







---
## 🍓🍓解析&&提取
import requests
import re
todo 列表拿来存储子页面,为后面提取每个子页面信息做准备
child_urls=[]
url = “地址”
resp = requests.get(url) # todo verify=False 去掉安全认证
resp.encoding = ‘gbk’
print(resp.text)
obj = re.compile(r’2022必看热片.*?
- (?P.*?)
obj2 = re.compile(r"<a href=’(?P.*?)‘",re.S)
obj3=re.compile(r’ title=“(?P
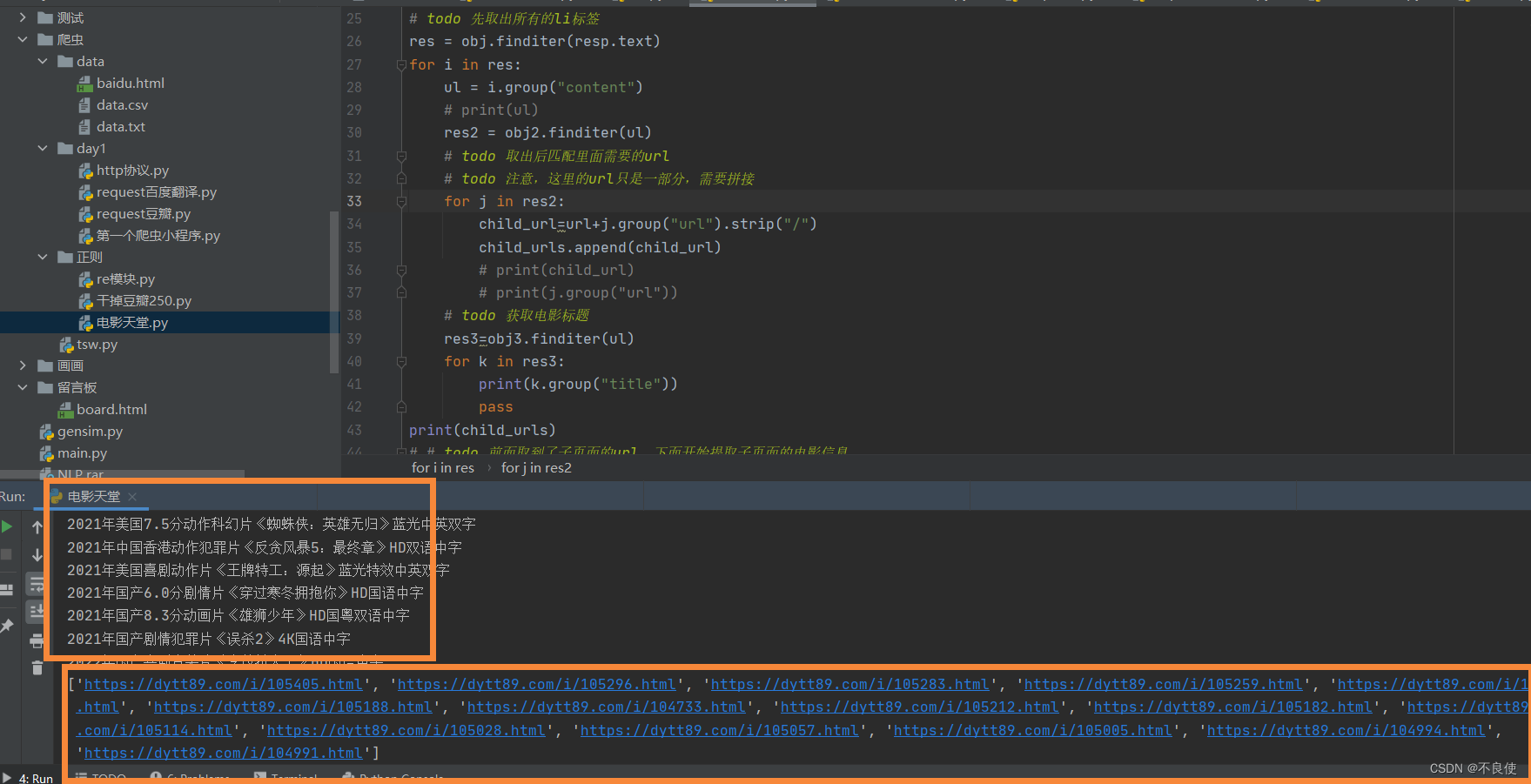
todo 先取出所有的li标签
res = obj.finditer(resp.text)
for i in res:
ul = i.group(“content”)
# print(ul)
res2 = obj2.finditer(ul)
# todo 取出后匹配里面需要的url
# todo 注意,这里的url只是一部分,需要拼接
for j in res2:
child_url=url+j.group(“url”).strip(“/”)
child_urls.append(child_url)
# print(child_url)
# print(j.group(“url”))
# todo 获取电影标题
res3=obj3.finditer(ul)
for k in res3:
print(k.group(“title”))
pass
print(child_urls)
---
## 🍓🍓挖掘
由于上面已经huoqu2022所有值得看电影的url,下面对每个url发起请求获得每个子页面的html,进行解析提取。
coding=utf-8
TODO 鸟欲高飞,必先展翅
TODO 向前的人 :Jhon
todo 定位2022必看片
todo 从2022必看片中拿到子页面链接地址
todo 请求子页面地址,拿到我们想要下载的地址
import requests
import re
todo 列表拿来存储子页面,为后面提取每个子页面信息做准备
child_urls=[]
url = “地址”
resp = requests.get(url) # todo verify=False 去掉安全认证
resp.encoding = ‘gbk’
print(resp.text)
obj = re.compile(r’2022必看热片.*?
- (?P.*?)
obj2 = re.compile(r"<a href=’(?P.*?)‘",re.S)
obj3=re.compile(r’ title=“(?P
todo 先取出所有的li标签
res = obj.finditer(resp.text)
for i in res:
ul = i.group(“content”)
# print(ul)
res2 = obj2.finditer(ul)
# todo 取出后匹配里面需要的url
# todo 注意,这里的url只是一部分,需要拼接
for j in res2:
child_url=url+j.group(“url”).strip(“/”)
child_urls.append(child_url)
# print(child_url)
# print(j.group(“url”))
# todo 获取电影标题
res3=obj3.finditer(ul)
for k in res3:
# print(k.group(“title”))
pass
print(child_urls)
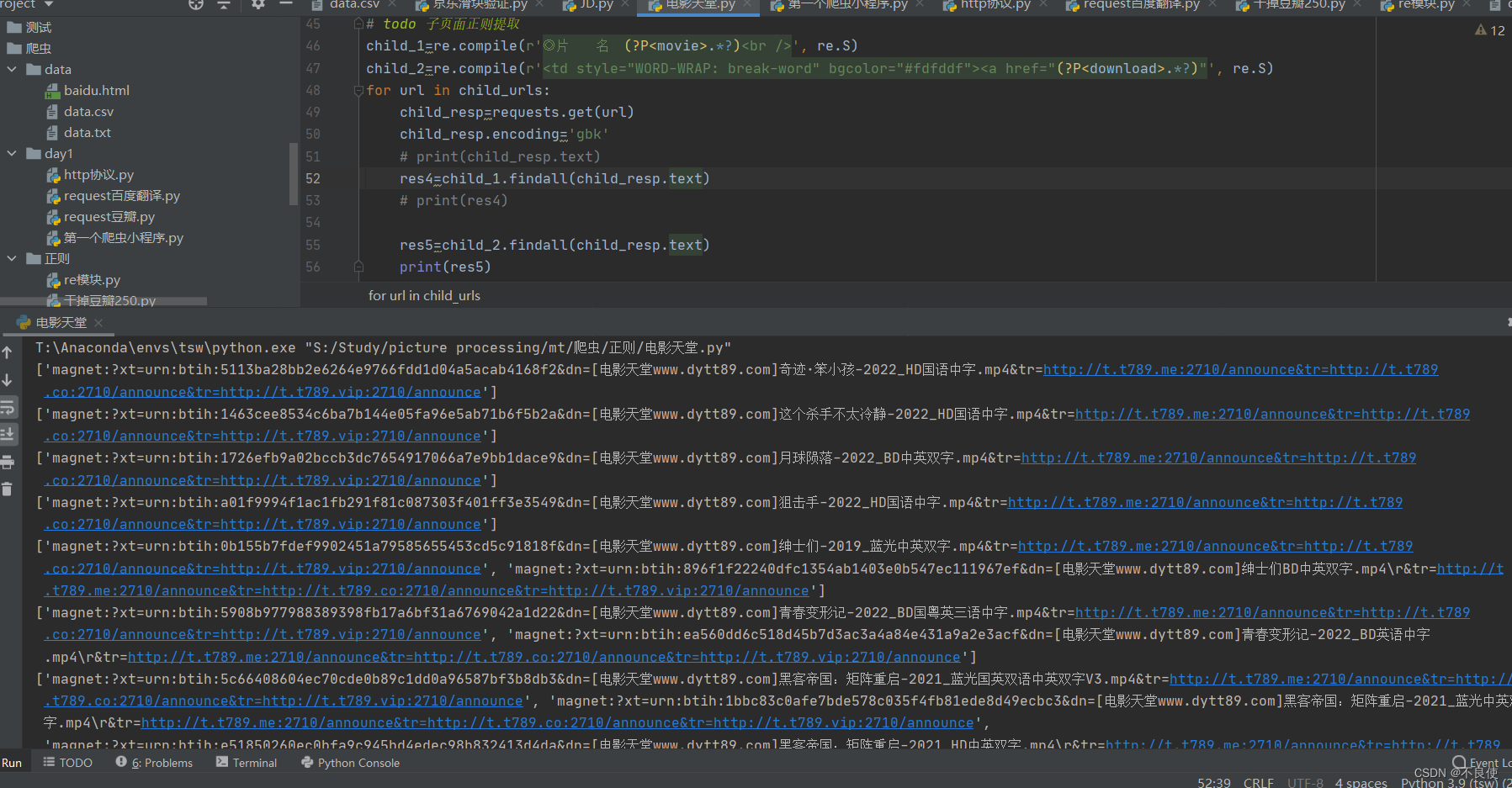
todo 前面取到了子页面的url,下面开始提取子页面的电影信息
todo 子页面正则提取
child_1=re.compile(r’◎片 名 (?P.*?)
‘, re.S)
child_2=re.compile(r’<a href=“(?P.*?)”', re.S)
for url in child_urls:
child_resp=requests.get(url)
child_resp.encoding=‘gbk’
# print(child_resp.text)
res4=child_1.findall(child_resp.text)
# print(res4)
res5=child_2.findall(child_resp.text)
print(res5)
**`流程:发起get请求-->定位-->解析-->获得定位的所有url-->对每个获得的url发起请求-->获得每部电影的html-->解析,提取需要的信息`**
[地址]( )
---
---
---
---
---
---
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
* * *
**(1)Python所有方向的学习路线(新版)**
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

**(2)Python学习视频**
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

**(3)100多个练手项目**
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

**(4)200多本电子书**
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
**(5)Python知识点汇总**
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

**(6)其他资料**
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

**这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。**
加入社区:https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









