






这个部分我们爬取的网站地址为:https://www.8lrc.com/search
尝试在这个页面进行搜索后我们很容易发现**,搜素框输入的结果直接作为get请求的参数,键为‘key’**

那么就很简单了,我们通过在界面搜索框的回车事件绑定爬虫函数,将搜索框中的内容作为参数传给函数,之后将参数拼接到https://www.8lrc.com/search后面并发送get请求即可得到响应体
随后使用BeautifulSoup中的html解析器对响应体文本进行解析
接下来通过f12查看页面元素
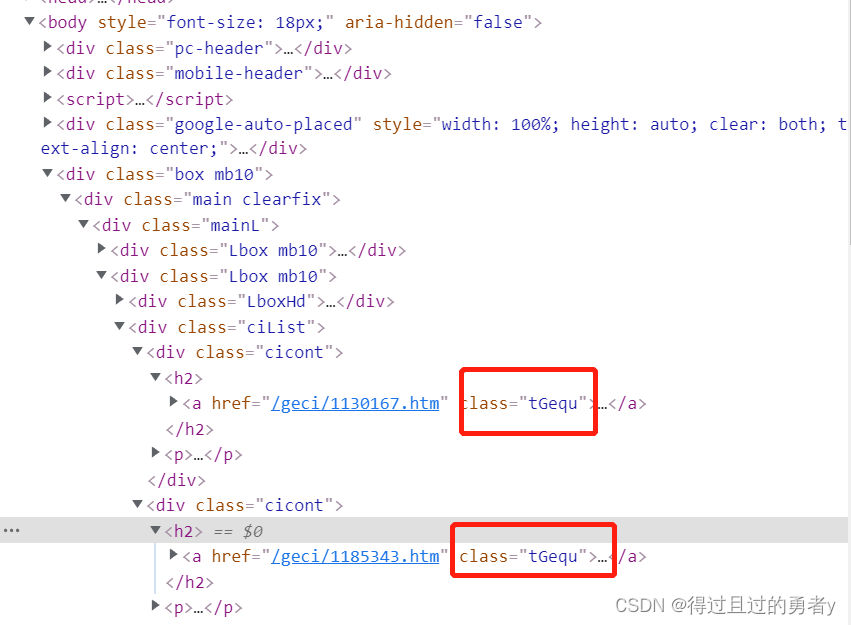
我们会发现,查询到的每首歌曲的跳转信息都在一个类名为”tGequ“的a标签里
那么我们就可以使用findAll函数获得所有歌曲的a标签
def search(self, keyword):
self.play_index_now = -1 # 每次重新搜索都将当前播放序号设置为-1
urlbase = r’https://www.8lrc.com/search’ # 搜索的基础地址
params = {‘key’: keyword} # 封装搜索的参数
res_body = requests.get(urlbase, params) # 拼接url,发送请求
soup_body = BeautifulSoup(res_body.text, ‘html.parser’) # html解析获得响应文本
self.tags = soup_body.findAll(class_=‘tGequ’) # 得到查询结果
通过tag[‘href’]即可得到其中的href属性值
由于这是一个相对地址,只要在前面加上baseurl:https://www.8lrc.com即可得到对应歌曲的链接
获取歌曲音频资源及歌词
接着我们访问具体歌曲如https://www.8lrc.com/geci/1130167.htm,希望获得其歌曲的资源以及歌词
同样打开开发者工具,可以发现在第四个script标签中的setPlayer函数里有一个url地址,且其以.mp3为后缀,结合这是一个播放器,我们不难想到这就是歌曲的音频资源,而下面的显然就是我们所需要的歌曲的歌词
知道了这些以后,就可以开始爬虫获取了
首先我们通过soup_body.select("body script")[3].get_text()语句获得这个script标签的文本
通过观察,url地址都是以”url“:"为起始,以引号"作为结束,所以我们不难写出匹配url地址的正则表达式:r'"url":"([^"]*)"'
括号中的内容即我们希望获得的mp3资源
通过re.search(pattern1, script).group(1)语句即可获得括号中的内容
由于获得的地址中会有转义字符/,所以我们需要用replace(r'\/', '/')将其置换为/

def get_song_detail(self, keyword): # 呈现搜索结果于界面
result = r’https://www.8lrc.com’ # 搜索结果的基础地址
pattern = r’(.) - (.)’ # 得到歌名的正则表达式
pattern1 = r’“url”:“([^”]*)"’ # 得到歌曲资源的正则表达式
self.keyword = keyword
self.names = []
self.musics = []
self.lyric = []
self.num = 0
for tag in self.tags[0:]:
if re.match(pattern, tag.text):
res_body = requests.get(result + tag[‘href’])
soup_body = BeautifulSoup(res_body.text, ‘html.parser’)
if soup_body.text.contains(“404”): continue
script = soup_body.select(“body script”)[3].get_text()
pre_music = re.search(pattern1, script).group(1)
self.names.append(re.split(pattern, tag.text)[1]) # 获取歌名
self.musics.append(pre_music.replace(r’/', ‘/’)) # 获取歌曲资源
self.num = self.num+1
self.song_show()
此处会有可能会出现一个问题,就是通过第一步获得的歌曲网址未必能打开,有的歌曲没有版权所以访问会出现404的情况,为了避免程序报错,我们需要跳过404的页面,所以有语句:if soup_body.text.__contains__("404"): continue
歌词方面同上都是先写出正则表达式,然后匹配得到结果,此处便不再演示,需要注意的是得到的歌词都带着\r\n字符,这显然不是我们所希望的,所以我们使用lyric.replace(r'\r\n', '\n')语句将这些字符转换为换行符,即可实现每句歌词占一行
这个部分我们爬取的网站地址为:http://m.yue365.com/bang/box100_w.shtml
步骤与上文无太大差别
值得一提的是该网站使用的编码是’gb2312’,而我们的编译器一般默认编码是utf-8,所以会出现乱码的情况
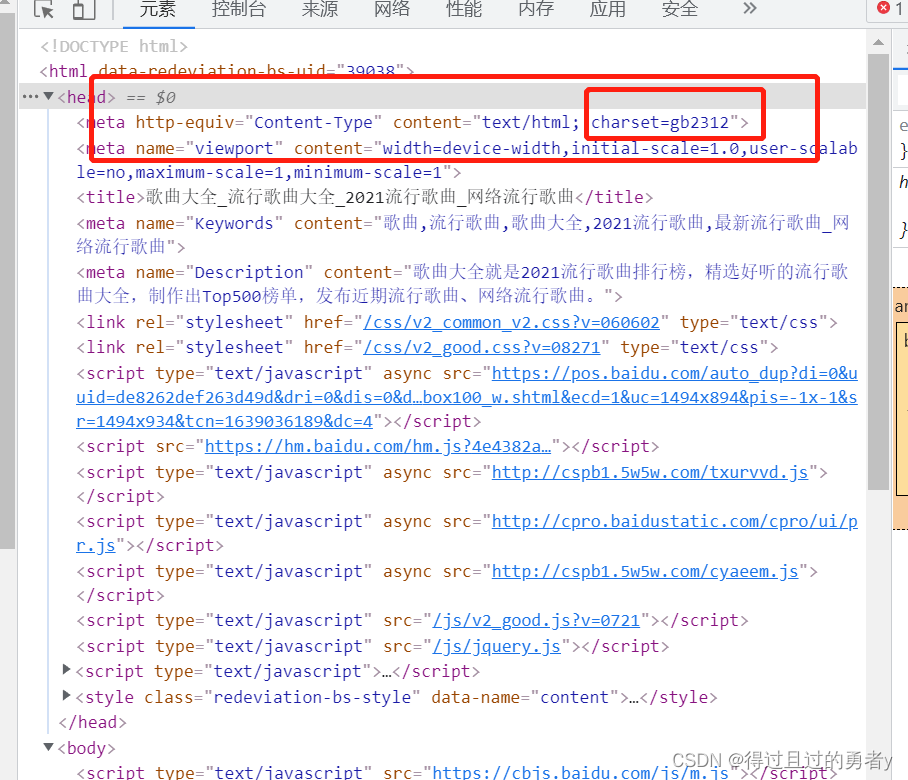
所以我们应该对获得的响应体设置编码
对于获取到的数据,我们采用excel存储
首先使用xlsxwriter.Workbook('popsongs.xlsx')创建一个名为popsongs的excel文件,可以再参数中设置格式,也可以利用add_format()创建格式
随后创建一个表单workbook.add_worksheet('pop500')命名为pop500,并使用 worksheet.set_column()设置列宽(第一个参数为起始列,第二个参数为终止列,第三个参数为长度,行数列数都从0开始)
之后就可以使用worksheet.write_row(row, 0, ['排名', '歌名', '歌曲url', '歌曲热度'], first_format)对每一行写入数据了,第一个参数为目标行,第二个参数为起始列,第三个参数为写入的值,从起始列开始写入列表中的值,第四个参数为之前所创建的格式
最后记得关闭excel文件,便大功告成了
def pop_songs(self):
row = 0
base = ‘http://m.yue365.com/’
url = ‘http://m.yue365.com/bang/box100_w.shtml’
pattern = r’width:(.*)%’
self.hot = []
res_body = requests.get(url)
res_body.encoding = ‘gb2312’
soup_body = BeautifulSoup(res_body.text, ‘lxml’)
songs = soup_body.findAll(class_=‘name’)
hot = soup_body.findAll(‘span’, class_=‘dib’)
workbook = xlsxwriter.Workbook(‘popsongs.xlsx’)
first_format = workbook.add_format({‘align’: ‘center’})
second_format = workbook.add_format({‘align’: ‘left’})
worksheet = workbook.add_worksheet(‘pop500’)















 5110
5110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









