






注意Linux的路径分隔符是 / ,而Windows的路径分隔符是 \
现在我们来到了Linux的根目录,若要想回到开始的路径,只需如下操作:
解释 .(当前路径):
**.**的含义为我要执行当前路径下的某个程序,如下的操作:
4.ls -d
将目录象文件一样显示,而不是显示其下的文件。 如: ls –d 指定目录
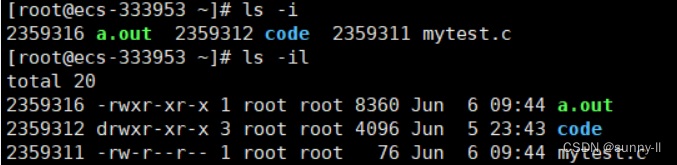
5.ls -i
ls -i表示输出文件的 i 节点的索引信息(inode)。类似的还有像 ls -il,具体何为索引,后续详谈。
补充:
**windows:**标识一个文件,文件名+后缀
**Linux:**一般文件名+后缀不是作为标识文件的主要方式,而是inode,具体是啥后续详谈。
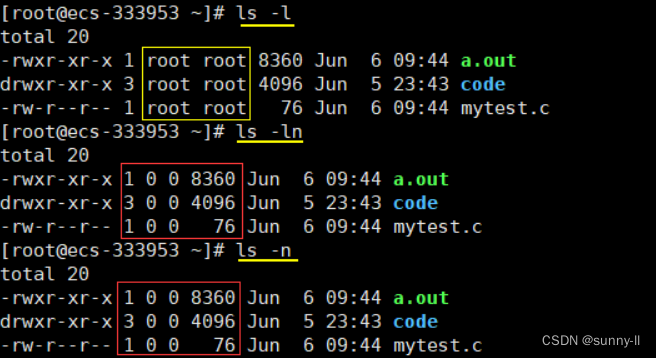
6.ls -n
ls -n 表示以数字的方式显示文件的相关信息。也可以使用ls -ln或ls -nl
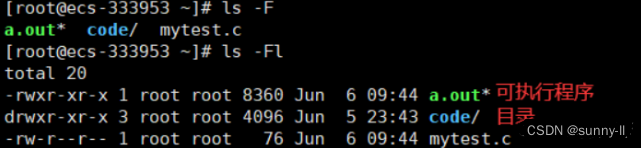
7.ls -F
ls -F表示在每个文件名后附上一个字符以说明该文件的类型, “*”表示可执行的普通文件; “/”表示目录; “@”表示符号链接; “|”表示FIFOs; “=”表示套接字(sockets)。(目录类型识别)。也可以用ls -Fl。
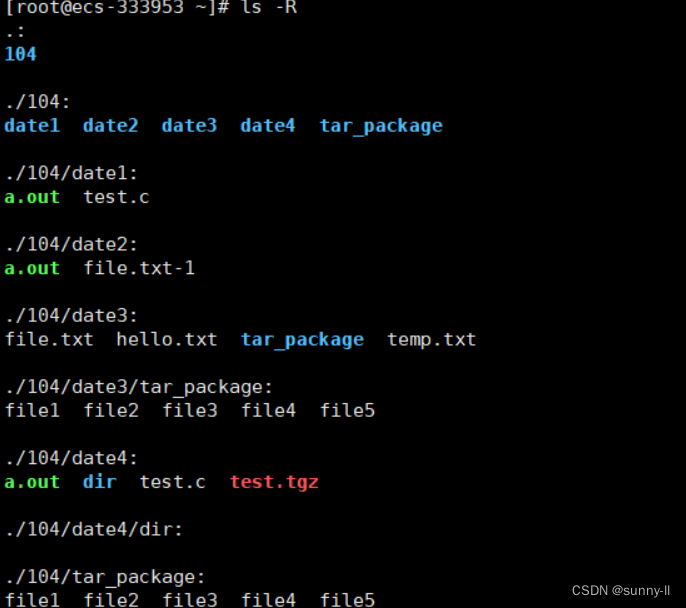
8.ls -R
ls -R是把当前目录下的文件递归式的给你展现出来
后续的选项就不再赘述了,可以下来试着敲一敲。


💦pwd指令
**语法:**pwd
**功能:**查看用户当前所处的路径。
示例:
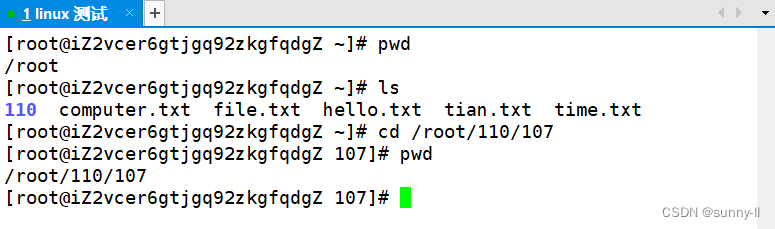
💦cd指令
**语法:**cd 目录名
**功能:**改变工作目录。将当前工作目录改变到指定的目录下。
举例:
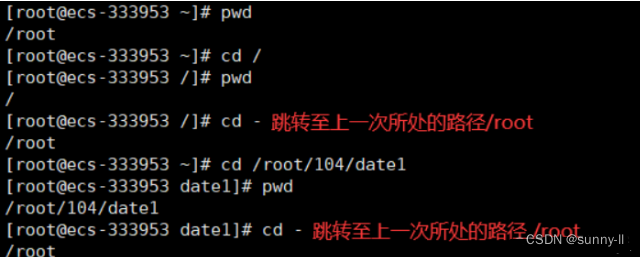
cd .. : 返回上级目录 cd /home/litao/linux/ : 绝对路径 cd ../day02/ : 相对路径 cd ~:进入用户家目录 cd -:返回当前所处路径的上一次所处的路径
- 一串路径的分隔符,Linux:/ windows:****
- **/**我们称之为根目录
首先,Linux的目录结构本质就是一颗多叉树。Linux系统中,磁盘上的文件和目录被组成一棵目录树,每个节点都是目录或文件。
我们一般“定位”某个文件,是通过路径定位的方式进行定位的,因为常规的路径定位方式具有唯一性。就比如说我要寻找根目录/下的test.c文件。可采用绝对路径和相对路径:
- 绝对路径:/home/shell/test.c
- 相对路径:假设从dev文件开始访问test.c文件。路径如下:…/home/shell/test.c
类比实际中Xshell的操作:
1.绝对路径:
2.相对路径:
**3.cd ~
cd ~**是进入用户家目录
**4.cd -
cd -**是跳转至上一次所处的路径
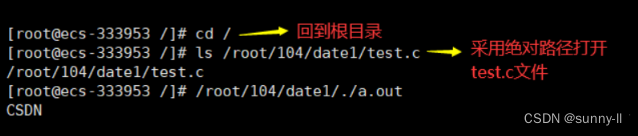
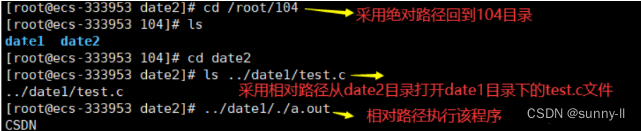

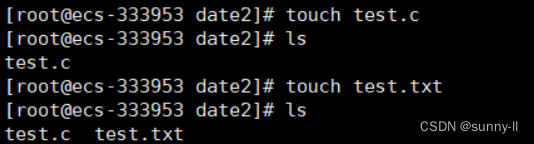
💦touch指令
**语法:**touch [选项]… 文件…
功能: touch命令参数可更改文档或目录的日期时间,包括存取时间和更改时间,或者新建一个不存在的文件。
常用选项:
- -a 或–time=atime或–time=access或–time=use只更改存取时间。
- -c 或–no-create 不建立任何文档。
- -d 使用指定的日期时间,而非现在的时间。
- -f 此参数将忽略不予处理,仅负责解决BSD版本touch指令的兼容性问题。
- -m 或–time=mtime或–time=modify 只更改变动时间。
- -r 把指定文档或目录的日期时间,统统设成和参考文档或目录的日期时间相同。
- -t 使用指定的日期时间,而非现在的时间
示例:
至于touch指令的其它选项,我们后续详谈。
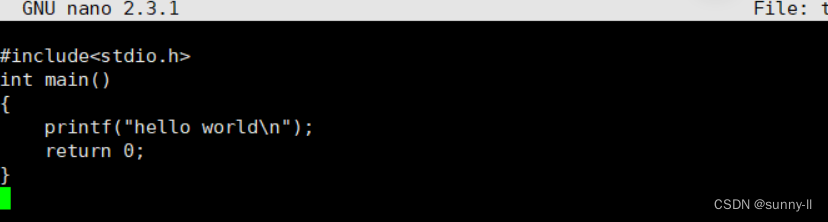
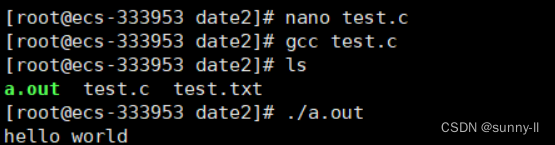
既然我们创建了文件,不如利用nano对test.c文件写一段"hello world"的代码。
随后ctrl+x,y,回车。最后按照如下指令操作即可:
如果你是root用户,且没有nano和gcc,那么需要输入如下指令进行配置。
//配置nano yum install -y nano //配置gcc yum install -y gcc-c++
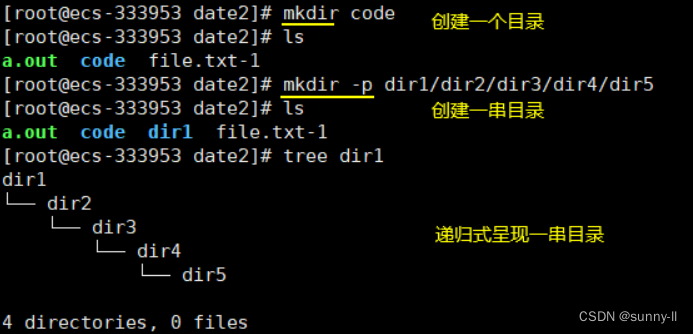
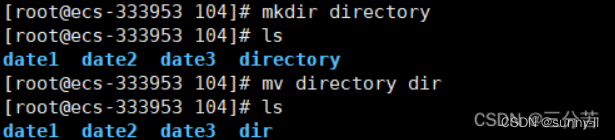
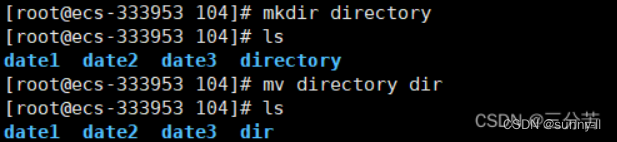
💦mkdir指令(重要)
语法: mkdir [选项] dirname…
**功能:**在当前目录下创建一个名为 “dirname”的目录
常用选项:
- -p, --parents 可以是一个路径名称。此时若路径中的某些目录尚不存在,加上此选项后,系统将自动建立好那些尚不存在的目录,即一次可以建立多个目录;
举例:
上述是创建单个目录,如果我想创建一长串目录就需要加上**-p**
tree命令是以树状形式显示指定的路径结构。
如果没有tree命令,那么只需要输入以下指令进行安装:
yum install -y tree

💦rmdir指令 && rm 指令(重要)
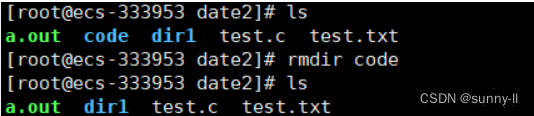
1、rmdir指令:
rmdir是一个与mkdir相对应的命令。 mkdir是建立目录,而rmdir是删除命令。
语法: rmdir [-p][dirName]
**适用对象:**具有当前目录操作权限的所有使用者
**功能:**删除空目录,非空目录删除不了
常用选项:
- -p 当子目录被删除后如果父目录也变成空目录的话,就连带父目录一起删除。
示例:
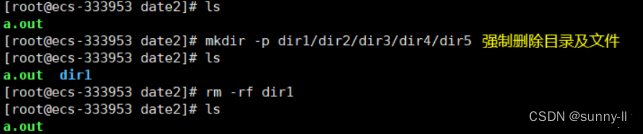
rmdir只能删除空目录,像刚刚连续创建的目录dir,就不能直接删除dir1,因为其递归里有dir
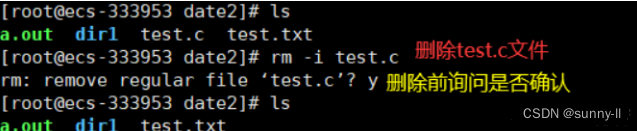
2、rm指令:
rm命令可以同时删除文件或目录
语法: rm [-f-i-r-v][dirName/dir]
**适用对象:**所有使用者
**功能:**删除文件或目录
常用选项:
- -f 即使文件属性为只读(即写保护),亦直接删除
- -i 删除前逐一询问确认
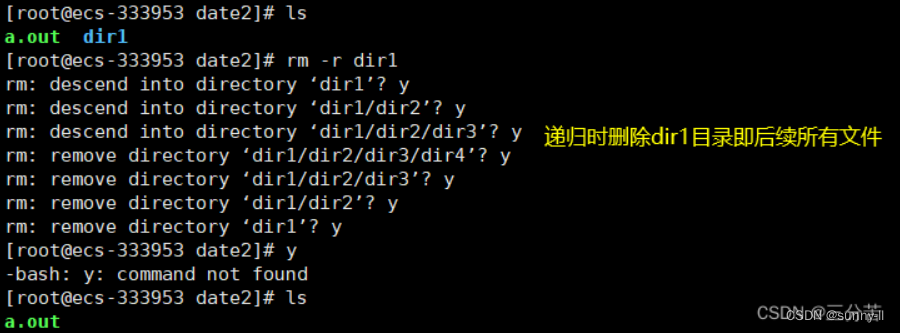
- -r 删除目录及其下所有文件
rm -i
rm -f
rm -r
rm -rf


💦man指令(重要)
Linux的命令有很多参数,我们不可能全记住,我们可以通过查看联机手册获取帮助。访问Linux手册页的命令是man
**语法:**man [选项] 命令
常用选项:
- -k 根据关键字搜索联机帮助
- num 只在第num章节找
- -a 将所有章节的都显示出来,比如 man printf 它缺省从第一章开始搜索,知道就停止,用a选项,当按下q退出,他会继续往后面搜索,直到所有章节都搜索完毕。
man手册分为8章
- 是普通的命令
- 是系统调用,如open,write之类的(通过这个,至少可以很方便的查到调用这个函数,需要加什么头文件)
- 是库函数,如printf,fread4是特殊文件,也就是/dev下的各种设备文件
- 是指文件的格式,比如passwd, 就会说明这个文件中各个字段的含义
- 是给游戏留的,由各个游戏自己定义
- 是附件还有一些变量,比如向environ这种全局变量在这里就有说明
- 是系统管理用的命令,这些命令只能由root使用,如ifconfig
示例:
如果你的云服务器上没有man手册,就需要自己手动安装,如下:
- root用户:yum install -y man-pages
- 普通用户:sudo yum install -y man-pages
💦cp指令(重要)
**语法:**cp [选项] 源文件或目录 目标文件或目录
功能: 复制文件或目录
**说明:**cp指令用于复制文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则它会把前面指定的所有文件或目录复制到此目录中。若同时指定多个文件或目录,而最后的目的地并非一个已存在的目录,则会出现错误信息
常用选项:
- f 或 --force 强行复制文件或目录, 不论目的文件或目录是否已经存在
- -i 或 --interactive 覆盖文件之前先询问用户
- -r递归处理,将指定目录下的文件与子目录一并处理。若源文件或目录的形态,不属于目录或符号链接,则一律视为普通文件处理
- -R 或 --recursive递归处理,将指定目录下的文件及子目录一并处理
示例:
- 当前路径下的拷贝:
cp的功能类似于windows中的复制粘贴
- 指定路径下的拷贝:
如果在cp的时候,要拷贝的文件,是拷贝在当前路径下,两个文件的名称不能一样,如果拷贝到不同路径下,可以一样。
- 拷贝目录:cp -r
- 强制拷贝:cp -f 或 cp -rf




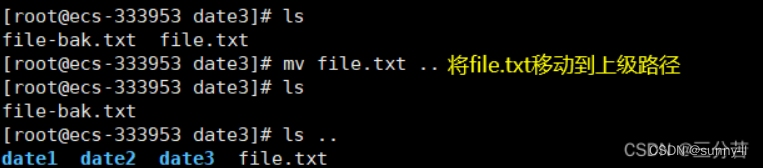
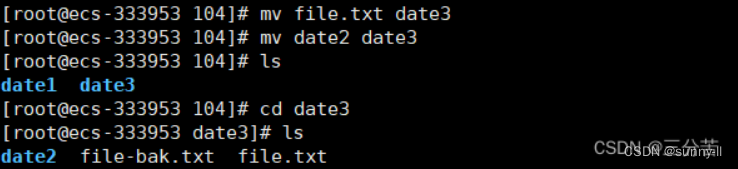
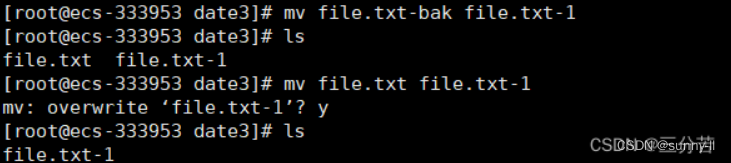
💦mv指令(重要)
mv命令是move的缩写,可以用来移动文件或者将文件改名(move (rename) files),是Linux系统下常用的命令,经常用来备份文件或者目录。
语法: mv [选项] 源文件或目录 目标文件或目录
功能:
- 视mv命令中第二个参数类型的不同(是目标文件还是目标目录), mv命令将文件重命名或将其移至一个新的目录中。
- 当第二个参数类型是文件时, mv命令完成文件重命名,此时,源文件只能有一个(也可以是源目录名),它将所给的源文件或目录重命名为给定的目标文件名。
- 当第二个参数是已存在的目录名称时,源文件或目录参数可以有多个, mv命令将各参数指定的源文件均移至目标目录中。
常用选项:
- -f : force 强制的意思,如果目标文件已经存在,不会询问而直接覆盖
- -i :若目标文件 (destination) 已经存在时,就会询问是否覆盖!
举例:
- mv剪切文件:
- mv剪切目录:
- mv重命名:
重命名文件
重命名目录:
- mv -i :若目标文件已经存在时,就会询问是否覆盖!
- mv -f : force 强制的意思,如果目标文件已经存在,不会询问而直接覆盖
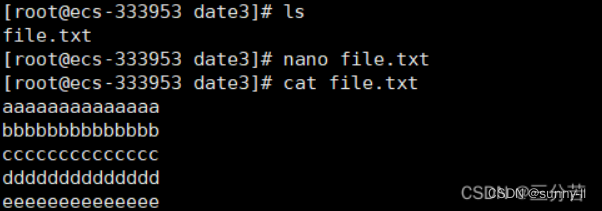
💦cat指令(重要)
语法:cat [选项][文件]
**功能:**查看目标文件的内容
常用选项:
- -b 对非空输出行编号
- -n 对输出的所有行编号
- -s 不输出多行空行
示例:
我们对nano对file.txt文件写入以下代码:
利用cat指令将其内容显示出来:
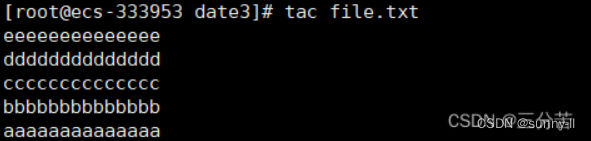
cat指令是正向输出,除此之外还有个tac指令逆向输出:
**注意:**cat指令适合于查看内容较少的文件,不适合查看大文本数据,因为会出现刷屏,要用到more指令。

💦more指令
**语法:**more [选项][文件]
**功能:**more命令,功能类似 cat
常用选项:
- -n 对输出的所有行编号
- q 退出more
准备工作:
按照如下的指令写段1万行文本:
cnt=1; while [ $cnt -le 100000 ]; do echo "hello bit $cnt"; let cnt++; done再将这段代码按如下指令写入到file.txt文件中:
示例:
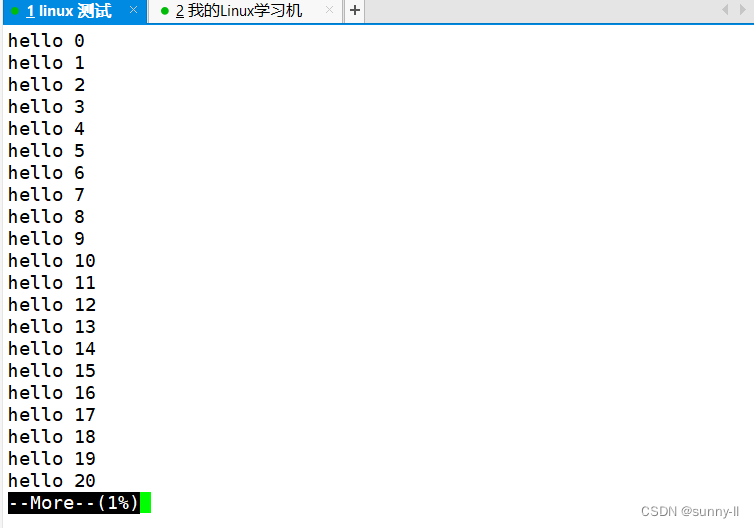
我可以手动输出想要跳转某行,more指令会帮助我们跳转到那行附近。more指令只能回车下翻数据,无法上翻数据。
💦less指令(重要)
- less 工具也是对文件或其它输出进行分页显示的工具,应该说是linux正统查看文件内容的工具,功能极其强大。
- less 的用法比起 more 更加的有弹性。在 more 的时候,我们并没有办法向前面翻, 只能往后面看
- 但若使用了 less 时,就可以使用 [pageup][pagedown] 等按键的功能来往前往后翻看文件,更容易用来查看一个文件的内容!
- 除此之外,在 less 里头可以拥有更多的搜索功能,不止可以向下搜,也可以向上搜。
**语法:**less [参数] 文件
功能:
less与more类似,但使用less可以随意浏览文件,而more仅能向前移动,却不能向后移动,而且less在查看之前不会加载整个文件。
选项:
- -i 忽略搜索时的大小写
- -N 显示每行的行号
- /字符串:向下搜索“字符串”的功能
- ?字符串:向上搜索“字符串”的功能
- n:重复前一个搜索(与 / 或 ? 有关)
- N:反向重复前一个搜索(与 / 或 ? 有关)
- q:quit
1. less也只能输出一整块屏幕
2. less支持利用键盘上下或J和K进行前后翻找
3. 推荐使用less
less可以帮助我们进行查看文本,可以用它进行日志查看,后续详谈。
- 补充1:
基本大部分计算机,要与人机交互,都要默认打开三个设备(文件)
- 标准输入,stdin,代码是0
- 标准输出,stdout,代码是1
- 标准错误输出,stderr,代码是2
标准输出和标准错误都是往显示器上打印。
- 补充2:输出重定向 >
把本来应该写入到显示器的内容写入到文件中。
输出重定向会清空原始文件的内容,进行重新写入:
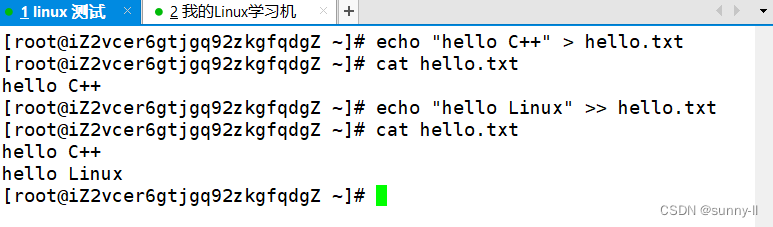
- 补充3:追加重定向 >>
使用>会清空原始内容,而>>就不会了,相反会在原始文件的结尾进行新增式的写入:
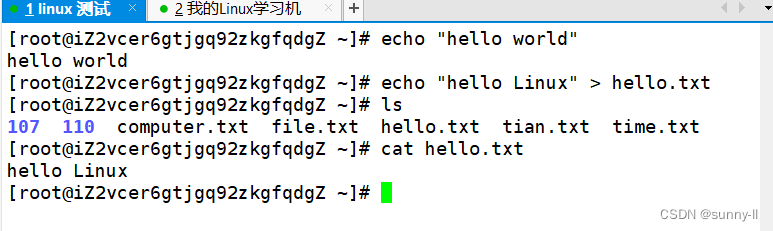
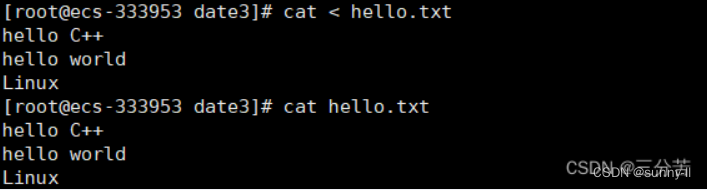
- 补充4:cat
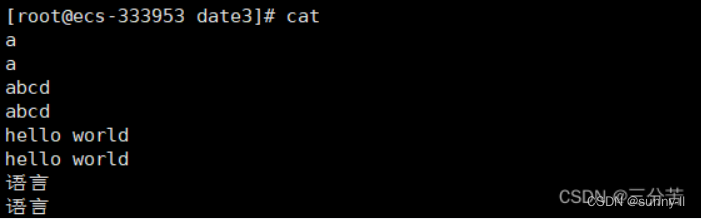
当cat指令后面不带任何东西时,默认从键盘(标准输入)进行读取:
想要推出次界面,按ctrl+c即可。 Linux下一切皆文件,键盘当作文件,所以可从键盘用cat读取数据,后续详谈。
- 补充5:输入重定向<
输入重定向,把本来应该从键盘文件中读取的数据的方式,改成从指定文件中读取。


💦head指令
head 与 tail 就像它的名字一样的浅显易懂,它是用来显示开头或结尾某个数量的文字区块, head 用来显示档案的开头至标准输出中,而 tail 想当然尔就是看档案的结尾。
语法: head [参数]… [文件]…
功能:
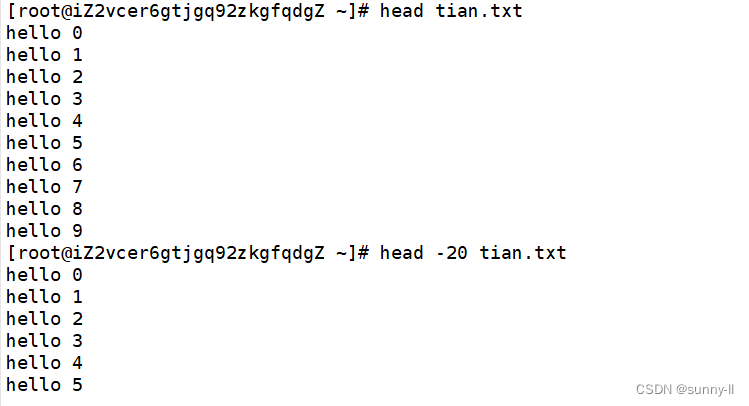
head 用来显示档案的开头至标准输出中,默认head命令打印其相应文件的开头10行。
选项:
-n<行数> 显示的行数
1. 默认head 指令打印文件的前10行
2. 加上 -n 指定输出文件前n行
💦tail指令 (查看日志常用)
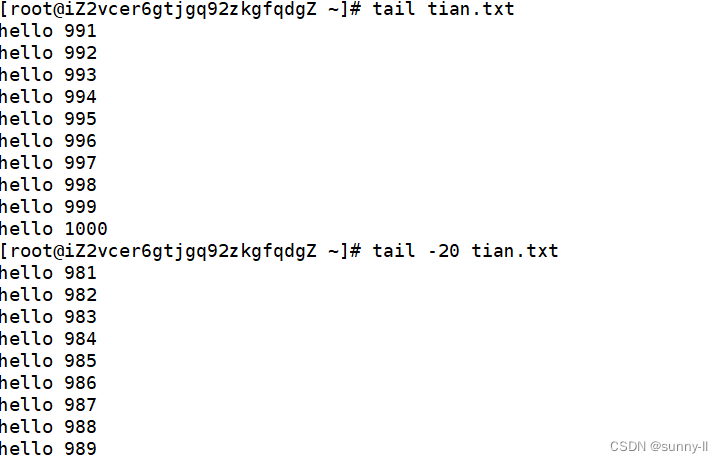
tail 命令从指定点开始将文件写到标准输出.使用tail命令的-f选项可以方便的查阅正在改变的日志文件,tail -f filename会把filename里最尾部的内容显示在屏幕上,并且不但刷新,使你看到最新的文件内容.
语法: tail[必要参数][选择参数][文件]
功能: 用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理。常用查看日志文件。
选项:
- f 循环读取
- -n<行数> 显示行数
示例:
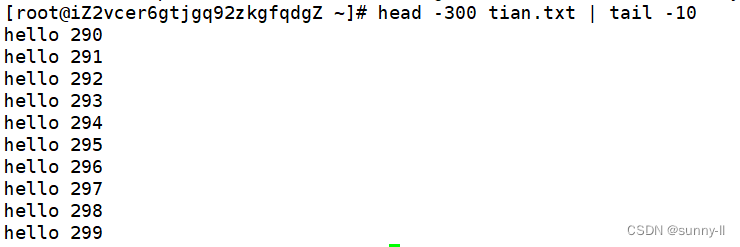
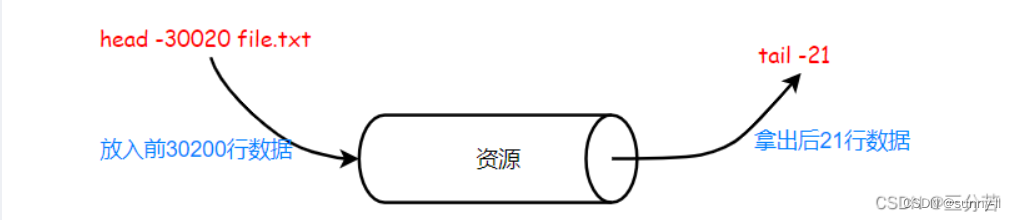
- 补充:如何拿到文本数据的第[ 30000, 30020]行?
管道法
直接使用指令:head -30020 file.txt | tail -21
该段指令的竖划线 | 即为管道。
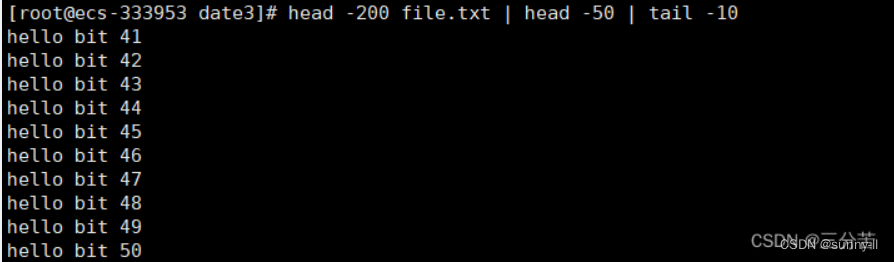
同样我们也可以级联多个命令,来完成流水线式的数据处理工作

💦date指令
date显示
date 指定格式显示时间: date +%Y:%m:%d
date 用法: date [OPTION]… [+FORMAT]
1、在显示方面,使用者可以设定欲显示的格式,格式设定为一个加号后接数个标记,其中常用的标记列表如下
- %H : 小时(00…23)
- %M : 分钟(00…59)
- %S : 秒(00…61)
- %X : 相当于 %H:%M:%S
- %d : 日 (01…31)
- %m : 月份 (01…12)
- %Y : 完整年份 (0000…9999)
- %F : 相当于 %Y-%m-%d
2、在设定时间方面
- date -s //设置当前时间,只有root权限才能设置,其他只能查看。
- date -s 20080523 //设置成20080523,这样会把具体时间设置成空00:00:00
- date -s 01:01:01 //设置具体时间,不会对日期做更改
- date -s “01:01:01 2008-05-23″ //这样可以设置全部时间
- date -s “01:01:01 20080523″ //这样可以设置全部时间
- date -s “2008-05-23 01:01:01″ //这样可以设置全部时间
- date -s “20080523 01:01:01″ //这样可以设置全部时间
3、时间戳
- 时间->时间戳: date +%s
- 时间戳->时间: date -d@1508749502
Unix时间戳(英文为Unix epoch, Unix time, POSIX time 或 Unix timestamp)是从1970年1月1日(UTC/GMT的午夜)开始所经过的秒数,不考虑闰秒。
示例:
- 时间->时间戳: date +%s
我们也可以通过自己的方式获取时间戳:
- 时间戳->时间: date -d@1508749502




💦cal指令
cal命令可以用来显示公历(阳历)日历。公历是现在国际通用的历法,又称格列历,通称阳历。 “阳历”又名“太阳历”,系以地球绕行太阳一周为一年,为西方各国所通用,故又名“西历”。
命令格式: cal [参数][月份][年份]
功能: 用于查看日历等时间信息,如只有一个参数,则表示年份(1-9999),如有两个参数,则表示月份和年份
常用选项:
- -3 :显示系统前一个月,当前月,下一个月的月历
- -j :显示在当年中的第几天(一年日期按天算,从1月1号算起,默认显示当前月在一年中的天数)
- -y:显示当前年份的日历
举例:


💦find指令
- Linux下find命令在目录结构中搜索文件,并执行指定的操作。
- Linux下find命令提供了相当多的查找条件,功能很强大。由于find具有强大的功能,所以它的选项也很多,其中大部分选项都值得我们花时间来了解一下。
- 即使系统中含有网络文件系统( NFS), find命令在该文件系统中同样有效,只你具有相应的权限。
- 在运行一个非常消耗资源的find命令时,很多人都倾向于把它放在后台执行,因为遍历一个大的文件系统可能会花费很长的时间(这里是指30G字节以上的文件系统)。
语法: find 路径 -name …
功能: 用于在文件树种查找文件,并作出相应的处理(可能访问磁盘)
常用选项:
- -name 按照文件名查找文件
示例:
比如查找C语言的头文件#include<stdio.h>:

💦grep指令(重点----查看日志)
语法: grep [选项] 搜寻字符串 文件
功能: 在文件中搜索字符串,将找到的行打印出来
常用选项:
- -i:忽略大小写的不同,所以大小写视为相同
- -n :顺便输出行号
- -v :反向选择,亦即显示出没有 ‘搜寻字符串’ 内容的那一行
示例:
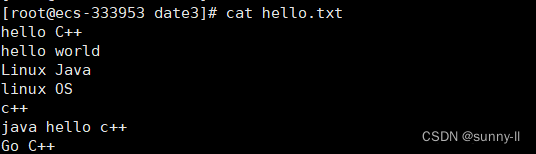
我们以次文本为例:
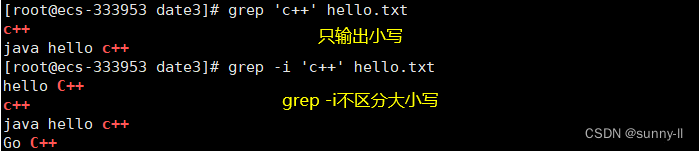
grep -i
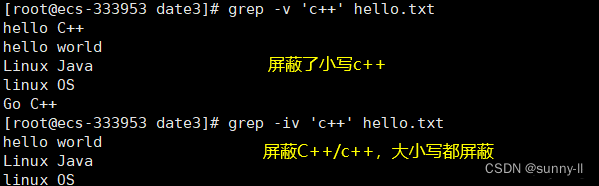
grep -v
grep -n

💦sort指令
**语法:**sort [选项] 对应排序的文件
**功能:**sort命令将文本文件内容加以排序,sort可针对文本文件的内容,以行为单位来排序
常用选项:
- -b 忽略每行前面开始出的空格字符。
- -c 检查文件是否已经按照顺序排序。
- -d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
- -f 排序时,将小写字母视为大写字母。
- -i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
- -m 将几个排序好的文件进行合并。
- -M 将前面3个字母依照月份的缩写进行排序。
- -n 依照数值的大小排序。
- -o<输出文件> 将排序后的结果存入指定的文件。
- -r 以相反的顺序来排序。
- -t<分隔字符> 指定排序时所用的栏位分隔字符。
- +<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
- –help 显示帮助。
- –version 显示版本信息
示例:
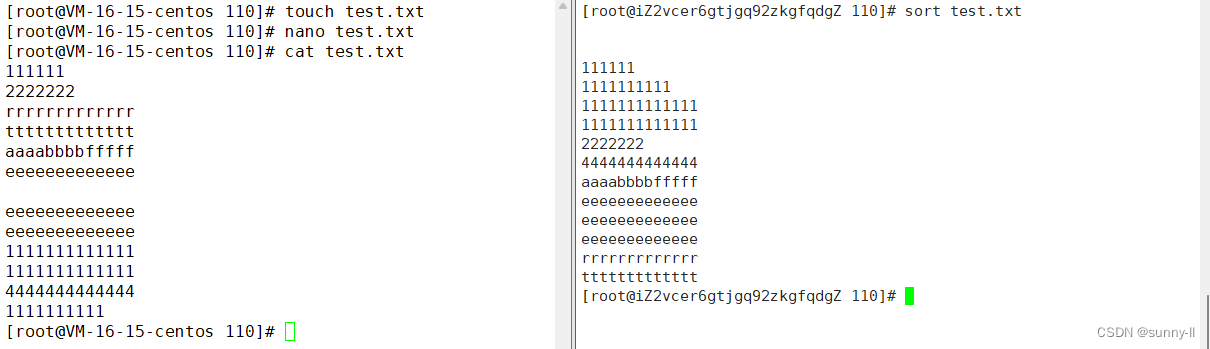
**sort 😗*sort将文件的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出,在这一点上和cat命令稍有区别
**sort -r :**反向输出
**sort -u 😗*sort的-u 选项它的作用很简单,就是在输出行中去除重复行,相比于uniq 的-u选项去重仅仅作用于相邻行,而sort -u去重的作用则是全局
**sort -n 😗*sort的-n选项依照数值的大小排序

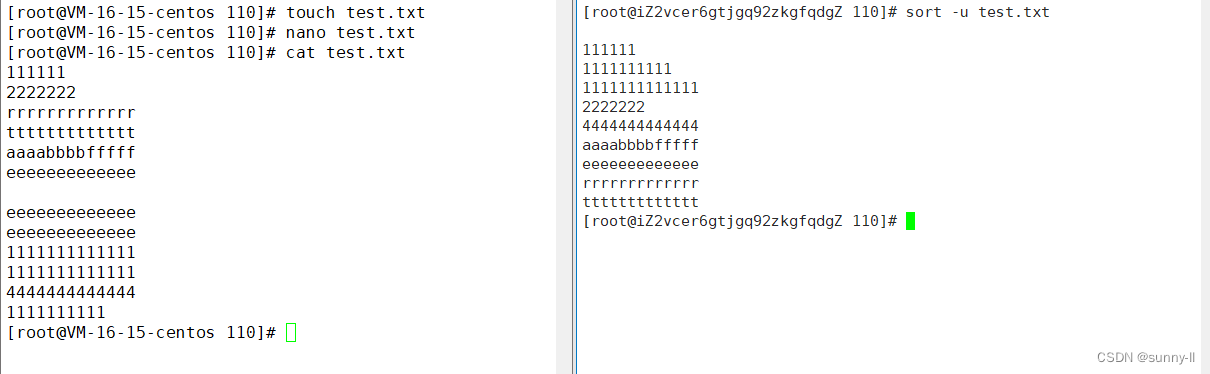
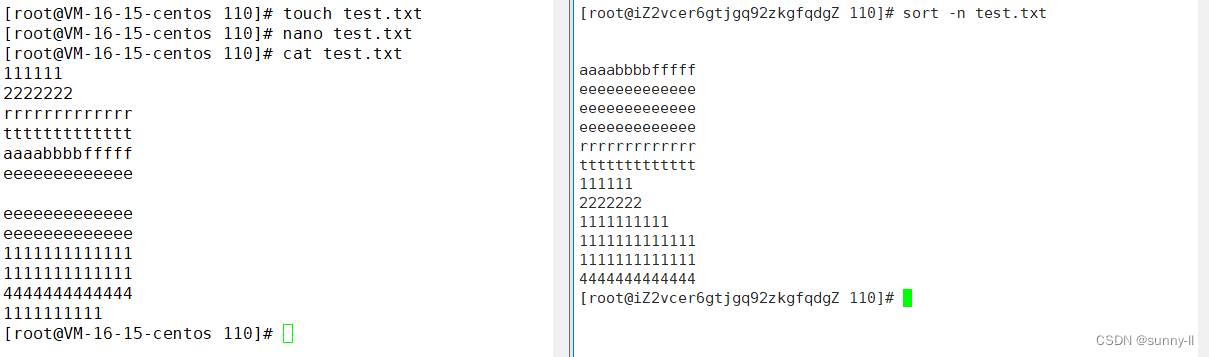
💦uniq指令
**语法:**uniq [选项] 对应处理的文件
**功能:**Linux uniq 命令用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用。uniq 可检查文本文件中重复出现的行列
常用参数:
- -u或–unique 仅显示出一次的行列。
- -c或–count 在每列旁边显示该行重复出现的次数。
- -d或–repeated 仅显示重复出现的行列。
- -f<栏位>或–skip-fields=<栏位> 忽略比较指定的栏位。
- -s<字符位置>或–skip-chars=<字符位置> 忽略比较指定的字符。
- -w<字符位置>或–check-chars=<字符位置> 指定要比较的字符。
- –help 显示帮助。
- –version 显示版本信息。
示例:
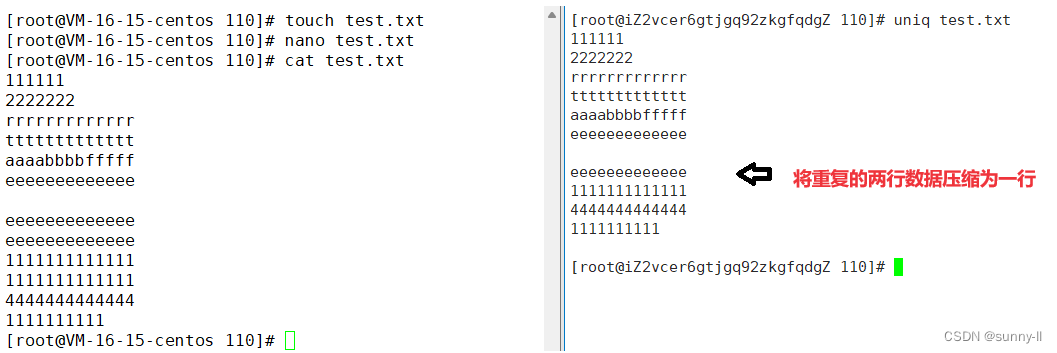
uniq :
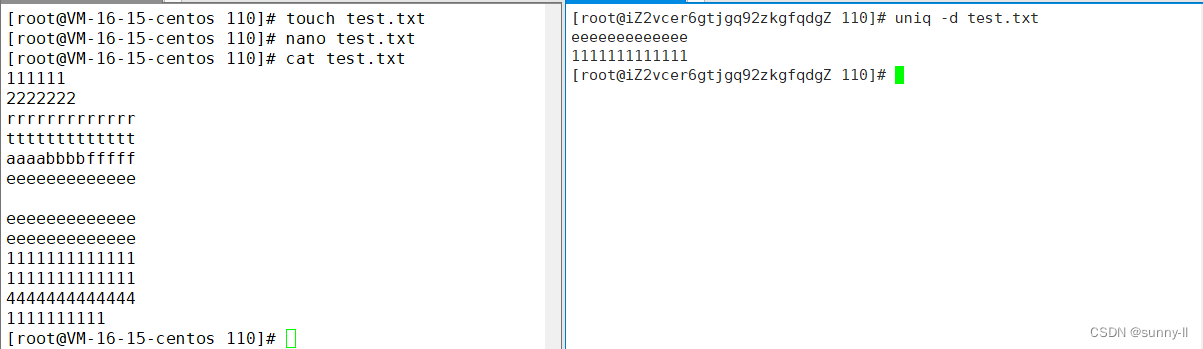
**uniq -d 😗*将文本数据中 相同的两行数据 ,提取一行出来(文本去重,不完全)
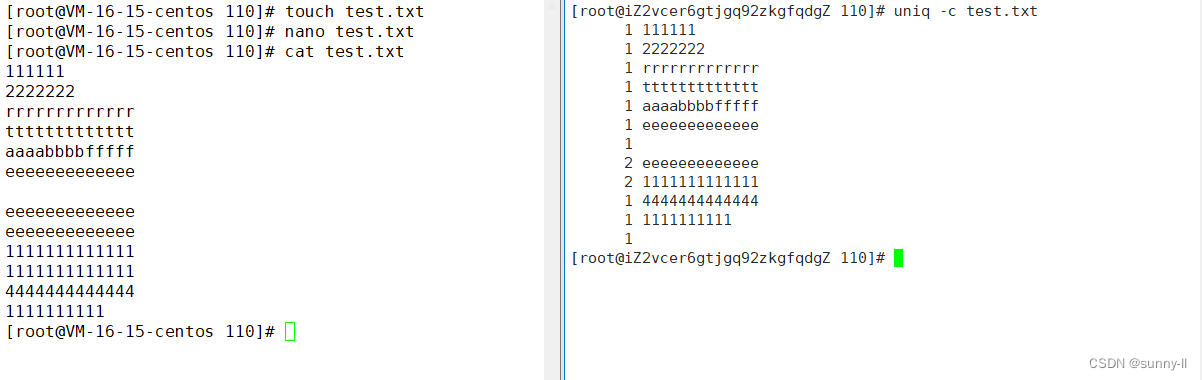
uniq -c : 显示每一行重复了几次
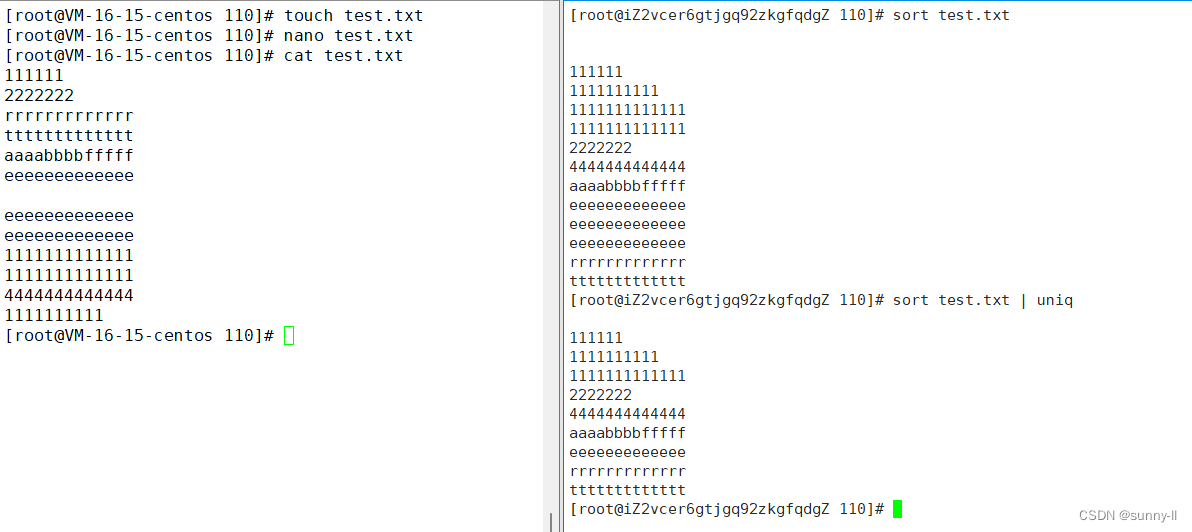
**sort 与 uniq 联动完全去重 :**sort test.txt | uniq
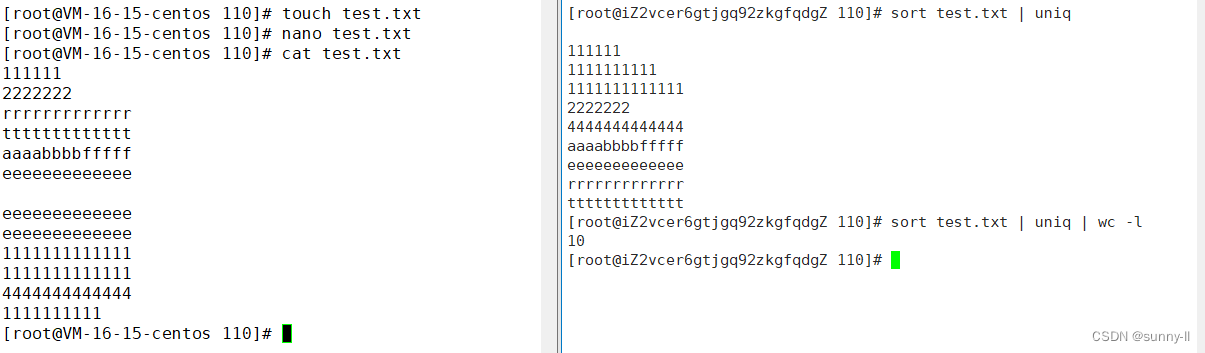
如果这个文件比较大,经过排序去重之后,我想知道,不重复的有多少行sort test.txt | uniq | wc -l
sort uniq grep 相互联动 :将文件中,包含 1 的行 过滤出来,进行行排序去重,还剩下几行
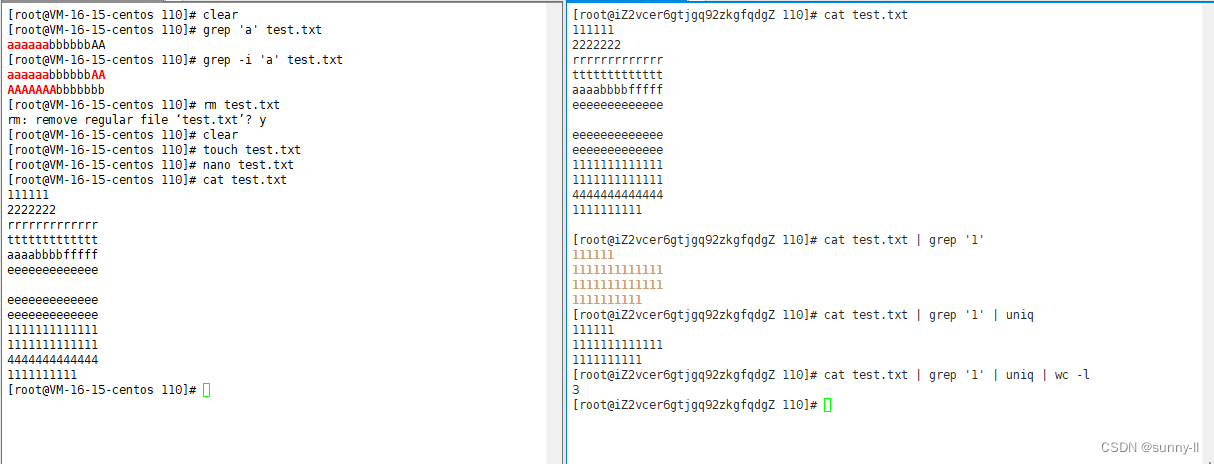















 3155
3155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









