







从图中我们可以看到目前有 13 万多人评分,达到了 7.5 分,打 4 星和 3 星的居多,并非网上一些人所说的口碑两极分化(如果两级分化,应该是打 5 星 和 1 星的居多吧?!)。
页面向下拉到影评位置,如下图所示:

我们可以看到有 5 万多条影评,目前豆瓣对查看影评数据的限制是:未登录最多可以查看 200 条数据,登录用户最多可以查看 500 条数据,我们要做的是通过 Python 爬取豆瓣 500 条影评数据,然后进行数据分析。
首先获取影片列表 URL,具体操作为:点击上图中 全部 52846 条,进入影评列表首页,如下图所示:

但我们发现一个问题,该 URL 参数中并没有行号等信息(实现翻页需要),这个问题我们只需点击后页按钮即可看到,结果如图所示:

现在我们可以从 URL 中看到这些信息了,因 start 参数为变量,我们将上面 URL 修改为:https://movie.douban.com/subject/27668250/comments?start=%d&limit=20&sort=new_score&status=P 作为爬取开始 URL。
接着我们看一下如何实现登陆,首先打开登录页,如下图所示:
我们先在手机号/邮箱和密码输入框处随意输入(不要输入正确的用户名和密码),再按 F12 键打开开发者工具,最后点击登录豆瓣按钮,结果如图所示:
我们点击上面图中所示 basic 项,点击后结果如图所示:
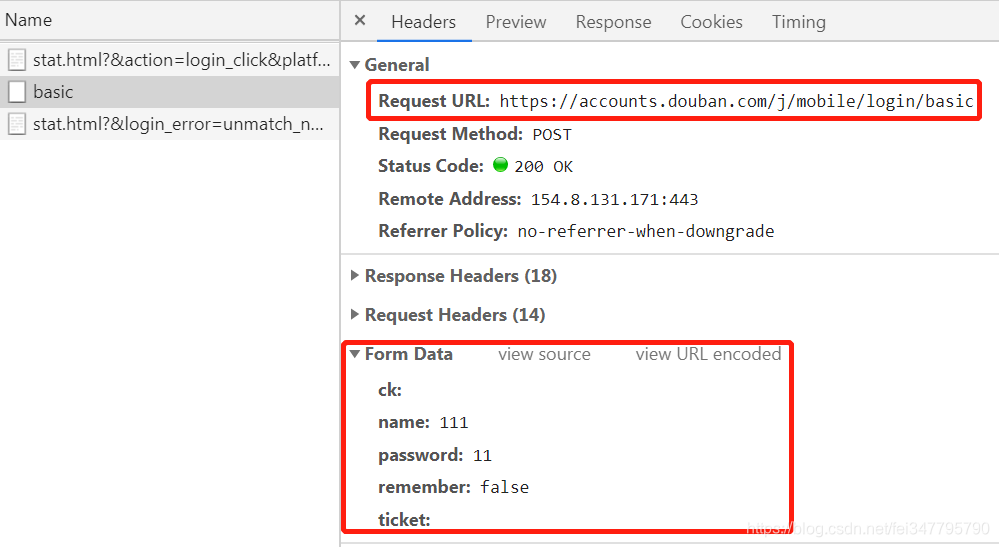
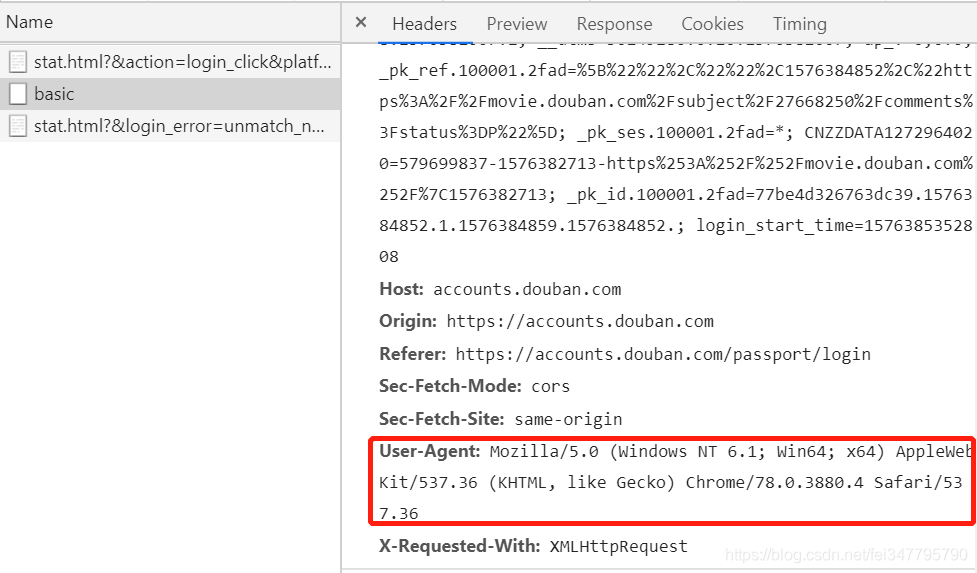
此时可以看到 Request URL(登录所需 URL) 和 Form Data 项,这两项是我们登录时需要的,当然我们还需 User-Agent,点击上面图中所示的 Request Headers 项即可看到,如图所示:
所需要的东西都找好了,接下来就是具体实现了,豆瓣登录和影评数据爬取的具体实现如下所示:
import requests
import time
import random
from lxml import etree
import csv
新建 csv 文件
csvfile = open(‘南方车站的聚会.csv’,‘w’,encoding=‘utf-8’,newline=‘’)
writer = csv.writer(csvfile)
表头
writer.writerow([‘时间’,‘星级’,‘评论内容’])
def spider():
url = ‘https://accounts.douban.com/j/mobile/login/basic’
headers = {“User-Agent”: ‘Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)’}
comment_url = ‘https://movie.douban.com/subject/27668250/comments?start=%d&limit=20&sort=new_score&status=P’
data = {
‘ck’: ‘’,
‘name’: ‘自己的用户名’,
‘password’: ‘自己的密码’,
‘remember’: ‘false’,
‘ticket’: ‘’
}
session = requests.session()
session.post(url=url, headers=headers, data=data)
总共 500 条,每页 20 条
for i in range(0, 500, 20):
获取 HTML
data = session.get(comment_url % i, headers=headers)
print(‘第’, i, ‘页’, ‘状态码:’, data.status_code)
暂停 0-1 秒
time.sleep(random.random())
解析 HTML
selector = etree.HTML(data.text)
获取当前页所有评论
comments = selector.xpath(‘//div[@class=“comment”]’)
遍历所有评论
for comment in comments:
获取星级
star = comment.xpath(‘.//h3/span[2]/span[2]/@class’)[0][7]
获取时间
t = comment.xpath(‘.//h3/span[2]/span[3]/text()’)
获取评论内容
content = comment.xpath(‘.//p/span/text()’)[0].strip()
排除时间为空的项
if len(t) != 0:
t = t[0].strip()
writer.writerow([t, star, content])
接下来我们通过词云直观的来展示下整体评论情况,具体实现如下所示:
import csv
import jieba
from wordcloud import WordCloud
import numpy as np
from PIL import Image
jieba 分词处理
def jieba_():
csv_list = csv.reader(open(‘南方车站的聚会.csv’, ‘r’, encoding=‘utf-8’))
print(‘csv_list’,csv_list)
comments = ‘’
for i,line in enumerate(csv_list):
if i != 0:
comment = line[2]
comments += comment
print(“comment–>”,comments)
jieba 分词
words = jieba.cut(comments)
new_words = []
要排除的词
remove_words = [‘以及’, ‘在于’, ‘一些’, ‘一场’, ‘只有’,
‘不过’, ‘东西’, ‘场景’, ‘所有’, ‘这么’,
‘但是’, ‘全片’, ‘之前’, ‘一部’, ‘一个’,
‘作为’, ‘虽然’, ‘一切’, ‘怎么’, ‘表现’,
‘人物’, ‘没有’, ‘不是’, ‘一种’, ‘个人’
‘如果’, ‘之后’, ‘出来’, ‘开始’, ‘就是’,
‘电影’, ‘还是’, ‘不是’, ‘武汉’, ‘镜头’]
for word in words:
if word not in remove_words:
new_words.append(word)
global word_cloud
用逗号分隔词语
word_cloud = ‘,’.join(new_words)
生成词云
def world_cloud():
背景图
cloud_mask = np.array(Image.open(‘bg.jpg’))
wc = WordCloud(
背景图分割颜色
background_color=‘white’,
背景图样
mask=cloud_mask,
显示最大词数
max_words=600,
显示中文
font_path=‘./fonts/simhei.ttf’,
字的尺寸限制
min_font_size=20,
max_font_size=100,
margin=5
)
global word_cloud
x = wc.generate(word_cloud)
生成词云图片
image = x.to_image()
展示词云图片
image.show()
保存词云图片
wc.to_file(‘wc.png’)
整体评论词云图

因为有人说了影片口碑两级分化,接下来我们看一下打 1 星和 5 星的词云效果如何,主要实现如下所示:
for i,line in enumerate(csv_list):
if i != 0:
star = line[1]
comment = line[2]
一星评论用 1,五星评论用 5
if star == ‘1’:
comments += comment
一星评论词云图
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









