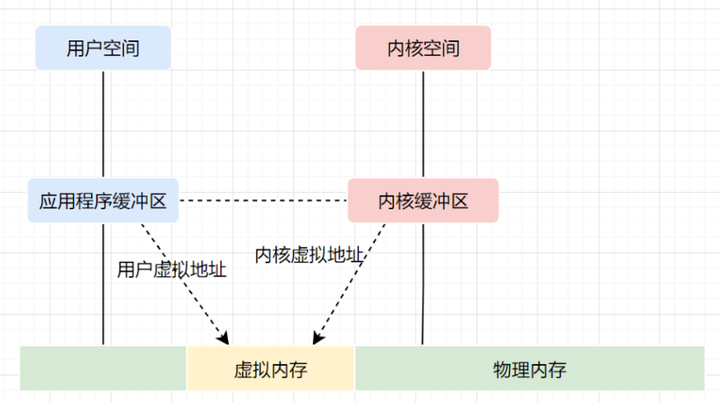
内核空间和用户空间
操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的权限。为了避免用户进程直接操作内核,保证内核安全,操作系统将虚拟内存划分为两部分,一部分是内核空间(Kernel-space),一部分是用户空间(User-space)。 在 Linux 系统中,内核模块运行在内核空间,对应的进程处于内核态;而用户程序运行在用户空间,对应的进程处于用户态。
操作系统为每个进程都分配了内存空间,一部分是用户空间,一部分是内核空间。内核空间是操作系统内核访问的区域,是受保护的内存空间,而用户空间是用户应用程序访问的内存区域。
内核空间
主要提供进程调度、内存分配、连接硬件资源等功能
内核空间总是驻留在内存中,它是为操作系统的内核保留的。应用程序是不允许直接在该区域进行读写或直接调用内核代码定义的函数的。按访问权限可以分为进程私有和进程共享两块区域。
-
进程私有的虚拟内存:每个进程都有单独的内核栈、页表、task 结构以及 mem_map 结构等。
-
进程共享的虚拟内存:属于所有进程共享的内存区域,包括物理存储器、内核数据和内核代码区域。
用户空间
每个普通的用户进程都有一个单独的用户空间,处于用户态的进程不能访问内核空间中的数据,也不能直接调用内核函数的 ,因此要进行系统调用的时候,就要将进程切换到内核态才行。用户空间包括以下几个内存区域:
-
运行时栈:由编译器自动释放,存放函数的参数值,局部变量和方法返回值等。栈区是从高地址位向低地址位增长的,是一块连续的内在区域,最大容量是由系统预先定义好的,申请的栈空间超过这个界限时会提示溢出,用户能从栈中获取的空间较小。
-
运行时堆:用于存放进程运行中被动态分配的内存段,位于 BSS 和栈中间的地址位。由卡发人员申请分配(malloc)和释放(free)。堆是从低地址位向高地址位增长,采用链式存储结构。频繁地 malloc/free 造成内存空间的不连续,产生大量碎片。当申请堆空间时,库函数按照一定的算法搜索可用的足够大的空间。因此堆的效率比栈要低的多。
-
代码段:存放 CPU 可以执行的机器指令,该部分内存只能读不能写。通常代码区是共享的,即其它执行程序可调用它。假如机器中有数个进程运行相同的一个程序,那么它们就可以使用同一个代码段。
-
未初始化的数据段:存放未初始化的全局变量,BSS 的数据在程序开始执行之前被初始化为 0 或 NULL。
-
已初始化的数据段:存放已初始化的全局变量,包括静态全局变量、静态局部变量以及常量。
-
内存映射区域:例如将动态库,共享内存等虚拟空间的内存映射到物理空间的内存,一般是 mmap 函数所分配的虚拟内存空间。
需要C/C++ Linux服务器架构师学习资料加qun579733396获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

DMA传输
DMA 的全称叫直接内存存取(Direct Memory Access),是一种允许外围设备(硬件子系统)直接访问系统主内存的机制。也就是说,基于 DMA 访问方式,系统主内存于硬盘或网卡之间的数据传输可以绕开 CPU 的全程调度。目前大多数的硬件设备,包括磁盘控制器、网卡、显卡以及声卡等都支持 DMA 技术。
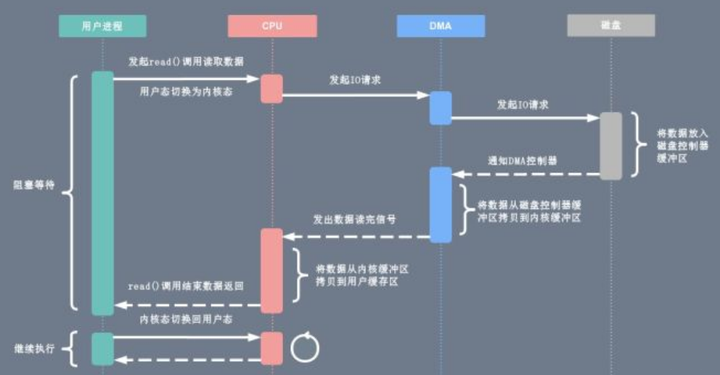
数据读取操作的流程如下:
-
用户进程向 CPU 发起 read() 系统调用读取数据,由用户态切换为内核态,然后一直阻塞等待数据的返回。
-
CPU 在接收到指令以后对 DMA 磁盘控制器发起调度指令。
-
DMA 磁盘控制器对磁盘发起 I/O 请求,将磁盘数据先放入磁盘控制器缓冲区,CPU 全程不参与此过程。
-
数据读取完成后,DMA 磁盘控制器会接受到磁盘的通知,将数据从磁盘控制器缓冲区拷贝到内核缓冲区。
-
DMA 磁盘控制器向 CPU 发出数据读完的信号,由 CPU 负责将数据从内核缓冲区拷贝到用户缓冲区。
-
用户进程由内核态切换回用户态,解除阻塞状态,然后等待 CPU 的下一个执行时间钟。
上下文切换
-
什么是CPU上下文?
CPU 寄存器,是CPU内置的容量小、但速度极快的内存。而程序计数器,则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。它们都是 CPU 在运行任何任务前,必须的依赖环境,因此叫做CPU上下文。
-
什么是CPU上下文切换?
它是指先把前一个任务的CPU上下文(也就是CPU寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
一般我们说的上下文切换,就是指内核(操作系统的核心)在CPU上对进程或者线程进行切换。进程从用户态到内核态的转变,需要通过系统调用来完成。系统调用的过程,会发生CPU上下文的切换。
CPU 寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。
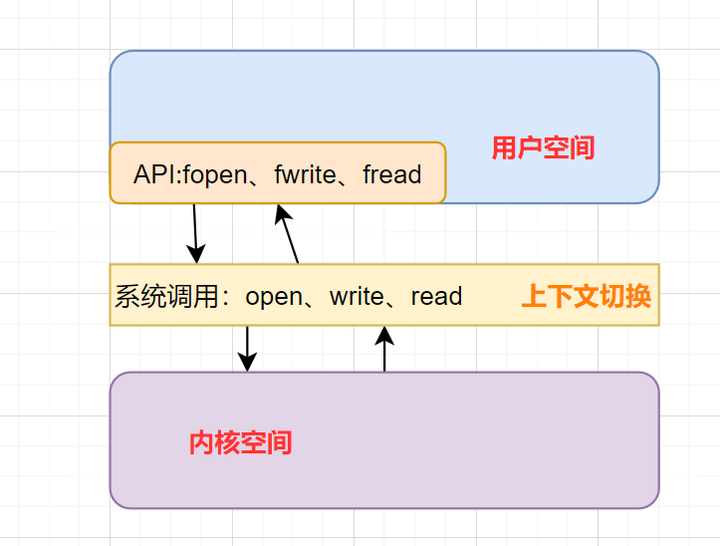
传统的文件传输
如果服务端要提供文件传输的功能,我们能想到的最简单的方式是:将磁盘上的文件读取出来,然后通过网络协议发送给客户端。
传统 I/O 的工作方式是,数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。
代码通常如下,一般会需要两个系统调用:
read(file, tmp_buf, len);
write(socket, tmp_buf, len);代码很简单,虽然就两行代码,但是这里面发生了不少的事情。
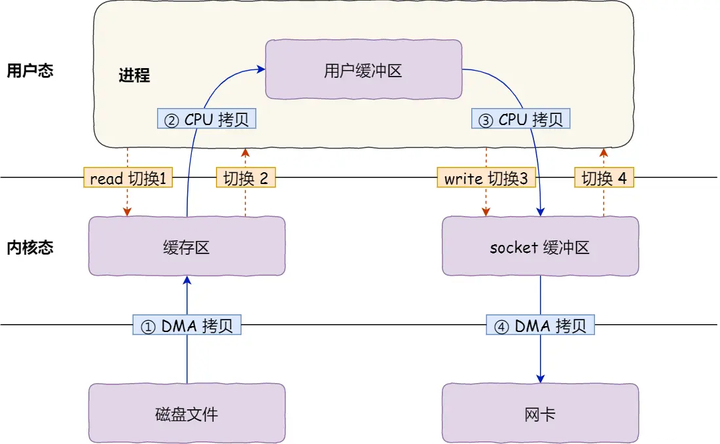
首先,期间共发生了 4 次用户态与内核态的上下文切换,因为发生了两次系统调用,一次是 read() ,一次是 write(),每次系统调用都得先从用户态切换到内核态,等内核完成任务后,再从内核态切换回用户态。
上下文切换到成本并不小,一次切换需要耗时几十纳秒到几微秒,虽然时间看上去很短,但是在高并发的场景下,这类时间容易被累积和放大,从而影响系统的性能。
其次,还发生了 4 次数据拷贝,其中两次是 DMA 的拷贝,另外两次则是通过 CPU 拷贝的,下面说一下这个过程:
-
第一次拷贝,把磁盘上的数据拷贝到操作系统内核的缓冲区里,这个拷贝的过程是通过 DMA 搬运的。
-
第二次拷贝,把内核缓冲区的数据拷贝到用户的缓冲区里,于是我们应用程序就可以使用这部分数据了,这个拷贝到过程是由 CPU 完成的。
-
第三次拷贝,把刚才拷贝到用户的缓冲区里的数据,再拷贝到内核的 socket 的缓冲区里,这个过程依然还是由 CPU 搬运的。
-
第四次拷贝,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程又是由 DMA 搬运的。
我们回过头看这个文件传输的过程,我们只是搬运一份数据,结果却搬运了 4 次,过多的数据拷贝无疑会消耗 CPU 资源,大大降低了系统性能。
这种简单又传统的文件传输方式,存在冗余的上文切换和数据拷贝,在高并发系统里是非常糟糕的,多了很多不必要的开销,会严重影响系统性能。
所以,要想提高文件传输的性能,就需要减少「用户态与内核态的上下文切换」和「内存拷贝」的次数。
如何优化文件传输的性能?
先来看看,如何减少「用户态与内核态的上下文切换」的次数呢?
读取磁盘数据的时候,之所以要发生上下文切换,这是因为用户空间没有权限操作磁盘或网卡,内核的权限最高,这些操作设备的过程都需要交由操作系统内核来完成,所以一般要通过内核去完成某些任务的时候,就需要使用操作系统提供的系统调用函数。
而一次系统调用必然会发生 2 次上下文切换:首先从用户态切换到内核态,当内核执行完任务后,再切换回用户态交由进程代码执行。
所以,要想减少上下文切换到次数,就要减少系统调用的次数。
再来看看,如何减少「数据拷贝」的次数?
在前面我们知道了,传统的文件传输方式会历经 4 次数据拷贝,而且这里面,「从内核的读缓冲区拷贝到用户的缓冲区里,再从用户的缓冲区里拷贝到 socket 的缓冲区里」,这个过程是没有必要的。
因为文件传输的应用场景中,在用户空间我们并不会对数据「再加工」,所以数据实际上可以不用搬运到用户空间,因此用户的缓冲区是没有必要存在的。
零拷贝
通过上面的分析可以看出,内核态到用户态数据的来回拷贝是没有意义的,数据应该可以直接从内核缓冲区直接送入socket缓冲区。零拷贝机制就实现了这一点。
操作系统层面减少数据拷贝次数主要是指用户空间和内核空间的数据拷贝,因为只有他们的拷贝是大量消耗CPU时间片的,而DMA控制器拷贝数据CPU参与的工作较少,只是辅助作用,所以减少CPU拷贝意义更大。
现实中对零拷贝的概念有“广义”和“狭义”之分,广义上是指只要减少了数据拷贝的次数,就称之为零拷贝;狭义上是指真正的零拷贝,就是避免了内核缓冲区和用户空间内存之间的两次CPU拷贝,
零拷贝实现方式:
Linux实现零拷贝—— mmap内存映射
既然是内存映射,首先来了解解下虚拟内存和物理内存的映射关系,虚拟内存是操作系统为了方便操作而对物理内存做的抽象,他们之间是靠页表(Page Table)进行关联的,关系如下:
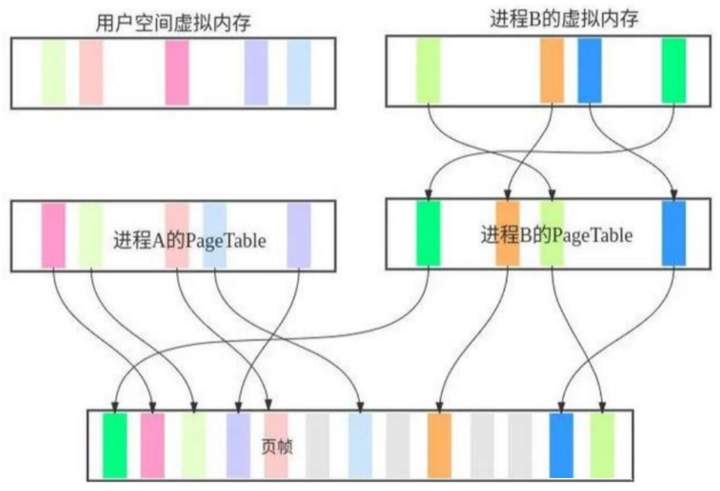
每个进程都有自己的PageTable,进程的虚拟内存地址通过PageTable对应于物理内存,内存分配具有惰性,它的过程一般是这样的:进程创建后新建与进程对应的PageTable,当进程需要内存时会通过PageTable寻找物理内存,如果没有找到对应的页帧就会发生缺页中断,从而创建PageTable与物理内存的对应关系。虚拟内存不仅可以对物理内存进行扩展,还可以更方便地灵活分配,并对编程提供更友好的操作。
内存映射(mmap)是指用户空间和内核空间的虚拟内存地址同时映射到同一块物理内存,用户态进程可以直接操作物理内存,避免用户空间和内核空间之间的数据拷贝。
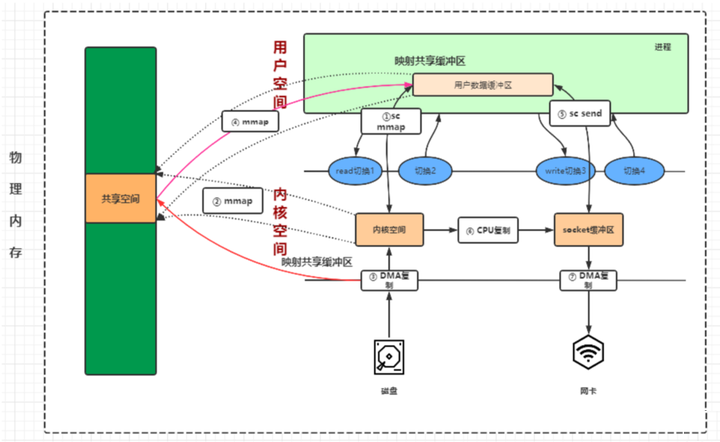
整个流程是这样的:
-
用户进程通过系统调用mmap函数进入内核态,发生第1次上下文切换,并建立内核缓冲区;
-
发生缺页中断,CPU通知DMA读取数据;
-
DMA拷贝数据到物理内存,并建立内核缓冲区和物理内存的映射关系;
-
建立用户空间的进程缓冲区和同一块物理内存的映射关系,由内核态转变为用户态,发生第2次上下文切换;
-
用户进程进行逻辑处理后,通过系统调用Socket send,用户态进入内核态,发生第3次上下文切换;
-
系统调用Send创建网络缓冲区,并拷贝内核读缓冲区数据;
-
DMA控制器将网络缓冲区的数据发送网卡,并返回,由内核态进入用户态,发生第4次上下文切换;
小结:
-
避免了内核空间和用户空间的2次CPU拷贝,但增加了1次内核空间的CPU拷贝,整体上相当于只减少了1次CPU拷贝;
-
针对大文件比较适合mmap,小文件则会造成较多的内存碎片,得不偿失;
-
不能很好的利用DMA方式,会比sendfile多消耗CPU,内存安全性控制复杂;
示例代码
#include <iostream>
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
void processMappedData(char* data, size_t size) {
// 处理映射的数据,这里简单打印前10个字符
std::cout << "Data in mmap: ";
for (size_t i = 0; i < std::min(size, static_cast<size_t>(10)); ++i) {
std::cout << data[i];
}
std::cout << std::endl;
}
int main() {
int fd = open("example.txt", O_RDONLY);
if (fd == -1) {
perror("Failed to open file");
return 1;
}
struct stat sb;
if (fstat(fd, &sb) == -1) {
perror("Failed to get file size");
close(fd);
return 1;
}
char* data = static_cast<char*>(mmap(NULL, sb.st_size, PROT_READ, MAP_PRIVATE, fd, 0));
if (data == MAP_FAILED) {
perror("Failed to mmap");
close(fd);
return 1;
}
// 使用零拷贝方式处理数据
processMappedData(data, sb.st_size);
// 解除映射并关闭文件
munmap(data, sb.st_size);
close(fd);
return 0;
}Linux实现零拷贝—— sendfile
sendfile是在Linux2.1引入的,它只需要2次上下文切换和1次内核CPU拷贝、2次DMA拷贝,函数定义如下:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);out_fd为文件描述符,in_fd为网络缓冲区描述符,offset偏移量(默认NULL),count文件大小。
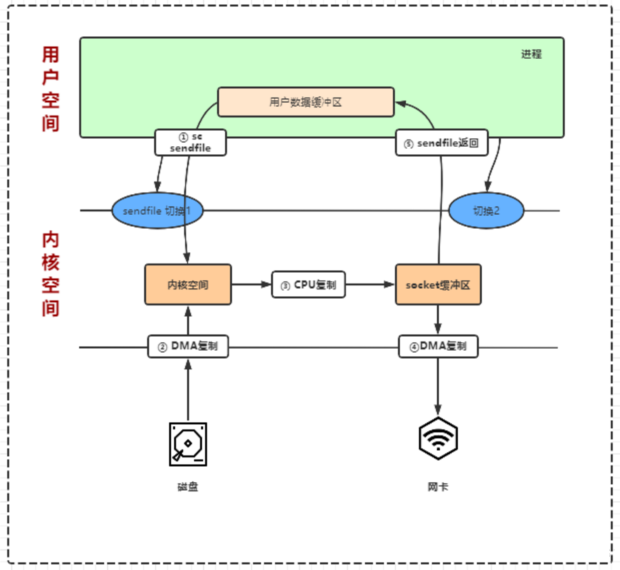
sendfile零拷贝的执行流程是这样的:
-
用户进程系统调用senfile,由用户态进入内核态,发生第1次上下文切换;
-
CPU通知DMA控制器把文件数据拷贝到内核缓冲区;
-
内核空间自动调用网络发送功能并拷贝数据到网络缓冲区;
-
CPU通知DMA控制器发送数据;
-
sendfile系统调用结束并返回,进程由内核态进入用户态,发生第2次上下文切换;
小结:
-
数据处理完全是由内核操作,减少了2次上下文切换,整个过程2次上下文切换、1次CPU拷贝,2次DMA拷贝;
-
优点上下文切换少,消耗 CPU 较少,大块文件传输效率高,无内存安全问题;
-
缺点是小块文件效率低亍 mmap 方式;
示例代码
#include <iostream>
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
void processMappedData(char* data, size_t size) {
// 处理映射的数据,这里简单打印前10个字符
std::cout << "Data in mmap: ";
for (size_t i = 0; i < std::min(size, static_cast<size_t>(10)); ++i) {
std::cout << data[i];
}
std::cout << std::endl;
}
int main() {
int fd = open("example.txt", O_RDONLY);
if (fd == -1) {
perror("Failed to open file");
return 1;
}
struct stat sb;
if (fstat(fd, &sb) == -1) {
perror("Failed to get file size");
close(fd);
return 1;
}
char* data = static_cast<char*>(mmap(NULL, sb.st_size, PROT_READ, MAP_PRIVATE, fd, 0));
if (data == MAP_FAILED) {
perror("Failed to mmap");
close(fd);
return 1;
}
// 使用零拷贝方式处理数据
processMappedData(data, sb.st_size);
// 解除映射并关闭文件
munmap(data, sb.st_size);
close(fd);
return 0;
}那么有没有什么办法彻底减少CPU拷贝次数,让数据不在内存缓冲区和网络缓冲区之间进行拷贝呢?答案就是sendfile + DMA gatter
Linux实现零拷贝—— sendfile + DMA gatter
Linux2.4对sendfile进行了优化,为DMA控制器引入了gather功能,就是在不拷贝数据到网络缓冲区,而是将待发送数据的内存地址和偏移量等描述信息存在网络缓冲区,DMA根据描述信息从内核的读缓冲区截取数据并发送。它的流程是如下:
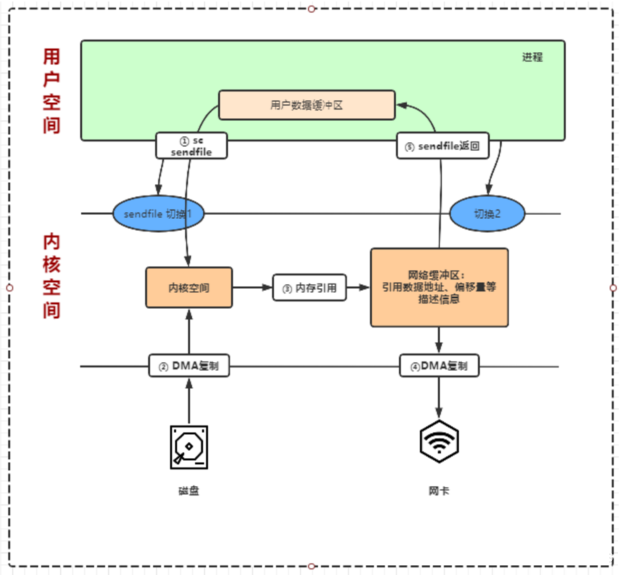
-
用户进程系统调用senfile,由用户态进入内核态,发生第1次上下文切换;
-
CPU通知DMA控制器把文件数据拷贝到内核缓冲区;
-
把内核缓冲区地址和sendfile的相关参数作为数据描述信息存在网络缓冲区中;
-
CPU通知DMA控制器,DMA根据网络缓冲区中的数据描述截取数据并发送;
-
sendfile系统调用结束并返回,进程由内核态进入用户态,发生第2次上下文切换;
小结:
-
需要硬件支持,如DMA;
-
整个过程2次上下文切换,0次CPU拷贝,2次DMA拷贝,实现真正意义上的零拷贝;
-
依然不能修改数据;
Linux实现的零拷贝—— splice
鉴于Sendfile的缺点,在Linux2.6.17中引入了Splice,它在读缓冲区和网络操作缓冲区之间建立管道避免CPU拷贝:先将文件读入到内核缓冲区,然后再与内核网络缓冲区建立管道。它的函数定义:
ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);它的执行流程如下
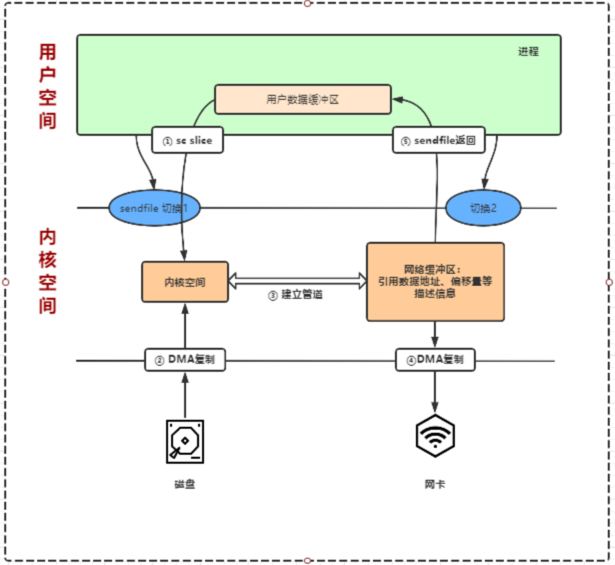
-
用户进程系统调用splice,由用户态进入内核态,发生第1次上下文切换;
-
CPU通知DMA控制器把文件数据拷贝到内核缓冲区;
-
建立内核缓冲区和网络缓冲区的管道;
-
CPU通知DMA控制器,DMA从管道读取数据并发送;
-
splice系统调用结束并返回,进程由内核态进入用户态,发生第2次上下文切换;
小结:
-
整个过程2次上下文切换,0次CPU拷贝,2次DMA拷贝,实现真正意义上的零拷贝;
-
依然不能修改数据;
-
fd_in和fd_out必须有一个是管道;
使用零拷贝技术的项目
事实上,Kafka 这个开源项目,就利用了「零拷贝」技术,从而大幅提升了 I/O 的吞吐率,这也是 Kafka 在处理海量数据为什么这么快的原因之一。
如果你追溯 Kafka 文件传输的代码,你会发现,最终它调用了 Java NIO 库里的 transferTo 方法:
@Override
public long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}如果 Linux 系统支持 sendfile() 系统调用,那么 transferTo() 实际上最后就会使用到 sendfile() 系统调用函数。
曾经有大佬专门写过程序测试过,在同样的硬件条件下,传统文件传输和零拷拷贝文件传输的性能差异,你可以看到下面这张测试数据图,使用了零拷贝能够缩短 65% 的时间,大幅度提升了机器传输数据的吞吐量。
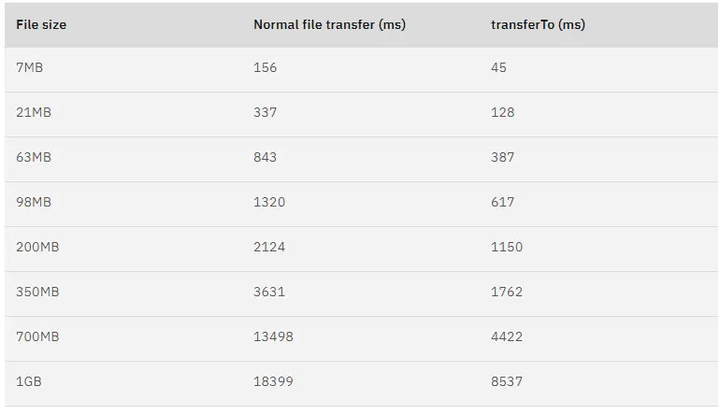
另外,Nginx 也支持零拷贝技术,一般默认是开启零拷贝技术,这样有利于提高文件传输的效率,是否开启零拷贝技术的配置如下:
http {
...
sendfile on
...
}sendfile 配置的具体意思:
-
设置为 on 表示,使用零拷贝技术来传输文件:sendfile ,这样只需要 2 次上下文切换,和 2 次数据拷贝。
-
设置为 off 表示,使用传统的文件传输技术:read + write,这时就需要 4 次上下文切换,和 4 次数据拷贝。
当然,要使用 sendfile,Linux 内核版本必须要 2.1 以上的版本。















 811
811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









