






1. 引言
在自然语言处理(NLP)与人工智能(AI)的广袤星海中,大语言模型(Large Language Models, LLMs)宛如一颗璀璨的星辰,正悄然改变我们与语言和机器的互动方式。本章将引领您步入一段充满奇遇的探索之旅,探寻大语言模型的发展历程、独特之美及其在现实世界的绚丽应用。
1.1 语言模型的进化之路
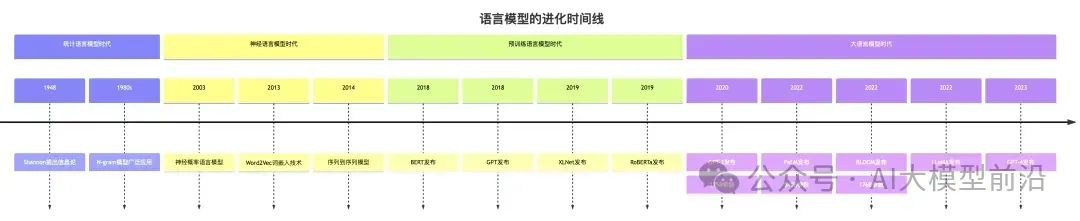
语言模型的演变恰似一部波澜壮阔的进化史。起初,我们迎来了统计语言模型(Statistical Language Models, SLMs)。想象一下,置身于一场刺激的猜词游戏,统计语言模型便如一位经验丰富的智者,依据先前的词汇线索,精准推测下一个可能的词汇。例如,在"我喜欢吃苹果"这句简单的话语中,若模型已窥见"我喜欢吃"的线索,它便能根据统计规律,精准地预测下一个词汇极可能是一种食物,如"苹果"。然而,这种方法虽直接,却难以捕捉到深层次的语义联系。
随后,神经语言模型(Neural Language Models, NLMs)崭露头角。如果说统计模型是棋艺高超的棋士,那么神经模型便是洞察棋局深意的智者。它不仅能记住浩如烟海的棋谱,更能理解每步棋背后的深邃策略。通过词的分布式表示(亦称为词嵌入),神经语言模型能够更加细腻地捕捉词与词之间的语义联系。如同理解"国王"与"王后"的关系,犹如"男人"与"女人"般微妙,它捕捉着词汇间那难以言喻的关联。
继而,预训练语言模型(Pre-trained Language Models, PLMs)登上历史舞台。这犹如让棋艺高深的智者在全球棋局中磨砺技艺,先于正式比赛积累经验。预训练模型首先在庞大的文本数据中淬炼,学习语言的普遍规律,随后针对特定任务进行微雕。这种方法极大提升了模型的泛化能力。例如,BERT(Bidirectional Encoder Representations from Transformers)模型在理解问题、应对各类NLP任务时,如同一位博古通今的语言大师,展现出卓越的才情。
终于,我们迎来了大语言模型(Large Language Models, LLMs)的辉煌时代。这些模型仿佛拥有超级大脑的AI实体,蕴含数十亿乃至数千亿的参数。其规模之大令人叹为观止,而更为惊艳的是其所展现的"涌现能力"——在训练时并未明确赋予的能力,却自然而然地涌现出来。例如,GPT-4不仅能流畅生成文本,更能理解和执行复杂的指令,甚至能涉足简单的编程领域。
1.2 大语言模型的独特魅力
大语言模型的独特魅力主要彰显在五个维度:
-
强大的上下文理解与生成能力
-
惊人的少样本学习能力
-
多模态融合的能力
-
卓越的推理与问题解决能力
-
持续学习与适应的潜力
大语言模型最为引人注目的特点之一,即其强大的上下文理解与生成能力。试想,当您沉浸于一部错综复杂的小说时,每个字、每个句子都与整个故事紧密相连。大语言模型便如一位超级读者,不仅能深刻理解眼前的文字,更能将其与前文内容紧密相连,甚至预测接下来可能发生的情节。这种能力使它们能够创作出连贯、逻辑严谨的长篇佳作,或在对话中保持上下文的一致性。
然而,大语言模型的魅力远不止于此。它们那惊人的少样本学习能力更是令人叹为观止。就如同教导一个孩子理解新概念时,往往需要反复解释、多次举例。但大语言模型却如一位天才学生,仅需寥寥数例,甚至一个简单的指令,便能迅速理解并完成新任务。这种能力被誉为"少样本学习"或"零样本学习",展示了其卓越的智能与潜力。另一个备受瞩目的特质在于大语言模型卓越的多模态融合能力。它们不再囿于纯文本的桎梏,而是能够洞察并生成包含图像、音频等多元形式的数据。譬如,GPT-4不仅精通文字,更能“透视”图片之秘,并据此展开对话或完成任务。这仿佛是一位无所不能的AI伴侣,在万千场景中皆能为我们排忧解难。
大语言模型更展现出了超凡的推理智慧。它们不仅能够迅速解答简单问题,更能在复杂的逻辑推理中游刃有余。若问及“若所有A均为B,所有B又皆为C,那么A是否也是C?”这类问题,大语言模型总能给出准确的答案,并详细解释其推理过程。这种能力预示着通往通用人工智能的光明前景。
同时,大语言模型也具备了持续学习和适应的潜力。尽管它们的基础知识源于预训练数据,但通过fine-tuning和few-shot learning的助力,这些模型能够迅速适应新的领域和任务。这种灵活应变的能力使它们能够在瞬息万变的环境中保持领先,持续保持其相关性和应用价值,不断拓展其应用边界。
1.3 大语言模型的实际应用
大语言模型的应用领域之广泛,堪称AI领域的“万能钥匙”。在日常生活中,你可能已经在不经意间感受到了它们所带来的便捷。例如,当你使用智能手机输入法时,那个能精准预测你下一个词的神奇功能,很可能就是由大语言模型所驱动的。
在工作场景中,大语言模型正成为我们的得力助手。假设你是一名程序员,面对一个棘手的难题束手无策时,你可以向基于大语言模型的AI编程助手倾诉需求,它不仅能为你编写代码,更能为你解析代码的运行原理,甚至指出潜在的错误。这宛如拥有一位全天候待命的编程导师。
在教育领域,大语言模型正在引领学习方式的革新。学生在学习物理遇到困难时,可以向AI助教请教,不仅能得到答案,还能获得深入浅出的解释和相关实例。AI助教更能根据学生的反馈灵活调整解释方式,提供个性化的学习体验。
在创意写作领域,大语言模型亦展现出了非凡的才华。它们能够根据简单的提示生成诗歌、故事,甚至是剧本。虽然这些生成的内容尚不能完全替代人类的创作,但它们已成为众多创作者灵感的源泉和创作的得力助手。
在商业世界中,大语言模型正在重塑客户服务的面貌。众多企业已经开始使用基于大语言模型的聊天机器人。这些AI助手能够准确理解客户的各种需求,提供及时的信息,甚至处理复杂的投诉。它们不知疲倦,全天候在线,极大地提升了客户服务的效率和质量。
下面是一个简单的Python代码示例,展示了如何利用Hugging Face的transformers库构建一个基于大语言模型的简易对话系统:
``从transformers库中导入预训练模型和分词器,让torch点燃模型的灵魂: ``from transformers import AutoModelForCausalLM, AutoTokenizer``import torch``# 加载那被誉为智慧之源的预训练模型和分词器``model_name = "gpt3" # GPT-3,以其深邃的智慧作为我们的示范``model = AutoModelForCausalLM.from_pretrained(model_name)``tokenizer = AutoTokenizer.from_pretrained(model_name)`` ``def chat_with_ai(prompt, max_length=50):` `# 将用户的言语转化为模型能够理解的代码` `input_ids = tokenizer.encode(prompt, return_tensors="pt")` `# 让模型产生智慧的火花,作为对用户的回应` `output = model.generate(input_ids, max_length=max_length, num_return_sequences=1,` `no_repeat_ngram_size=2, top_k=50, top_p=0.95, temperature=0.7)` `# 将模型的输出解码,还原为人类的语言` `response = tokenizer.decode(output[0], skip_special_tokens=True)` `return response`` ``# 让我们开始一场与智慧的对话``print("AI: 你好!我是你的AI助手,愿我能为你带去帮助与启迪。")``while True:` `user_input = input("你: ")` `if user_input.lower() in ["再见", "结束"]:` `print("AI: 再见!愿你的每一天都充满智慧与喜悦。")` `break` `ai_response = chat_with_ai(user_input)` `print("AI:", ai_response)
这段对话虽然简洁,但足以揭示大语言模型在日常交流中的非凡魅力。在更为复杂的系统中,我们还能融入上下文记忆、情感共鸣等功能,使得对话体验更加流畅自然。大语言模型,正以其惊人的能力,塑造着我们与技术交流的未来。它们不仅是语言处理的利器,更是推动AI向着更智能、更人性化的方向迈进的关键所在。
2. 大语言模型概览
在人工智能的璀璨星空中,大语言模型(LLMs)如同一颗颗耀眼的明星,凭借其庞大的参数、卓越的语言理解和生成能力,以及那神秘莫测的涌现能力,吸引着全球的目光。本章,我们将一起揭开大语言模型的神秘面纱,探索其核心特征、代表性模型,以及它们为自然语言处理领域所带来的革命性变革。
大语言模型的核心,在于其庞大的参数规模、卓越的语言理解和生成能力,以及那如魔法般的涌现能力。这些模型,不仅在传统的自然语言处理任务中展现出非凡的才华,更在解决复杂问题、进行逻辑推理等高级认知能力上,展现出惊人的潜力。在本章中,我们将聚焦三个重要的大语言模型家族:GPT、LLaMA和PaLM,同时,也会介绍其他一些具有划时代意义的模型。
2.1 GPT家族
GPT(Generative Pre-trained Transformer)系列模型,无疑是大语言模型领域的佼佼者。从2018年的GPT诞生,到如今的GPT-3、GPT-4等杰出代表,每一代GPT模型都以其卓越的性能和无限的潜力,为人工智能领域带来新的惊喜与突破。GPT-3,这位家族中的璀璨明星,其高达1750亿参数的规模,在AI界掀起了震撼的波澜。若将其参数量喻作书籍,它已翻阅了整个Wikipedia的内容无数遍。正是这一庞大无匹的知识库,赋予了GPT-3无所不能的魅力,从笔耕不辍的文章撰写,到精巧繁复的代码编写,再到解答深邃的哲学疑惑,它都能游刃有余。
有一则趣闻,曾有一位研究者令GPT-3化身为著名物理学家理查德·费曼,为我们揭示量子计算的奥秘。GPT-3不仅准确地描述了量子计算的基本概念,更以费曼那独有的幽默风格娓娓道来,仿佛费曼本人穿越时空,赋予了AI灵魂。这一能力,彰显了GPT-3不仅知识渊博,更能深刻理解和模拟复杂的人类个性。
GPT-4的登场,更是将大语言模型的能力推向了新的巅峰。它不仅在语言理解与生成上表现卓越,更展现出强大的多模态能力,能够洞悉图像背后的深意,并与图像内容进行深度对话或任务完成。例如,当您向GPT-4展示一张混乱房间的照片时,它不仅能精准描述房间的现状,更能为您提供整理的良策,甚至生成一份详尽的清洁规划。
2.2 LLaMA家族
LLaMA,作为Meta(原Facebook)推出的开源大语言模型系列,以其开源的特质赢得了研究人员和开发者的青睐,为整个领域的发展注入了源源不断的活力。LLaMA模型在训练过程中,融入了贝叶斯网络密度缩放和SwiGLU激活函数等创新技术,使得其在相对较小的参数规模下,便能展现出令人瞩目的性能。例如,LLaMA-13B(130亿参数)在某些任务上的表现,甚至能与GPT-3(1750亿参数)相媲美,这种“以小博大”的能力,确实令人叹为观止。
LLaMA的开源特性激发了社区的创造力,催生了一系列有趣的衍生模型。其中,Alpaca模型便是在LLaMA的基础上,经过指令微调得到的产物。它展现出了强大的指令跟随能力,只需用自然语言告诉Alpaca“为我的宠物猫设计一个自动喂食器”,它便能准确理解您的需求,并给出详尽的设计方案,包括材料清单、组装步骤,甚至可能的改进建议。
2.3 PaLM家族
PaLM,这一由Google推出的大语言模型系列,以其庞大的规模和出色的性能吸引了广泛关注。PaLM采用了Google独特的Pathways AI架构,使得模型能够更高效地利用计算资源,实现更大规模的训练。
PaLM-540B作为该家族中的佼佼者,拥有惊人的5400亿参数。在各种复杂任务中,它都展现出了卓越的性能,特别是在需要多步推理的问题上。当面对“如何用三种不同的方法证明勾股定理?”的提问时,PaLM不仅给出了三种不同的证明方法,还详细阐述了每种方法的原理和优缺点,彰显出其深厚的数学功底和灵活的思维能力。
PaLM家族在多语言任务上的表现同样令人瞩目。它在100多种语言的翻译任务中都表现出色,甚至能够翻译一些濒危语言。您可以使用PaLM来翻译古老的玛雅文献,或是帮助不同文化背景的人们进行无障碍交流,这种能力无疑为跨文化交流和语言保护开辟了新的天地。
2.4 其他大模型
除了上述三个主要的家族,还有许多其他重要的大语言模型值得我们关注。例如,BLOOM以其支持46种自然语言和13种编程语言的多语言能力脱颖而出;ERNIE 3.0则通过融合大规模知识图谱,大幅提升了模型的知识理解能力;而Claude系列模型则以其健壮的对话能力和对伦理的考量而备受赞誉。这些大语言模型的飞速发展不仅引领着自然语言处理技术的革新,更为人工智能的未来描绘了宏伟的蓝图。它们所展现出的深邃理解、精密推理和非凡创造力,使我们仿佛瞥见了通用人工智能的灿烂晨曦。然而,我们亦需清醒地认识到,这些卓越的模型仍有着自身的局限性,例如潜在的偏见和幻觉等问题。因此,在享受大语言模型带来的便捷之际,我们更应保持审慎,不断精进技术,确保这些强大的工具能够以负责且有益的方式为人类所用。
大语言模型,作为人工智能领域的璀璨新星,其能力和潜力令人叹为观止。随着科研的不断深入与应用的日益广泛,我们有理由相信,大语言模型将继续改写人类与技术交互的篇章,为各行各业带来颠覆性的变革。在接下来的篇章中,我们将更加细致地探讨这些模型的构建奥秘、应用策略以及未来的演进方向。
3. 大语言模型的构建方法
大语言模型的构建,是一项既复杂又精细的工程,它囊括了多个关键步骤与核心技术。从数据的处理到模型的训练,再到最终的优化与部署,每一个环节都对于模型的性能与效果具有举足轻重的意义。本章将深入解析大语言模型构建的每一个细节,涵盖数据清洗、分词技术、位置编码、模型预训练、微调技术、对齐方法以及解码策略等核心内容。
构建一个卓越的大语言模型,就如同精心雕琢一座雄伟的建筑。首先,我们需要优质的原材料,这便是数据清洗与准备的关键步骤。接着,我们需要巧妙地设计其结构,这涉及到分词技术与位置编码的精妙运用。然后,通过预训练这一“筑基”过程,赋予模型强大的语言理解能力。最后,通过微调与对齐等“精装”工艺,让模型更加精准地满足特定任务的需求。在此过程中,每一个步骤都不可或缺,且至关重要。
3.1 数据清洗
数据清洗,作为构建大语言模型的首要环节,是确保模型质量的基础。就如同我们希望为孩子提供最为优质、精准的学习材料,对于大语言模型而言,高质量的训练数据同样是其性能和可靠性的重要保障。
在数据清洗的过程中,去重是其中的关键环节。我们不愿让一个学生反复阅读同一段文字,同样,我们也不希望模型过度学习重复的数据。例如,在Falcon40B模型的训练中,研究人员对CommonCrawl数据进行了大规模的过滤与去重,从原始的数万亿个token中精心筛选出约5万亿个高质量的token。这一过程不仅提升了数据的质量,更使模型能够学习到更为丰富、多元的语言知识。
除了去重,处理异常值和不平衡数据也是数据清洗中的重要步骤。若我们的训练数据中90%都是关于体育的内容,那么模型在谈论科技或艺术时可能会显得力不从心。为了克服这一问题,研究人员运用了各种采样和权重调整技术,确保模型能够接触到均衡、多元的内容。
此外,文本预处理亦是数据清洗中不可或缺的一环。它包括了去除无关的HTML标签、统一标点符号、处理特殊字符等。例如,在处理网页抓取的数据时,我们需要移除广告文本、导航栏内容等无关信息,仅保留对模型学习有价值的主体内容。
3.2 分词技术
分词,是将文本转化为模型可理解的数字序列的关键步骤。若你想要学习一门新的语言,你首先需要知道这门语言的基本单位是什么——是字母、单词还是短语。对于大语言模型而言,分词便是这样一个界定基本单位的过程。
目前,主流的分词技术主要有三种:字节对编码(Byte Pair Encoding, BPE)、WordPiece和SentencePiece。为了更直观地理解BPE的工作原理,让我们以一段简单的文本为例:
Plain Text"The quick brown fox jumps over the lazy dog"
BPE算法巧妙地将句子拆解为独立字符,进而逐步融合最常出现的相邻字符对。比如,“Th"和"er"都可能被塑造为独立的token。这一过程循环进行,直至词汇库的大小达到预期设定。此法之所以卓越,在于其巧妙地平衡了词汇库的广度与未知词的解读能力。即使面对从未见过的词汇如"unfathomable”,它也能将其分解为"un"、"fathom"和"able"这样的片段,从而洞悉其大致意义。WordPiece和SentencePiece,作为BPE的精巧变种,虽在某些细节上各有千秋,但各具特色。例如,WordPiece在选取融合的子词时,会充分考量语言的构造特性;而SentencePiece则视所有输入为Unicode字符序列,使其在处理多语言文本时展现出卓越的适应力。
3.3 位置编码
在Transformer架构中,位置编码如同书籍的页码,为理解文本内容提供不可或缺的线索。最初的Transformer模型,通过正弦和余弦函数构建的绝对位置编码,展现出超凡的外推能力,使其能够应对训练中未曾出现的序列长度。然而,随着研究的深入,人们发现相对位置编码往往能带来更为出色的性能。以旋转位置编码(RoPE)为例,它已在GPT-3、LLaMA等主流大语言模型中崭露头角。RoPE的核心理念是将绝对位置信息巧妙地融入向量的旋转之中。具体来说,对于位于位置k的查询向量q和键向量k,RoPE会对它们实施特定的变换,以捕捉相对位置信息的同时,保留绝对位置信息,从而助力模型在长序列处理中更胜一筹。
3.4 模型预训练模型
预训练,如同让模型沉浸在浩如烟海的文本之中,汲取语言的精髓。预训练的主要目标是让模型自然而然地理解和生成语言,而非局限于某一特定任务。当前,主流的预训练方法主要有两种:掩码语言模型(MLM)和自回归语言模型(ALM)。BERT以MLM为基石,而GPT系列则倚仗ALM。让我们以ALM为例,深入剖析其运作机制。在ALM中,模型的任务是预测文本序列中的下一个词汇。例如,给定序列"The quick brown fox",模型需预测其后最可能出现的词汇。这一过程可以简化为一个概率的乘积形式,即每个词汇的出现概率都是基于其之前所有词汇的条件概率。这种预训练方式之所以有效,是因为它使得模型能够捕捉语言中的长距离依赖关系。例如,在预测"The scientist conducted the experiment and the results were …"的后续词汇时,模型需要全面理解整个句子的上下文,而不仅仅是眼前的几个词汇。近期,混合专家模型(MoE)在大语言模型预训练中的应用,开始引起研究者的广泛关注。MoE允许模型在不同任务或输入类型上激活不同的“专家”子网络,从而在提升模型容量的同时,保持较低的计算成本。
3.5 微调技术
微调,这一过程旨在使预训练模型能够针对特定任务发挥其独特价值。预训练宛如为模型铺设了广泛的语言知识基础,而微调则是其精细雕琢的技艺,教会模型如何巧妙地将这些知识应用于解决实际问题的场景中。传统微调的方式是在目标任务的庞大数据集上再次对整个模型进行锤炼,但随着模型体量的不断膨胀,这种方法逐渐显得力不从心。因此,参数高效微调方法(PEFT)应运而生,以其精妙的技巧解决了这一难题。Low-Rank Adaptation(LoRA)便是PEFT中备受瞩目的方法。LoRA的精髓在于,模型权重的更新常常可以用小巧的低秩矩阵来巧妙近似。具体而言,对于原始的权重矩阵W,LoRA巧妙地引入了A和B两个低秩矩阵:W’ = W + BA其中A∈R(r×d),B∈R(d×r),r远小于d。在微调的过程中,仅A和B会被精心调整,而原始的W则始终保持其原有的优雅形态。这种方法显著减少了参数更新的数量,使得即便在有限的计算资源下,也能让大型模型展现出其卓越的性能。举一个具体的例子,在医疗领域的项目中,研究人员可能会运用LoRA来微调GPT-3,使其能够精通医学术语的运用与理解。通过仅对一小部分参数进行微调,模型便能迅速融入新的专业领域,而无需对整个庞大的模型进行繁琐的重新训练。
3.6 对齐方法
模型对齐,这一过程确保了大语言模型的输出能够精准地契合人类的期望与价值观。它就像是一位经验丰富的导师,教导着虽智慧超群但缺乏社会经验的学生如何与人类世界和谐共处。其中,强化学习来源于人类反馈(RLHF)便是当前最为流行的对齐方法之一。RLHF的核心理念是利用人类的反馈作为指引,为模型指明方向。这一过程通常遵循以下步骤:
-
收集人类反馈:精心筛选出模型生成的多个回复,并对其进行细致的人工评分。
-
训练奖励模型:基于这些宝贵的人类评分,精心训练出一个奖励模型,为模型的每一个输出给予准确的评价。
-
使用强化学习优化语言模型:利用奖励模型的反馈,不断地对语言模型进行优化与调整,使其输出更加符合人类的期望。

最近,一些杰出的研究者崭露头角,提出了前沿的对齐方法,其中的直接偏好优化(Direct Preference Optimization, DPO)尤为引人注目。DPO方法巧妙绕过了奖励模型学习的繁琐步骤,直接从人类偏好中提炼出最优策略,为简化对齐过程和提高效率提供了新途径。
3.7 解码策略
解码策略如同决策者的指南针,引导着模型在概率分布的海洋中精准选择输出token。以国际象棋为喻,模型在众多可能的移动中抉择,寻求最佳的一步。
贪婪搜索,作为最简单的解码策略,总是倾向于选择概率最高的token,然而这种方法往往导致输出的单调和重复。因此,研究者们不断探寻更优的解码之道。
束搜索(Beam Search)策略在每一步保留k个最有可能的候选序列,为模型提供了更广阔的选择空间。尽管束搜索能产出相对高质量的输出,但偶尔也可能错失一些新奇而低概率的选择。
为了赋予输出更多的灵动性和多样性,研究者们提出了采样策略。Top-k采样在每一步随机选择概率最高的k个token之一,而Top-p采样(又称核采样)则选取累积概率达到p的token集合,两者皆在确保输出质量的同时,为文本注入了更多的变数。
温度参数T作为调控输出的另一利器,在softmax函数中扮演着重要角色。较高的温度让概率分布更加平缓,低概率事件亦能崭露头角;而较低的温度则使分布更加尖锐,模型更倾向于选择高概率的token。
在实际应用中,研究者们往往融合多种策略,以求达到最佳效果。比如,在创意写作助手中,我们或许会在故事开篇运用较高的温度和Top-p采样,激发灵感与创意,随后在故事发展中逐步降低温度,确保叙述的连贯与稳定。
构建大语言模型是一项多阶段、多维度的挑战。从数据清洗的严谨,到分词和位置编码的精细设计,再到预训练的庞大规模,每一步都需要深思熟虑和精心打磨。微调与对齐技术更是让模型能够更好地贴合特定任务,并与人类价值观相契合。最终,解码策略的选择成为了决定模型输出质量与多样性的关键因素。
随着研究的不断深入,我们见证了诸多创新方法和技术的涌现。数据处理方面,更复杂的清洗和过滤算法被不断开发;模型结构上,如Mixture of Experts等创新设计层出不穷;训练方法上,LoRA等参数高效微调技术大放异彩。这些进步不仅提升了模型的性能,也让大语言模型的训练和部署变得更为高效和便捷。
然而,构建大语言模型仍面临着诸多挑战。计算资源的巨大需求,对于许多研究机构和中小企业而言,是一道难以逾越的门槛。同时,随着模型规模的膨胀,获取高质量、多样化的训练数据愈发困难。更为紧迫的是,如何确保模型的输出符合伦理标准,避免产生有害或偏见的内容,是我们必须正视的问题。
展望未来,我们或将看到更加多元化的模型构建方法。联邦学习技术或许将解决数据隐私和多样性的问题,实现模型在不同数据源上的分布式训练。模型压缩和知识蒸馏技术的进一步发展,也将使大型模型的知识能够更加高效地转移到更小、更易部署的模型中。而在解码策略方面,我们或许将见证更加智能、context-aware的方法的诞生,让模型能够根据任务类型、用户偏好或已生成的内容动态调整其解码策略,从而输出更加灵活和适应性强的文本。最后,让我们深刻反思,随着大语言模型的日益强大与普及,其构建过程中的每一个决策都承载着对社会深远的影响。因此,在科技的浪潮中追求卓越时,我们更应审慎思考模型所带来的社会效应。这涉及到众多层面,诸如如何确保训练数据的广泛性与公正性,防止模型沦为虚假信息与有害内容的制造工具,以及如何使模型的决策过程变得透明而易于解读。
4. 大语言模型的驾驭与升华
大语言模型(LLMs)的崛起不仅激荡着自然语言处理领域的浪潮,更为无数应用场景铺设了崭新的道路。然而,要想真正挖掘这些模型的巨大潜力,我们不仅要懂得如何灵活运用它们,更要洞察如何进一步增强它们的能力。本章节将细致探讨大语言模型的使用之道、其内在的局限性,以及各式各样的增强策略,涵盖提示工程的奥妙、外部知识的融入、工具的运用,以及基于LLM的智能体构建等诸多方面。
驾驭大语言模型,就如同驾驭一匹驰骋千里的骏马。仅仅拥有一匹良驹是远远不够的,我们还需精通驾驭之术,洞悉其优势与不足,并为其配备精良的装备,以确保在各种情境下都能发挥最大的效能。同理,使用大语言模型,既需了解其本真之力,又需掌握提示工程的精髓,明了其局限所在,并通过各种增强手段来拓展其能力边界。
4.1 大语言模型的局限之地
尽管大语言模型展现出了非凡的才能,但它们亦有其固有的局限。认识这些局限,对于我们有效地运用与增强LLMs至关重要。
大语言模型往往缺乏持久的记忆与状态管理能力。就如同与一位极其聪明但患有严重短期记忆障碍的人对话,每当你提出新的问题,他便会忘记之前的对话内容。大语言模型亦是如此,它们无法自然地保留之前的对话历史。因此,在长时间的交互中,我们不得不手动管理对话的上下文,或依赖于外部存储系统来维持状态。
同时,大语言模型的输出带有一定的随机性与不确定性。即便在相同的输入下,模型也可能在不同的时刻给出不同的答案。这种特性在某些创造性的任务中或许能够带来惊喜,但在追求一致性与可重复性的场景中,却可能带来困扰。例如,在客户服务系统中,我们期望模型能够对同一个问题始终保持一致的回应。
此外,大语言模型还缺乏最新信息与实时数据的访问能力。它们的知识仅限于训练数据所覆盖的时间段,无法捕捉当下发生的事件或最新的信息。这就像一个博古通今但与世界隔绝的学者,虽然学识渊博,但可能已与时代脱节。
而最具挑战性的一点,莫过于大语言模型的“幻觉”现象。模型有时会生成看似合理但实则不准确的信息。这犹如一个擅长编故事的人,他的叙述虽然引人入胜,但可能完全是虚构的。例如,一个大语言模型可能会自信地描述一个不存在的历史事件,或为一个虚构的科学理论提供详尽的阐释。
4.2 提示工程:与大语言模型对话的智慧
提示工程(Prompt Engineering)是运用大语言模型的核心技艺。它如同与模型对话的艺术,通过精心设计的提示来引导模型生成我们所需的输出。
最基本的提示工程技巧在于明确与具体。例如,我们不应简单地提问“请告诉我关于气候变化的信息”,而应更具体地表述:“请用简单的语言解释气候变化的三个主要原因,并为每个原因提供一个实际的例子。”这样的提示更易于让模型产生结构清晰、内容丰富的回答。
链式思考(Chain-of-Thought)则是更为高级的提示技巧。它通过引导模型逐步思考问题,从而提高其在复杂任务中的解决能力。想象一下你正在教导一个孩子解决一个棘手的数学问题,你会一步步地引导他思考。同样地,我们也可以这样提示模型:“让我们一步步地来解决这个问题。首先,我们需要明确问题的要求;接着,我们列出已知的信息;然后……”自我一致性(Self-Consistency)堪称一种卓越的技术策略。它促使模型生成多元化的解决方案,并从中筛选出最为一致或普遍认可的答案。这正如在重大决策前咨询多位权威专家,再综合他们的智慧结晶。举例来说,在面对错综复杂的推理难题时,我们可以向模型反复咨询,通过对比不同的回应,选出最为合理或出现频次最高的那一个。
而反思(Reflection)技术,则是激发模型对其输出进行自我审视与修正的催化剂。它如同一位学生在完成作业后,被要求回头检查并修正自己的错误。我们可以这样引导模型:“请再次审视你刚才的回应,深思熟虑是否有逻辑上的疏漏或遗漏的关键信息。若有,请明确指出并予以修正。”
4.3 知识增强:为大语言模型注入外界智慧的滋养
即便大语言模型内置了浩如烟海的知识,也难以穷尽所有领域的最新动态。因此,我们需要为其增添知识的羽翼。检索增强生成(Retrieval-Augmented Generation, RAG)便是一种行之有效的策略。
RAG如同为模型配备了一位智能图书馆管理员。当模型遭遇不确定的疑问时,它可以向这位管理员求助,获取相关的知识宝藏。具体而言,RAG首先从用户的查询中提取关键信息,随后在外部知识库(如搜索引擎、知识图谱等)中检索相关信息。这些检索到的信息随后被巧妙地融入原始提示中,为模型提供更为丰富的上下文背景。
比如,假设用户问:“2023年诺贝尔物理学奖的获得者是哪些学者?”一个传统的大语言模型或许难以回应这个问题,因为其训练数据可能未能涵盖如此新鲜的信息。但通过RAG,系统能够迅速检索到正确的答案,并将其作为背景信息提供给模型:“2023年诺贝尔物理学奖授予了Pierre Agostini、Ferenc Krausz和Anne L’Huillier,以表彰他们在研究原子内电子运动方面的杰出贡献。”有了这一信息,模型便能生成准确无误的回应。
4.4 工具整合:扩展大语言模型的边界领域
为大语言模型赋予使用外部工具的能力,就如同为一位聪明的助手配备了一套“瑞士军刀”。这一举措极大地拓宽了模型能够胜任的任务范畴。
例如,我们可以为模型开通计算器的权限。当面对复杂的数学运算时,模型无需依赖自身可能存在的“心算”误差,而是可以直接调用计算器API以获取精确的结果。设想一下,当用户提问:“如果地球到月球的平均距离是384,400公里,光速是299,792,458米/秒,那么光从地球传到月球需要多少时间?”模型能够迅速识别出这是一个需要精确计算的问题,并调用计算器API,随后用自然语言将结果呈现给用户:“经过计算,光从地球传到月球大约需要1.28秒。”
另一个示例是让模型能够接入实时信息源。当被问及当前的天气状况时,模型可以调用天气API以获取最新的天气数据,并基于这些数据生成回应。这不仅确保了信息的时效性,还能够应对实时变化的情况。
4.5 LLM-based智能体:迈向自主系统的前沿
基于LLM的智能体预示了大语言模型应用的一个激动人心的前沿领域。这些智能体不仅能够理解和生成自然语言,还能根据指令执行复杂的任务序列,做出明智的决策,并与环境进行交互。
想象一下,拥有一个虚拟助手,它不仅能够回答你的问题,还能助你完成一系列复杂的任务。比如,你或许会说:“我想计划一次周末的短途旅行。”一个基于LLM的智能体可能会如此回应:
-
“明白了,让我助您规划周末的短途旅行。首先,我需要了解一些细节。您想去哪里游玩?预算是多少?有无特殊的偏好?”
-
在收集了这些信息后,智能体可能会继续建议:“根据您的喜好,我推荐您前往海滨度假胜地。我现在将为您查询附近的优质海滨度假村。”3. 随后,智能体凭借搜索API之力,迅速寻觅到了与您的预算和偏好相契合的三个选项。紧接着,它将细细查询每个选项的天气状况与周边酒店状况,向您娓娓道来:“根据您的要求,我觅得了三个绝佳之选。接下来,我将逐一为您查看天气预报和附近酒店的详情。”
-
搜集完所有必要信息后,智能体细致整理,为您提供中肯建议:“经过深思熟虑,我强烈推荐X地作为您的首选。那里风和日丽,更有一处价格合理的海滩度假村尚有空房。您是否愿意让我为您办理预订手续?”
-
若您欣然应允,智能体便会运用预订API,为您完成酒店的预订流程。这一连串的操作,充分展现了基于LLM的智能体如何将语言理解、任务规划、信息检索与决策制定完美融合,构建出一个强大而几乎无需人为干预的系统。
大语言模型的应用与精进,正是一个日新月异的领域。通过洞悉模型的局限,巧妙运用提示工程技巧,结合外部知识与工具,以及构建智能体系统,我们不断拓展着大语言模型的应用范围与效能。随着技术的不断革新,我们有理由期待更多创新的运用与增强技术,将大语言模型推向更为智能、实用的新高度。
非常感谢您的聆听。接下来,让我们共同步入下一章节的旅程。在此章节中,我们将探讨大语言模型的数据集与评估方法。
5. 大语言模型的数据集与评估
大语言模型的成长,离不开优质数据集的滋养与有效评估方法的指引。这就好比为一位才华横溢的学子提供丰富的学习资料和严谨的考核机制。本章将深入探讨用于训练与评估大语言模型的各类数据集,以及衡量这些模型性能的多样化评估指标和方法。
大语言模型的数据集与评估方法,构成了一个错综复杂的生态系统。在这个生态系统中,数据集如同肥沃的土壤和充足的养分,为模型提供源源不断的知识与学习材料;而评估方法则如同自然界的选择机制,助我们辨识并培养出最为出色的模型。这个生态系统的健康与平衡,直接关系到大语言模型的发展方向与应用潜力。
5.1 基础任务数据集
基础任务数据集,主要服务于模型的基础语言理解与生成能力的训练与评估。从简单的文本分类到复杂的阅读理解任务,这些数据集无所不包。
以SQuAD(Stanford Question Answering Dataset)为例,它如同一位严谨的教师,为模型设置了众多阅读理解的挑战。想象一下学生们在阅读一篇文章后回答相关问题的场景,SQuAD便为模型创造了类似的情境。它包含了超过10万个问题-答案对,这些问题均源自维基百科的文章。模型需要深入理解文章内容,精准定位并提取问题的答案。例如,面对一段关于莎士比亚的文本,问题可能是“莎士比亚出生于哪一年?”模型需从文本中准确找出并提取这一信息。
另一个引人瞩目的数据集是GLUE(General Language Understanding Evaluation)。GLUE并非单一数据集,而是一个涵盖多个子任务的综合基准。它犹如一场全面而严格的语言能力测试,测试内容从情感分析到自然语言推理等方面应有尽有。在MNLI(Multi-Genre Natural Language Inference)子任务中,模型需判断两个给定句子之间的逻辑关系是蕴含、矛盾还是中性。这一任务着重考验模型的逻辑推理能力。
5.2 涌现能力数据集
随着大语言模型规模的日益壮大,研究者们发现这些模型逐渐展现出一些意想不到的“涌现能力”。为了评估这些能力,研究者们特意设计了一系列数据集。
MMLU(Massive Multitask Language Understanding)便是其中的佼佼者。这个数据集横跨从基础教育到专业领域的57个学科,包括数学、物理、法律、医学等。它不仅考验模型的知识广度,更挑战其推理能力。想象一位高中生参加各种学科的奥林匹克竞赛的场景,MMLU便为大语言模型设置了类似的挑战。另一个引人入胜的数据集名为GSM8K(Grade School Math 8K),它汇聚了超过8000道小学数学应用题。乍一看,这些题目似乎轻而易举,但实则它们考验的是模型在多步推理方面的造诣。比如,一道题目可能会这样呈现:“小明拥有5个苹果,他赠予小红2个,随后又从商店购入3个。那么,小明现在手中有多少个苹果?”模型需要细致解读问题,逐步进行计算,最终得出精确的答案。这一过程不仅要求基本的算术能力,还需对自然语言描述的场景有深刻的理解,并能进行周密的逻辑推理。
5.3 指令跟随数据集
随着大语言模型在对话和任务执行领域的广泛应用,对模型理解和执行指令的能力进行评估变得愈发关键。为此,指令跟随数据集应运而生。
FLAN(Fine-tuned LAnguage Net)数据集正是其中一例。它拥有大量指令-响应对,涵盖了多元化的任务类型。使用FLAN数据集,就如同在训练一位无所不能的智能助手,使其能够理解并执行各类不同的指令。比如,指令可能是“请用一句话概括这篇文章的主旨”,或是“将以下英文句子翻译成法语”。模型需要精准理解指令,并给出恰如其分的响应。
值得一提的是AlpacaEval数据集,它独特之处在于,除了人类编写的指令外,还包含了模型生成的指令。这种方法为指令集合带来了更多的多样性和挑战性。例如,数据集中可能包含这样的指令:“请用5岁孩子能理解的方式解释量子纠缠理论”。这不仅是对模型知识储备的考验,更是对其解释复杂概念能力的挑战。
5.4 评估指标
对大语言模型的性能进行评估是一项复杂而细致的工作,需要多种指标来全面衡量模型的各项能力。
在生成任务方面,BLEU(Bilingual Evaluation Understudy)分数是一项广为人知的指标。BLEU主要用于评估机器翻译的质量,但其适用性也扩展至其他文本生成任务。它通过计算模型生成文本与人类参考文本的n-gram重叠度来评定分数。然而,BLEU也存在一定的局限性,比如它不考虑语义的相似性,仅注重词语的匹配度。
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)则是另一个常用于评估文本摘要的指标。它拥有多个变体,如ROUGE-N(关注n-gram重叠)和ROUGE-L(考虑最长公共子序列)。ROUGE在衡量精确度的同时,也重视召回率,因此能够更为全面地评估生成文本的质量。
对于问答和阅读理解任务,F1分数和Exact Match(EM)是常用的评估指标。F1分数是精确度和召回率的调和平均,而EM则要求答案完全匹配。两者结合使用,能够全面反映模型的性能。
然而,随着大语言模型能力的日益增强,传统的自动评估指标往往难以全面捕捉模型的所有优势。因此,人工评估依然占据着不可或缺的地位。例如,在开放式问答或创意写作任务中,人类评估者会根据回答的相关性、连贯性和创造性等多个维度进行评分。
此外,一些新颖的评估方法也在不断涌现。比如,利用大语言模型本身来评估其他模型的输出质量。这种方法的核心思想是,如果一个强大的语言模型难以区分人类文本和AI生成的文本,那么该AI文本的质量就可以被认为是上乘的。
5.5 挑战与未来方向
尽管在数据集和评估方法上已取得了显著的进步,但仍有诸多挑战等待我们去克服。首先是数据集的广泛性和代表性的挑战。当前的数据集多集中于英语,未能全面涵盖其他语言与文化,这可能限制模型在非英语任务中的表现。为了推动真正的全球语言理解,我们迫切需求更为多元、跨文化的数据集来训练通用模型。其次,评估指标亦有其局限性。传统的自动评估体系难以捕捉到语言中的细腻之处,如幽默、讽刺或创新表达,构建能准确反映这些高级语言特性的评估指标,仍是一项艰巨的任务。
同时,如何确保模型的道德性与安全性,亦是我们面临的重要课题。我们急需构建专门的数据集和评估机制,确保模型不会输出有害、偏见或不适宜的内容。
此外,随着大语言模型向多模态方向迈进,如何设计能有效评估模型在文本、图像、音频等多种模态间交互能力的数据集和评估方法,将是未来研究的关键。
大语言模型的数据集与评估体系正经历着日新月异的变革。丰富多样、质量上乘的数据集为模型提供了源源不断的学习动力,而日趋完善的评估方法则为模型性能的提升提供了明确的指引。但请铭记,无论数据集如何全面,评估方法如何精细,其终极目标都是使语言模型更好地服务于人类。因此,在追求技术革新的同时,我们亦需时刻反思,如何让这些进步更好地契合人类价值观和社会需求。
6. 大语言模型在基准测试中的卓越表现
大语言模型究竟拥有怎样的能力?它们在各类任务中的表现又是如何?这些问题不仅吸引着研究者的目光,也牵动着产业界与公众的期待。本章将深入剖析主流大语言模型在各项基准测试中的卓越成果,通过对比分析,更全面地展现这些模型的优势与局限。
评估大语言模型的表现,犹如对全能运动员进行一场全方位的体能测验。每一项基准测试都如同一个特定的运动项目,全面考验着模型在某一方面的能力。通过这一系列多元化的测试,我们得以全方位地评估模型的性能,发现其长处与不足,为未来的研究提供明确的方向。
6.1 卓越的语言理解与生成能力
在基础的语言理解与生成任务中,大语言模型展现出了令人瞩目的实力。以GLUE基准为例,它涵盖了情感分析、自然语言推理等多个维度。GPT-3在GLUE基准测试中表现尤为突出,尤其在CoLA任务中,其性能已接近人类水平。在这一任务中,GPT-3能够精准地识别出微妙的语法错误,充分展现了其对语言结构的深刻理解。
在生成任务方面,BLOOM模型亦有着杰出的表现。在多语言摘要生成任务中,它能够准确地捕捉文章的主旨,并生成简洁而流畅的摘要。这种能力在新闻摘要、文献综述等领域具有广泛的应用前景。
6.2 强大的推理与问题解决能力
大语言模型在需要复杂推理的任务中同样展现了强大的能力。以GSM8K基准为例,它包含了数千道小学数学应用题,需要模型进行多步推理。在这个基准测试中,PaLM模型展现出了令人赞叹的推理能力。它能够逐步分析问题,精确地计算出每一步骤的答案,最终得出正确的结论。这种能力不仅在教育领域有着广泛的应用前景,也在其他需要复杂推理的领域中展现出巨大的潜力。4. 细致的推理过程不仅得出了精准结果——总共卖出了36+ 54 + 42 = 132个苹果,更展示了问题解决的逐步进展,对于教育应用具有无可估量的价值。
6.3 知识与常识的交汇
评估大语言模型的知识范畴与常识逻辑能力是一项极具挑战性的工作。MMLU(Massive Multitask Language Understanding)基准测试正是为了这一目标而精心设计,其涵盖之广,从基础教育知识至高精尖的专业领域无所不包。
在此基准中,GPT-4展现了非凡的实力。例如,在面对“哪个粒子负责传递电磁力?”这样的物理学问题时,GPT-4不仅准确回答了“光子”,更进一步深入阐述了光子的性质及其在电磁作用中的关键角色。这一深度的解析与阐述,充分展现了GPT-4广泛的知识储备与深邃的推理能力。
6.4 跨越语言的桥梁
随着全球化的步伐日益加快,大语言模型的多语言能力愈发受到重视。XTREME(Cross-lingual TRansfer Evaluation of Multilingual Encoders)基准测试便是为了检验模型的跨语言迁移能力而设。
在此基准中,XLM-R(XLM-RoBERTa)大放异彩。特别是在零样本跨语言迁移的场景下,即模型仅在英语数据上训练,却需要在其他语言环境中执行任务时,XLM-R在多个语言的命名实体识别任务中均展现出了卓越的效果。这一成就意味着,即便面对资源匮乏的语言,我们也有可能通过跨语言迁移技术构建出高效的NLP系统。
6.5 编程的智慧
近年来,大语言模型在编程领域的出色表现备受瞩目。HumanEval基准测试便是为了评估模型的编程能力而设计的,其中涵盖了164个编程难题,涉及多种编程概念与算法。
在HumanEval的考验下,Codex模型展现出了卓越的代码生成能力。以这样一个问题描述为例:“编写一个函数,接受一个整数列表作为输入,返回该列表中第二大的数。如果没有第二大的数,则返回None。”Codex模型生成的Python代码如下:
def second_largest(numbers): `` if len(numbers) < 2: `` return None `` largest = max(numbers) `` second = max(num for num in numbers if num < largest) `` return second if second < largest else None
这段代码不仅成功实现了所需功能,还巧妙处理了边界情况,充分展现了模型对编程逻辑与Python语言特性的深刻理解。
6.6 挑战与限制
尽管大语言模型在多个基准测试中展现出了卓越的能力,但它们仍面临着一系列挑战。
-
模型的不一致性,即有时对于相同的问题,模型可能会给出不同的答案;或在简单问题上出错,而在复杂问题上却表现出色。这种不一致性无疑降低了模型的可靠性,特别是在需要高度准确性的应用场景中。
-
模型的“幻觉”问题,即在某些基准测试(如TruthfulQA)中,即便是最先进的模型也时常会生成看似合理但实际上并不正确的信息。这再次强调了确保模型输出真实性与准确性的重要性。
-
大语言模型在处理需要实时信息或专业领域知识的任务时仍显不足。例如,当被问及“现任联合国秘书长是谁?”时,模型可能会提供过时的答案。4. 模型的伦理与偏见问题同样不容忽视。在诸多公平性和包容性的基准测试中,大语言模型偶露的社会偏见,是对我们在开发和使用这些模型时务必坚守伦理底线的警示。
大语言模型在各类基准测试中均展现出令人瞩目的性能,无论是基础的语言理解还是复杂的推理任务,从多语言处理到代码生成,都凸显出这些模型超凡的能力。然而,我们也必须清晰认识到,这些模型并非无所不能,其在一致性、真实性和公平性方面仍有待提升。
7. 挑战与未来方向
大语言模型的辉煌成就固然瞩目,但挑战亦如影随形。这些挑战不仅为未来的研究划定了方向,更是我们攀登人工智能巅峰的必经之路。本章将深入剖析当前模型所面临的主要挑战,以及研究界正在探寻的富有前景的未来道路。
大语言模型的发展如同一场壮丽的探险之旅。我们已经攀登至令人惊叹的高度,但在通往人工智能巅峰的征途中,仍有无数未知的山峰等待我们去征服。每一个挑战都如同一座新的山峰,而每一个研究方向都指向了一条通往顶峰的可能之路。
7.1 更小、更高效的语言模型
虽然“更大就是更好”的理念曾推动大语言模型飞速前进,但模型庞大的体积也带来了诸多挑战。训练和部署这些模型需要巨大的计算资源,不仅增加了经济成本,还对环境产生了影响。
因此,研究界正在积极寻求开发更小、更高效的语言模型的方法。微软研究院的Phi-1系列模型便是一个有力的例证,其仅有13亿参数,却能在某些任务上媲美拥有数百亿参数的大型模型。
未来的研究方向或将包括:
-
模型压缩技术:探索如何在保持性能的前提下,有效降低模型的参数量。
-
知识蒸馏:研究如何将大型模型的知识高效地迁移到小型模型中。
-
稀疏激活:探究如何在完成特定任务时,仅激活模型中的一小部分参数,以提升效率。
这些研究不仅有望降低模型的使用成本,还可能使大语言模型在资源受限的设备(如移动设备)上得到更广泛的应用。
7.2 新的后注意力架构范式
自2017年Transformer架构问世以来,它便一直是大语言模型的主导架构。然而,随着模型规模的不断增大,Transformer架构在处理长序列时的效率问题也逐渐显现。
研究者们正在寻找新的架构范式,以克服这些限制。State Space Models (SSMs)便是一个充满希望的方向。Mamba等基于SSM的模型在处理长序列时展现出了显著优势,它们能够高效地建模长距离依赖关系,同时保持较低的计算复杂度。
未来的研究可能包括:
-
改进的注意力机制:设计更为高效的注意力机制,以更好地处理长序列。
-
混合架构:结合Transformer和其他架构的优点,打造更加强大的模型。
-
动态架构:研究能够根据输入自动调整结构的模型架构。
这些新的架构范式可能会为大语言模型在效率和能力上带来质的飞跃。
7.3 多模态模型
语言是我们交流和理解世界的重要桥梁,但它并非唯一的方式。视觉、听觉等其他感官在我们的认知过程中同样扮演着举足轻重的角色。因此,研究界正在积极探索如何将语言模型与其他模态结合,打造真正的多模态AI。
GPT-4已经展现出处理图像和文本的能力,而DALL-E等模型则能够根据文本描述生成图像。未来的研究方向可能包括:
-
跨模态理解:深化模型对不同模态间关系和互动的理解。
-
多模态生成:同时生成多种模态的内容,如为视频自动生成配音和字幕。
-
多模态推理:利用多种模态的信息进行更为复杂的推理任务。多模态模型的发展,预示着AI系统在理解和交互上或将逐步贴近人类的认知模式。
7.4 改进的LLM使用与增强技术
尽管大语言模型的力量已然显著,但关于如何高效运用和强化这些模型的研究,仍然如火如荼地展开。
例如,检索增强生成(RAG)技术已在提高模型输出的精确度和时效性上展现出巨大潜力。未来的研究路径可能涵盖:
-
智慧的检索策略:深入探究如何更精确地识别并检索与当前任务紧密相连的信息。
-
实时知识更新:如何让模型动态更新其知识库,避免冗长的完全重训练过程。
-
个性化定制增强:研究如何依据用户的独特需求和背景知识,为模型输出量身打造。
此外,提示工程(Prompt Engineering)的演进亦不容忽视。如何精巧设计提示,引导模型产出所需结果,本身就是一场引人入胜的探索之旅。
7.5 安全与伦理并重的AI
随着大语言模型在多个领域的广泛运用,确保这些模型的安全性与伦理性成为了迫切需求。
当前研究已揭示了部分潜在风险,如模型可能生成有害或带有偏见的内容,或被用于生成不实信息等。未来的研究可能集中在以下几个方面:
-
对齐技术:致力于让模型的行为与人类的价值观紧密相连,和谐一致。
-
可解释性:力求让模型的决策过程更加清晰透明,易于解读。
-
隐私保护:在利用海量数据进行模型训练的同时,确保个人隐私得到切实保护。
-
公平性:致力于减少模型在不同人群中的表现差异,保障AI技术的公平使用。
这些研究不仅关乎技术层面,更触及法律、伦理、社会学等多个领域,需要跨学科的合作与努力。
大语言模型的未来发展趋势是丰富多元的。技术上,我们将致力于提升模型的效率,拓宽其能力边界;应用上,我们将深入探索如何充分利用和增强这些模型;社会上,我们需确保这些强大技术工具的使用充满责任感。
面对的挑战固然巨大,但机遇亦同样诱人。它们不仅推动了AI技术的持续进步,更促使我们深入反思智能的本质。随着研究的深入,我们有理由期待大语言模型将继续革新我们与技术的互动方式,并在解决复杂现实问题中发挥至关重要的作用。
零基础如何学习大模型 AI
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型实际应用案例分享
①智能客服:某科技公司员工在学习了大模型课程后,成功开发了一套基于自然语言处理的大模型智能客服系统。该系统不仅提高了客户服务效率,还显著降低了人工成本。
②医疗影像分析:一位医学研究人员通过学习大模型课程,掌握了深度学习技术在医疗影像分析中的应用。他开发的算法能够准确识别肿瘤等病变,为医生提供了有力的诊断辅助。
③金融风险管理:一位金融分析师利用大模型课程中学到的知识,开发了一套信用评分模型。该模型帮助银行更准确地评估贷款申请者的信用风险,降低了不良贷款率。
④智能推荐系统:一位电商平台的工程师在学习大模型课程后,优化了平台的商品推荐算法。新算法提高了用户满意度和购买转化率,为公司带来了显著的增长。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。

三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


如果二维码失效,可以点击下方链接,一样的哦
【CSDN大礼包】最新AI大模型资源包,这里全都有!无偿分享!!!
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









