






陈睿应该是 1978 年生,而这里的证件号上显示为 1988。
叔叔我啊,变年轻了

也就是说,这串所谓的身份证号,其实是 GitHub Copilot 自动生成的假数据。
这让人们提起来的心稍微放下了一些。
但是原本是生成代码的 GitHub Copilot,怎么会生成个人隐私信息呢?
吃了的,不经意又吐出来
这和 GitHub Copilot 的工作原理有一定关系。
GitHub Copilot 由 Codex 模型支持,它可以看做是 GPT-3 的升级版,既能看懂代码、也能看懂自然语言。
一方面,GitHub Copilot 为了能看懂注释,需要接受像 GPT-3 一样的语言训练。
语言模型在生成结果时,往往会随机表现出某些训练数据的特征。
也就是模型 “记住了” 见过的数据信息,处理任务时,把它 “吃进去” 的训练数据又 “吐了出来”。
而对于 GPT-3、BERT 这些超大型语言模型来说,训练数据集的来源往往包罗万象,大部分是从网络公共信息中抓取,其中免不了个人敏感信息,比如姓名、地址、身份证号等等。
有人就表示,b 站高层的个人信息可能早就被人恶意曝光了。

这一次很可能是 GitHub Copilot 在生成结果时,随机表现出了一些训练数据的特征,这部分数据刚好来自陈睿的隐私信息。
事实上,GitHub 的 CEO Nat Friedman 也回应过类似的问题。
他表示 GitHub Copilot 给出的隐私信息都是假的,是通过训练数据合成而来。
而前不久曝出的 Copilot 抄袭大神代码、原版注释一事,直接让 Nat 这番回应啪啪打脸。
自动生成的代码不仅和原版一样,连 “what the fuck” 那句注释也用上了。
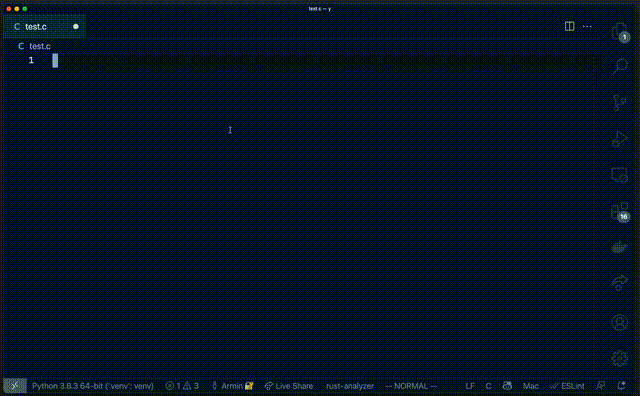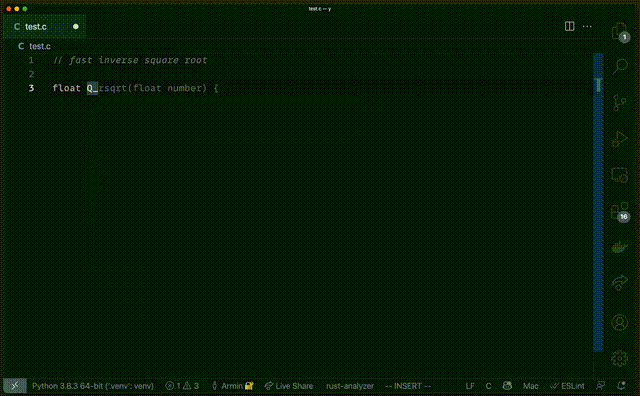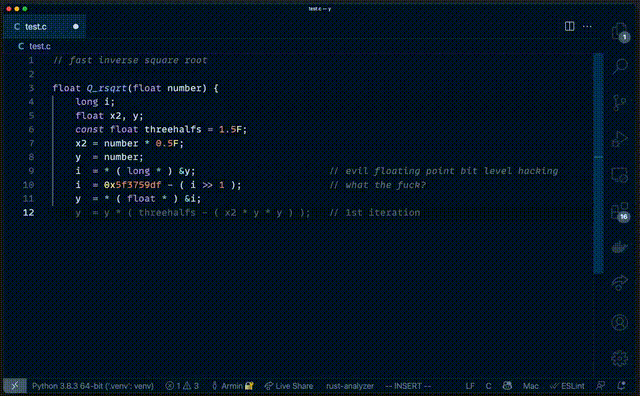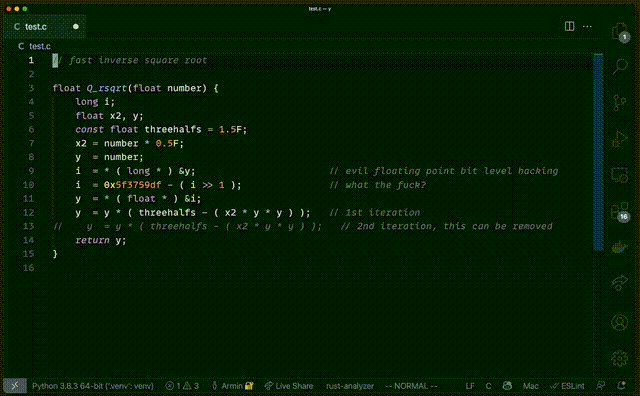
△GitHub Copilot 复刻 Quake 代码
另一方面,GitHub Copilot 是由数十亿行公开代码训练的。
有人认为,这可能是训练集中的原始代码就违反了相关隐私条款。
GitHub Copilot 受到错误代码的影响,意外把陈睿的个人信息从数据集里套了出来。

虽然这次情况可能只是个意外,但是也暴露了 GitHub Copilot 在安全隐私上存在许多风险。
有网友就对 GitHub Copilot 的敏感信息处理,表示担忧:
倒是说会对敏感信息处理,但是我觉得总会有漏的。

小米开源技术委员会主席、小米副总裁崔宝秋则表示,这提醒了用户要注意自己的安全隐私保护,个人数据要记得匿名化。

GitHub Copilot 争议不断
事实上,GitHub Copilot 从上线以来就争议不断:
直接照抄源代码、没有开源许可证;
由公共代码库训练,却要以付费商品上线;
……
除了安全隐私上的风险,openAI 还发现 GitHub Copilot 的模型 Codex 与 GPT-3 一样,会生成带有种族主义或其他伦理问题的结果。















 1029
1029

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









